DeepSeek-OCR: Contexts Optical Compression
Abstract: We present DeepSeek-OCR as an initial investigation into the feasibility of compressing long contexts via optical 2D mapping. DeepSeek-OCR consists of two components: DeepEncoder and DeepSeek3B-MoE-A570M as the decoder. Specifically, DeepEncoder serves as the core engine, designed to maintain low activations under high-resolution input while achieving high compression ratios to ensure an optimal and manageable number of vision tokens. Experiments show that when the number of text tokens is within 10 times that of vision tokens (i.e., a compression ratio < 10x), the model can achieve decoding (OCR) precision of 97%. Even at a compression ratio of 20x, the OCR accuracy still remains at about 60%. This shows considerable promise for research areas such as historical long-context compression and memory forgetting mechanisms in LLMs. Beyond this, DeepSeek-OCR also demonstrates high practical value. On OmniDocBench, it surpasses GOT-OCR2.0 (256 tokens/page) using only 100 vision tokens, and outperforms MinerU2.0 (6000+ tokens per page on average) while utilizing fewer than 800 vision tokens. In production, DeepSeek-OCR can generate training data for LLMs/VLMs at a scale of 200k+ pages per day (a single A100-40G). Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepSeek-OCR, a new system that turns pictures of documents into text very efficiently. The big idea is to use images as a smart way to “compress” long text so that AI models (like chatbots) can handle more information without using tons of computing power. The authors show that a small number of image pieces (called vision tokens) can hold the same information as many more text pieces (text tokens), and the AI can still read it back accurately.
What questions did the researchers ask?
To make the idea simple, think of a long document like a huge puzzle. Each small piece is a “token.” The researchers wanted to know:
- How few image pieces (vision tokens) do we need to rebuild the original text pieces (text tokens) correctly?
- Can we design an image reader (encoder) that handles big, high-resolution pages without using too much memory?
- Will this approach work well on real-world document tasks (like PDFs with text, tables, charts, formulas), and can it be fast enough for practical use?
How does DeepSeek-OCR work?
Imagine a two-part team: a “camera brain” that breaks the page image into meaningful chunks, and a “reading brain” that turns those chunks back into clean text.
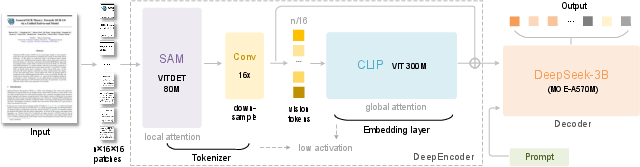
- The camera brain is called DeepEncoder. It has two parts:
- A “window attention” part (like scanning the page through many small windows to find details). This uses SAM.
- A “global attention” part (like stepping back to see the whole page and connect the dots). This uses CLIP.
- Between those two parts, there’s a “shrinker” (a 16× compressor) that reduces how many image tokens need to be handled globally. Think of it as shrinking a big photo while keeping the important details clear enough to read.
- The reading brain is a LLM (DeepSeek-3B-MoE). “MoE” means “Mixture of Experts”: multiple small specialists inside the model each focus on what they’re best at, which makes reading faster and smarter.
To handle different kinds of pages, they trained the system with multiple resolution modes:
- Tiny and Small for fewer tokens (quick scans),
- Base and Large for more detail,
- Gundam/Gundam-M for very big or dense pages (cutting the page into tiles plus a global view, like reading both zoomed-in pieces and the full page).
For training, they used several kinds of data:
- OCR 1.0: regular documents and street/scene text.
- OCR 2.0: tricky things like charts, chemical formulas, and geometry drawings.
- General vision: tasks like captions and object detection to keep some broad image understanding.
- Text-only: to keep the language skills strong.
They trained the encoder first, then the full system, using lots of pages and smart prompts (instructions) for different tasks.
What did they find, and why does it matter?
The results are impressive and easy to understand with a few key numbers:
- Compression power:
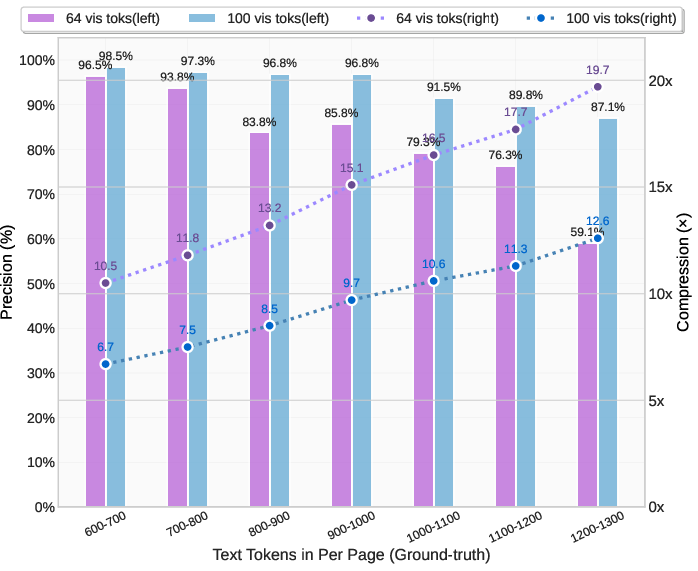
- About 97% accuracy when the text is compressed to within 10× (meaning the number of text tokens is roughly 10 times the number of vision tokens).
- Around 60% accuracy even at 20× compression (much tighter packing).
- Real-world performance:
- On OmniDocBench, an evaluation of document parsing:
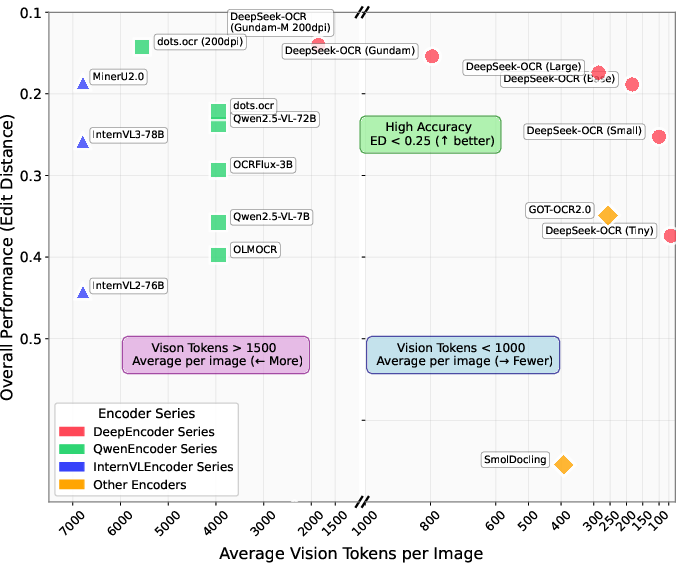
- DeepSeek-OCR beat GOT-OCR2.0 using only 100 vision tokens.
- It also outperformed MinerU2.0 while using fewer than 800 vision tokens (MinerU used nearly 7,000).
- Versatility:
- It can handle not just plain text, but also charts, chemical formulas, simple geometry, and natural images.
- It supports nearly 100 languages for PDF OCR.
- Speed and scale:
- It can generate training data at very large scale (200k+ pages per day on one GPU; tens of millions per day on a cluster), which is valuable for building better AI models.
Why it matters: If AI can compress and read long text using images, then big LLMs can remember more context (like conversation history or long documents) while using fewer resources. That means faster, cheaper, and more capable AI systems.
What could this change in the future?
The paper suggests a new way to handle long-term memory in AI:
- Optical context compression: Turn earlier parts of a long conversation or document into images and read them with fewer tokens. Keep recent parts in high detail, and compress older parts more. This mimics “forgetting” like humans do: older memories become fuzzier and take less space, but important recent ones stay sharp.
- Better long-context AI: With smart compression, AI could handle much longer histories without running out of memory.
- Practical tools: DeepSeek-OCR is already useful—for creating training data, doing large-scale OCR, and parsing complex documents with charts and formulas—while using fewer resources.
In short, DeepSeek-OCR shows that “a picture is worth a thousand words” can be true for AI too. By packing text into images and reading it back efficiently, we can build faster, smarter systems that remember more without slowing down.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions the paper leaves open, formulated to be actionable for future research.
- Lack of theoretical framework: No formal model or scaling law explains why specific compression ratios (e.g., 10×, 20×) succeed or fail, nor how accuracy scales with encoder/decoder capacity, resolution, and token budgets.
- Decoder capacity sensitivity: No experiments vary the decoder size (e.g., 500M, 3B MoE, 7B, 70B) to quantify how larger or smaller LLMs affect the learnability and fidelity of optical compression/decompression.
- Encoder component ablations: Missing ablations isolating contributions of SAM, CLIP, and the 16× convolutional compressor (e.g., remove/replace each, alter attention regimes) to accuracy, memory, and token count.
- Compression factor choice: The 16× token compressor is fixed; there is no systematic study of alternative compression factors (e.g., 8×, 12×, 24×, 32×) and their trade-offs on accuracy, activation memory, and throughput.
- Positional encoding robustness: No analysis of dynamic interpolation of positional encodings across modes (Tiny/Small/Base/Large/Gundam/Gundam-M), including stability, generalization to unseen resolutions/aspect ratios, and failure modes.
- Tiling artifacts and global coherence: The Gundam tiling strategy lacks evaluation of cross-tile context integration, reading order consistency, edge artifacts at tile boundaries, and alignment between local/global views.
- Output format mismatch: Reported Fox benchmark results acknowledge formatting mismatches; there is no standardized evaluation protocol that normalizes layout/format to fairly measure content fidelity (e.g., CER with format normalization).
- Metric coverage gaps: OmniDocBench results use edit distance but omit structure-aware metrics (e.g., HTML validity, table structural F1, LaTeX/MathML correctness, chart semantic fidelity, reading order accuracy).
- Needle-in-a-haystack and retrieval: The proposed context optical compression for dialogue memory is not validated on retrieval-heavy tests (needle-in-a-haystack, factual recall, long-range dependency reasoning).
- Long-context integration: No end-to-end demonstration of compressing conversation histories into images, then decoding on demand in an LLM agent loop; missing policies for when/what to compress and how to manage recency/importance.
- Forgetting mechanism quantification: The “progressive downsizing” forgetting hypothesis is untested; no quantitative curves relate compression ratio vs. recall fidelity, nor user/task-level impact on conversation quality.
- Runtime and cost trade-offs: There is no rigorous comparison of compute, latency, and energy between optical compression and pure text long-context baselines (e.g., attention truncation, retrieval-augmented generation).
- Hardware portability: Performance and memory claims are centered on A100-40G; there is no analysis on consumer GPUs/edge devices (e.g., VRAM footprint, throughput, batch limits, mixed precision stability).
- Token budget scheduler: Absent an automatic policy to allocate vision tokens per document type/content density (e.g., slides vs. newspapers), balancing accuracy vs. compute under dynamic constraints.
- Small-font and low-quality scans: No targeted stress tests on small fonts, low contrast, heavy compression artifacts, skew/rotation, or bleed-through typical in historical/scanned documents.
- Handwriting and cursive: Paper focuses on printed text; robustness to handwritten documents, mixed printed/handwritten content, and cursive scripts remains unexplored.
- Multilingual evaluation depth: Although trained on ~100 languages, systematic per-language accuracy, script-wise failure modes (e.g., Arabic, Devanagari, Sinhala), and low-resource language performance are not reported.
- Minority language annotation quality: The pipeline for minority languages relies on fitz and flywheel with small patches; the label accuracy, noise rates, and their downstream impact are not quantified.
- Tokenizer effects: The 129k vocabulary choice is not analyzed; how tokenization (subword granularity, script-specific vocab) affects “text tokens” counts and compression ratio is unaddressed.
- Reading order guarantees: While edit distance is reported, there is no explicit metric/validation for reading order correctness across complex layouts (e.g., multi-column, footnotes, marginalia).
- Table structure fidelity: Chart/table outputs emphasize edit distance; structure correctness (headers, merges, nested tables, spanning cells) is not evaluated, especially for HTML outputs.
- Chemical/geometry generalization: OCR 2.0 tasks (SMILES, geometry) are synthetic-heavy; robustness to real-world renderings, varied chem drawing tools, noisy scans, occlusions, and complex diagrams is not assessed.
- Chart semantics: HTML-table conversion for charts may lose semantics (axis metadata, units, scales, annotations); there is no benchmark verifying semantic correctness beyond token-level similarity.
- Layout vs. non-layout prompts: The system depends on prompt-controlled outputs; failure modes when prompt is missing/ambiguous and the reliability of prompt-conditioned decoding are not quantified.
- Safety and adversarial robustness: No tests for adversarial images, prompt injection via embedded text, or content spoofing, especially relevant when compressing sensitive long histories.
- Data compliance: Large-scale web/PDF scraping lacks discussion of licensing, privacy, and personally identifiable information handling; downstream implications for training/evaluation use are unclear.
- Benchmark contamination: No audit for possible training-test leakage/contamination from public benchmarks (OmniDocBench, Fox) within scraped or model-generated data.
- Error taxonomy: No fine-grained error analysis by category (characters, spacing, punctuation, math symbols, tables, reading order) across compression ratios to guide targeted improvements.
- General VLM capabilities: Only 20% general vision data is used; the extent to which DeepSeek-OCR supports non-OCR tasks (VQA, grounding beyond simple cases) and the cost of this inclusion is not characterized.
- Joint vs. staged training: SAM and compressor are frozen; the benefits/risks of end-to-end joint fine-tuning (including SAM/compressor) on memory, accuracy, and overfitting are untested.
- Sequence length limits: Training uses 8192 tokens; claims of “theoretically unlimited context” via optical compression are not validated for contexts substantially beyond 8k when decoded back to text.
- Robustness to domain shift: No evaluation on out-of-domain layouts (e.g., legal contracts, medical forms, code listings), heavily templated forms, or multi-modal pages mixing images/equations/flowcharts.
- Governance of secondary model calls: “Deep parsing” depends on secondary calls; orchestration reliability, error propagation, and end-to-end consistency guarantees are not studied.
- Public reproducibility: Despite code/weights release claims, complete data pipelines (annotation scripts, label normalization, preprocessing, sampling strategies) and their reproducibility are not detailed.
- Fair comparison protocols: Some baselines are evaluated at specific dpi/token settings (e.g., 200 dpi); a standardized, reproducible protocol ensuring apples-to-apples token budgets and image preprocessing is missing.
- Practical deployment policies: Guidance for selecting modes (Tiny/Small/Base/Large/Gundam[-M]) in production to meet SLAs (accuracy/latency/cost) is not provided; no auto-tuning or adaptive selection demonstrated.
Practical Applications
Overview
Based on the paper’s findings and innovations—especially the DeepEncoder architecture, multi-resolution modes, demonstrated token compression ratios, multilingual capabilities, and “deep parsing” for charts, geometry, and chemistry—the following practical applications are organized by deployment horizon. Each item includes sector linkages, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Variable-token OCR API for cost-tiered document processing
- Sector: software, enterprise IT, legal, finance, education
- Tools/products/workflows: an OCR microservice exposing preset modes (Tiny, Small, Base, Large, Gundam/Gundam-M); autoscaling and job routing by estimated document token density; layout-aware OCR outputs with coordinates
- Assumptions/dependencies: best accuracy at ≤10× compression; for dense docs (e.g., newspapers) Gundam or Gundam-M mode likely needed; image quality and DPI (200 dpi improves performance); model requires GPU resources; accuracy may vary by document layout and language
- High-throughput document ingestion pipelines (data factories)
- Sector: AI model training, data engineering, cloud services
- Tools/products/workflows: scheduled bulk OCR pipelines converting PDFs/images to text + structured formats; production throughput of ~200k+ pages/day per A100-40G, scaling to ~33M pages/day on 20×8 A100 nodes; output data for LLM/VLM pretraining and RAG
- Assumptions/dependencies: stable GPU cluster; data governance and privacy controls; post-OCR QA and deduplication; storage and indexing of structured outputs
- Layout-aware RAG ingestion
- Sector: enterprise search, knowledge management, developer platforms
- Tools/products/workflows: parsing PDFs into text segments with coordinates; chunking by paragraphs/tables/formulas for precision retrieval; HTML table outputs for charts reduce tokens and unify downstream parsing
- Assumptions/dependencies: consistent prompt usage to select layout/no-layout outputs; mapping coordinates to document canvases; ground-truth alignment differences can affect edit-distance metrics
- Chart-to-table extraction in financial/scientific workflows
- Sector: finance, business intelligence, scientific analysis
- Tools/products/workflows: “deep parsing” of embedded charts to HTML tables; integration with BI tools, time-series extractors, and model-based analytics
- Assumptions/dependencies: chart variety (line, bar, pie, composites) supported; accuracy depends on chart render quality and axis labeling; table postprocessing required for schema normalization
- Chemical diagram-to-SMILES conversion for document mining
- Sector: pharma, chemical informatics, materials science
- Tools/products/workflows: scanning technical docs to extract chemical structures; build or update chemical knowledge bases and downstream property prediction models
- Assumptions/dependencies: quality of input diagrams; symbol disambiguation; domain QA safeguards; RDKit or similar tools for validation
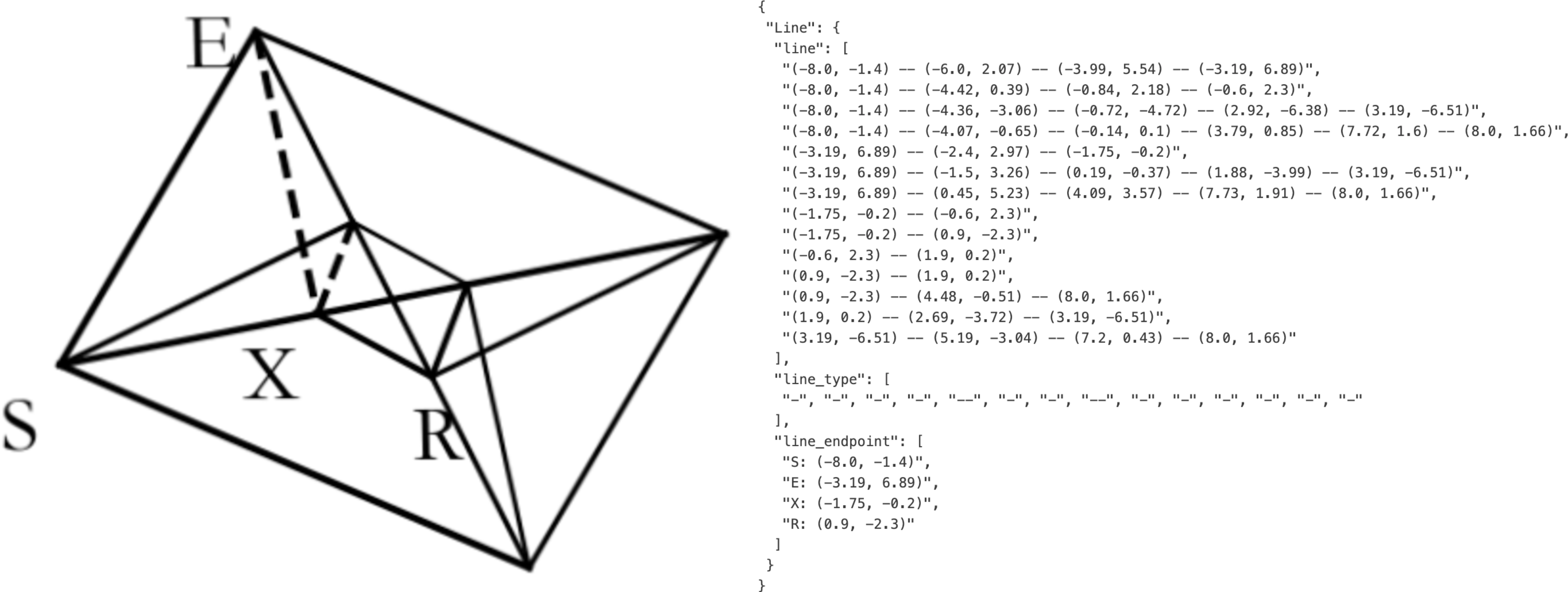
- Geometry-to-JSON parsing for edtech and assessment
- Sector: education, edtech, automated assessment
- Tools/products/workflows: transform textbook diagrams into structured representations (line segments, endpoints, types); auto-grading and problem generation pipelines
- Assumptions/dependencies: reliable performance on simple planar geometry; complex interdependencies still challenging; human review for high-stakes use
- Multilingual document digitization and translation preparation
- Sector: public sector, NGOs, localization, global enterprises
- Tools/products/workflows: OCR across ~100 languages; layout and no-layout formats to feed translation engines; archival and records digitization
- Assumptions/dependencies: language coverage varies by training data; minority languages may need QA; sensitive data requires compliance processes
- Accessibility enhancements (alt text and reading support)
- Sector: accessibility tech, education, publishing
- Tools/products/workflows: generate alt text for embedded images; detect/ground objects in documents; improve screen-reader experiences with structured outputs
- Assumptions/dependencies: general vision capabilities are present but limited; may require completion prompts; postprocessing for consistent alt text quality
- Legal eDiscovery and compliance digitization
- Sector: legal tech, compliance, auditing
- Tools/products/workflows: end-to-end OCR for scanned exhibits and contracts; maintain layout coordinates for provenance; index tables, formulas, and citations
- Assumptions/dependencies: robust QA for evidentiary-grade accuracy; compile chain-of-custody records; alignment with court standards
- Healthcare forms and reports digitization
- Sector: healthcare IT, payers, providers
- Tools/products/workflows: OCR for lab reports, discharge summaries, and older scans; structured extraction of tables and formulas (e.g., labs)
- Assumptions/dependencies: HIPAA/GDPR compliance; domain-specific vocabulary; thorough QA for clinical safety; higher resolution recommended for dense or small text
- Cost-optimized newsroom and archive ingestion
- Sector: media, libraries, archives
- Tools/products/workflows: Gundam/Gundam-M modes for newspapers and magazines (4–5k+ tokens); dynamic tiling with global view for dense pages
- Assumptions/dependencies: device memory planning; DPI scaling; practical trade-offs between speed and accuracy for mass digitization
Long-Term Applications
- Optical context compression for long-memory LLMs
- Sector: consumer chatbots, customer support, coding assistants, autonomous agents
- Tools/products/workflows: render older conversation rounds into images; decode near-losslessly at ~10× compression; apply progressive downsizing to simulate forgetting while retaining recent context fidelity
- Assumptions/dependencies: orchestrator that manages when/how to compress context; accuracy declines beyond ~10×; large-scale pretraining to integrate optical decoding natively into LLMs; UX safeguards for resurfacing important but compressed content
- Progressive memory decay schedulers inspired by biological forgetting
- Sector: AI platforms, agent frameworks
- Tools/products/workflows: tiered compression strategies (recent text as tokens; older text as images at varying resolutions); policies to preserve high-value information while reducing compute
- Assumptions/dependencies: reliable importance scoring; auditability of compressed context; hybrid storage (text + image) standards and observability
- Digital-optical interleaved pretraining regimes
- Sector: foundation model research, AI labs
- Tools/products/workflows: pretrain LLMs/VLMs to jointly encode/decode compressed visual contexts; “picture worth a thousand words” curriculum to optimize token budgets
- Assumptions/dependencies: large-scale, mixed-modality datasets; tokenizer harmonization; evaluation on tasks like needle-in-a-haystack and ultra-long-context QA
- Energy-efficient LLM operations via token-budgeting
- Sector: cloud AI, green computing
- Tools/products/workflows: reduce sequence lengths by offloading older context to vision tokens; measure and optimize wall-clock time and energy usage
- Assumptions/dependencies: careful runtime profiling; stability of latency and throughput under mixed-modal prompts; scheduler integration
- Scientific and regulatory agents that “read” complex docs
- Sector: science (chemistry, materials), regulatory compliance
- Tools/products/workflows: agents that parse charts, chemical diagrams, geometry in publications and standards; generate structured evidence for audits or meta-analyses
- Assumptions/dependencies: reasoning stack on top of OCR; domain-grounded validation; acceptable error rates for compliance contexts
- Mobile/edge OCR for everyday capture (receipts, notes, homework)
- Sector: consumer apps, fintech, edtech
- Tools/products/workflows: optimized variants of DeepEncoder + compact decoders on NPUs; user workflows for snapping and structuring documents on-device
- Assumptions/dependencies: significant model compression/distillation needed; privacy-preserving design; accuracy impacts on low-quality camera inputs
- Standardization and policy for “image-as-context” memory
- Sector: policy, governance, compliance
- Tools/products/workflows: standards around storing compressed conversational context; retention policies, audit trails, and privacy impact assessments
- Assumptions/dependencies: multi-stakeholder consensus; robust redaction and access controls; explainability for compressed memory in regulated environments
- Interactive editors and transformation tools for scanned docs
- Sector: productivity software, publishing
- Tools/products/workflows: edit structured outputs from OCR (tables/formulas/coordinates) directly; “AI copy-paste” across scanned and digital sources
- Assumptions/dependencies: UX for reconciling layout with text; schema-aware editing; collaborative QA and version control
- Robotics and industrial reading
- Sector: robotics, manufacturing, logistics
- Tools/products/workflows: reading labels, instrument panels, and SOP charts; integrate deep parsing to interpret tables or process diagrams
- Assumptions/dependencies: domain tuning (lighting, occlusion, perspective); real-time constraints; safety-critical validation
Key Cross-Cutting Assumptions and Dependencies
- Compression fidelity: near-lossless decoding is demonstrated up to ~10×; accuracy declines above this ratio, necessitating mode switching (e.g., Gundam/Gundam-M) for very dense pages.
- Input quality: DPI and image clarity materially impact performance; 200 dpi interpolation improves results in benchmarks.
- Model configuration: the released model is not a chatbot (no SFT); prompts and formatting control are required to elicit layout vs free OCR outputs.
- Infrastructure: GPU availability is needed for high-throughput pipelines; activation memory is managed via DeepEncoder’s compressor and multi-resolution modes.
- Data governance: privacy, compliance, and QA layers are crucial for regulated sectors (healthcare, legal, government).
- Multilingual coverage: broad but uneven; minority languages may need additional QA or domain adaptation.
- Downstream normalization: structured outputs (HTML tables, JSON geometry, SMILES) typically require schema validation and postprocessing for production use.
Glossary
- 16× token compressor: A module that reduces the number of vision tokens by a factor of 16 to control memory and compute. "a 16 token compressor that bridges between them."
- Activation memory: The GPU memory consumed by intermediate activations during forward/backward passes; a key bottleneck at high resolutions. "offering controllable parameters and activation memory"
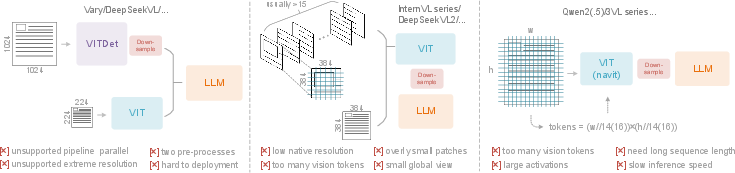
- Adaptive resolution encoding: An encoder strategy that flexibly handles images of varying resolutions without tiling by operating on variable-sized patches. "adaptive resolution encoding represented by Qwen2-VL~\cite{wang2024qwen2}"
- AdamW optimizer: An optimization algorithm with decoupled weight decay commonly used for training deep networks. "using the AdamW~\cite{AdamW} optimizer"
- CLIP: A contrastively trained vision-LLM often repurposed as a vision encoder or feature extractor. "For CLIP, we remove the first patch embedding layer"
- Convolutional downsampling: Reducing token/spatial resolution using strided convolutions to compress representation size. "use a 2-layer convolutional module to perform 16 downsampling of vision tokens."
- Cosine annealing scheduler: A learning-rate schedule that follows a cosine decay (often with restarts) to improve convergence. "cosine annealing scheduler~\cite{loshchilov2016sgdr}"
- Contexts optical compression: Compressing long textual contexts by rendering them into images and processing them as vision tokens. "validate the feasibility of contexts optical compression through this model"
- Data parallelism (DP): Training strategy that replicates the model across devices to process different data shards in parallel. "a data parallelism (DP) of 40"
- Dual-tower architecture: A design with two parallel visual encoders (towers) whose outputs are combined, enabling scalable visual vocabularies. "The first type is a dual-tower architecture represented by Vary~\cite{wei2024vary}"
- Dynamic resolution: Combining multiple native resolutions (e.g., tiled local views plus a global view) to balance detail and memory. "Dynamic resolution can be composed of two native resolutions."
- Edit distance: A sequence-level error metric (e.g., Levenshtein distance) measuring differences between predicted and reference text. "All metrics in the table are edit distances"
- End-to-end: An approach that performs the entire task within a single model without separate detection/recognition modules. "state-of-the-art performance among end-to-end models"
- Global attention: Attention computed over all tokens (dense) rather than within local windows, improving global context modeling. "with dense global attention"
- Grounding: Associating textual descriptions with specific image regions or objects. "tasks such as caption, detection, and grounding."
- Gundam mode: A dynamic-resolution setting combining multiple local tiles with a global view to handle ultra-high-resolution inputs. "Gundam mode consists of n640640 tiles (local views) and a 10241024 global view."
- Mixture of Experts (MoE): A model with many expert subnetworks where a router selects a small subset to activate per token for efficiency. "The decoder adopts a 3B MoE~\cite{liu2024deepseekv2,liu2024deepseekv3} architecture"
- NaViT paradigm: A patch-based variable-size vision transformer design that processes full images without explicit tiling. "adopts the NaViT~\cite{dehghani2023patch} paradigm"
- Next token prediction: The autoregressive training objective of predicting the next token given previous tokens. "use the next token prediction framework to train DeepEncoder."
- Patch embedding layer: The initial projection that converts image patches into token embeddings for transformer encoders. "we remove the first patch embedding layer"
- Patch tokens: Tokenized representations corresponding to fixed-size image patches. "segment it into 1024/161024/16=4096 patch tokens."
- Pipeline parallelism (PP): Splitting different parts (stages) of the model across devices and running them in a pipeline to scale training. "uses pipeline parallelism (PP) and is divided into 4 parts"
- Positional encodings: Signals added to tokens to encode spatial/sequence positions, sometimes interpolated to new resolutions. "dynamic interpolation of positional encodings"
- Prefill: The initial inference phase that processes the full context before token-by-token generation. "prefill and generation phases of inference"
- RDKit: An open-source cheminformatics toolkit used here to render molecular structures as images. "render them into images using RDKit, constructing 5M image-text pairs."
- SAM (Segment Anything Model): A general-purpose segmentation backbone used for perception-oriented visual features. "a SAM~\cite{kirillov2023segment} for perception dominated by window attention"
- Sequence packing: Combining multiple shorter sequences in one long context window during training to improve efficiency. "sequence packing requires extremely long sequence lengths during training."
- SMILES: A text string representation of molecular structures used for chemical formula decoding. "convert them to SMILES format."
- Step-based scheduler: A learning-rate schedule that updates the rate at fixed training steps. "with a step-based scheduler"
- Tile-based method: Processing large images by splitting them into smaller tiles for parallel computation and lower activation memory. "The second type is tile-based method exemplified by InternVL2.0~\cite{chen2024internvl2}"
- Tokenizer: The algorithm/model that converts text into tokens according to a specific vocabulary. "DeepSeek-OCR's tokenizer"
- Vision-LLM (VLM): A model jointly trained on images and text to perform multimodal understanding and generation. "vision-LLMs (VLMs)"
- Vision tokenizer: A component that produces discrete token sequences from images for a language-model-style decoder. "we treat SAM and the compressor as the vision tokenizer"
- Vision tokens: Discrete token embeddings derived from images that serve as the visual input to a decoder. "the fewest vision tokens"
- Vision–text token compression ratio: The ratio of text tokens to vision tokens, indicating how compactly text is represented via images. "vision-text token compression ratios"
- Window attention: Attention restricted to local windows to reduce computation and memory at high resolutions. "dominated by window attention"
Collections
Sign up for free to add this paper to one or more collections.

