Multimodal Alignment and Fusion: A Survey
Abstract: This survey provides a comprehensive overview of recent advances in multimodal alignment and fusion within the field of machine learning, driven by the increasing availability and diversity of data modalities such as text, images, audio, and video. Unlike previous surveys that often focus on specific modalities or limited fusion strategies, our work presents a structure-centric and method-driven framework that emphasizes generalizable techniques. We systematically categorize and analyze key approaches to alignment and fusion through both structural perspectives -- data-level, feature-level, and output-level fusion -- and methodological paradigms -- including statistical, kernel-based, graphical, generative, contrastive, attention-based, and LLM-based methods, drawing insights from an extensive review of over 260 relevant studies. Furthermore, this survey highlights critical challenges such as cross-modal misalignment, computational bottlenecks, data quality issues, and the modality gap, along with recent efforts to address them. Applications ranging from social media analysis and medical imaging to emotion recognition and embodied AI are explored to illustrate the real-world impact of robust multimodal systems. The insights provided aim to guide future research toward optimizing multimodal learning systems for improved scalability, robustness, and generalizability across diverse domains.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Multimodal Alignment and Fusion: A Survey”
1) What is this paper about?
This paper looks at how computers can understand and combine different kinds of information at the same time—like pictures, text, sounds, and video. This is called “multimodal” learning. The paper explains two big ideas:
- Alignment: making sure information from different sources matches up (for example, that a caption really describes the image it’s paired with).
- Fusion: mixing the matched information together so a system can make better predictions or answers.
It’s a survey, which means the authors read and organized ideas from more than 260 other studies to give a clear map of what works, how it works, and where the field is going.
2) What questions does it try to answer?
The paper focuses on easy-to-understand questions like:
- How can we make text, images, audio, and video line up so computers know they’re about the same thing?
- What are the main ways to combine (fuse) different kinds of data so machines perform better?
- Which model designs work best for different tasks?
- What problems still make multimodal learning hard (like bad data or high computing costs)?
- How are these methods used in real life (social media, medicine, robots, etc.)?
3) How did the authors approach this?
Because this is a survey, the “method” is organizing and comparing lots of past research. The authors set up two simple ways to think about the field:
- By structure (how and where fusion happens in a model):
- Data-level fusion: mix raw inputs (like stacking image pixels and audio waves together) and process them with one model.
- Feature-level fusion: first turn each input into features (compressed, meaningful signals), then combine those.
- Output-level fusion: run separate models for each input, then combine their final answers.
- By technique (what math or model ideas are used under the hood):
- Statistical and kernel methods: classical math tools (like CCA and kernels) to align different data types, including non-linear relationships.
- Graph-based methods: represent things (objects, words, regions) and their relationships as networks to align and fuse them.
- Generative methods: models that learn to create or reconstruct data, which helps them learn shared patterns across modalities.
- Contrastive methods: learn by pulling matching pairs close together (like an image and its caption) and pushing mismatched pairs apart.
- Attention-based methods: models that “pay attention” to the most relevant parts across inputs (for example, the image region that answers a question).
- LLM-based (LLM) methods: treat different modalities as languages and use powerful LLMs to connect and reason across them.
To make this friendlier, think of it like teamwork:
- Alignment is like agreeing on the topic before a group project.
- Fusion is like combining everyone’s notes into one great report.
- Different approaches are different teamwork strategies.
The paper also explains popular model “shapes”:
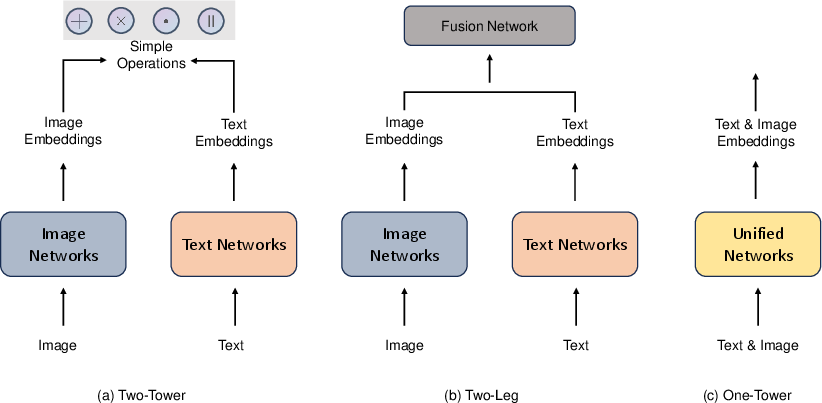
- Two-Tower: separate encoders for, say, images and text, then combine their embeddings (good for retrieval tasks).
- Two-Leg: separate encoders plus a special “fusion” network to mix them deeply.
- One-Tower: a single network that processes everything together from the start (tighter integration).
4) What are the main findings and why do they matter?
From organizing the field, the paper highlights several important points:
- Alignment and fusion are both essential. You usually can’t fuse well if things aren’t aligned first.
- Feature-level fusion often hits a sweet spot: it captures useful patterns without being too simple (like early data mixing) or too late (like only combining final decisions).
- Attention and contrastive learning changed the game. Methods like CLIP learn strong shared spaces for images and text, enabling zero-shot tasks (doing new tasks without training on them).
- LLM-based multimodal models are rising fast. Treating modalities like “languages” and using LLMs to reason across them is powerful for tasks like visual question answering or multimodal conversations.
- Model architecture matters for the task. Two-Tower models shine at retrieval (find the matching picture for a caption). One-Tower or Two-Leg models often do better at complex reasoning (like answering questions about a video).
- Big, diverse datasets help a lot. Datasets like LAION-5B or WIT power large-scale pretraining, leading to better generalization.
- There are major challenges that still need work:
- Misalignment: captions and images don’t always match well.
- Modality gap: images and text can be very different, making it hard to map them into a shared space.
- Computing costs: training giant models is expensive.
- Data quality: web data can be noisy, biased, or low-quality.
These findings matter because better multimodal systems can:
- Understand context more like humans (combining sight, sound, and words).
- Perform better with limited data in one modality by borrowing strengths from another.
- Power real-world tools: safer robots, smarter medical assistants, better content understanding, and more.
5) What’s the impact and what comes next?
This survey gives researchers and developers a clear guide to build stronger multimodal systems. The likely impact includes:
- Smarter assistants that can see, read, and listen—and explain their reasoning.
- Better tools in healthcare (like medical image understanding with reports), education (interactive tutors), and safety (multisensor robots and vehicles).
- More robust models that work across languages, domains, and device sensors.
Going forward, the field will focus on:
- Making models more efficient and scalable so more people can use them.
- Reducing the modality gap and improving alignment so fusion is more reliable.
- Cleaning and curating data to limit noise and bias.
- Designing models that can handle many modalities at once and generalize across tasks.
In short, this paper maps out how computers can combine “multiple senses” to understand the world more deeply—and what we need to do to make that work even better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of missing pieces, uncertainties, and unresolved questions that future research could concretely address:
- Lack of standardized, modality-agnostic benchmarks for alignment quality beyond vision–language (e.g., audio–video, sensor–text, tabular–text), including temporal, streaming, and multilingual scenarios.
- No unified evaluation metrics for “alignment” itself; current practice relies heavily on retrieval R@K or downstream accuracy, which do not directly quantify cross-modal semantic consistency, grounding, or temporal synchronization error.
- Insufficient guidance on when to prefer data-, feature-, or output-level fusion versus method-centric paradigms (contrastive, generative, attention, LLM-based); no decision framework tying task properties and constraints to fusion choices.
- Limited quantitative meta-analysis across methods (e.g., ablation-normalized, compute-normalized comparisons) to separate gains from data scale, architecture depth, and objective choices.
- Sparse coverage of optimal transport–based alignment (e.g., Wasserstein, Gromov–Wasserstein) and manifold alignment methods; open questions on scalability, stability, and when they outperform contrastive objectives.
- Graph-based alignment is only sketched; missing procedures for automatic graph construction, noise-robust edge inference, dynamic graphs for time-varying data, and scaling to large, heterogeneous graphs.
- Kernel methods are treated conceptually; missing empirical comparisons on large-scale settings, automated kernel/parameter selection, approximate kernels for scalability, and handling pre-image ambiguity in fusion pipelines.
- Minimal discussion of probabilistic/Bayesian fusion for uncertainty-aware alignment; open problems include principled uncertainty propagation and confidence aggregation across modalities.
- No framework for calibration and reliability in multimodal systems (e.g., how to compose modality-wise uncertainties, detect overconfidence, and calibrate LLM-based outputs).
- Missing-modality robustness remains underexplored: training/inference-time modality dropouts, imputation, gating, and graceful degradation strategies need systematic evaluation.
- Negative transfer detection and modality conflict resolution are not addressed; when and how to suppress harmful modalities or features remains an open design question.
- Limited treatment of causal perspectives: how to avoid spurious cross-modal correlations, exploit interventions, and learn invariant multimodal representations under distribution shift.
- Temporal alignment at scale is underspecified: beyond DTW-era ideas, how to align asynchronous streams with variable frame rates, lags, and missing timestamps in modern transformer architectures.
- Real-time, streaming, and online adaptation are not covered; open issues include latency-aware fusion, continual learning with modality drift, and on-the-fly re-alignment under changing sensors.
- Few-shot, weakly supervised, and unpaired multimodal learning (e.g., leveraging pseudo-pairs, cycle consistency, or cross-modal self-supervision) need deeper coverage and standard protocols.
- Multilingual and cross-lingual alignment gaps: how to jointly align images/audio with text across diverse languages and scripts, including low-resource and code-mixed settings.
- Domain shift and transfer: limited guidance for adapting alignment/fusion from web-scale data to specialized domains (medical, remote sensing, industrial sensors) with different statistics and constraints.
- Data quality and bias: no concrete protocols to quantify and mitigate dataset biases (e.g., in LAION-like corpora) and their cross-modal amplification through fusion.
- Ethical, legal, and governance aspects are underdeveloped: licensing compliance for web-scale multimodal datasets, filtering harmful content, and auditing cross-modal leakage of sensitive attributes.
- Adversarial and corruption robustness is not delineated: how perturbations in one modality propagate through fusion and how to design adversarially robust, multi-corruption-resilient multimodal systems.
- Safety in LLM-based multimodal systems: open issues on hallucination reduction, cross-modal consistency constraints, refusal policies, and robust grounding for safety-critical tasks.
- Energy, compute, and memory profiling are missing: lack of standardized reporting of training/inference costs, scaling laws for multimodal pretraining, and efficiency–performance trade-offs across methods.
- Edge deployment and compression: open questions on cross-modal pruning, quantization, distillation from multi- to uni-modal students, and maintaining alignment after compression.
- Objective design remains ad hoc: how to balance contrastive, generative, reconstruction, and instruction-tuning losses; curriculum strategies and multi-objective optimization for stable, data-efficient training.
- Interpretability and faithfulness: cross-modal attention maps and learned alignments need validation; research is needed on causal/faithful explanations for fused decisions.
- Benchmark incompleteness for embodied AI: standardized tasks for sensor fusion, sim-to-real robustness, closed-loop control with perception–language–action alignment, and failure analysis are lacking.
- Limited coverage of privacy-preserving multimodal learning: federated training with heterogeneous modalities, secure aggregation, and differential privacy for cross-modal representations.
- Inadequate treatment of annotation economics: strategies to reduce cross-modal labeling costs (active learning, weak signals, programmatic labeling) and measure label quality impacts on alignment.
- Sparse analysis of failure modes and error taxonomies specific to alignment (e.g., spatial mis-grounding, temporal lag, semantic drift) with actionable diagnostics and unit tests.
- Theoretical foundations are thin: need generalization bounds, identifiability conditions for alignment, sample complexity with missing/unpaired data, and convergence guarantees for modern objectives.
- Reproducibility gaps: many surveyed advances rely on proprietary data or incomplete releases; the survey offers no reproducibility checklist (datasets, seeds, compute, hyperparameters, licenses).
- Taxonomy tension remains unresolved: boundaries between structural (early/feature/late) and method-centric taxonomies blur in modern architectures; a unifying formalism or ontology is missing.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the survey’s summarized methods (e.g., Two-Tower retrieval, co-attention feature fusion, early/raw sensor fusion, contrastive and sigmoid losses, LLM-based/One-Tower MLLMs, ImageBind-style emergent alignment) and datasets (e.g., LAION-5B, WIT, RS5M), with sector links, potential tools/workflows, and feasibility notes.
- E-commerce product search and recommendation (image-to-text, text-to-image)
- Sector: software/retail
- Method links: Two-Tower contrastive retrieval (CLIP/ALIGN), feature-level refinement (BLIP, ViLBERT/UNITER co-attention), efficient pretraining via Sigmoid loss
- Tools/workflows: Catalog ingest → image/text embedding index → multimodal query → retrieval/reranking and attribute-aware matching
- Assumptions/dependencies: High-quality image–text pairs, consistent product taxonomies, IP/compliance for web-crawled data, moderate GPU for embedding and indexing
- Social media sentiment, content moderation, and trend analysis
- Sector: media/platforms/policy
- Method links: Feature-level fusion (co-attentional Transformers: ViLBERT/UNITER; FLAVA), output-level ensembles, contrastive pretraining on LAION/WIT, LLM-driven VLMs for reasoning (e.g., LLaVA-style)
- Tools/workflows: Ingestion pipeline for text–image–video → fused classifier for sentiment/toxicity → explanation generation via MLLM
- Assumptions/dependencies: Privacy and consent, fair and representative labels, robustness to adversarial content, policy alignment on moderation criteria
- Accessibility: automatic alt-text and video summarization
- Sector: public sector, education, daily life
- Method links: Generative fusion (BLIP/InstructBLIP), One-Tower MLLMs (e.g., MiniGPT-4-like), attention-based multi-level fusion
- Tools/workflows: CMS/browser plugins that caption images and summarize videos; QA loop with human-in-the-loop validation
- Assumptions/dependencies: Hallucination control and calibration, domain adaptation for specialized content (e.g., scientific figures), legal compliance for accessibility standards
- Medical imaging: assistive report drafting and cross-modal retrieval
- Sector: healthcare
- Method links: Feature-level vision–language fusion (BLIP, LLaVA-Med), output-level reranking for safety, contrastive retrieval for case-based reasoning
- Tools/workflows: PACS integration for text-to-study retrieval, preliminary report generation with structured templates and clinician review
- Assumptions/dependencies: Regulatory approval, curated domain-specific datasets, bias and shift evaluation across sites/scanners, strict data governance (HIPAA/GDPR)
- Autonomous driving perception (camera–LiDAR–radar fusion)
- Sector: robotics/automotive
- Method links: Data-level and feature-level fusion of raw sensor streams (early fusion, YOLO-based joint processing; Two-Leg fusion networks), open radar hardware/software stacks
- Tools/workflows: Real-time detection stack with synchronized camera/LiDAR/radar; cyclist/pedestrian detection in sparse point clouds; on-vehicle deployment with latency budgets
- Assumptions/dependencies: Precise sensor calibration and synchronization, embedded compute constraints, safety validation under edge cases and adverse weather
- Customer support visual troubleshooting and self-service
- Sector: consumer electronics, enterprise support
- Method links: One-Tower MLLMs (vision + language) for VQA; Two-Tower retrieval for FAQ/KB grounding; attention-based fusion for reasoning over steps
- Tools/workflows: Mobile app capturing device photos/video → multimodal Q&A → retrieval-augmented guidance with step-wise instructions
- Assumptions/dependencies: Domain-specific fine-tuning, privacy in user-uploaded media, UX to capture sufficient visual context, robust OCR for small text
- Emotion and affect recognition for driver monitoring and call centers
- Sector: automotive, enterprise CX
- Method links: Tri-modal feature-level fusion (text/audio/video) with hierarchical fusion; datasets like DEAP, CH-SIMS, MuSe-CaR
- Tools/workflows: In-cabin monitoring for drowsiness/stress; real-time call analytics for arousal/valence and agent coaching alerts
- Assumptions/dependencies: Consent and transparency, cultural/linguistic bias mitigation, on-device processing for privacy, accuracy under noisy conditions
- Remote sensing search and annotation (text-to-satellite imagery)
- Sector: energy, public safety, environment, logistics
- Method links: Two-Tower retrieval fine-tuned on RS5M; feature-level fusion for geo-specific descriptors; contrastive loss
- Tools/workflows: GIS plugin enabling text queries (e.g., “solar farms near X”) → candidate imagery retrieval → downstream detection/segmentation
- Assumptions/dependencies: Geographic coverage/recency of datasets, domain-specific noise (clouds/SAR artifacts), human verification for critical decisions
- More efficient pretraining of vision–LLMs
- Sector: ML infrastructure
- Method links: Sigmoid loss for language–image pretraining enabling smaller batches and chunked training at scale
- Tools/workflows: Replace softmax contrastive with sigmoid loss in training scripts; memory-efficient distributed training; rapid domain-adaptive pretraining
- Assumptions/dependencies: Careful temperature/bias tuning; evaluation of calibration and downstream task performance vs. softmax baselines
Long-Term Applications
Below are forward-looking applications that depend on continued research and scaling in multimodal alignment/fusion (e.g., One-Tower MLLMs, Perceiver for arbitrary input types, ImageBind-style emergent alignment across six modalities), stronger safety, and broader datasets.
- Generalist multimodal assistants and home robots
- Sector: robotics/consumer
- Method links: One-Tower MLLMs (PaLM-E, X-LLM), Perceiver-style architectures for arbitrary modalities, ImageBind-like alignment for camera/audio/depth/thermal/IMU
- Tools/workflows: Household task planning from voice + video + sensor feedback; interleaved perception and language-guided control
- Assumptions/dependencies: Reliable grounding and real-world robustness, safety constraints and failure recovery, efficient on-device inference, scalable multimodal data collection
- Multimodal clinical decision support (beyond assistive drafting)
- Sector: healthcare
- Method links: Deep fusion of imaging + EHR text + waveforms; graphical patient trajectory models; attention-based joint reasoning
- Tools/workflows: Triage/diagnosis support, multimodal risk scoring, longitudinal disease modeling
- Assumptions/dependencies: Regulatory trials, interoperable data pipelines (FHIR), causal robustness, rigorous bias and subgroup analysis
- Cross-modal misinformation detection and content provenance
- Sector: policy/media
- Method links: Feature/output-level fusion for cross-checking image–text consistency; contrastive embeddings to detect mismatches; graph alignment to trace source relationships
- Tools/workflows: Newsroom and platform tools to flag incongruities (e.g., image reused with misleading caption), provenance chains across networks
- Assumptions/dependencies: High precision to avoid false positives, clear explainability, policy frameworks balancing moderation and free expression
- Privacy-preserving multimodal analytics for smart cities
- Sector: public sector/smart cities
- Method links: Output-level fusion of on-device models (edge AI), federated learning with modality dropout, replacement of RGB with thermal/IMU (ImageBind) for privacy
- Tools/workflows: Traffic and crowd analytics, anomaly detection, incident triage using minimal personally identifiable information
- Assumptions/dependencies: Edge hardware investment, robust federated optimization under heterogeneous sensors, legal/privacy mandates and citizen acceptance
- Education: multimodal tutors and assessments
- Sector: education
- Method links: One-Tower MLLMs analyzing handwriting, speech, and video; attention-based reasoning over steps; interleaved inputs (TextBind-style)
- Tools/workflows: Feedback on problem-solving processes, lab experiment evaluations via video/sensor data, personalized guidance
- Assumptions/dependencies: Student privacy and parental consent, fairness across demographics, offline/on-device options for low-resource settings
- Finance: multimodal fraud and risk detection
- Sector: finance
- Method links: Kernel-based fusion of structured transactions + unstructured documents + call audio; graphical models for entity networks; contrastive alignment of heterogeneous evidence
- Tools/workflows: Case triage dashboards combining multimodal signals with interpretable explanations
- Assumptions/dependencies: PII protection and auditability, adversarial robustness, regulatory acceptance and model governance
- Scientific automation and lab co-pilots
- Sector: R&D
- Method links: Graph-based alignment of protocols and video demonstrations; Perceiver to ingest vision + sensor streams; LLM planning with embodied execution
- Tools/workflows: Procedure verification from video, error detection, and automated documentation; few-shot generalization to new instruments
- Assumptions/dependencies: Standardized instrumentation interfaces, safety interlocks, large curated multimodal corpora of protocols and experiments
- Creative design and multimodal generation workflows
- Sector: media/design/software
- Method links: TextBind-like coupling of LMs to diffusion models; interleaved multimodal I/O for iterative conditioning (sketch + brief → draft → refinement)
- Tools/workflows: Product mockups and storyboards from sketches, spoken briefs, and reference images; constraint-aware design assistants
- Assumptions/dependencies: IP and licensing of training data, controllability and style fidelity, safeguards against harmful/brand-inconsistent outputs
- Energy and industrial IoT: predictive maintenance and control
- Sector: energy/manufacturing
- Method links: Data-level fusion (Perceiver) of IMU/vibration/audio/thermal streams; kernel-based fusion for heterogeneous sensor integration; attention-based anomaly detection
- Tools/workflows: Plant-wide monitoring with fused signals, cross-modal root-cause suggestions, autonomous shutdown triggers with human oversight
- Assumptions/dependencies: Reliable sensor placement and calibration, operation under extreme conditions, validated control-loop safety and false-alarm management
These applications reflect the survey’s core insights: (1) robust multimodal alignment (contrastive, kernel, graph, generative, and attention-based) is foundational to downstream value; (2) structural choices (data-/feature-/output-level fusion; Two-Tower vs. One-Tower) map to deployment constraints (compute, latency, explainability); and (3) feasibility hinges on data quality/coverage, computational budgets, governance and privacy frameworks, and careful evaluation for bias, safety, and generalization.
Glossary
- Attention mechanism: A neural mechanism that enables models to focus on the most relevant parts of input sequences by weighting elements dynamically. "especially since the introduction of attention mechanisms and the Transformer"
- Canonical Correlation Analysis (CCA): A statistical method that finds linear projections of two datasets that are maximally correlated. "However, CCA can only capture linear relationships between two modalities, limiting its applicability in complex scenarios involving non-linear relationships."
- Contrastive learning: A representation learning paradigm that brings semantically similar pairs closer while pushing dissimilar pairs apart in an embedding space. "Aligns image and text via contrastive learning on large-scale data."
- Contrastive Loss: An objective function that optimizes embeddings by increasing similarity for positive pairs and decreasing it for negative pairs. "Contrastive Loss (and Variants), commonly used in tasks such as image-text matching, aims to pull together semantically similar pairs while pushing apart dissimilar ones in the embedding space."
- Cross-Entropy Loss: A classification loss measuring the divergence between predicted probabilities and true labels. "- Cross-Entropy Loss, a widely used classification loss, calculates the divergence between predicted and true probability distributions, enabling label-driven learning across modalities."
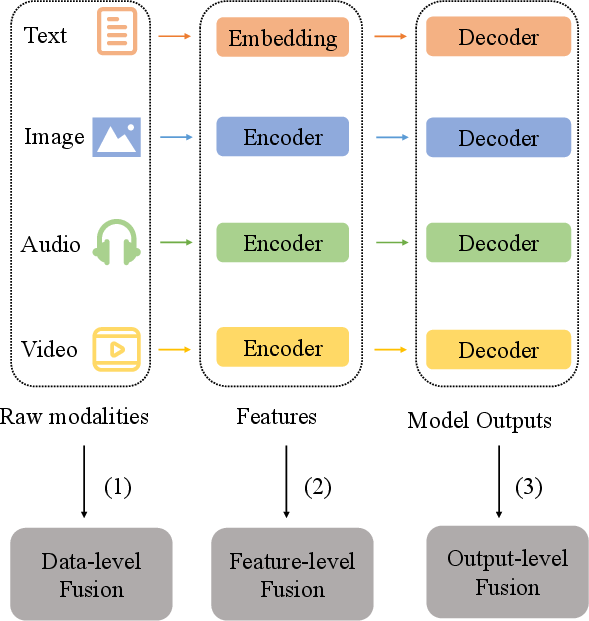
- Data-level fusion: Fusion strategy that directly combines raw multimodal inputs before any feature extraction. "Data-level Fusion: directly combines raw data from multiple modalities;"
- Deep Canonical Correlation Analysis (DCCA): A deep learning extension of CCA that captures nonlinear correlations between modalities via neural networks. "deep canonical correlation analysis (DCCA) further improved upon the original CCA method"
- Dynamic Time Warping (DTW): An algorithm for aligning two sequences by nonlinearly warping their time axes to minimize distance. "DTW measures the similarity between two sequences by finding an optimal match through time warping, which involves inserting frames to align the sequences"
- Encoder–decoder architecture: A model design where an encoder maps inputs to a latent representation and a decoder reconstructs outputs from it. "From structural perspectives, a multimodal model typically involves an encoder that captures essential features from the input data and compresses them into a compact form, while the decoder reconstructs the output from this compressed representation"
- Emergent alignment: The phenomenon where modalities align in a shared space without explicit pairwise training due to indirect binding. "Achieves 'emergent alignment' for unseen modality pairs without direct training, enabling zero-shot cross-modal retrieval and classification."
- Feature-level fusion: Fusion strategy that integrates features extracted from each modality before downstream processing. "Feature-level Fusion: integrates encoded features from each modality;"
- GraphAlignment: An algorithm for aligning nodes across graphs to identify correspondences under an evolutionary model. "The GraphAlignment algorithm, based on an explicit evolutionary model, demonstrates robust performance in identifying homologous vertices and resolving paralogs, outperforming alternatives in specific scenarios"
- Hidden Markov Model (HMM): A probabilistic model of sequences with hidden states emitting observable outputs. "through a multi-stream Continuous hidden markov model (HMM) outperformed individual features and equal-weight combinations."
- Hybrid fusion: Fusion approach that combines early (feature-level) and late (output-level) fusion strategies. "hybrid approaches that integrate both strategies \cite{zhao_deep_2024}"
- Image-Text Matching (ITM): A pretraining task to predict whether a given image and text correspond to each other. "Pioneered MLM, MRM, and ITM tasks, setting the standard for subsequent VLP models."
- Kernel Canonical Correlation Analysis (KCCA): A kernelized version of CCA that models nonlinear relationships by mapping data into higher-dimensional feature spaces. "kernel canonical correlation analysis (KCCA) was introduced to handle non-linear dependencies by mapping the original data into a higher-dimensional feature space using kernel methods"
- Kernel trick: A technique that implicitly maps data into high-dimensional spaces via kernel functions to enable nonlinear learning with linear algorithms. "These methods leverage the kernel trick to map data into higher-dimensional spaces, enabling improved feature representation and analysis"
- LLM: A high-capacity neural model trained on massive text corpora to perform diverse language tasks. "LLMs have emerged, such as OpenAI's GPT series"
- Large Vision Model (LVM): A high-capacity visual model pretrained on large-scale image/video data for general-purpose perception tasks. "large vision models (LVMs) have been proposed, including Segment Anything \cite{kirillov2023segment}, DINO \cite{zhang2022dinodetrimproveddenoising}, and DINOv2 \cite{oquab2024dinov2learningrobustvisual}"
- Latent bottleneck: A compact latent array used to aggregate and process inputs efficiently within a transformer architecture. "Uses asymmetric cross-attention to fuse raw inputs into a latent bottleneck."
- Masked Language Modeling (MLM): A pretraining objective where some tokens are masked and the model learns to predict them from context. "Pioneered MLM, MRM, and ITM tasks, setting the standard for subsequent VLP models."
- Masked Region Modeling (MRM): A vision-language pretraining objective where masked image regions are predicted to learn visual semantics. "Pioneered MLM, MRM, and ITM tasks, setting the standard for subsequent VLP models."
- Modality gap: The discrepancy in representation or statistical properties across different modalities that hinders alignment and fusion. "critical challenges such as cross-modal misalignment, computational bottlenecks, data quality issues, and the modality gap"
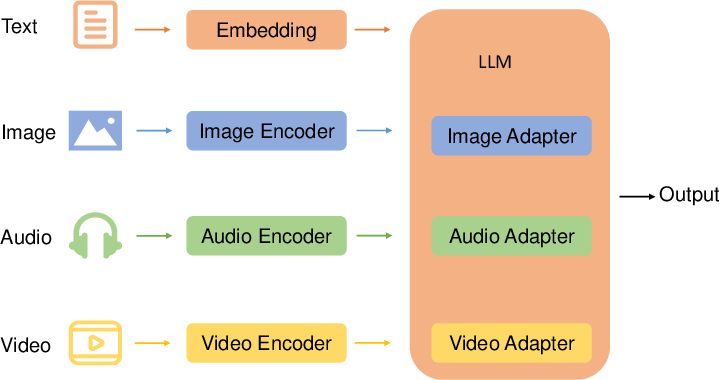
- Multimodal LLM (MLLM): An LLM augmented to process and reason over multiple modalities such as text, images, audio, and video. "leading to the emergence of a new field called multimodal LLMs (MLLMs)."
- One-Tower: An architecture that jointly encodes all modalities within a single unified network. "One-Tower: utilizes a unified network to jointly embed image and text inputs."
- Output-level fusion: Fusion strategy that combines outputs (e.g., predictions) from modality-specific models. "Output-level Fusion: fuses outputs from individual modality decoders to produce a final result."
- Q-Former: A query-based transformer module that maps visual features to a LLM-friendly representation. "Combines feature-level fusion (Q-Former mapping) and output-level fusion (LM to Stable Diffusion)."
- Reconstruction Loss: A loss function that encourages models to reproduce inputs from latent representations, aiding robustness and alignment. "- Reconstruction Loss, used in autoencoders and multimodal fusion tasks, aims to reconstruct input data or mask noise, making models more resilient to modality-specific distortions."
- Set cross-entropy: A variant of cross-entropy tailored for prediction over sets, allowing multiple correct targets. "variants such as set cross-entropy offer greater flexibility for multimodal tasks by handling multiple target answers"
- Sigmoid Loss: A binary classification-based loss for language-image pretraining that decouples batch normalization from softmax. "- Sigmoid Loss~\cite{zhai2023sigmoidlosslanguageimage} proposes a simplified and more efficient alternative to the softmax-based contrastive loss used in models like CLIP."
- Support Vector Machine (SVM): A margin-based classifier used for tasks such as multimodal retrieval with kernel-based fusion. "Verma and Jawahar demonstrated that multimodal retrieval could be achieved using support vector machines (SVMs)"
- Transformer: A neural architecture based on self-attention that excels in sequence modeling across modalities. "especially since the introduction of attention mechanisms and the Transformer"
- Two-Leg: An architecture with separate encoders whose embeddings are combined via an explicit fusion network. "(b) Two-Leg \cite{Allaire2012FusingIF,Badrinarayanan2015SegNetAD,danapal2020sensofusion,Guo2023AMF,Jaiswal2015LearningTC,Li2020HierarchicalFF,Li2018DenseFuseAF,Mai2019DivideCA,Makris2011AHF,Missaoui2010ModelLF,Rvid2019TowardsRS,Steinbaeck2018DesignOA,Uezato2020GuidedDD,Wei2021DecisionLevelDF,kim_vilt_2021}: combines separate image and text embeddings using a Fusion Network;"
- Two-Tower: A dual-encoder architecture that processes modalities separately and combines their embeddings with simple operations. "(a) Two-Tower \cite{radford_clip_2021,jia2021ALIGN,liang2024multimodal,vasilakis2024instrument,xu2023bridgetower,su2023beyond,du2023touchformer,chen2024mixtower,fei2022towards,wen2024multimodal,tu2022crossmodal,yuan2021medication}: processes images and text separately, combining embeddings through simple operations (add, multiple, dot product and concatenate);"
- Zero-shot classification: Performing classification on new categories without task-specific training by leveraging aligned multimodal representations. "supporting open-domain generation and robust zero-shot classification tasks"
Collections
Sign up for free to add this paper to one or more collections.