- The paper introduces an automated framework that converts human visual demonstrations into bimanual manipulation skills using a novel contact-based reward system.
- It integrates 3D object reconstruction, robust pose estimation, motion retargeting, and residual RL policy training to achieve state-of-the-art performance.
- Experimental results demonstrate improved success rates and pose accuracy, highlighting a scalable approach to video-to-robot skill acquisition.
DexMan: Learning Bimanual Dexterous Manipulation from Human and Generated Videos
Introduction and Motivation
DexMan introduces an automated framework for transferring human visual demonstrations into bimanual dexterous manipulation skills for humanoid robots in simulation. The system operates directly on third-person monocular RGB videos, eliminating the need for camera calibration, depth sensors, scanned 3D object assets, or ground-truth hand/object motion annotations. Unlike prior approaches that focus on simplified floating hands or require motion-capture data, DexMan directly controls a full humanoid robot and leverages novel contact-based rewards to improve policy learning from noisy hand-object poses estimated from in-the-wild videos.

Figure 1: DexMan is an automated framework that transfers human visual demonstrations into bimanual dexterous manipulation skills for humanoid robots in simulation.
The framework is motivated by the need to scale robot skill acquisition beyond the constraints of motion-capture datasets, enabling the use of both real and synthetic videos for large-scale, diverse data curation. DexMan addresses the embodiment gap between human and robot morphologies by combining object-centric contact priors, robust pose estimation, and residual RL policy refinement.
System Architecture and Pipeline
DexMan's pipeline consists of four main stages:
- 3D Object Reconstruction: Utilizes SAM2 for object segmentation and Trellis for mesh generation from cropped images. Meshes are rescaled using depth maps predicted by VGGT, aligned to the metric scale of MANO hand meshes.
- Hand and Object Pose Estimation: Employs HaMeR for hand mesh recovery and FoundationPose for object pose estimation, regularized by 3D point trajectories tracked via SpatialTracker. This hybrid approach yields temporally consistent and accurate pose estimates, even under occlusion or fast motion.
- Motion Retargeting: Retargets human wrist and finger motions to the robot using staged IK solvers. The system aligns the human body pose with the robot's simulator frame via gravity and facing direction estimation, and samples stable object configurations to mitigate physical instability in simulation.
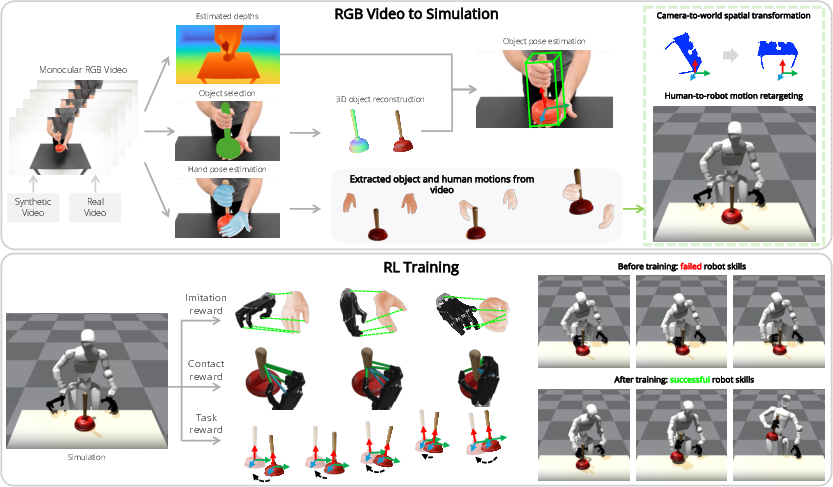
Figure 2: Overview of DexMan’s pipeline from monocular video to robot skill acquisition, including object reconstruction, pose estimation, retargeting, and RL policy refinement.
- Residual RL Policy Training: Trains a policy to refine retargeted motions, guided by object-following, imitation, and a novel contact-prior attraction reward. The contact reward establishes correspondence between robot hand keypoints and human-contacted object vertices, promoting stable, task-relevant grasps.

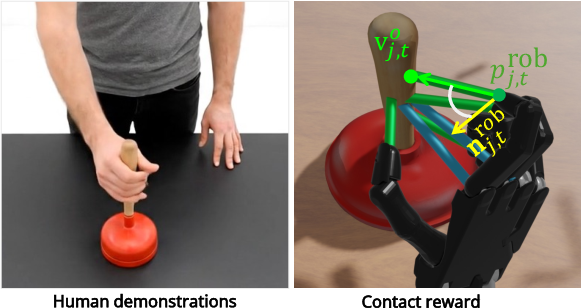
Figure 3: DexMan’s sampling strategy for stable object configuration in simulation.
DexMan’s contact reward is designed to overcome the limitations of prior contact-reward formulations, which often encourage trivial or physically implausible contacts. The reward is object-centric, robust to pose variations, and consists of:
- Attraction Term: Pulls robot hand keypoints toward human-contacted object vertices.
- Directional Alignment Term: Aligns the keypoint–vertex vector with the surface normal, preventing unrealistic contacts.
This structured correspondence enables efficient exploration and acquisition of generalizable contact skills, rather than mere positional imitation.
(Figure 4)
Figure 4: Contact reward formulation, showing attraction and alignment of robot hand keypoints to human-contacted object vertices and surface normals.
Experimental Results
Object Pose Estimation
On the TACO dataset, DexMan achieves state-of-the-art performance in 6D object pose estimation, outperforming FoundationPose and SpatialTracker in ADD-S, VSD, and failure rate metrics. The integration of 3D point trajectories yields more stable and accurate pose estimates.
Residual RL Policy
On OakInk-v2, DexMan’s RL policy surpasses MANIPTRANS by 19% in success rate, despite controlling a full humanoid robot rather than floating hands. The contact-based reward is critical for reliable task execution, as evidenced by ablation studies showing a collapse in success rate when contact rewards are removed.
Skill Acquisition from Real and Synthetic Videos
DexMan demonstrates the first end-to-end video-to-robot skill acquisition pipeline from uncalibrated monocular RGB inputs. It recovers 27.4% of skills from TACO videos and 39.0% from Veo3-generated synthetic videos, without ground-truth hand-object annotations. The system closely reproduces observed object motions, achieving IoU scores of 49.0% (TACO) and 44.7% (Veo3).






Figure 5: Success case in Veo3-generated video: bimanual book manipulation.




Figure 6: Success case in Veo3-generated video: single-handed wine bottle manipulation.




Figure 7: Success case in Veo3-generated video: single-handed banana manipulation.




Figure 8: Success case in Veo3-generated video: pouring motion with a water bottle.




Figure 9: Success case in Veo3-generated video: bimanual tire manipulation.



Figure 10: Success case in Veo3-generated video: bimanual pot manipulation.




Figure 11: Success case in Veo3-generated video: single-handed vegetable peeler manipulation.



Figure 12: Success case in TACO dataset.



Figure 13: Success case in TACO dataset.
Failure Case Analysis and Limitations
DexMan’s failure cases highlight the embodiment gap and limitations in contact reasoning. For example, in the guitar-lifting task, the robot fails due to morphological discrepancies with the human demonstrator. In the brush-picking task, video-generated trajectories are sometimes physically infeasible, and the robot cannot execute rapid in-hand rotations. In the shoe-picking task, the contact reward does not distinguish between correct and incorrect approach sides, leading to unsuccessful grasps.






Figure 14: Failure case in the brush-picking task, showing visual penetration of the brush into the hand.



Figure 15: Failure case in the shoe-picking task, with misaligned thumb contact.
The framework is currently limited to simulation, single-human demonstrations, and rigid tabletop objects. It prioritizes task completion over motion naturalness and does not fully account for arm posture or collision avoidance.
Implementation Details
DexMan is implemented in Isaac Gym, using PPO for RL policy training. The observation space includes robot joint states, object pose, target pose, and current timestep. Reward weights and thresholds are carefully tuned for contact, object-following, and imitation components. The system leverages state-based RL, with residual corrections applied to retargeted human motions via real-time bimanual IK solvers.
Implications and Future Directions
DexMan demonstrates a scalable pathway for robot skill acquisition from human demonstrations, leveraging both real and synthetic video data. The contact-centric reward formulation is shown to be essential for physically plausible skill transfer. The framework’s ability to operate without motion-capture data or ground-truth annotations opens avenues for large-scale, generalist dexterous manipulation policy training.
Future work should address sim-to-real transfer, extend to deformable and articulated objects, improve motion naturalness, and integrate contact reasoning into pose estimation. Mobile manipulation platforms and more expressive control parameterizations may further enhance generalizability and robustness.
Conclusion
DexMan presents a comprehensive framework for learning bimanual dexterous manipulation from human and generated videos, achieving strong performance in pose estimation and skill transfer benchmarks. The system’s contact-centric approach and ability to leverage monocular RGB inputs represent significant advances in scalable robot learning. While current limitations remain, DexMan lays the groundwork for future research in real-world deployment and more complex manipulation scenarios.