Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning
Abstract: Vision-language agents have achieved remarkable progress in a variety of multimodal reasoning tasks; however, their learning remains constrained by the limitations of human-annotated supervision. Recent self-rewarding approaches attempt to overcome this constraint by allowing models to act as their own critics or reward providers. Yet, purely text-based self-evaluation struggles to verify complex visual reasoning steps and often suffers from evaluation hallucinations. To address these challenges, inspired by recent advances in tool-integrated reasoning, we propose Agent0-VL, a self-evolving vision-language agent that achieves continual improvement with tool-integrated reasoning. Agent0-VL incorporates tool usage not only into reasoning but also into self-evaluation and self-repair, enabling the model to introspect, verify, and refine its reasoning through evidence-grounded analysis. It unifies two synergistic roles within a single LVLM: a Solver that performs multi-turn tool-integrated reasoning, and a Verifier that generates structured feedback and fine-grained self-rewards through tool-grounded critique. These roles interact through a Self-Evolving Reasoning Cycle, where tool-based verification and reinforcement learning jointly align the reasoning and evaluation distributions for stable self-improvement. Through this zero-external-reward evolution, Agent0-VL aligns its reasoning and verification behaviors without any human annotation or external reward models, achieving continual self-improvement. Experiments on geometric problem solving and visual scientific analysis show that Agent0-VL achieves an 12.5% improvement over the base model. Our code is available at \href{https://github.com/aiming-lab/Agent0/Agent0-VL}{this https URL}.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Agent0‑VL, a smart computer program that can look at pictures and read text, then figure things out step by step. Unlike many models that depend heavily on people to label right and wrong answers, Agent0‑VL teaches itself to get better over time. It does this by using helpful tools (like calculators or code) not only while solving problems, but also while checking and fixing its own work.
What questions does it try to answer?
To make the ideas clear, here are the main questions the researchers wanted to explore:
- How can a vision‑LLM improve its reasoning without relying on human‑provided labels or external reward judges?
- Can using tools during both “thinking” and “checking” reduce mistakes like visual misunderstandings or math errors?
- Will a model that learns to verify and repair its own steps get steadily better over multiple training rounds?
- Can the model’s “checker” be reused to help other models pick better solutions?
How did the researchers approach the problem?
They built Agent0‑VL with two “jobs” inside one model and a repeated practice loop that helps it learn on its own.
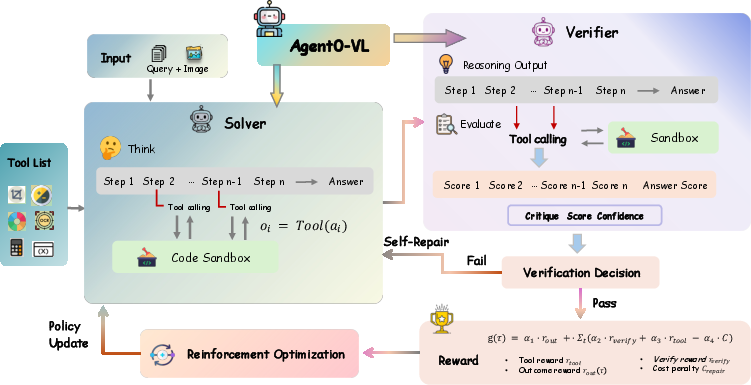
Two roles inside one model: Solver and Verifier
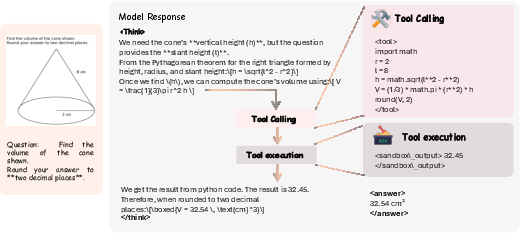
- Solver: Think of this as the student. It reads the question, looks at the image, and works through the solution step by step. If needed, it calls tools—like running simple code, measuring, calculating, or reading values from charts—to make sure the steps are grounded in facts and numbers.
- Verifier: Think of this as a coach. It reviews each step the Solver took, checks facts (also using tools), gives a score for correctness, a confidence level (how sure it is), and a short explanation of what might be wrong. If confidence is low, the Verifier suggests how to fix the mistake.
This setup is like doing homework with a calculator and a measuring tool, then having a coach point out errors and explain how to improve.
Using tools during both thinking and checking
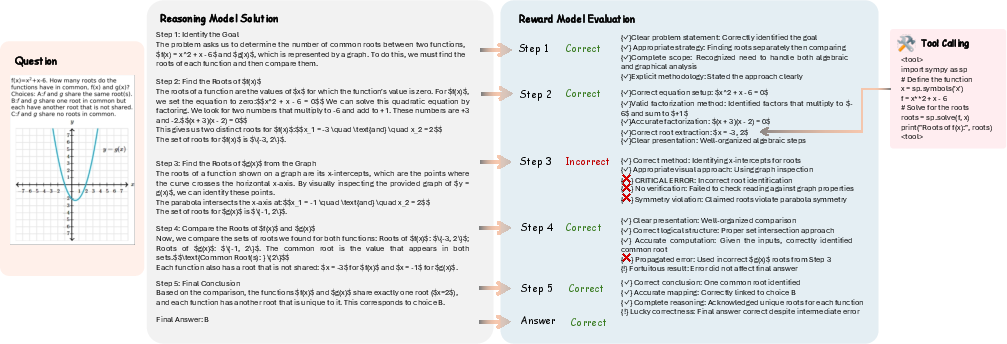
Many models only “think in words” (text) when solving and checking. That can lead to “hallucinations,” where the model guesses something that sounds right but doesn’t match the picture or the math. Agent0‑VL avoids this by:
- Calling tools during solving to compute exact numbers, read chart values, or perform geometry calculations.
- Calling tools during checking to verify each step with real evidence, not just words.
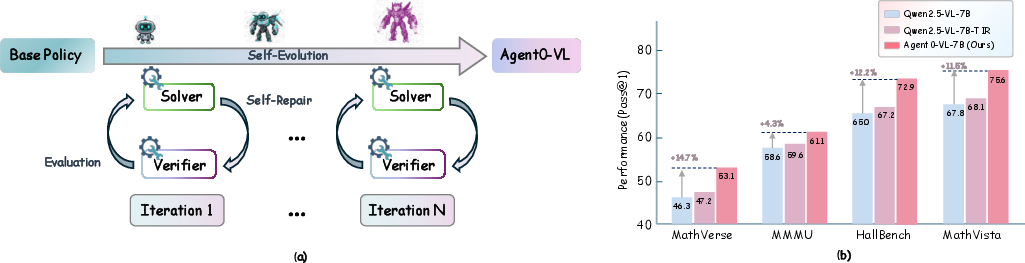
The Self‑Evolving Reasoning Cycle (SERC)
Agent0‑VL trains in two phases and loops through them:
- Warm‑up with supervision (SFT): It learns the basic format of using tools and how to write and check step‑by‑step solutions.
- Practice with self‑feedback (RL): It repeatedly:
- Solves tasks while using tools.
- Verifies each step, scoring correctness and confidence.
- Repairs low‑confidence steps with guided fixes.
- Gives itself “process rewards” based on how correct and well‑verified each step was.
For the RL part, they use something called Group Relative Policy Optimization (GRPO). In simple terms, the model tries many solution paths and then favors those that perform better than the group’s average, while keeping changes stable and safe.
You can think of SERC like training for a sport:
- Inner loop: Practice one routine, get feedback from your coach, fix weak parts.
- Outer loop: Update your overall strategy based on which routines performed better than average.
What did they find?
The model was tested on several visual reasoning benchmarks (like math problems with diagrams, chart reading, and scientific questions). Here’s what stood out:
- Clear performance gains: Agent0‑VL improved about 12.5% over its base model on average. The larger 8B version beat many strong open‑source models and even matched or surpassed closed‑source systems on some tasks (like MathVista, HallusionBench, and ChartQA).
- Steady improvement over iterations: Training in multiple rounds led to consistent gains each time. The model didn’t just get lucky once—it kept getting better.
- Fewer hallucinations: Using tools to check facts reduced mistakes where the answer sounded plausible but didn’t match the image or the math.
- Important parts matter: Removing tool use, the repair step, or the self‑evolving loop made the model worse. This shows each piece—solving with tools, verifying with tools, and repairing low‑confidence steps—works together to boost performance.
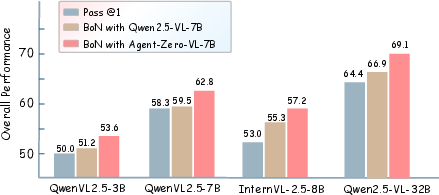
- Useful to other models: The Verifier can be reused as a “process reward model” (a smart scorer of solution steps) to help other vision‑LLMs pick better answers during test time. This gave those models an average 7.3% boost.
Why does this matter?
- Less dependence on human labels: Agent0‑VL shows that a model can keep improving without needing people to label tons of data. That makes training more scalable and affordable.
- More trustworthy reasoning: When a model checks itself using tools, it’s more likely to give accurate answers—especially for tasks involving numbers, geometry, or charts.
- Reusable checks: The Verifier is like a portable coach. Other models can use it to select better solutions, even if they weren’t trained with Agent0‑VL.
Simple takeaways
- Think, check, repair: Agent0‑VL solves problems, double‑checks with tools, and fixes low‑confidence steps. This loop helps it learn from its own mistakes.
- Tools reduce guesswork: Calculators, code, and visual measurements make reasoning concrete rather than just “wordy.”
- Practice makes progress: With repeated self‑guided practice, the model steadily improves across math, charts, and scientific reasoning.
- Shared coaching helps everyone: The Verifier can help other models pick stronger answers, spreading the benefits of careful, tool‑grounded checking.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to be actionable for follow-up research.
- Ambiguity in “zero external rewards”: the training objective includes a final outcome reward (Eq. 7), but the paper does not clarify whether this uses ground-truth answers (external supervision) or is disabled; concrete specification and experiments with vs. are missing.
- Unspecified and sometimes undefined notation and components impede reproducibility (e.g., in Eq. 5, “EE” and “RA” in Algorithm 1, role-gating mechanics, and broken/math typos across equations).
- Confidence calibration is assumed but not validated: the Verifier’s confidence gates repairs, yet no calibration metrics (e.g., ECE/Brier score), reliability diagrams, or temperature-tuning procedures are reported; robustness of gating under distribution shift remains unknown.
- Repair penalty design () is under-specified: how “unnecessary repairs” are detected, how penalty magnitudes are chosen, and their sensitivity to task/domain are not analyzed.
- Tool selection policy is underspecified: how the agent chooses which tool to call, when to call, and how to sequence multi-tool pipelines (e.g., solver vs. verifier tool orchestration) lacks formalization and ablation.
- Tool inventory and capabilities are unclear for vision tasks: beyond “Python code,” the paper does not detail vision-specific tools (e.g., OCR, detection, segmentation, chart parsers) or their APIs, coverage, accuracy, and error modes.
- Robustness to tool failures/noise is not evaluated: the agent’s behavior under erroneous, delayed, adversarial, or missing tool outputs is unstudied; failure injection and recovery strategies are absent.
- Safety and security of tool execution are not addressed: no sandboxing, resource isolation, permission controls, or mitigations against malicious code/data returned by tools are described.
- Data decontamination is unreported: the SFT dataset sources include known benchmarks (e.g., MM-Eureka, Retool) and possibly overlaps with evaluation sets; there is no contamination audit, split-level isolation, or leakage analysis.
- Reliance on “GPT-5” and Qwen2.5-VL-72B as teachers is opaque: teacher model configurations, availability, prompt templates, and quality checks for auto-generated trajectories are not provided; reproducibility and licensing are unclear.
- Compute, efficiency, and cost are not quantified: the overhead of multi-turn tool calls, verifier passes, self-repair loops, and RL iterations (wall-clock time, GPU hours, memory, tool latency) is not reported; sample efficiency studies are absent.
- Reward hacking risks are not assessed: alignment between Solver and Verifier distributions could incentivize superficial agreement; there is no adversarial analysis of reward exploitation, mode-collapse, or shortcutting (e.g., language priors masquerading as tool-grounding).
- Convergence and stability lack theoretical or empirical guarantees: GRPO with dual roles has no formal convergence analysis; long-horizon evolution (>3 iterations), oscillations, or catastrophic forgetting of perception are untested.
- Limited evaluation domains: tasks focus on math, charts, and hallucination; generalization to other modalities (video, audio), embodied or interactive environments (robotic control, web navigation), or real-world noisy settings is untested.
- No comparison to two-model architectures: the unified Solver–Verifier policy is not benchmarked against specialized or decoupled models (separate PRM, or separate solver and verifier) to quantify interference vs. benefits.
- Missing baselines on alternative RL algorithms: only GRPO is used; comparisons to PPO, VPG, DPO/sequence-level preference optimization, and off-policy methods (e.g., SAC) are absent, as are credit-assignment studies for process vs. outcome rewards.
- Step-level reward design is not validated: the weighting of tool correctness, semantic reliability, and KL alignment () lacks sensitivity analyses; cross-task tuning and generality are unproven.
- PRM evaluation lacks ground-truth correlation: the Verifier’s step-wise scores are not validated against labeled intermediate correctness or human judgments; rank correlations, ROC/AUC, or agreement analyses are missing.
- Best-of-N (BoN) gains may conflate sampling with evaluation: improvements using the Verifier as a PRM are reported for BoN but not top-1; disentangling selection bias from genuine reasoning improvement is not done.
- Error analysis and failure taxonomy are thin: beyond a single case study, there is no systematic categorization of failure modes (e.g., visual misreads, numeric errors, tool misuse, repair misfires) or actionable diagnostics.
- ChartQA/HallBench improvements are modest and unexplained: the paper does not analyze why certain domains benefit less or what bottlenecks (vision tooling, parsing) limit gains; targeted interventions are not proposed.
- Role-switching mechanics are not stress-tested: the conditions, frequency, and costs of alternating between Solver and Verifier are not profiled; potential interference or role confusion is unquantified.
- Outcome vs. process reward trade-offs are unstudied: the balance parameter (Eq. 7) is introduced without tuning studies; how process rewards alone perform vs. combined rewards remains unclear.
- Generalization across languages and formats is unknown: cross-lingual performance, non-English benchmarks, and robustness to varied prompt styles or layouts (e.g., handwritten math, scanned charts) are untested.
- Dataset construction and curation details are missing: filtering, deduplication, diversity metrics, tool-augmented label quality, and license compliance for the 200k SFT and 40k RL datasets are not documented.
- Ethical and environmental impacts are not considered: energy footprint, carbon cost of multi-iteration RL with tool calls, and responsible use of executable tooling are not discussed.
Glossary
- Advantage (normalized): A scalar signal in policy-gradient RL that measures how much better a sampled trajectory performed relative to a baseline. "we compute a normalized advantage for each trajectory:"
- Agent0-VL: The proposed self-evolving vision-language agent that integrates reasoning, verification, and self-repair with tools. "we propose Agent0-VL, a self-evolving vision-language agent that achieves continual improvement with tool-integrated reasoning."
- Best-of-8 (BoN): An evaluation protocol that selects the best output among eight sampled trajectories/answers. "significantly improves Best-of-8 (BoN) performance"
- Confidence-gated self-repair: A mechanism that triggers corrective regeneration only when the verifier’s confidence falls below a threshold. "tool-grounded reasoning, verification, and confidence-gated self-repair."
- Discount factor: In RL, a number in [0,1) that geometrically downweights future rewards in return computation. "where is the discount factor,"
- Distributional self-consistency: Aligning the distributions of reasoning and evaluation so they reinforce each other during training. "a process of distributional self-consistency, where reasoning and evaluation behaviors are jointly aligned and continually optimized."
- Epistemic certainty: The model’s estimated confidence about the correctness of its knowledge for a step. "estimates epistemic certainty,"
- Evaluation hallucination: A failure mode where a model’s evaluator rewards plausible but incorrect reasoning or penalizes correct reasoning due to language priors. "evaluation hallucination, where the model incorrectly rewards a linguistically plausible yet visually incorrect answer, or penalizes a visually correct answer that fails to align with its language-based expectations."
- Gating temperature: A scalar controlling the sharpness of the sigmoid gate that decides whether to trigger repair. "where is the sigmoid function, and controls the gating temperature."
- Group Relative Policy Optimization (GRPO): A PPO-style RL algorithm that optimizes trajectories based on their performance relative to a group average. "Group Relative Policy Optimization (GRPO)~\cite{shao2024deepseekmath}"
- Importance sampling ratio: The likelihood ratio used to correct for off-policy sampling in policy-gradient updates. "where $\rho_i = \tfrac{\pi_\theta(\tau_i)}{\pi_{\theta_{\text{old}(\tau_i)}$ is the importance sampling ratio."
- Kullback–Leibler (KL) divergence: A measure of discrepancy between two probability distributions, used here as a regularizer for stable updates. "while maintaining stability through a KL regularization term:"
- Large Vision-LLM (LVLM): A large multimodal model jointly processing images and text. "a unified self-evolving LVLM that integrates reasoning, verification, and self-repair"
- Latent belief state: An internal representation that accumulates reasoning context and multimodal information across steps. "where represents the latent belief state encoding accumulated reasoning context and multimodal information."
- Partially Observable Markov Decision Process (POMDP): A framework modeling decision-making under partial observability of the environment. "within the framework of a partially observable Markov decision process (POMDP):"
- Process reward: Step-wise rewards derived from verifier feedback and tool checks that shape the reasoning trajectory. "Compute process reward $r_{\text{proc}^{(t)}$ (Eq.~\ref{eq:proc_reward})."
- Process Reward Model (PRM): A model that scores intermediate reasoning steps to guide selection or training. "we deploy it as a Process Reward Model (PRM) to assess reasoning trajectories"
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm whose clipped objective stabilizes updates. "a variant of PPO designed for generative tasks."
- Reinforcement Learning (RL): A learning paradigm where an agent optimizes behavior via rewards from interactions. "trained via Reinforcement Learning (RL)"
- Return (trajectory return): The cumulative (discounted) reward over a trajectory. "the total return for the trajectory is aggregated,"
- Self-Evolving Reasoning Cycle (SERC): The paper’s iterative framework coupling inner-loop generation/verification with outer-loop RL updates. "We formalize this iterative learning paradigm as a Self-Evolving Reasoning Cycle (SERC)."
- Self-repair: The mechanism by which the model revises and regenerates flawed segments of its reasoning trajectory. "it initiates a self-repair process that leverages self-evaluation signals to revise and refine the reasoning trajectory"
- Self-rewarding learning: Training where the model generates its own reward signals (e.g., via a built-in critic/verifier) instead of relying on external labels. "recent research has explored self-rewarding learning"
- Semantic reliability: A component of the process reward reflecting correctness weighted by confidence. "$\underbrace{\text{score}_t \cdot \text{conf}_t}_{\text{semantic reliability}$"
- Solver: The role of the model responsible for multi-turn, tool-integrated reasoning to produce solutions. "the Solver, which performs multi-turn reasoning and selectively invokes external tools"
- Tool-grounded verification: Verification that cross-checks reasoning steps using external tools to reduce hallucinations. "through tool-grounded verification, confidence-gated repair, and reinforcement learning."
- Tool-Integrated Reasoning (TIR): Reasoning that interleaves model steps with external tool calls for computation or retrieval. "Multi-turn Tool-Integrated Reasoning (TIR) agents"
- Trajectory: The sequence of states, actions, and observations generated during multi-turn reasoning with tools. "Trajectory. Given an input , the model generates a multimodal trajectory:"
- Verifier: The role of the model that evaluates steps, produces critiques, confidence scores, and step-wise rewards, and can trigger repairs. "the Verifier that performs generative verification using tool feedback to produce critiques and step-wise rewards."
- Zero-external-reward evolution: Self-improvement achieved without any human labels or external reward models. "Through this zero-external-reward evolution, Agent0-VL aligns its reasoning and verification behaviors without any human annotation or external reward models,"
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging Agent0-VL’s tool-integrated Solver–Verifier loop, process reward modeling (PRM), and reduced hallucination rates on visual reasoning tasks. Each item notes sectors, potential products/workflows, and key dependencies.
- Sector: Software, AI Platforms
- Use case: Verifier-as-a-Service for multimodal agents
- What: Plug Agent0-VL’s Verifier (as a PRM) into existing LVLM/VLM pipelines to score and select the best-of-N reasoning traces (BoN) for images, charts, and diagrams.
- Tools/products/workflows: SDK/API for PRM scoring; integration with LangChain/LlamaIndex/agent frameworks; Python sandbox for tool calls.
- Assumptions/dependencies: Secure code execution environment; access to tool-call infrastructure (e.g., Python, OCR, retrieval); latency budgets for BoN; model licensing.
- Sector: Finance, Enterprise Reporting, Journalism
- Use case: Chart and report auditing assistant
- What: Analyze financial reports (10-K/10-Q), investor decks, and news articles; extract chart data; verify calculations (growth rates, ratios); flag misleading axis scales or annotations.
- Tools/products/workflows: PDF parsers, Chart-to-data extraction (e.g., ChartOCR/DePlot), Python/NumPy/SciPy for recomputation, EDGAR/API connectors.
- Assumptions/dependencies: High-quality OCR/diagram parsing; secure handling of confidential documents; domain-specific prompts; human-in-the-loop sign-off.
- Sector: Education
- Use case: Interactive geometry and math tutor with step-wise verification
- What: Provide immediate, tool-grounded feedback on student solutions (geometry diagrams, handwritten work); offer guided “self-repair” hints when confidence is low.
- Tools/products/workflows: LMS plugin; whiteboard/camera input; Python-based solvers (sympy/numpy); rubric-aligned critique templates.
- Assumptions/dependencies: Content alignment to curricula; guardrails against over-correction; privacy compliance for student data.
- Sector: Scientific Publishing, R&D
- Use case: Scientific figure and method consistency checker
- What: Validate numeric claims against plotted data, axis scales, and reported statistics in figures; detect unit inconsistencies and mislabeled panels.
- Tools/products/workflows: Plot digitization, PDF ingestion, unit-consistency checks, LaTeX/PDF toolchains.
- Assumptions/dependencies: Accurate figure parsing; domain-specific units/metadata; author consent/workflow integration.
- Sector: Data/AI Operations
- Use case: Multimodal annotation QA
- What: Auto-verify labels for image–text datasets (e.g., chart captions, visual math reasoning), flag ambiguous or inconsistent annotations, propose repairs.
- Tools/products/workflows: Labeling platform plugin (Label Studio, CVAT); Verifier feedback loop; selective self-repair suggestions.
- Assumptions/dependencies: Coverage of target label schema; budget for tool calls; adjudication workflow.
- Sector: Compliance, Safety, Trust & Safety
- Use case: Hallucination guardrails for multimodal assistants
- What: Use the Verifier to check factual consistency of answers grounded in images/diagrams; block or revise low-confidence steps via confidence-gated repair.
- Tools/products/workflows: Middleware guardrail policy; confidence thresholds; structured critique prompts; escalation to human review.
- Assumptions/dependencies: Proper threshold tuning; acceptable latency; audit logging.
- Sector: Customer Support, Consumer Electronics
- Use case: Troubleshooting from device photos/manual diagrams
- What: Parse device images and schematic snippets; verify steps via tool calls (calculations, cross-references); guide users through repair checks.
- Tools/products/workflows: OCR/diagram readers; retrieval over manuals; Python calculators; visual similarity search.
- Assumptions/dependencies: Access to up-to-date manuals; robust OCR for low-quality images; disambiguation prompts.
- Sector: Accessibility
- Use case: Accurate chart and infographic descriptions
- What: Convert figures into accessible, verified narratives with computed values and uncertainty estimates; reduce hallucinated summaries.
- Tools/products/workflows: Screen-reader integration; chart-to-data pipelines; numerical verification scripts.
- Assumptions/dependencies: Legal/compliance requirements for accessibility; format diversity across charts.
- Sector: Enterprise AI/ML
- Use case: Self-evolving domain adaptation without labels
- What: Use SERC on proprietary multimodal corpora to bootstrap domain-specific reasoning (e.g., industrial diagrams, QA logs) without human preference labels.
- Tools/products/workflows: RL training loop (GRPO), compute cluster; domain toolchains (custom parsers, calculators).
- Assumptions/dependencies: Sufficient unlabeled data; safe/sandboxed tools; compute budget for iterative RL.
- Sector: Legal, E-Discovery
- Use case: Evidence chart/diagram validation
- What: Cross-check exhibits (charts, timelines, accident diagrams) against underlying data; surface inconsistencies or missing units/sources.
- Tools/products/workflows: Document ingestion; timeline and metadata reconciliation; audit trails for review.
- Assumptions/dependencies: Chain-of-custody and admissibility concerns; non-repudiation logs; human oversight.
Long-Term Applications
The following applications are plausible with further research, scaling, integration with domain tools, validation, and/or regulatory acceptance. They leverage the same Agent0-VL innovations (tool-grounded verification, self-repair, SERC) but require additional development.
- Sector: Robotics, Manufacturing
- Use case: Vision-guided assembly verification and corrective planning
- What: Verify each visual step of assembly tasks using tool-integrated checks (pose estimation, torque calculators) and trigger self-repair plans when confidence is low.
- Tools/products/workflows: Vision-tool orchestration (pose/force estimators), robot APIs, digital twin simulators.
- Assumptions/dependencies: Real-time constraints; safety certification; robust perception in dynamic environments.
- Sector: Healthcare (Clinical Decision Support)
- Use case: Tool-grounded verification of measurements and dosing from medical images
- What: Extract measurements (e.g., cardiothoracic ratio on CXR), run medical calculators, verify unit conversions; generate flagged reports for clinician review.
- Tools/products/workflows: PACS integrations; FDA-compliant sandboxes; validated medical calculators.
- Assumptions/dependencies: Regulatory approval; clinical validation and bias audits; domain-specific datasets and tools.
- Sector: Engineering (CAD/EDA)
- Use case: Automated design rule checking from schematics/PCB layouts
- What: Parse layouts/images; compute spacing, clearance, trace widths; verify bill-of-materials against design constraints and standards.
- Tools/products/workflows: CAD parsers (e.g., IPC standards), EDA APIs, geometric computation libraries.
- Assumptions/dependencies: Access to proprietary formats; high-precision parsing; certification in safety-critical domains.
- Sector: Energy and Utilities
- Use case: Grid and plant monitoring via visual and chart analysis
- What: Analyze SCADA charts, P&IDs, thermal imagery; verify anomalies with simulation/estimation tools; propose repair plans with confidence gating.
- Tools/products/workflows: Historian connectors; simulation engines; alarm triage workflows.
- Assumptions/dependencies: Cybersecurity and NERC/CIP compliance; robust integration; operator-in-the-loop.
- Sector: Scientific Automation
- Use case: Closed-loop lab assistant for figure-grounded analysis
- What: Execute analyze–verify–repair cycles on microscopy/gel images and instrument charts; suggest protocol adjustments when verification fails.
- Tools/products/workflows: Instrument APIs; ELN integration; image quantification libraries.
- Assumptions/dependencies: Wet-lab validation; error propagation modeling; safety protocols.
- Sector: Public Policy, Fact-Checking
- Use case: At-scale verification of public-facing charts and statistics
- What: Systematically audit government/NGO releases for chart integrity (scales, baselines), unit consistency, and numerical claims against open datasets.
- Tools/products/workflows: Open data connectors; reproducible computation notebooks; audit dashboards.
- Assumptions/dependencies: Data quality/coverage; governance for corrections; interpretability for public trust.
- Sector: Geospatial/Remote Sensing
- Use case: Tool-integrated measurement verification from satellite/aerial imagery
- What: Compute areas, distances, change detection; verify claims (e.g., deforestation, construction progress) with GIS tools.
- Tools/products/workflows: GDAL/OGR, raster/vector analytics, coordinate transforms; temporal stacks.
- Assumptions/dependencies: Accurate geo-referencing; atmospheric corrections; licensing for imagery.
- Sector: Education at Scale
- Use case: Fully automated, step-aware grading of multimodal assignments
- What: Grade math/physics problems with diagrams, apply tool-based checks, and deliver targeted repair feedback; adaptively refine grading rubrics via SERC.
- Tools/products/workflows: LMS-gradebook APIs; rubric authoring UIs; proctoring integrations.
- Assumptions/dependencies: Fairness audits; adversarial behavior handling; privacy and FERPA compliance.
- Sector: Finance and Risk
- Use case: Automated audit of investor communications and ESG disclosures
- What: Detect misleading visuals, unverifiable statistics, and inconsistent ESG charts; cross-validate with filings and third-party data.
- Tools/products/workflows: EDGAR/NLP + chart parsers; ESG databases; anomaly scoring dashboards.
- Assumptions/dependencies: False-positive management; legal review; evolving disclosure standards.
- Sector: Transportation/Smart Cities
- Use case: Visual reasoning over traffic dashboards and camera feeds
- What: Verify computed KPIs in dashboards; reconcile counts from charts with observed video/image samples; trigger plan “self-repair” when inconsistencies arise.
- Tools/products/workflows: VMS/CCTV ingestion; spatiotemporal analytics; incident response playbooks.
- Assumptions/dependencies: Video privacy and retention policies; edge compute for latency.
- Sector: Retail/Logistics
- Use case: Shelf and planogram compliance with step-wise verification
- What: Compare store shelf images to planograms; compute deviations; propose corrective steps; self-improve on store-specific layouts without annotated labels.
- Tools/products/workflows: Planogram parsers; inventory connectors; field-ops apps.
- Assumptions/dependencies: Store variability; occlusions; data-sharing agreements.
- Sector: General AI Infrastructure
- Use case: “Self-Evolving Agent Platform” for domain-specific LVLMs
- What: Offer SERC-based training as a managed service for enterprises to build domain-adapted, tool-grounded self-improving agents with zero external rewards.
- Tools/products/workflows: GRPO training loops; tool orchestration; evaluation harnesses; governance and audit.
- Assumptions/dependencies: Significant compute; safety policies for tool calls; monitoring for evaluation drift.
Notes on Cross-Cutting Assumptions and Dependencies
- Tooling: Reliable access to external tools (Python, OCR, chart parsers, retrieval, domain calculators, GIS/CAD/EDA/medical APIs) and a secure, sandboxed execution environment.
- Data and domain shift: Performance outside math/chart/visual scientific domains depends on domain-specific corpora and tools; additional SFT/RL may be required.
- Compute and latency: BoN selection, verification, and iterative self-repair add cost/latency; batching and caching strategies may be necessary.
- Safety and compliance: Regulated sectors (healthcare, finance, critical infrastructure) require validation, auditability, and adherence to standards; human oversight is essential.
- Interpretability: Structured critiques and confidence scores can aid adoption but may need domain-tailored templates and thresholds.
- IP/licensing: Use of base models, teacher models, datasets, and third-party tools must respect licenses and data governance.
Collections
Sign up for free to add this paper to one or more collections.