- The paper introduces an innovative H-shaped architecture that bridges mid-layers of heterogeneous pretrained models to achieve unified multimodal tasks.
- It strategically pairs large LLM/VLM models for understanding with diffusion-based models for generation, effectively reducing modality discrepancies and training costs.
- Empirical evaluations on benchmarks show superior performance in image generation and editing, highlighting efficient semantic alignment and resource optimization.
HBridge: H-Shape Bridging of Heterogeneous Experts for Unified Multimodal Understanding and Generation
Introduction
HBridge introduces a novel architecture to integrate multimodal understanding and generation through heterogeneous experts. The design departs from symmetric paradigms, proposing an asymmetric H-shaped architecture that strategically pairs large pretrained LLMs for understanding with diffusion-based generative models. It optimizes cross-modal fusion by bridging only the intermediate layers while leveraging reconstructive semantic tokens to enhance alignment in generation tasks.
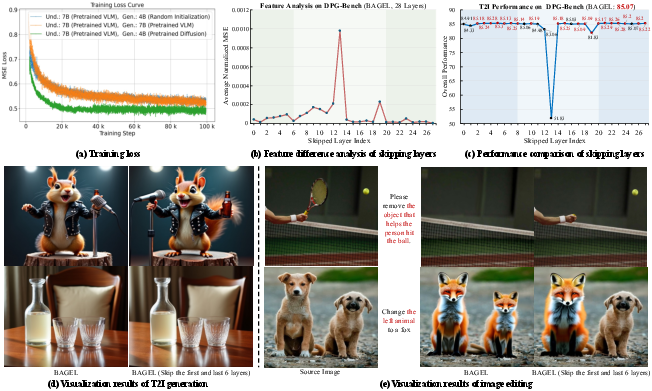
Figure 1: Motivation behind HBridge. The ``H'' refers to Heterogeneous (asymmetric) experts and the H-shape bridging that connects only the mid-layers between experts.
Heterogeneous Expert Architecture
In contrast to the existing Mixture-of-Transformers (MoT) paradigms such as BAGEL and LMFusion, HBridge employs heterogeneous experts to minimize modality discrepancies. Instead of densely sharing attention across all layers, HBridge focuses interaction at mid-layers, reducing unnecessary connections.
The understanding branch initializes from large pretrained LLM/VLM models, while the generative branch comprises a diffusion model, adapted with QKV-Linear alignment modules to harmonize feature dimensions across modalities. This strategic pairing allows effective utilization of pretrained priors specific to each modality, enhancing convergence speed and reducing training costs significantly.

Figure 2: Overview of the proposed HBridge architecture, highlighting the connection of mid-layers and the introduction of semantic tokens.
Mid-layer Semantic Bridge
A key innovation of HBridge is its mid-layer semantic bridge, which reduces attention sharing by over 40% and promotes efficient semantic alignment. The bridging excludes both shallow and deep layer connections, which predominantly capture modality-specific representations. This selective approach enhances cross-modal coherence while avoiding possible overfitting to shallow semantic features from the understanding model.
HBridge also introduces Semantic Reconstruction Tokens that facilitate explicit alignment of generative tasks with ViT-level semantic features, further reinforcing semantic control during text-to-image synthesis.
Empirical Evaluation
Extensive experiments on benchmarks including DPG-Bench and GenEval showcase HBridge's superior performance in image generation and editing tasks, outperforming state-of-the-art models like BAGEL and UniWorld-V1. Despite utilizing fewer generative parameters, HBridge consistently achieves higher scores, indicating its efficient architecture and semantic alignment capability.

Figure 3: Ablation study on initialization manners showing the benefits of pretrained diffusion initialization.
Conclusion
HBridge presents a significant advancement in unified multimodal understanding and generation through its asymmetric expert architecture and strategic mid-layer fusion. Its ability to leverage pretrained priors from heterogeneous models while maintaining task-specific representation highlights its potential for future developments in AI. The modularity of the semantic bridge offers flexibility for adapting the architecture to diverse multimodal tasks, paving the way for more efficient resource utilization and enhanced generative quality.
Given its innovative design and robust empirical results, HBridge sets a new standard in the integration of understanding and generative models, with promising implications for the development of more sophisticated multimodal systems in AI.

