GenDexHand: Generative Simulation for Dexterous Hands
Abstract: Data scarcity remains a fundamental bottleneck for embodied intelligence. Existing approaches use LLMs to automate gripper-based simulation generation, but they transfer poorly to dexterous manipulation, which demands more specialized environment design. Meanwhile, dexterous manipulation tasks are inherently more difficult due to their higher degrees of freedom. Massively generating feasible and trainable dexterous hand tasks remains an open challenge. To this end, we present GenDexHand, a generative simulation pipeline that autonomously produces diverse robotic tasks and environments for dexterous manipulation. GenDexHand introduces a closed-loop refinement process that adjusts object placements and scales based on vision-LLM (VLM) feedback, substantially improving the average quality of generated environments. Each task is further decomposed into sub-tasks to enable sequential reinforcement learning, reducing training time and increasing success rates. Our work provides a viable path toward scalable training of diverse dexterous hand behaviors in embodied intelligence by offering a simulation-based solution to synthetic data generation. Our website: https://winniechen2002.github.io/GenDexHand/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “GenDexHand: Generative Simulation for Dexterous Hands”
Overview: What is this paper about?
This paper is about teaching robot hands (like artificial versions of human hands) to do tricky tasks—such as opening a laptop, picking up a bottle, or putting an apple into a bowl—entirely inside a computer simulation. The big idea is to use powerful AI models to automatically create lots of realistic practice tasks and virtual environments, then train the robot hand to solve them. This helps fix a major problem: there isn’t enough good training data for robots with many moving parts (like fingers), which makes learning slow and hard.
Goals: What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- How can we automatically create many different, realistic practice tasks for robot hands without humans having to set them up one by one?
- How can we check and improve these virtual scenes so objects are the right size, in the right places, and physically possible?
- How can we make learning faster and more reliable for complex, multi-step hand tasks?
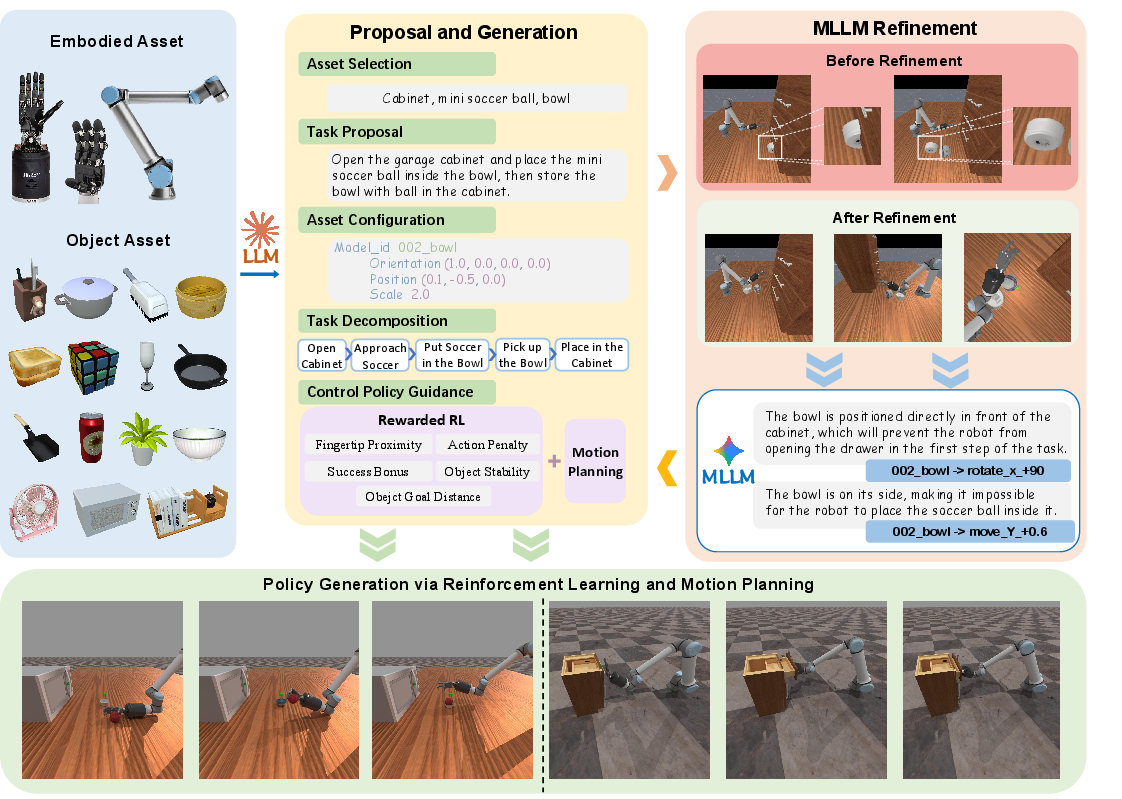
Methods: How does GenDexHand work?
Think of GenDexHand as a smart “level designer” and “coach” for a robot hand inside a virtual world. It works in three stages:
- Stage 1: Propose and Build
- An AI suggests a task based on available objects (for example, “put the apple into the bowl”).
- It builds the scene with those objects, adjusting sizes to be realistic (like making sure a tennis ball fits the hand) and placing items in sensible starting spots.
- Analogy: It’s like creating a new level in a game—choosing the room, props, and where everything goes.
- Stage 2: Refine with Vision
- The scene is rendered into pictures from different camera angles.
- A vision-language AI looks at the pictures and points out problems (e.g., “the microwave is too big” or “the marker pen is intersecting the laptop”). It then suggests exact fixes like “scale the laptop to 50%” or “move the pen by 0.3 meters.”
- Analogy: It’s like having a careful art director who checks screenshots and gives precise edits to make the level look and feel right.
- Stage 3: Generate Robot Motions
- The AI breaks a long task into smaller steps (subtasks). For example: “approach the bottle,” “grasp the bottle,” “lift the bottle.”
- It chooses the right tool for each subtask:
- Motion planning (like a GPS for the robot’s arm) draws a safe path to reach places without collisions.
- Reinforcement learning (trial-and-error learning guided by rewards) handles touch-heavy actions like grasping or rotating.
- To make learning easier, the system sometimes “freezes” certain joints (like keeping the wrist steady) so the robot focuses on the fingers, reducing confusion and speeding up learning.
- Analogy: It’s like first walking to the shelf using a map, then carefully using your fingers to pick up a fragile object with practice and feedback.
Findings: What did they discover, and why does it matter?
The team found several important results:
- Better Scenes: By using the vision-language AI to review and fix the scenes, the virtual tasks became more realistic and physically sensible. Objects were scaled properly and placed logically.
- More Variety: The tasks covered many different activities (opening, rotating, placing) and environments, meaning the robot learned a broad set of skills. In plain terms: there’s a lot of different “levels,” not just repeating the same one.
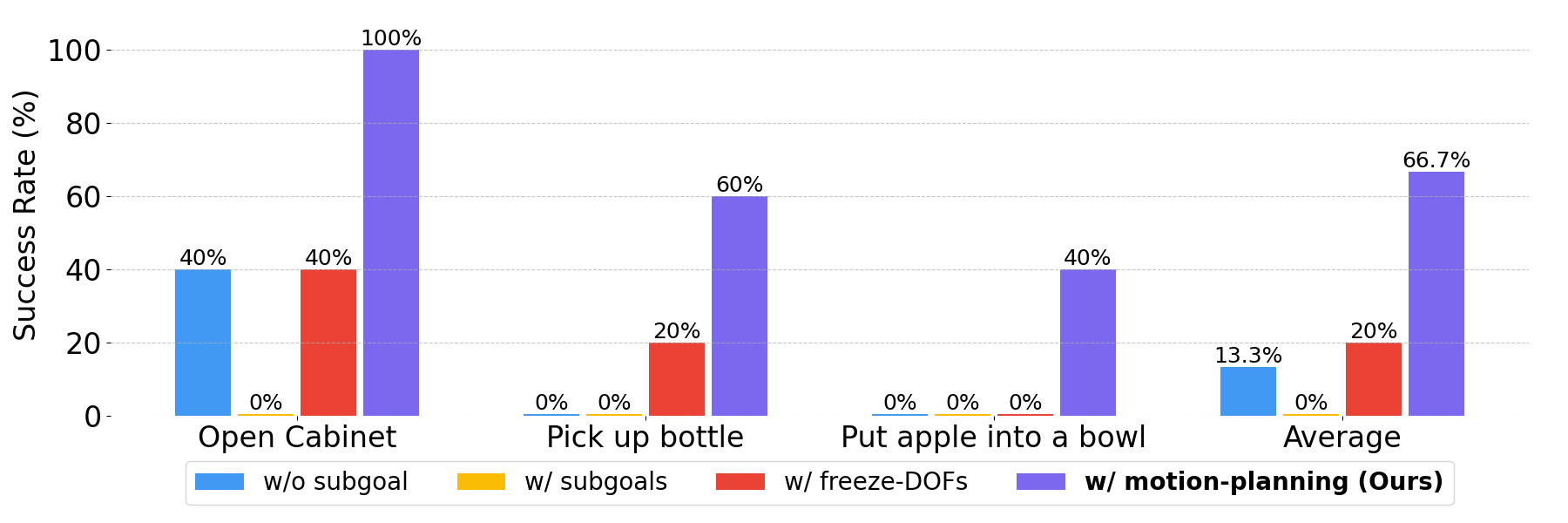
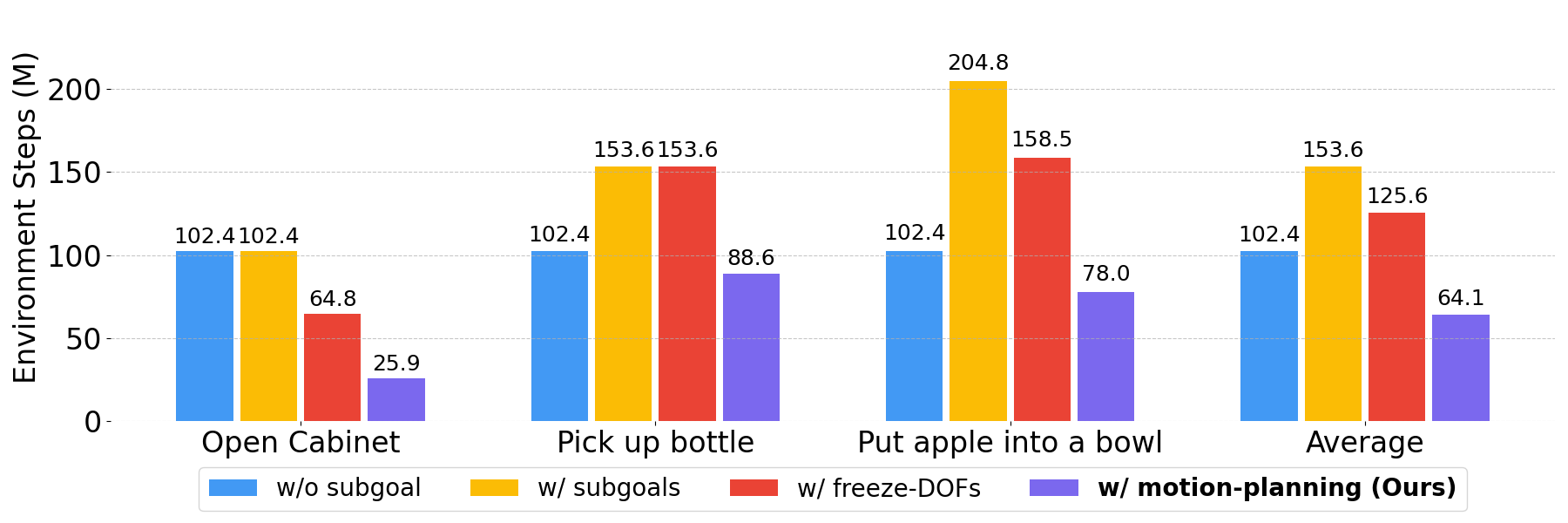
- Faster, More Successful Learning: Breaking tasks into subtasks, freezing unneeded joints, and mixing motion planning with reinforcement learning made training much more effective. Across their tests, success rates improved on average by 53.4%.
- Practical Examples: For tasks like “Open Cabinet,” “Pick up Bottle,” and “Put the Apple into the Bowl,” the structured strategy (decomposing tasks and using both planning and learning) outperformed simple, end-to-end learning. It also reduced the number of simulation steps needed to gather many successful examples.
Why it matters: Robots with dexterous hands can do much more than simple grippers. Making it easier and faster to train them opens the door to real-world tasks that require careful finger control, like opening containers, sorting objects, or operating tools.
Implications: What could this lead to?
- Scalable Training: GenDexHand can generate a huge number of different practice tasks automatically. This helps build large, diverse datasets that are great for teaching robots complex hand skills.
- Better Robot Hands: As robots learn from varied, high-quality simulations, they become more robust and adaptable—closer to how human hands handle everyday objects.
- Foundation for Future Systems: The trajectories produced (the “how-to” motions) can train other learning methods, like imitation learning. Over time, stronger AI models and better training techniques might solve even more challenging, long, multi-step tasks.
- Real-world impact: While this work is in simulation, the methods can guide future real-world training for robots in homes, hospitals, and factories—places where careful, finger-level manipulation matters.
In short, GenDexHand shows how to automatically build realistic virtual practice worlds for robot hands, fix them with smart visual checks, and train the robot using a mix of planning and trial-and-error. It’s a big step toward teaching robots to use their “fingers” with the kind of skill people take for granted.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete future work:
- Sim-to-real transfer is not evaluated; no real-robot validation, no domain randomization strategy, and no analysis of transfer gaps from Sapien to hardware.
- Observation modalities for policy learning are unspecified (e.g., state vs vision vs tactile); robustness under partial observability, noise, and sensor latency is untested.
- Physical parameter calibration after mesh scaling (mass, inertia, friction, restitution) is not addressed; dynamic realism and its impact on policy learning remain unknown.
- The MLLM refinement loop lacks quantitative evaluation: no metrics for scale correctness, interpenetration rate, object pose errors, number of refinement iterations, convergence, or stability across seeds.
- How metric corrections are reliably inferred from images is unclear (e.g., camera intrinsics/extrinsics or scene scale provided to the MLLM?); risks of numerically incorrect adjustments are not analyzed.
- No ablation across different MLLMs/LLMs or prompt designs; sensitivity to model choice, prompting, and temperature remains unquantified.
- LLM-generated rewards and success detectors are not validated for correctness; reward hacking, false positives/negatives in success criteria, and robustness to edge cases are not assessed.
- Subtask decomposition quality and failure modes are unmeasured; there is no automatic verification that decompositions yield solvable and well-conditioned subtasks.
- Criteria for freezing degrees of freedom are opaque; optimality, generality across tasks, and automated selection strategies are not studied.
- Hybrid motion planning + RL handoff is not analyzed for continuity (e.g., smoothness, contact stability); motion jitter and discontinuities at subtask boundaries remain unresolved.
- Planner configuration details (collision meshes, planning time budget, success rates, articulated joint constraints) and sensitivity to asset quality are not reported.
- Asset sanitization is ad hoc; no automated pipeline for detecting/fixing mesh defects, self-intersections, broken normals, non-watertight meshes, or incorrect object frames.
- Background realism is added via images/static objects, but the 3D consistency of occluders/obstacles is not validated; impact on policy learning is unknown.
- Task difficulty calibration is limited: evaluation covers only three representative tasks; large-scale benchmarking across many generated tasks with standardized metrics is missing.
- Diversity is measured only via text embeddings; there are no scene/geometry/physics diversity metrics (e.g., distribution of object sizes, contact types, articulation types, friction regimes).
- Comparisons to existing dexterous datasets are limited to semantic diversity; no head-to-head policy performance comparisons on shared tasks or standardized benchmarks.
- Policy learning uses a single algorithm (PPO) with fixed settings; no ablations over algorithms, hyperparameters, curriculum strategies, or reward shaping designs.
- No exploration of hierarchical RL/skills/options, diffusion policies, or model-based RL to tackle long-horizon tasks beyond hand-engineered subtasking.
- Tactile/force feedback and compliant control are absent; their necessity and benefits for contact-rich dexterous skills are not investigated.
- Domain randomization (textures, lighting, dynamics), sim noise injection, and their effects on generalization and robustness are not studied.
- Success metrics are not formally defined per task; reliance on LLM-generated evaluators may bias outcomes; human-verified or programmatic ground-truth benchmarks are lacking.
- Throughput and scalability are unquantified: wall-clock cost, GPU/CPU budget, success/failure rate per pipeline stage, and cost per usable trajectory are not reported.
- The claimed 53.4% success improvement lacks detail: number of tasks, variance, confidence intervals, and precise baselines (e.g., with/without refinement, subtasking, DoF freezing) are not fully specified.
- Hand embodiment generality is untested; adapting to different hand kinematics/actuation and automating retargeting or controller parameterization remains open.
- Articulated object realism (joint limits, friction/stiction, constraint compliance) is not validated; fidelity of interactions with articulated assets is unknown.
- Failure analysis is sparse; there is no taxonomy of common failure modes across generation, refinement, planning, and RL, nor diagnostics to trigger regeneration vs refinement.
- Data release scope is unclear: availability, scale, metadata (rewards, evaluators, asset licenses), task schemas, and reproducible benchmarks are not concretely specified.
- No downstream study shows that the generated trajectories improve imitation learning or VLA policies on external dexterous benchmarks; scaling benefits remain hypothetical.
- Safety/constraints in generated tasks (joint limits, self-collision avoidance, actuator limits) lack formal guarantees; constraint violations are not tracked or penalized.
- Coverage of deformable objects, liquids, or non-rigid contacts is absent; extendability of the pipeline to these regimes is unknown.
- Dependence on closed-source models (Claude, Gemini) challenges reproducibility, cost control, and long-term sustainability; open-model alternatives are not evaluated.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed today by leveraging GenDexHand’s generative simulation pipeline, multimodal refinement, and hierarchical policy learning.
- Synthetic dataset generation for dexterous manipulation
- Sector: robotics (industry), academia
- What: Use GenDexHand to auto-generate large, diverse task scenes (e.g., “open laptop,” “put apple in bowl,” “rotate tennis ball”) and collect successful trajectories at scale to pretrain or fine-tune dexterous policies and imitation learners.
- Tools/Workflow: Sapien simulator + Claude Sonnet (task proposal) + Gemini 2.5 Pro (multi‑view scene QA) + PPO (RL) + OMPL (motion planning); 1024 parallel environments for efficient collection.
- Assumptions/Dependencies: Simulator fidelity, access to MLLM/LLM APIs, high-quality 3D assets (DexYCB, RoboTwin, PartNet-Mobility), compute budget, reward correctness.
- Rapid prototyping of dexterous gripper behaviors for manufacturing and logistics
- Sector: manufacturing, logistics/warehousing
- What: Generate task families for operating knobs, opening drawers, grasping deformable or odd-shaped items; benchmark candidate hand designs and control strategies before building hardware.
- Tools/Workflow: DoF-freezing for finger subsets, subtask decomposition (“approach → grasp → twist”), hybrid RL+planning to achieve a reported average 53.4% success-rate gain.
- Assumptions/Dependencies: Real-to-sim mapping of hand geometry and compliance, sim-to-real transfer strategy, perception stack integration.
- MLLM-in-the-loop scene validation and correction for simulation platforms
- Sector: software tooling, robotics simulation
- What: Integrate the closed-loop generator–verifier to automatically detect and fix object scale, placement, and interpenetration issues from rendered multi‑view images.
- Tools/Workflow: “SceneRefine API” style plugin for Sapien/Unity/ROS; textual directives (Scale_Action, Position_Action, Pose_Action) converted into numeric transforms.
- Assumptions/Dependencies: Reliable MLLM access, accurate mapping from language to geometry, asset licensing.
- Reward and subtask authoring assistant for dexterous RL
- Sector: software/robotics R&D
- What: Use an LLM to draft reward functions and success checks for common dexterous subtasks and to decide when to invoke motion planning versus RL.
- Tools/Workflow: Prompt templates for reward shaping; policy gating (LLM chooses RL vs OMPL); unit tests for reward validity.
- Assumptions/Dependencies: Human-in-the-loop validation for reward correctness; stable LLM behavior.
- Creation of standardized dexterous manipulation benchmarks
- Sector: academia, robotics consortia
- What: Publish curated task suites with diversity metrics (semantic embedding cosine similarity) to compare algorithms across long-horizon, contact-rich skills.
- Tools/Workflow: Task bank managed via configuration files and rendering scripts; automated evaluation harness with success-rate and sample-efficiency metrics.
- Assumptions/Dependencies: Community adoption, reproducible configs, versioning of assets and prompts.
- Sim-first workflow for robotics startups
- Sector: robotics industry
- What: Establish a “Sim-first dexterity pipeline” to iterate task definitions, scene QA, and policy training before pilot deployments.
- Tools/Workflow: CI/CD for simulation jobs; automated collection of 1,000+ successful trajectories per task; policy evaluation dashboards.
- Assumptions/Dependencies: DevOps for GPUs/CPUs, cost controls for LLM/VLM inference.
- Pretraining for teleoperation and assistive manipulation
- Sector: healthcare/assistive robotics
- What: Generate diverse simulated tasks (opening cabinets, twisting lids, placing items) to pretrain policies that can be fine-tuned with teleoperation data.
- Tools/Workflow: Offline trajectory datasets for IL; DoF constraints that mimic human operator skill profiles.
- Assumptions/Dependencies: Mapping from robot-hand policies to teleoperation interfaces; compliance and safety considerations.
- Robotics education and lab curricula
- Sector: education, academia
- What: Use the pipeline to create hands-on labs teaching hierarchical control, motion planning, and RL for dexterous hands.
- Tools/Workflow: Prepared scenes and tasks; student assignments that refine environments and collect trajectories; grading via automated success metrics.
- Assumptions/Dependencies: Classroom compute availability, clear licensing of datasets, simplified setup scripts.
- Internal governance for synthetic data usage
- Sector: policy/compliance within organizations
- What: Draft guidelines for licensing, IP attribution of public 3D assets, and safety gating when moving from sim policies to pilots.
- Tools/Workflow: Policy templates; audit trails on data sources and LLM prompt logs.
- Assumptions/Dependencies: Legal review; alignment with asset licenses (DexYCB, PartNet-Mobility).
Long-Term Applications
The following use cases are plausible with further advances in sim-to-real transfer, tactile sensing, hardware reliability, and regulatory assurance.
- General-purpose household robots with dexterous hands
- Sector: consumer robotics
- What: Train robust multi-finger policies for cooking prep, organizing, operating appliances, and tool use via scaled synthetic data generation.
- Tools/Workflow: Large task banks reflecting domestic contexts; hierarchical control (planning + RL) with DoF constraints; on-device adaptation.
- Assumptions/Dependencies: High-fidelity sim-to-real transfer, tactile sensing, safety certification, affordable hardware.
- Warehouse and e-commerce item handling with multi-finger grippers
- Sector: logistics
- What: Dexterous picking from clutter, opening packaging, bagging and sorting of diverse SKUs trained via simulated complexity and subtask curricula.
- Tools/Workflow: Domain randomization, perception integration; hybrid control for grasp + manipulation; KPI tracking (throughput, breakage).
- Assumptions/Dependencies: Robust perception under occlusion, real-time planning, ROI versus simpler grippers.
- Assistive robots for activities of daily living (ADLs)
- Sector: healthcare/elder care
- What: Dressing assistance, opening containers, feeding, household tasks personalized via synthetic training and patient-specific fine-tuning.
- Tools/Workflow: Patient-specific simulators; IL from teleoperation; safety gates; DoF tailoring to patient environments.
- Assumptions/Dependencies: Clinical trials, regulatory approval, human factors and trust, fail-safe design.
- Surgical and micro-manipulation training
- Sector: healthcare (surgical robotics)
- What: Generate high-precision, contact-rich tasks for microsuturing, instrument handling, and tissue manipulation as pretraining curricula.
- Tools/Workflow: Differentiable physics and tactile models; closed-loop refinement of surgical scenes and tools; hierarchical controllers.
- Assumptions/Dependencies: Extremely accurate physics, validated simulators, regulatory constraints, surgeon-in-the-loop oversight.
- Industrial operation of legacy equipment
- Sector: energy, manufacturing, utilities
- What: Turn valves, press buttons, operate panels and latches with dexterous hands trained on synthetic replicas of plant environments.
- Tools/Workflow: Digital twins of facilities; generative scene variations; RL+planning for safety-critical operation sequences.
- Assumptions/Dependencies: Detailed CAD/scan data, strict safety and reliability requirements, operator acceptance.
- Personalized prosthetics and exoskeleton control
- Sector: healthcare/biomechatronics
- What: Use generative tasks to train and adapt multi-finger control models personalized to a user’s daily routines and strength ranges.
- Tools/Workflow: Subtask decomposition for common activities; user-specific DoF constraints; transfer learning from robot-hand sims to human prostheses.
- Assumptions/Dependencies: Neuromuscular interface quality, cross-domain generalization from robot hands to human biomimetic devices.
- “Generative Simulator-as-a-Service” platforms
- Sector: software/cloud
- What: Offer hosted APIs for task proposal, multi-view scene QA, and policy training for dexterous manipulation.
- Tools/Workflow: SceneRefine API, Dexterous Task Bank marketplace, job orchestration for large batch runs.
- Assumptions/Dependencies: Cloud cost efficiency, stable MLLM/LLM APIs, enterprise integration.
- ROS/MoveIt/OMPL integration: “Dexterity Autopilot”
- Sector: robotics software
- What: A plugin that lets an LLM select planning vs RL per subtask, refine scenes from renders, and enforce DoF freezes for complex manipulation.
- Tools/Workflow: Middleware adapters to simulators and hardware; monitoring and introspection; safety interlocks.
- Assumptions/Dependencies: Reliability of LLM decisions, certification for industrial use.
- Educational consortia and MOOC-scale dexterous robotics curricula
- Sector: education
- What: Cross-institution task banks and labs that standardize training pipelines and benchmarks for dexterous manipulation at scale.
- Tools/Workflow: Shared datasets, leaderboards, reproducible configs, grading harnesses.
- Assumptions/Dependencies: Funding for compute, community standards, asset licensing agreements.
- Standards and governance for synthetic dexterous data and sim-to-real safety
- Sector: policy/regulation
- What: Develop test protocols, deployment gates, and documentation practices for policies trained primarily on synthetic dexterous datasets.
- Tools/Workflow: Benchmark suites, safety checklists, traceable prompt/config logs, model cards for control policies.
- Assumptions/Dependencies: Multi‑stakeholder consensus, regulator involvement, alignment with existing safety norms.
Glossary
- Articulated objects: Rigid objects composed of multiple linked parts connected by joints. Example: "articulated and soft-body objects"
- Closed‑loop refinement process: An iterative generate-and-correct procedure where outputs are evaluated and modified based on feedback to improve quality. Example: "GenDexHand introduces a closedâloop refinement process that adjusts object placements and scales based on visionâLLM (VLM) feedback"
- Collision-free: Describes motion that avoids contact with obstacles. Example: "For subtasks requiring collision-free, point-to-point motion"
- Cosine similarity: A metric measuring the angle between two vectors to quantify similarity, often used on embeddings. Example: "report the average cosine similarity as the diversity metric"
- Degree-of-freedom constraints: Restrictions placed on the controllable joints or movement dimensions to simplify control. Example: "including degree-of-freedom constraints, motion planning integration, and subtask decomposition"
- Degrees of freedom (DoFs): Independent parameters that define a system’s configuration, such as robot joint angles. Example: "the high degrees of freedom (DoFs) inherent to dexterous hands"
- Dexterous hand manipulation: Robotic manipulation using multi-fingered hands capable of complex in-hand and contact-rich tasks. Example: "dexterous hand manipulation tasks"
- DexYCB: A public dataset of 3D object models and hand-object interaction benchmarks for dexterous manipulation. Example: "DexYCB"
- Embodied intelligence: AI systems that perceive, act, and learn within physical or simulated bodies in an environment. Example: "Data scarcity remains a fundamental bottleneck for embodied intelligence."
- End-effector: The terminal part of a robot manipulator that interacts with the environment (e.g., palm). Example: "the end-effector (i.e., the palm's position and orientation)"
- End-to-end policy: A single learned controller that maps observations directly to actions without modular decomposition. Example: "difficult to solve with a single end-to-end policy."
- Foundation models: Large pre-trained models (often multimodal) with broad capabilities transferable to many tasks. Example: "foundation models demonstrate strong capabilities in generating formalized code"
- Gemini 2.5 Pro: A multimodal LLM used for analyzing rendered scenes and suggesting refinements. Example: "we adopt Gemini 2.5 Pro as the multimodal LLM"
- Generative simulation: Using generative models to automatically create simulation environments, tasks, and data. Example: "Generative simulation has recently emerged as a promising direction in robotics"
- Generator–verifier refinement process: A pipeline where one model generates candidates and another verifies/corrects them iteratively. Example: "our framework employs a generatorâverifier refinement process"
- Imitation learning (IL): Learning policies from demonstrations rather than explicit reward optimization. Example: "imitation learning (IL)"
- In-hand object rotation: Manipulation where the object is rotated within the grasp without regrasping. Example: "such as in-hand object rotation"
- LLM: A LLM trained on vast text data, used here for proposing tasks, code, and policies. Example: "LLMs"
- Long-horizon tasks: Tasks requiring extended sequences of coordinated actions, often with delayed rewards. Example: "decompose long-horizon tasks into a sequence of shorter-horizon subtasks"
- Motion planning: Computing collision-free trajectories for robots to reach target configurations. Example: "either motion planning or reinforcement learning"
- Multimodal LLM (MLLM): An LLM that processes multiple modalities (e.g., text and images) for analysis and guidance. Example: "multimodal LLM (MLLM)"
- Parallel-jaw gripping: Grasping using a two-finger, parallel-jaw gripper mechanism. Example: "parallel-jaw gripping"
- Partnet-Mobility: A dataset of articulated 3D objects with part-level mobility annotations. Example: "Partnet-Mobility"
- Reinforcement learning (RL): Learning to act via trial-and-error optimization of cumulative rewards. Example: "Reinforcement learning (RL)"
- Sampling-based motion planner: A planning method (e.g., RRT, PRM) that samples configurations to find feasible paths. Example: "we employ a sampling-based motion planner"
- Sapien: A physics-based robotics simulation platform used for experiments. Example: "We adopt Sapien as our simulation platform."
- Semantic embedding: Vector representations capturing the meaning of text for similarity or clustering. Example: "we employ a semantic embedding-based approach"
- Semantic plausibility: Whether a scene or task configuration makes sense given real-world semantics. Example: "ensure semantic plausibility and physical consistency"
- Sim-to-real transfer: Deploying policies trained in simulation to real-world robots with minimal performance loss. Example: "sim-to-real transfer"
- Soft-body objects: Objects with deformable, non-rigid dynamics. Example: "soft-body objects"
- Sparse rewards: Reward signals that occur infrequently, making exploration and learning harder. Example: "due to vast exploration spaces and sparse rewards"
- Subtask decomposition: Splitting a complex task into simpler, sequential subtasks to ease learning and control. Example: "with and without subtask decomposition"
- Vision‑LLM (VLM): A model that jointly understands visual and textual inputs. Example: "visionâLLM (VLM) feedback"
Collections
Sign up for free to add this paper to one or more collections.

