- The paper proposes a bifurcated architecture that bridges pretrained MLLMs and diffusion models using patch-level CLIP latents for efficient image generation.
- The method replaces VAE-based latents with native CLIP embeddings, enhancing spatial control and reducing computational overhead.
- Empirical results demonstrate state-of-the-art image reconstruction quality with fewer decoding steps and scalable performance.
Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents
Introduction
The integration of visual generation capabilities into LLMs posits significant computational challenges, primarily due to an LLM's lack of exposure to image representations during pretraining. "Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents" proposes a solution by introducing a framework that merges pretrained multimodal LLMs (MLLMs) and diffusion models through the use of patch-level CLIP image embeddings. These embeddings, aligned with the MLLM's CLIP visual encoder, serve as latent representations that bridge the two model types efficiently, enhancing both training ease and final image generation quality.
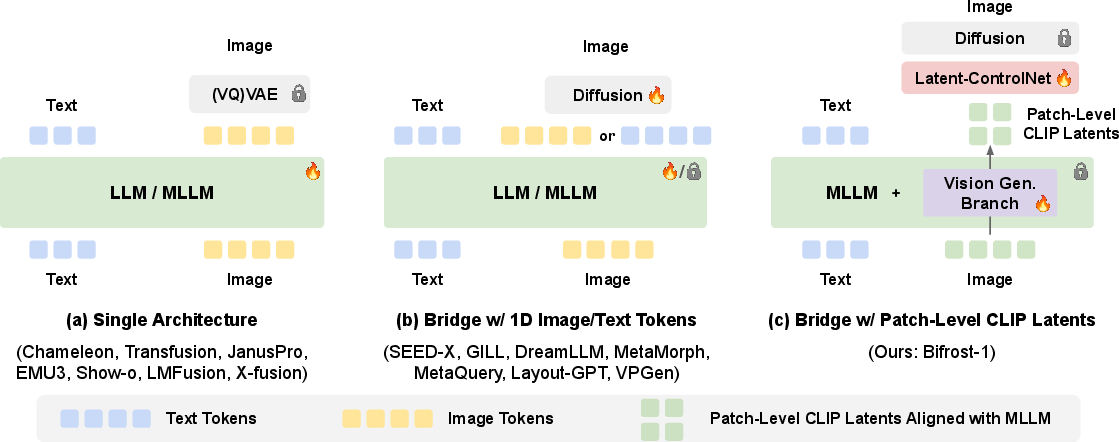
Figure 1: Comparison of different approaches in using LLM for image generation. (a) Single architecture handling both text and image tokens into the LLM/MLLM. (b) Bridging LLM and Diffusion model with a 1D sequence (image tokens or text tokens). (c) Bifrost-1, which bridges MLLM with diffusion models with 2D image tokens aligned with MLLM embeddings.
Framework Overview
Bifrost-1 employs a bifurcated architecture. The framework augments a backbone MLLM with a visual generation branch, consisting of a trainable copy of the MLLM’s parameters and a newly added vision head. The framework utilizes patch-level CLIP image latents, enabling high-fidelity and controllable image generation without significant degradation of the MLLM's existing reasoning capabilities.
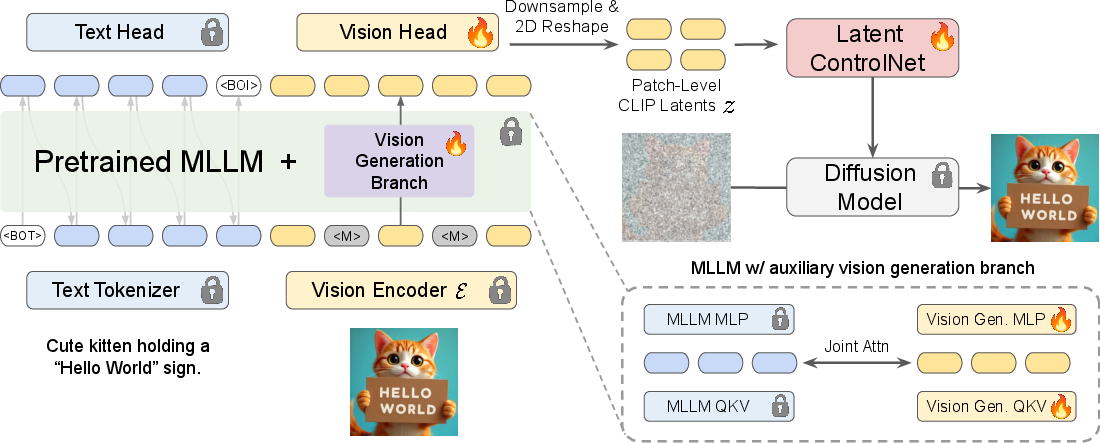
Figure 2: Overview of Bifrost-1, showcasing the integration of visual generation and its guiding role via latent ControlNet.
The visual generation branch is trained to predict masked portions of images, utilizing a downsampling convolution block to prepare these embeddings for input into a latent ControlNet, a lightweight adaptation intended to guide the diffusion model more efficiently.
Implementation Details
Visual Encoder Alignment
The MLLM’s native visual encoder (CLIP) is the linchpin of Bifrost-1, enabling seamless integration through patch-level embeddings. By replacing VAE-based latents with these native embeddings, the system streamlines training, achieving efficient alignment without the need for extensive realignment or recalibration of existing pretrained models.
Latent ControlNet
ControlNet adds structural reinforcement to the diffusion model by embedding spatial controls directly into image generation. By leveraging patch-level CLIP latents as a medium for conveying spatial guidance, the framework maintains consistent multimodal reasoning abilities while improving the fidelity of generated visuals.
Results
Empirical tests illustrate that Bifrost-1 outperforms current unified multimodal models, maintaining or exceeding state-of-the-art benchmarks at a fraction of the computational cost. Bifrost-1 demonstrates excellent scalability and efficiency, evidenced by its superior performance across multiple image reconstruction quality metrics.
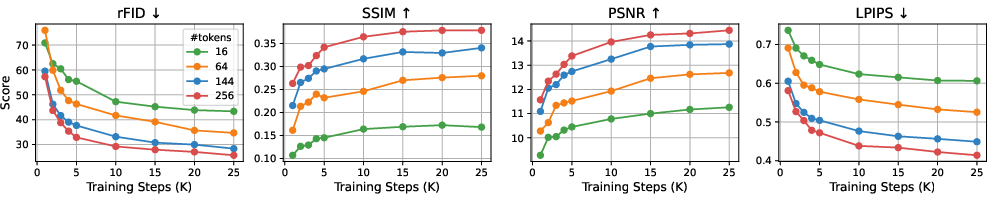
Figure 3: Image reconstruction scores with different numbers of 2D CLIP latent tokens used within Bifrost-1 on ImageNet.

Figure 4: Visual samples for image reconstruction with different numbers of patch-level CLIP tokens, highlighting the visual fidelity achieved.
Comparison with Baselines
Among various architecture choices, patch-level CLIP latents stand out as significantly more efficient than prior methods using learnable query tokens or external encoders. The integration enables substantial improvements in image quality metrics like FID and sFID while reducing the reliance on computationally expensive operations.
Decoding Steps and Efficiency
Crucial to Bifrost-1's application potential is its robust performance across different MLLM decoding step configurations. It maintains high visual output quality with a minimum of 8 decoding steps, thus offering flexibility for inference time-optimized deployments.
Conclusion
Bifrost-1 presents an advanced yet efficient architecture for integrating image generation into multimodal frameworks. By effectively leveraging pretrained models and aligning them with patch-level CLIP visual latents, this framework promises enhanced visual synthesis capabilities whilst preserving the computational efficiency crucial for scalable deployment. Future work can further explore the potential of larger datasets and more advanced MLLM backbones to fully exploit Bifrost-1's architectural advantages.