- The paper introduces X-Sim, a framework that trains robot manipulation policies from human videos by leveraging object-centric rewards in photorealistic simulations.
- It employs 2D Gaussian Splatting and online domain adaptation to transfer policies from simulation to real-world environments efficiently.
- Experiments demonstrate a 30% improvement over baselines and 90% task success in low-data settings, underscoring robust cross-embodiment learning.
"X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real" (arXiv ID: (2505.07096))
Introduction
The paper introduces X-Sim, a framework designed to train robot manipulation policies using human videos, without the need for explicit action labels. Current approaches in imitation learning require paired human-robot demonstrations or attempt to directly translate human movements to robots, often failing due to embodiment mismatches. X-Sim leverages a real-to-sim-to-real methodology by generating photorealistic simulations from human video data to train RL policies. This paper focuses on utilizing object motion as a transferable supervisory signal, thus enabling robots to achieve similar tasks even when following different trajectories than humans.
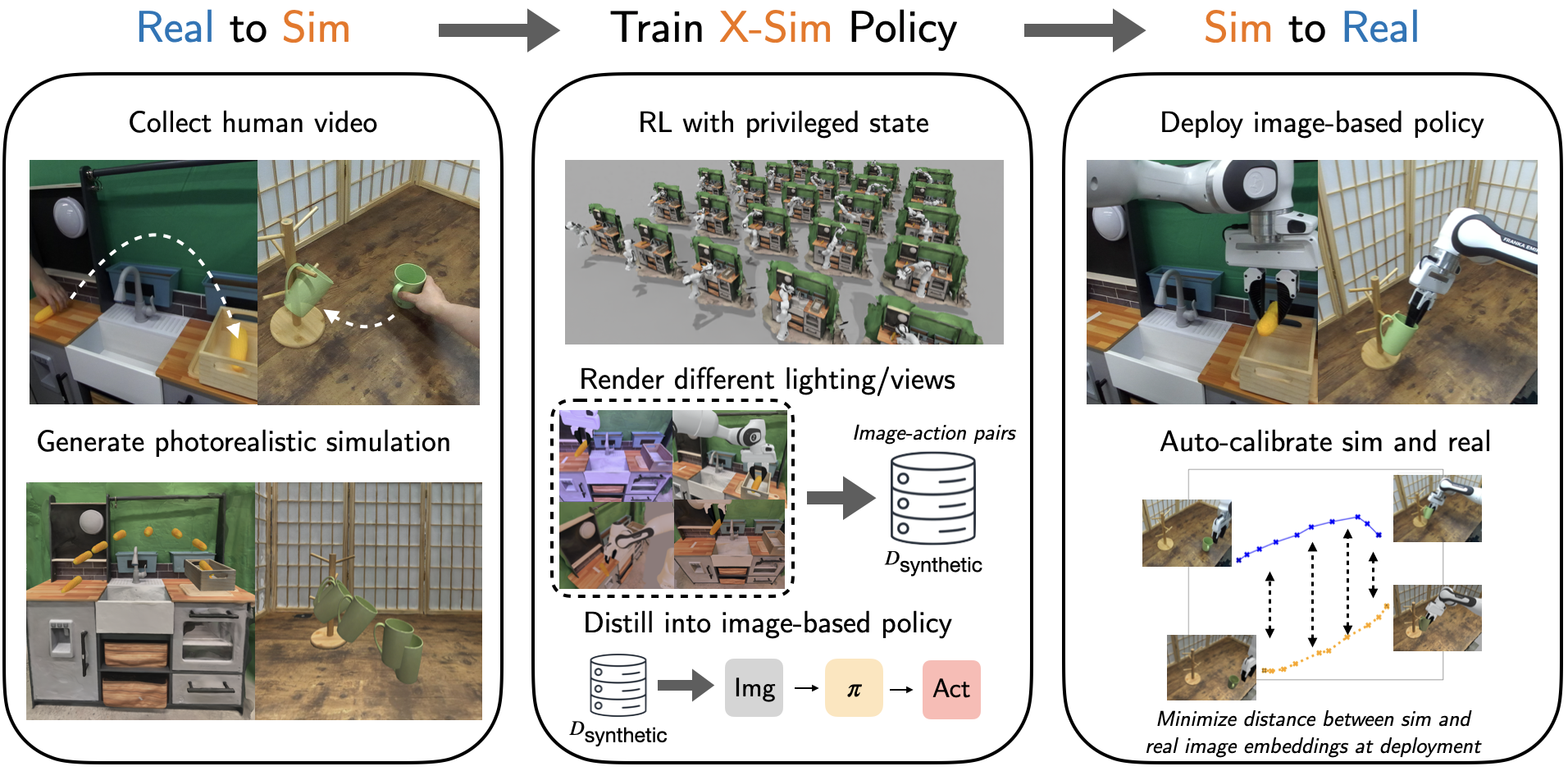
Figure 1: X-Sim framework overview demonstrating the real-to-sim-to-real approach for policy learning from human videos.
Methodology
Real-to-Sim Transfer
The key innovation of X-Sim lies in reconstructing simulation environments from RGBD videos to track object states and define object-centric rewards. By extracting high-fidelity object meshes and tracking their trajectories over the video, it employs 2D Gaussian Splatting to construct accurate simulation environments. This procedure allows Q-learning agents to mimic the outcomes of the human demonstrations by utilizing object-centric rewards based on the trajectory divergence between the RL policy and the human demonstration.
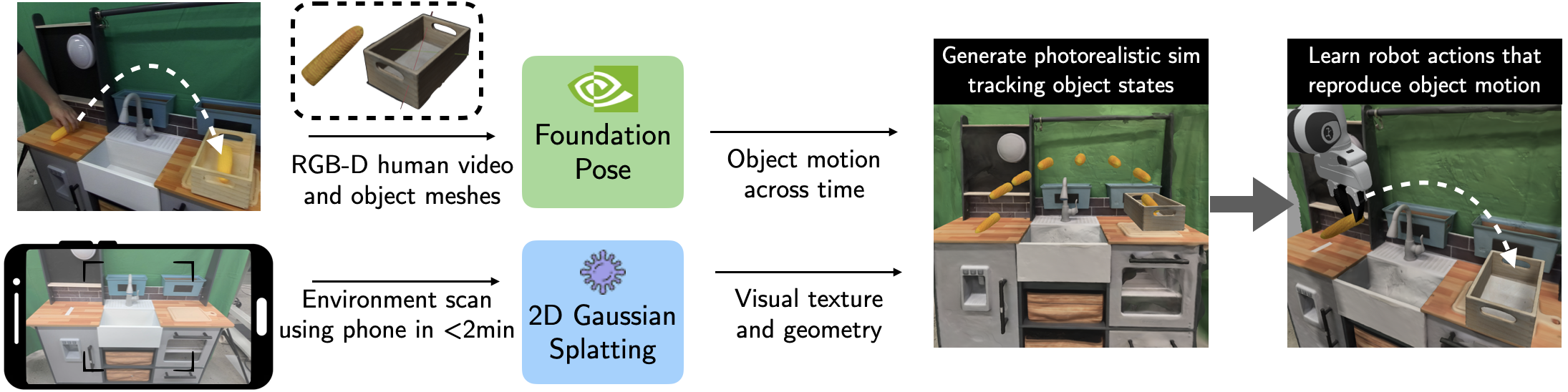
Figure 2: The real-to-sim process captures object motion from RGBD videos and constructs a simulation environment to train RL policies.
Sim-to-Real Policy Transfer
Once the privileged-state RL policies are trained, X-Sim generates a synthetic dataset of image-action pairs. The approach involves rendering diversified scenes by varying object configurations and viewpoints. Subsequently, it distills these policies into an image-conditioned diffusion network that can be deployed in real-world scenarios. Sim-to-real transfer is achieved via online domain adaptation, comparing real and simulated rollouts to iteratively minimize the sim-to-real visual gap during policy execution.
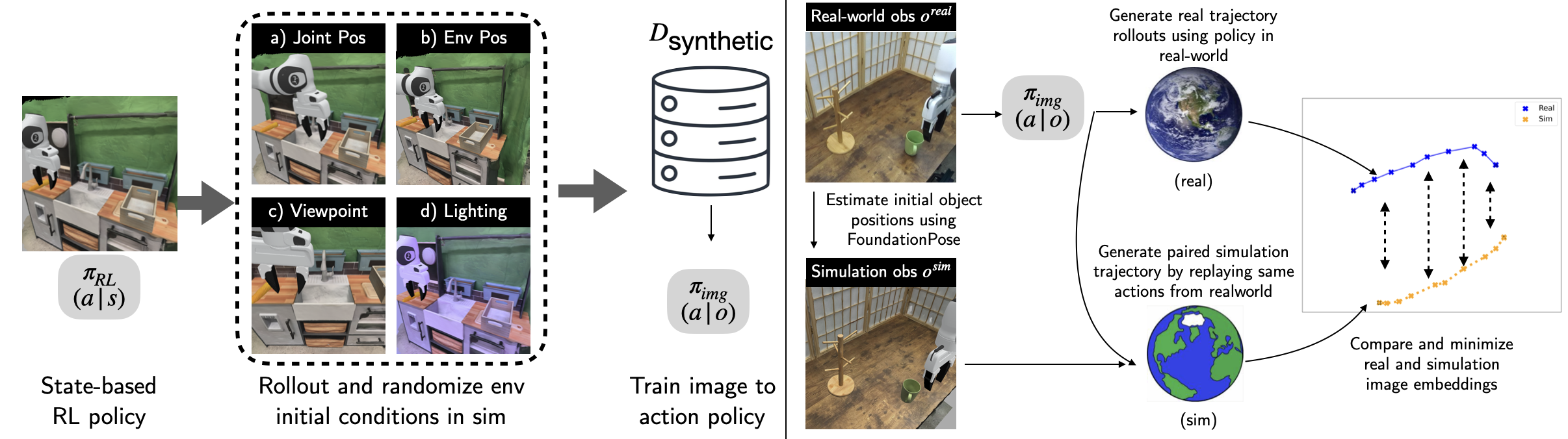
Figure 3: Demonstration of the sim-to-real transfer process with domain adaptation minimizing observation discrepancies.
Experimental Results
Extensive evaluations demonstrate X-Sim's capability to translate policies from simulation to real-world scenarios effectively. In tests across five different manipulation tasks, X-Sim consistently outperformed benchmarks, achieving a 30% improvement over traditional hand-tracking and baseline sim-to-real approaches. The diffusion policy was particularly impactful in low-data settings, showing effective generalization with 90% task success using only a fraction of the data compared to traditional teleoperation.
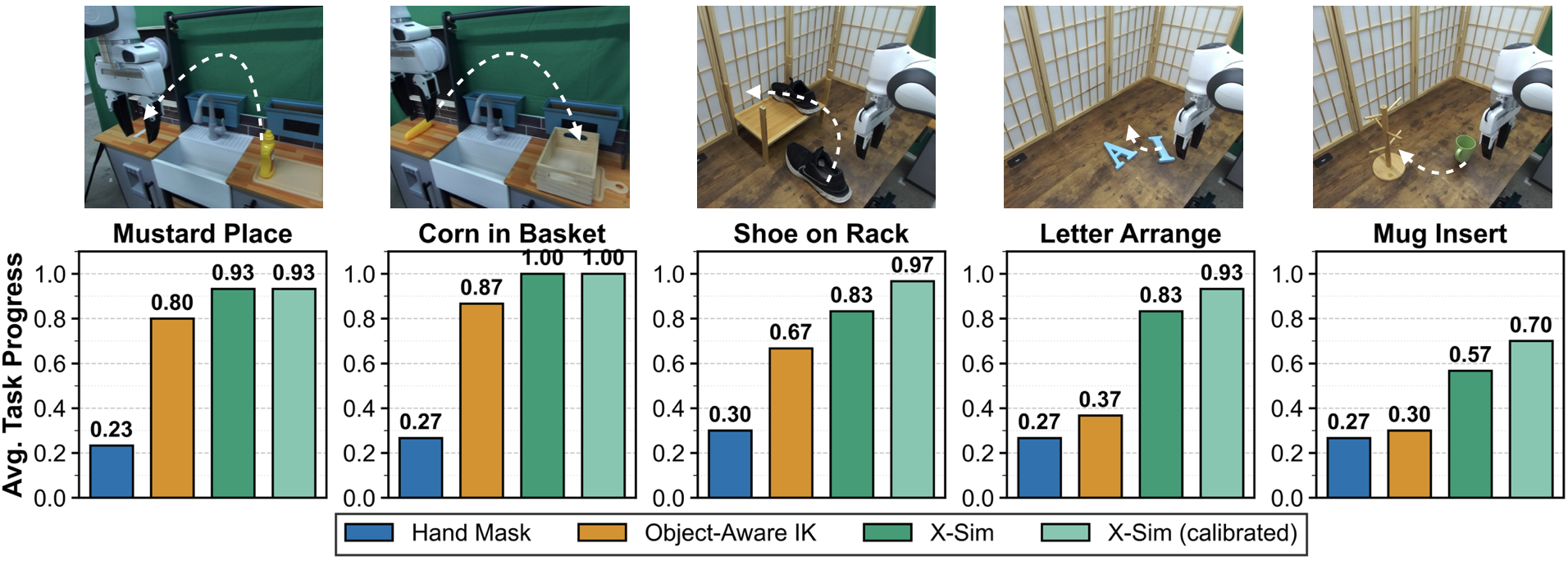
Figure 4: Task performance metrics showing the average task progress of X-Sim against baseline methods.
Discussion
Data Efficiency and Robustness
The method outpaces behavior cloning in terms of data efficiency, reducing the need for teleoperator data by 10 times while matching performance. The framework’s synthetic data strategy efficiently addresses initial state distribution broadening, providing robustness to unseen tasks and novel camera viewpoints.

Figure 5: Visualization of task initial state distributions used for data efficiency assessment.
Future Work and Limitations
While demonstrating strong results, X-Sim currently relies on 3D object meshes for tracking, which limits deployment in unstructured environments. Future developments could focus on combining prior models with the framework for seamless adaptation to dynamic scenes, articulations, and deformables. Real-to-sim-to-real calibration refinement remains essential in minimizing real-world observational discrepancies.
Conclusion
X-Sim advances the field of robot policy learning by introducing a scalable, data-efficient platform capable of leveraging human videos as rich sources of information for cross-embodiment learning. Its innovations in simulation and domain adaptation provide a promising direction for incorporating less structured, real-world data, reducing dependency on extensive robot teleoperation. Such capabilities have the potential to significantly accelerate the development of adaptable, large-scale robot models.