Hyper-Bagel: A Unified Acceleration Framework for Multimodal Understanding and Generation
Abstract: Unified multimodal models have recently attracted considerable attention for their remarkable abilities in jointly understanding and generating diverse content. However, as contexts integrate increasingly numerous interleaved multimodal tokens, the iterative processes of diffusion denoising and autoregressive decoding impose significant computational overhead. To address this, we propose Hyper-Bagel, a unified acceleration framework designed to simultaneously speed up both multimodal understanding and generation tasks. Our approach uses a divide-and-conquer strategy, employing speculative decoding for next-token prediction and a multi-stage distillation process for diffusion denoising. The framework delivers substantial performance gains, achieving over a 2x speedup in multimodal understanding. For generative tasks, our resulting lossless 6-NFE model yields a 16.67x speedup in text-to-image generation and a 22x speedup in image editing, all while preserving the high-quality output of the original model. We further develop a highly efficient 1-NFE model that enables near real-time interactive editing and generation. By combining advanced adversarial distillation with human feedback learning, this model achieves ultimate cost-effectiveness and responsiveness, making complex multimodal interactions seamless and instantaneous.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Hyper-Bagel, a way to make big AI models that handle both text and images much faster without losing quality. These models can understand mixed inputs (like a paragraph with pictures) and also create images from text or edit existing images. The problem is they can be slow and expensive to run. Hyper-Bagel speeds up both “understanding” and “generation” at the same time.
What questions did the researchers ask?
- Can we make one unified system that speeds up both reading/understanding mixed text–image content and creating/editing images?
- Can we do it without hurting the model’s quality or accuracy?
- Can we make it fast enough for near real-time use (like instant image edits while you type), but still keep results looking great?
How did they do it?
They used a “divide-and-conquer” approach with two different accelerations, one for understanding and one for generation. Think of it like a newsroom:
- A fast draft writer speeds up reading and writing, while a careful editor checks the work.
- A better printing press makes the final pictures come out crisp, but with fewer steps.
Speeding up understanding: speculative decoding (the “draft-and-check” trick)
When AI writes or reads step-by-step (predicting the next token), it can be slow. Speculative decoding speeds this up by:
- Training a small “draft” model that quickly guesses several next tokens in a row.
- The big “target” model then checks those guesses in one go (like batch fact-checking).
- If the guesses are good, we accept them and skip ahead—saving time.
Challenges with multimodal models:
- The AI isn’t just reading words. It also “reads” visual pieces (image tokens) and special image-related data. These tokens look very different from text tokens, so the draft model can easily get confused.
Fixes they added:
- A smarter “intermediate layer” that gathers helpful signals from many layers of the big model using attention (like giving the draft writer better notes).
- Special weight “zero-initialization” and skip-connections so training starts stable and learns faster.
- A balanced training loss that combines two ideas: match the big model’s full probability distribution (soft labels) and also learn from the most likely answer (hard label). This makes learning easier for the small draft model.
Result: The speed of understanding more than doubled (over 2x), with the main model’s quality kept intact because it still verifies the draft.
Speeding up generation: diffusion distillation (fewer “cleaning” steps)
Image generators often work like this: start with noisy “static” and gently clean it over many steps to form an image. Fewer steps = faster, but it’s hard to keep quality.
Two key terms:
- NFE (Number of Function Evaluations): Roughly, how many “cleaning” steps the model runs. Fewer NFEs means faster generation.
- CFG (Classifier-Free Guidance): A knob that controls how strongly the image should follow the text (and, in editing, how much to stick to the original image).
They built two fast versions:
- A “lossless” 6-NFE model: Just 6 steps, but keeps the same quality as the slow original.
- A super-fast 1-NFE model: Only 1 step, for near real-time use. It’s a bit less detailed, but very responsive.
How they trained these fast models (in simple terms):
- Stage 1: Teach the model to understand control knobs (like text guidance and image guidance) in one pass so users can still tune how strongly prompts are followed. This keeps “control” intact.
- Stage 2: Improve overall structure using an adversarial teacher (a “critic” that spots fake images). A special multi-head critic checks images at multiple scales so things like layout and shapes stay correct.
- Stage 3: Match the original model’s image “path” using ODE-based training (called DMDO). This avoids images looking too smooth and brings back rich details and colors, while keeping the same sampler as the original model.
For the 1-NFE model, they added two more steps:
- Stage 4 (ADP): Use the 6-NFE model as a strong teacher to shape the 1-NFE model’s basic structure via adversarial training in the “flow” space, so one-step still places objects correctly.
- Stage 5 (ReFL): Use a reward model (a smart judge built on a vision-LLM) to prefer images people like. This polishes color, detail, and overall appeal with human-like feedback.
What did they find?
- Understanding speed: More than 2x faster when reading and generating tokens, thanks to speculative decoding with their improved intermediate layer and training tricks.
- Image generation:
- 6-NFE model: About 16.67x faster for text-to-image, with “lossless” quality compared to the original slow model on the GenEval benchmark.
- 1-NFE model: Near real-time; still competitive with other top models, though with some trade-offs in fine detail.
- Image editing:
- 6-NFE model: About 22x faster, also “lossless” on the GEdit-Bench benchmark in both English and Chinese—outputs look virtually the same as the original slow model.
- 1-NFE model: Very fast and strong for interactive edits; tiny drops in photorealistic details, but still highly usable.
In short:
- 6-NFE = same quality, huge speedup.
- 1-NFE = instant feedback, slightly less detail.
Why is this important?
- Faster and cheaper: Running big multimodal models is expensive. Hyper-Bagel makes them much more efficient without hurting quality (for 6-NFE), and fast enough for instant creative work (for 1-NFE).
- Better user experience: Near real-time editing and generation make interactive tools (like “edit this photo as I type instructions”) feel smooth and responsive.
- Practical deployment: The approach keeps understanding and generation strong at the same time, which is important for unified “all-in-one” AI assistants that read, write, see, and create.
- Flexible control: Users can still tune how strictly the model follows the text or preserves the original image in edits—important for practical workflows.
Key takeaways
- Hyper-Bagel accelerates both reading/understanding and image creation/editing within one unified framework.
- Speculative decoding + smarter training makes token processing over 2x faster.
- Multi-stage distillation produces a “lossless” 6-step image model (16.67x–22x faster), and an ultra-fast 1-step model for real-time use.
- Quality stays high, control stays flexible, and the system becomes much more practical for everyday creative and multimodal tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future researchers could address.
- Speculative decoding generality: Demonstrate and quantify acceleration on unified multimodal models beyond BAGEL (e.g., other architectures with different tokenizers, latent formats, or interleaving schemes), to show the approach is not teacher-specific.
- Hardware/stack dependence: Report speedups across diverse inference stacks and hardware (e.g., Triton/Transformers/FlashAttention vs. SGLang; A100, H100, consumer GPUs), including tensor-parallel and pipeline-parallel deployments; current results are limited to chain decoding on one A100 in SGLang.
- End-to-end latency accounting: Provide wall-clock latency and throughput for full multimodal workloads (including speculative validation overhead, KV-cache management, and diffusion branch interaction), not just Tokens Per Second or acceptance statistics.
- Batch-size and context-length sensitivity: Characterize speedup and acceptance under varying batch sizes, long contexts, and heavily interleaved sequences (text→image latent→text), which are common in real usage.
- Acceptance dynamics across modality transitions: Measure draft acceptance length/rate conditioned on transitions among text tokens, ViT tokens, clean latents, and (where present) noisy latents; verify whether certain transitions systematically degrade accuracy.
- Draft model capacity vs. gains: Systematically ablate the number of draft decoder layers (
N), hidden sizes, and vocabulary tying to quantify the trade-off between acceptance length and draft compute/memory overhead. - Intermediate layer design details: Provide complete specifications for meta-query count (
Q), dimensionalities, attention heads, and positional encodings in the proposed cross-attention aggregator; quantify memory footprint and inference overhead of this intermediate block. - Initialization strategy robustness: Validate zero-init plus residual design across multiple teacher models and sequence distributions; study training stability and convergence if pre-trained layers differ or are partially missing.
- Loss function ablation depth: Explore alternative mixtures of forward/reverse KL, focal losses, temperature scaling, and label smoothing; the current
KL + λ·CEchoice is only lightly probed. - Speculative tree variants: Compare chain decoding to tree-based speculative strategies (EAGLE-2-like dynamic trees, beam-style drafts) for multimodal sequences; quantify benefits or pitfalls in acceptance and compute.
- Cross-modality grounding impacts: Assess whether speculative decoding affects cross-modal grounding quality (e.g., pointer alignment to image regions, OCR tokens, spatial references) in long, interleaved reasoning.
- Understanding task coverage: Beyond freezing the understanding branch, verify no regressions on broader VLM benchmarks (MMMU, MMBench, OCR-heavy tasks, multi-image dialogues), not just the acceptance metrics.
- Deployment-weight swapping overhead: Quantify practical costs of switching between distilled generation weights and original understanding weights in live systems (I/O, memory mapping, cache invalidation), and measure real-world end-to-end speed gains.
- CFG distillation scope: Justify and test the selected text image guidance scale ranges (text: 1–5; image: 1.0–2.5); analyze sensitivity to wider/extreme scales, negative CFG, and per-layer injection alternatives.
- CFG effectiveness evaluation: Provide quantitative adherence-vs-fidelity curves showing how the single-pass CFG embeddings reproduce control across timesteps, especially for editing consistency and prompt obedience.
- DMDO generalization across samplers: Show whether Distribution Matching Distillation via ODE holds for other ODE solvers (e.g., Heun, RK methods) and schedulers; assess transfer to SDE sampling at inference if needed.
- Training stability and cost of DMDO: Report training time, GPU hours, memory utilization, and failure modes (e.g., collapse, artifacts), since trajectories are reused and regularizers are removed compared to DMD/DMD2.
- Multi-head discriminator specifics: Detail the architecture (heads, receptive fields, strides), training schedules, and ablations; compare against single-head or feature pyramid designs to isolate contributions to structural integrity.
- Progressive vs. one-shot segmentation in TSCD: Verify that skipping progressive distillation does not hurt edge cases; provide controlled comparisons and failure analyses for complex compositions or fine-grained geometry.
- Resolution and aspect ratio robustness: Evaluate distillation at higher resolutions (e.g., 4K as in PixArt-Σ) and diverse aspect ratios; confirm “lossless” claims beyond 1024×1024 with detailed fidelity metrics.
- Domain coverage of generation data: Quantify generalization from Midjourney-heavy JourneyDB (synthetic prompts) to real-world prompts and photographic distributions; examine style bias and mode collapse risks.
- Editing benchmarks breadth: Extend evaluation to localized edits (masked/region-specific), structural swaps, compositing, and exemplar-based edits; GEdit-Bench coverage may miss fine-grained, localized constraints.
- Multi-turn interleaved editing evaluation: Although multi-turn editing data is used for training, provide explicit multi-turn evaluation metrics (consistency across turns, cumulative drift, instruction adherence over 3–5 turns).
- 1-NFE fidelity gaps: Characterize classes of failures (missing small objects, typography errors, texture blur), and quantify where ReFL helps or fails; provide actionable guidance on when to prefer 6-NFE vs. 1-NFE in production.
- Reward model alignment risks: Investigate reward hacking, prompt overfitting, and semantic misalignment when using VLM-based HPSv3; compare to ensembles or multi-signal rewards (aesthetics, CLIP, safety) and study robustness.
- Cross-lingual performance beyond EN/CN: Test prompt adherence and editing quality across more languages and scripts (e.g., Arabic, Devanagari, Cyrillic, CJK typography) and OCR-heavy instructions.
- Safety, fairness, and content filters: Evaluate the acceleration framework’s interaction with safety filters (NSFW, harmful content), demographic fairness, and bias amplification under faster sampling regimes.
- Energy and carbon footprint: Report training and inference energy metrics for 6-NFE and 1-NFE models; quantify environmental trade-offs for adopting the acceleration framework at scale.
- Reproducibility assets: Release or document full training hyperparameters (optimizers, LR schedules, timestep shifts), code, checkpoints, and dataset curation details; the paper currently omits critical reproducibility specifics.
- Integration with external controls: Examine compatibility and performance with ControlNet-like conditional modules, LoRA adapters, and compositional controls (depth, pose, segmentation) under few-step generators.
- Robustness to adversarial/perturbation prompts: Stress-test speculative decoding and few-step generation against adversarial instructions, noisy inputs, and out-of-distribution captions; document defensive strategies.
- Scalability to video/audio modalities: Extend the unified acceleration to spatiotemporal tokens (video) and audio; characterize token interleaving effects on speculative acceptance and few-step distillation for non-image modalities.
- Theoretical understanding of acceptance in multimodal drafts: Develop formal analysis linking modality heterogeneity, embedding space mismatch, and draft acceptance rates; provide predictive models to guide draft design.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Hyper-Bagel’s 2x speedup in multimodal understanding and its lossless 6‑NFE/near-real-time 1‑NFE image generation and editing.
- Accelerated multimodal assistants for consumer and enterprise
- Sectors: software, consumer tech, productivity, customer support
- Tools/products/workflows: integrate speculative decoding (draft model + meta-query intermediate layer) to double TPS for multimodal chat; serve generation via 6‑NFE model and use original understanding branch for prefills; use SGLang chain decoding in inference
- Assumptions/dependencies: target model supports interleaved tokens; draft model training and acceptance validation in production; GPU availability (A100-class recommended) for advertised latency
- Real-time text-guided image editing in consumer apps
- Sectors: creative software, social media, mobile photo apps
- Tools/products/workflows: embed the 1‑NFE editor in mobile/desktop UIs for instant “remove object,” “replace text,” “style change” edits with CFG controls; multi-turn conversational editing flows (SEED-Data-Edit style)
- Assumptions/dependencies: 1‑NFE fidelity trade-offs acceptable for consumer use; safety filters and content moderation integrated
- High-throughput content generation for marketing and e-commerce
- Sectors: marketing, retail, advertising, media
- Tools/products/workflows: batch pipelines using 6‑NFE generator to create A/B variants, banners, product visuals with ~16.67x speedup; automatic prompt libraries with CFG ranges for brand consistency
- Assumptions/dependencies: prompt quality; human-in-the-loop review; licensing compliance for training and output usage
- Scalable product image editing and localization
- Sectors: e-commerce, retail platforms
- Tools/products/workflows: API service for background removal, label replacement, language localization (text edits in images) using 6‑NFE editing; workflow orchestration with QC gates
- Assumptions/dependencies: edit accuracy thresholds; audit trails for compliance
- Education: interactive teaching assistants with dynamic visuals
- Sectors: education, training
- Tools/products/workflows: classroom and LMS plugins that generate diagrams, examples, and edited visuals on the fly (1‑NFE for instant feedback, 6‑NFE for print-quality)
- Assumptions/dependencies: pedagogical validation and content accuracy checks
- Research and engineering acceleration for multimodal model development
- Sectors: academia, AI research labs
- Tools/products/workflows: adopt the speculative decoding recipe (zero-init residuals + CE+KL losses) to accelerate other VLMs; reuse the three-stage distillation (CFG→TSCD→DMDO) to compress other diffusion backbones
- Assumptions/dependencies: architectural compatibility (DiT/CFG injection), access to curated datasets (e.g., LLaVA-OneVision, JourneyDB, SEED-Data-Edit), reproducible training
- Cost and energy reduction in AI inference
- Sectors: enterprise IT, sustainability programs
- Tools/products/workflows: replace high-NFE pipelines with 6‑NFE for parity quality and halve understanding inference latency; track compute and carbon metrics before/after
- Assumptions/dependencies: stable performance under production workload; established measurement framework for energy savings
- Synthetic dataset generation and augmentation
- Sectors: computer vision, simulation, autonomous systems
- Tools/products/workflows: use 6‑NFE to scale diverse high-fidelity synthetic images for training; configure CFG to control adherence and diversity; integrate reward-guided selection to match domain preferences
- Assumptions/dependencies: domain gap assessment; ethical and licensing considerations
- Multimedia customer support and content operations
- Sectors: customer service, operations
- Tools/products/workflows: 2x faster multimodal understanding for ticket triage (screenshots, photos + text); quick visual redaction/editing using 1‑NFE for privacy and compliance
- Assumptions/dependencies: secure data handling; guardrails for sensitive content
- AR/VR prototyping with fast visual feedback
- Sectors: AR/VR, design
- Tools/products/workflows: 1‑NFE previews of scene edits and textures during design sessions; 6‑NFE for final assets
- Assumptions/dependencies: device-side acceleration or cloud streaming; acceptable fidelity trade-offs in previews
Long-Term Applications
These applications require further research, scaling, or development (e.g., broader domain validation, hardware adaptation, regulatory alignment).
- Fully real-time multimodal co-creation agents in productivity suites
- Sectors: creative software, collaboration tools
- Tools/products/workflows: conversational agents that understand interleaved inputs and apply live image edits/generation while users talk/type; fine-grained CFG knobs surfacing “adherence vs. creativity” controls
- Assumptions/dependencies: tighter latency budgets across devices; robust streaming memory management; UI/UX polish and safety layers
- On-device deployment (mobile, AR glasses, edge)
- Sectors: consumer hardware, wearables
- Tools/products/workflows: quantized 1‑NFE models with speculative decoding for on-device multimodal experience; minimal-power ODE samplers
- Assumptions/dependencies: model compression, memory footprint, specialized NPUs/accelerators, privacy guarantees
- Fast video generation and editing via extended distillation
- Sectors: media, entertainment, advertising
- Tools/products/workflows: extend ADP and DMDO to video (few-step generators with multi-head temporal discriminators); near-real-time storyboard-to-video and object-level edits
- Assumptions/dependencies: temporal consistency objectives, large-scale video datasets, compute scaling
- Simulation for robotics and digital twins
- Sectors: robotics, manufacturing, logistics
- Tools/products/workflows: rapid generation of synthetic scenes and edited environments for training and planning; CFG-selectable domain parameters
- Assumptions/dependencies: validated domain fidelity (physics, lighting), integration with 3D/physics engines
- Domain-specific reward models for design and compliance
- Sectors: enterprise design, regulated industries
- Tools/products/workflows: replace general HPSv3 with domain-tuned VLM reward models (e.g., pharmaceutical packaging compliance); ReFL to align outputs with strict preferences
- Assumptions/dependencies: curated preference datasets, expert-in-the-loop labeling, model scaling
- Healthcare imaging: synthetic data and de-identification workflows
- Sectors: healthcare, medical imaging
- Tools/products/workflows: accelerated generation of de-identified visuals and synthetic cohorts for training; controlled edits for education
- Assumptions/dependencies: rigorous validation, clinical safety, regulatory approvals (HIPAA, GDPR), domain-specific reward models
- Policy and standards for energy-efficient multimodal AI
- Sectors: public policy, industry consortia
- Tools/products/workflows: establish benchmarks and procurement guidelines privileging few-step and speculative-decode deployments; carbon reporting for AI services
- Assumptions/dependencies: stakeholder consensus, standardized measurement, auditability
- Hardware co-design for diffusion and speculative decoding
- Sectors: semiconductors, cloud infrastructure
- Tools/products/workflows: inference accelerators optimized for few-step ODE samplers and batch validation of speculative drafts; memory-access-aware designs for interleaved KV caches
- Assumptions/dependencies: ecosystem support, software stacks, capital investment
- Trust & safety: watermarking and controllable editing policies
- Sectors: platform governance, security
- Tools/products/workflows: watermarking tuned to accelerated generators; configurable editing controls (limits on removal/insertion) enforced by policy engines
- Assumptions/dependencies: robust watermarking under post-processing, adversarial testing
- Personalized tutoring with dynamic multimodal content
- Sectors: education
- Tools/products/workflows: real-time generation of step-by-step visuals aligned with learner models; conversational edits to adapt difficulty and style
- Assumptions/dependencies: validated learning outcomes, bias and safety review, privacy-preserving telemetry
Glossary
- Acceptance length: The average number of consecutive tokens the target model accepts from a draft model’s speculative predictions. "we present the average acceptance length and acceptance rate 10- with 10 extrapolation steps using chain decoding"
- Acceptance rate (10-α): A metric indicating how often speculative tokens are accepted; here reported with 10 extrapolation steps. "we present the average acceptance length and acceptance rate 10- with 10 extrapolation steps using chain decoding"
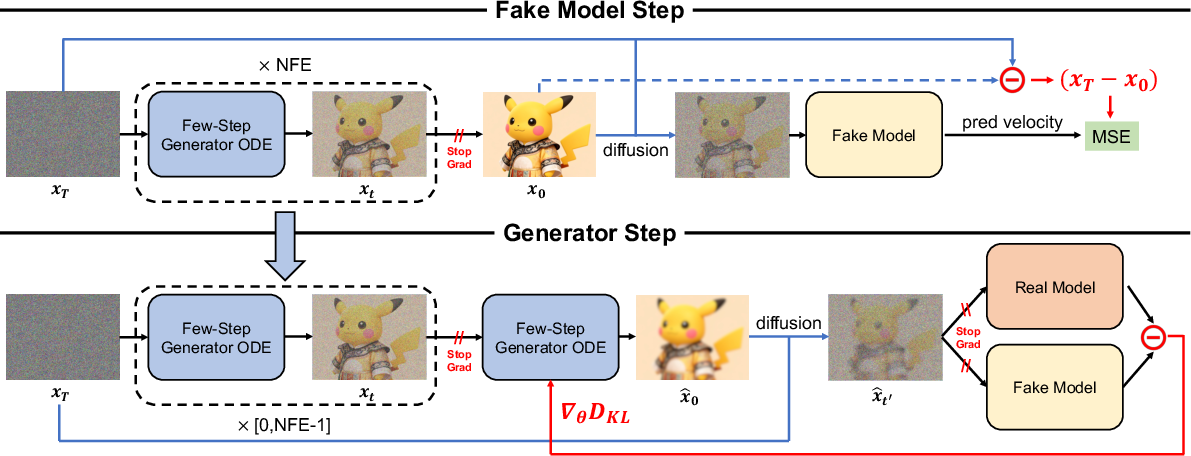
- Adversarial Diffusion Pre-training (ADP): An adversarial training procedure that aligns a faster generator to a stronger teacher using trajectories from diffusion ODEs. "Inspired by the Adversarial Diffusion Pretraining (ADP) proposed by DMDX~\cite{lu2025adversarial}, we utilize an ODE-based objective for adversarial training in the style of rectified flow"
- Adversarial distillation: Training a student generator using adversarial losses against a discriminator to match the teacher’s distribution. "which involves adversarial distillation followed by score distillation"
- Autoregressive decoding: Sequential next-token generation where each token depends on previous ones, often a speed bottleneck. "the iterative processes of diffusion denoising and autoregressive decoding impose significant computational overhead"
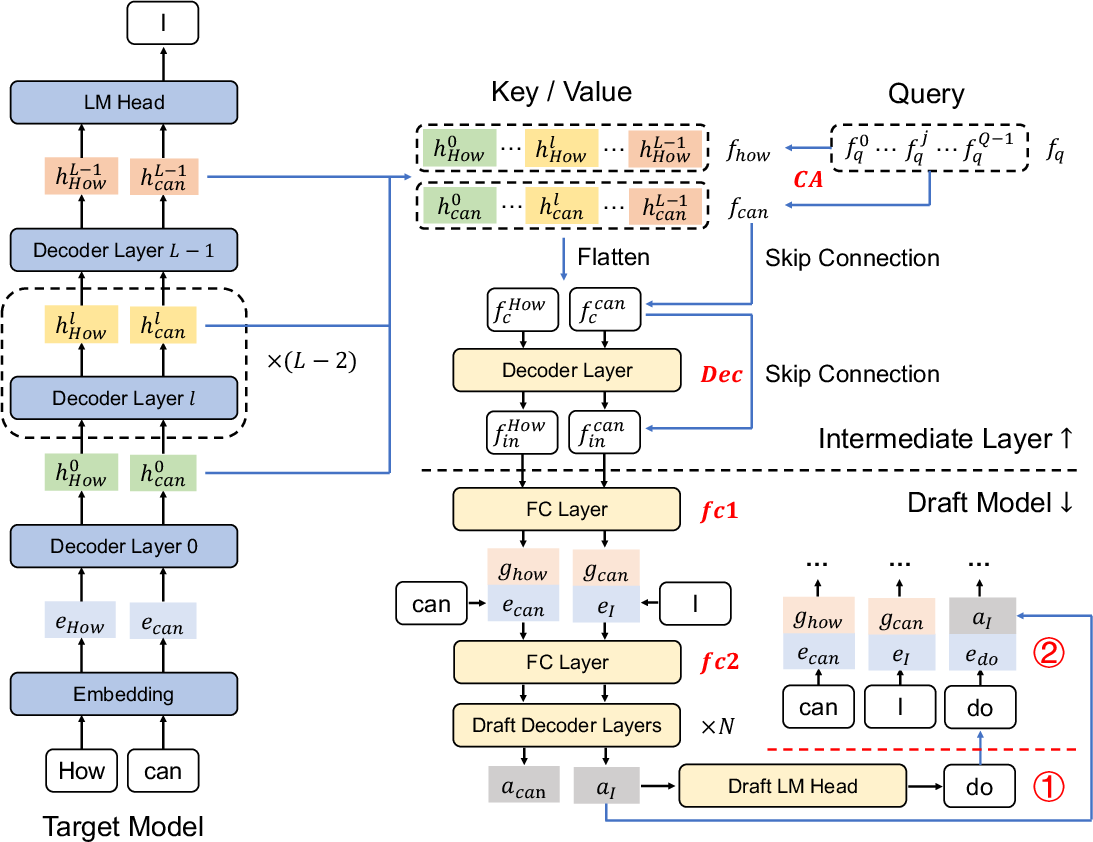
- BAGEL: A unified multimodal model/framework that interleaves text, image, and latent tokens for joint understanding and generation. "BAGEL presents even greater challenges than standard VLMs because it must handle not only text and ViT image tokens but also the clean latent tokens prefilled after diffusion denoising"
- Chain decoding: A speculative decoding strategy that processes sequences in chains to validate multiple predicted tokens efficiently. "with chain decoding on a single A100 GPU"
- Classifier-Free Guidance (CFG): A technique to trade off adherence to conditioning (e.g., text/image guidance) versus sample diversity in diffusion models. "i.e. Classifier-Free Guidance (CFG) control, structural integrity, and image fidelity, each optimized with tailored algorithms"
- Clean latent: The denoised latent representation at the end of diffusion sampling, used to condition further multimodal context. "clean latent tokens prefilled after diffusion denoising"
- Consistency distillation: A distillation method that aligns student outputs across timesteps/segments to consistent trajectories from a teacher. "After CFG distillation, we conduct a similar consistency distillation approach as in our previous work Hyper-SD"
- Consistency sampler: A sampler designed for consistency-model training that can cause oversmoothing under SDE-based setups. "the Stochastic Differential Equation (SDE) based on the consistency sampler in DMD~\cite{yin2023one}"
- Cross-attention: An attention mechanism that uses one sequence as queries and another as keys/values to aggregate information. "as keys and values through cross-attention"
- DiT (Diffusion Transformer): A transformer-based diffusion architecture that injects timestep and guidance signals across layers. "ensuring that control signals can be precisely propagated to every layer of DiT~\cite{peebles2023scalable}"
- Diffusion denoising: The iterative process of converting noisy latents to clean latents during diffusion sampling. "the iterative processes of diffusion denoising and autoregressive decoding impose significant computational overhead"
- Distribution Matching Distillation (DMD): A distillation framework that matches student and teacher distributions for one/few-step generators. "unlike in DMD~\cite{yin2023one} or DMD2~\cite{yin2024improved}"
- Distribution Matching Distillation via ODE (DMDO): A proposed method that uses ODE trajectories and Euler sampling to match teacher distributions without extra regularizers. "we propose a new method called DMDO"
- Draft model: A lightweight model that speculatively predicts multiple tokens to be verified by the target model. "by training a lightweight draft model with fewer parameters and lower computational requirements"
- Euler discrete sampler: A numerical solver for ODE-based diffusion trajectories that mirrors baseline sampling. "employing the Euler discrete sampler"
- Few-step generator: A distilled diffusion model that produces outputs in a small number of function evaluations. "In the few-step generator update step, we reuse the existing trajectories from the fake update step"
- Forward KL divergence: A loss measuring how well a student covers the modes of a teacher’s distribution; often challenging for small draft models. "using forward KL divergence as the loss function to cover all modes may be overly challenging for a draft model with very limited capacity"
- GenEval: A benchmark for evaluating text-to-image generation quality and adherence. "maintaining equivalent performance on GenEval~\cite{ghosh2023geneval} and GEdit-Bench~\cite{liu2025step1x} metrics compared to the baseline model"
- GEdit-Bench: A benchmark for evaluating image editing quality and semantic consistency. "maintaining equivalent performance on GenEval~\cite{ghosh2023geneval} and GEdit-Bench~\cite{liu2025step1x} metrics compared to the baseline model"
- Human preference alignment: Aligning model outputs to human judgments using a reward model. "followed by human preference alignment using Reward Feedback Learning (ReFL)~\cite{xu2024imagereward}"
- Hyper-Bagel: The paper’s unified acceleration framework for multimodal understanding and generation. "we propose Hyper-Bagel, a unified acceleration framework designed to simultaneously speed up both multimodal understanding and generation tasks"
- Hyper-SD: A prior framework using trajectory-segmented consistency and adversarial/score distillation to accelerate diffusion. "The latter two stages are similar to the previous Hyper-SD~\cite{ren2025hyper}, which involves adversarial distillation followed by score distillation"
- Image fidelity: The richness of detail, color vibrancy, and realism in generated images. "structural integrity, and image fidelity, each optimized with tailored algorithms"
- Interleaved multimodal tokens: Mixed sequences of different modality tokens (text, image, latents) within a single context. "as contexts integrate increasingly numerous interleaved multimodal tokens"
- KV cache: Key–value attention states cached during autoregressive decoding; managing them affects speed and memory. "without retaining the KV cache of the noisy latent"
- KL divergence: A divergence measure; here used to describe regularization needs in distribution matching methods. "to counterbalance the KL divergence, unlike in DMD~\cite{yin2023one} or DMD2~\cite{yin2024improved}"
- Latent space: The representation space of encoded images used by diffusion and discriminators. "two different discriminators in the latent space and pixel space"
- Meta queries: Learnable query embeddings used to aggregate multi-layer target features via cross-attention. "we initialize several learnable embeddings as meta queries"
- Multi-head discriminator: A discriminator with multiple heads/scales to better judge realism and structure across resolutions. "the design of a multi-head discriminator, which discriminates between fake and real latents at multiple scales"
- NFE (Number of Function Evaluations): The number of solver steps used in diffusion inference; fewer NFEs mean faster generation. "6-NFE (Number of Function Evaluations)"
- ODE (Ordinary Differential Equation): The deterministic formulation of diffusion’s probability flow used for fast sampling/distillation. "an Ordinary Differential Equation (ODE) employing the Euler discrete sampler"
- Prefill: Inserting tokens or latents into the model’s context prior to decoding without keeping all caches. "the clean latent after each diffusion denoising is incorporated into the context via prefill"
- Probability flow: The ODE-derived trajectories representing the evolution from noise to data in diffusion models. "to sample several probability flows as training data"
- Rectified flow: A training objective that straightens probability flow paths to accelerate generation. "for adversarial training in the style of rectified flow"
- ReFL (Reward Feedback Learning): A method to fine-tune generators based on a learned reward signal reflecting human preferences. "Reward Feedback Learning (ReFL)~\cite{xu2024imagereward}"
- Score distillation: Training that uses score information (gradients of log-density) to align student outputs with a target. "which involves adversarial distillation followed by score distillation"
- SDE (Stochastic Differential Equation): The stochastic diffusion formulation; certain samplers under SDE can oversmooth outputs. "the Stochastic Differential Equation (SDE) based on the consistency sampler in DMD~\cite{yin2023one}"
- SGLang: An inference environment/framework used to measure TPS performance. "in the SGLang~\cite{zheng2024sglang} environment"
- Skip connections: Residual connections that aid gradient flow and feature reuse in deep networks. "add skip connections for both \verb|CA| and \verb|Dec|"
- Speculative decoding: Accelerated next-token prediction using a draft model whose outputs are validated in parallel by the target model. "we employ speculative decoding~\cite{leviathan2023fast, li2024eagle, cai2024medusa, li2025eagle3scalinginferenceacceleration} by training a lightweight draft model"
- Structural integrity: The global composition and arrangement quality in generated images. "structural integrity, and image fidelity, each optimized with tailored algorithms"
- Student–teacher models: A distillation setup where a student mimics trajectories or outputs of a stronger teacher. "maintain the alignment of the ODE trajectories between the student and teacher models"
- Tokens Per Second (TPS): A throughput metric for decoding speed in language or multimodal models. "achieved only a 1.7x speedup in Tokens Per Second (TPS)"
- Trajectory Segmented Consistency Distillation (TSCD): A consistency-based distillation scheme splitting trajectories into segments. "The 6-NFE model is obtained through three-stage training involving CFG Distillation (\cref{sec:stage1}), TSCD (\cref{sec:stage2}) and DMDO (\cref{sec:stage3})"
- VAE tokens: Tokens produced by a Variational Autoencoder used in multimodal sequences. "since VAE tokens are incorporated into the sequence context"
- ViT tokens: Patch embeddings from a Vision Transformer representing images in tokenized form. "text and ViT image tokens"
- Vision-LLM (VLM): Models that jointly process and understand visual and textual inputs. "Notably, community reproductions on the latest Vision-LLM (VLM) Qwen3~\cite{yang2025qwen3} achieved only a 1.7x speedup"
- Zero-init: Initializing certain layers to zeros to ease training and stabilize alignment with pretrained targets. "zero-init the last projection layer of both \verb|CA| and \verb|Dec| in the intermediate layer"
Collections
Sign up for free to add this paper to one or more collections.

