- The paper demonstrates that integrating self-supervised tactile objectives into RL significantly improves dexterous manipulation, yielding up to 36% faster object finding and enhanced performance on the RoTO benchmark.
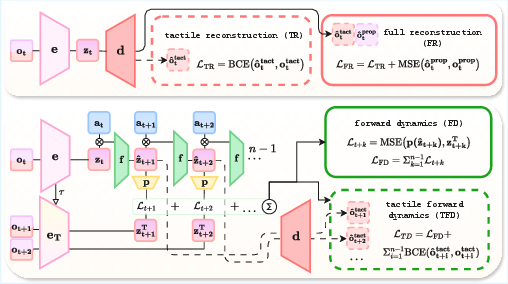
- The paper introduces four self-supervised objectives, including forward dynamics and tactile reconstruction, to robustly encode sparse tactile signals and predict future states.
- The paper shows that decoupling the auxiliary memory from on-policy learning improves long-horizon performance, particularly benefiting complex tasks like Baoding that require precise contact resolution.
Enhancing Tactile-based Reinforcement Learning for Robotic Control
Introduction and Motivation
The paper "Enhancing Tactile-based Reinforcement Learning for Robotic Control" (2510.21609) addresses the persistent challenge of leveraging tactile sensing in reinforcement learning (RL) for dexterous robotic manipulation. While vision-based RL has achieved notable successes, manipulation tasks remain bottlenecked by the reliance on idealized state information and the lack of robust, scalable tactile integration. The authors hypothesize that the inconsistent efficacy of tactile feedback in RL arises from the unique data characteristics of tactile signals—namely, their sparsity and non-smoothness—which can destabilize representation learning and policy optimization. To address this, the paper introduces a suite of self-supervised learning (SSL) objectives tailored to tactile data, and empirically demonstrates their impact on dexterous manipulation tasks using only proprioception and sparse binary contacts.
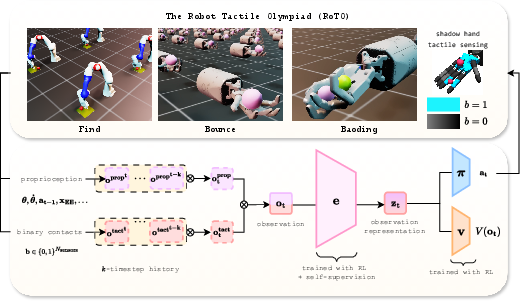
Figure 1: Tactile-based RL with self-supervision. Agents achieve superhuman dexterity in the RoTO benchmark using only proprioception and binary contacts, with self-supervised encoders capturing object positions and velocities.
Methodology
The authors formalize the problem as a POMDP, where the agent receives a k-step history of proprioceptive and tactile observations. The observation encoder, policy, and value function are implemented as MLPs, with the encoder trained jointly via PPO and an auxiliary SSL loss. The total loss is:
L=LPPO+cauxLaux
where Laux is the self-supervised objective.
Self-Supervised Objectives
Four SSL objectives are proposed (see Figure 2):
Separated Auxiliary Memory
To stabilize SSL training, the authors decouple the auxiliary memory from the on-policy RL buffer, allowing the auxiliary loss to be computed over a larger, more diverse dataset. This is particularly beneficial for tasks with long temporal dependencies.
Experimental Setup
Experiments are conducted in Isaac Lab on three custom tasks (the RoTO benchmark):
- Find: Locate a fixed sphere using a Franka arm with two finger contact sensors.
- Bounce: Maximize ball bounces with a Shadow Hand instrumented with 17 binary contact sensors.
- Baoding: Rotate two balls in-hand as many times as possible with the Shadow Hand.
All agents are trained with 4096 parallel environments and extensive hyperparameter sweeps per method and environment.
Results
RL-only Baselines
Proprioceptive-only agents can solve Find and Bounce via implicit contact inference from control errors, but fail on Baoding. Adding explicit tactile signals yields marginal gains in Find, moderate gains in Bounce, and is essential for Baoding.
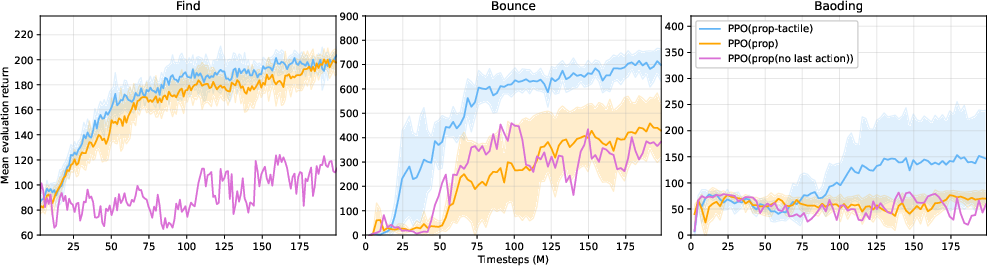
Figure 3: RL-only. Mean evaluation returns for proprioceptive-tactile and proprioceptive-only agents.
RL + SSL
All four SSL objectives outperform RL-only baselines. TR and FD are consistently superior, with FD yielding the highest mean returns in Find and Bounce, and TR providing more reliable performance in Baoding. FR and TFD show environment-dependent performance and are less robust.
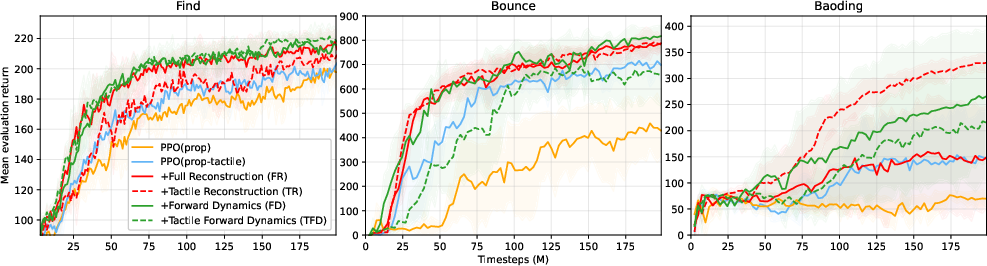
Figure 4: RL+SSL. Mean evaluation returns of self-supervised agents.
RL + SSL + Memory
Decoupling the auxiliary memory has minimal effect in Find and Bounce, but substantially improves Baoding performance, indicating the importance of long-horizon dynamics for complex manipulation.
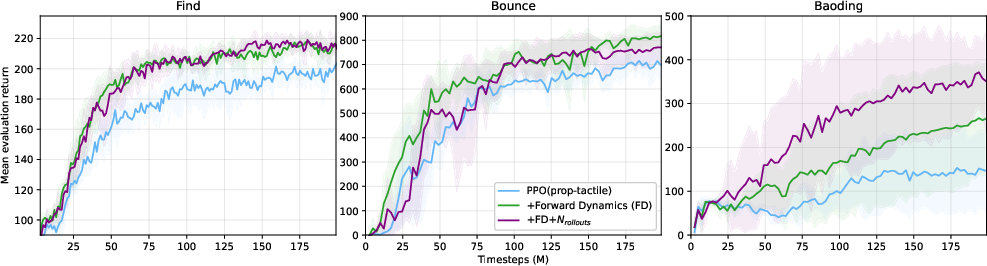
Figure 5: RL+SSL+Memory. Mean evaluation returns of the FD agent with on-policy vs. extended auxiliary memory.
Representation Analysis
Mutual information estimation between the learned latent zt and ground-truth state st reveals that FD agents encode significantly more task-relevant information, especially in Baoding. Marginal MI analysis shows that FD uniquely captures object positions and velocities, while TR and TFD primarily encode contact events.
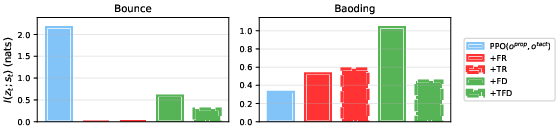
Figure 6: Mutual information estimation. I(zt;st) between latent representations and ground-truth state.
Physical Metrics
Self-supervised agents achieve strong improvements in physical task metrics: 36% faster object finding, 10 more bounces in Bounce, and up to 25 Baoding rotations in 10 seconds—substantially exceeding human and prior robotic baselines.
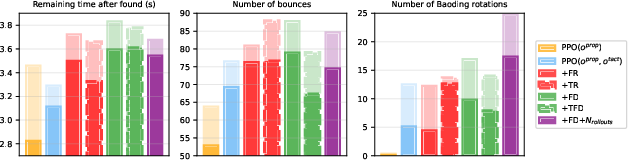
Figure 7: Physical metrics. Maximum (shaded) and mean (bold) across seeds.
Discussion
Task-Dependent Utility of Tactile Sensing
The utility of explicit tactile signals is highly task-dependent. They are critical when:
- Object-robot dynamics are decoupled (e.g., Baoding).
- Objects are low-inertia and proprioceptive signals are insufficient (e.g., Bounce).
- Contact localization or multi-contact resolution is required.
Efficacy of Self-Supervision
Self-supervision enforces compression of task-critical information into the latent space, improving policy learning and robustness. Forward dynamics objectives are particularly effective at encoding predictive state information, while reconstruction objectives can suffer from negative interference when combining modalities.
Off-Policy Auxiliary Training
Decoupling the auxiliary memory enables leveraging a broader data distribution, which is especially beneficial for tasks with long temporal dependencies. This suggests a promising direction for integrating off-policy data into on-policy RL pipelines.
Practical Recommendations
- For tactile-based RL, joint training with tactile reconstruction or forward dynamics objectives and a separated auxiliary memory is recommended.
- Simpler tactile information formats (binary contacts) are surprisingly effective and computationally efficient compared to high-bandwidth pixel-based tactile signals.
Limitations
The primary limitation is the lack of real-world hardware validation. However, the focus on binary contacts mitigates sim-to-real transfer issues. Training with SSL increases computational requirements, especially for long-horizon dynamics objectives and larger auxiliary memories.
Implications and Future Directions
This work demonstrates that self-supervised representation learning can unlock the potential of tactile sensing for dexterous manipulation, even with minimalistic binary contact signals. The findings challenge the prevailing assumption that vision or privileged state information is necessary for high-level dexterity, and suggest that scalable, robust tactile-based RL is feasible with appropriate representation learning strategies.
Future research should focus on:
- Real-world deployment and sim-to-real transfer of tactile-based RL agents.
- Extending SSL objectives to richer tactile modalities (e.g., continuous force, contact pose, or tactile images).
- Integrating off-policy and on-policy learning for improved sample efficiency and generalization.
- Investigating the interplay between tactile, proprioceptive, and visual modalities in multi-sensory RL.
Conclusion
The paper provides a comprehensive empirical and methodological contribution to tactile-based RL, demonstrating that self-supervised objectives—especially forward dynamics—enable superhuman dexterity in complex manipulation tasks using only proprioception and sparse binary contacts. The introduction of the RoTO benchmark and the analysis of representation learning set a new standard for future research in tactile manipulation. The results have significant implications for the design of scalable, robust, and efficient robotic systems capable of dexterous, sensory-driven control.