VisPlay: Self-Evolving Vision-Language Models from Images
Abstract: Reinforcement learning (RL) provides a principled framework for improving Vision-LLMs (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence. The project page is available at https://bruno686.github.io/VisPlay/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VisPlay, a way for AI models that understand both pictures and text (called Vision-LLMs, or VLMs) to teach themselves without needing humans to write questions or answers. VisPlay helps a single model get better at “looking at an image and reasoning about it” by turning it into two cooperating roles that learn from each other using only raw images found online.
What questions did the researchers ask?
- Can a vision-LLM improve its reasoning skills using only unlabeled images (no human-written questions or answers)?
- How can we design rewards for learning when we don’t have ground-truth answers?
- Can the model learn to ask challenging but fair questions and also learn to answer them more accurately over time?
- Will this reduce “hallucinations” (when an AI makes things up or says something that isn’t in the image)?
How did they do it?
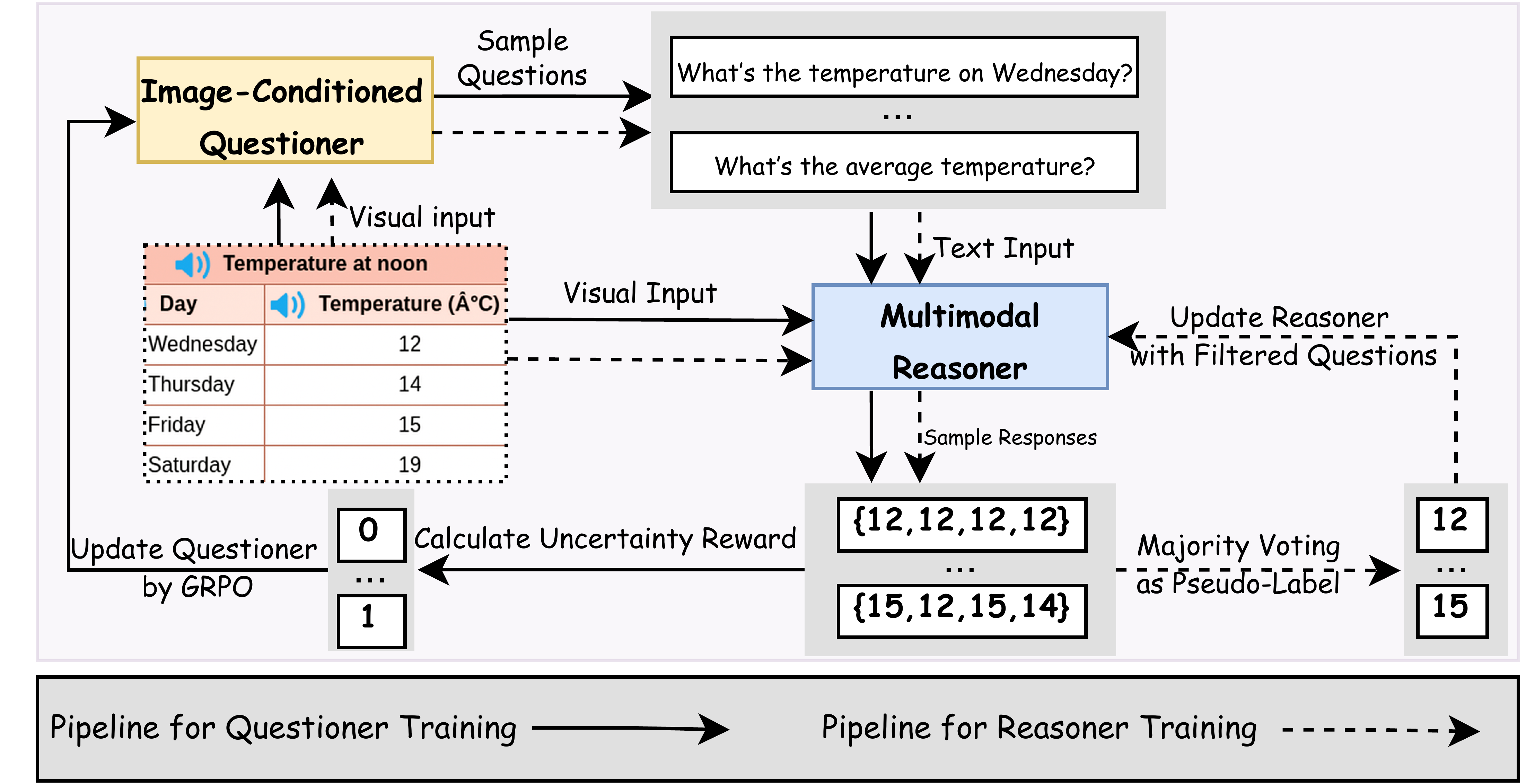
The idea is like two kids practicing together: one asks questions about a picture, and the other tries to answer. Both are copies of the same model, and they take turns improving.
Two roles: the Questioner and the Reasoner
- The Image-Conditioned Questioner looks at a picture and creates a question about it.
- The Multimodal Reasoner sees the same picture and the question, and then tries to answer.
They start from the same base model, and then “co-evolve” (improve together) through repeated practice.
How the Questioner learns
Because there are no human answers, the model can’t directly check if a question is “good.” Instead, it checks how uncertain the Reasoner is when answering:
- The Reasoner answers the same question multiple times.
- If the answers vary a lot, that means the question is hard and interesting.
- If the answers are identical every time, it’s too easy.
- If the answers are totally random, it’s likely confusing or bad.
The Questioner earns more reward for questions that make the Reasoner “half-sure/half-unsure” (the sweet spot of difficulty). It also gets a penalty if it repeats very similar questions, so it learns to be diverse and not spam the same thing. There’s a simple format check too (questions must follow a certain structure).
This learning uses a method called GRPO (Group Relative Policy Optimization). In simple terms, the model:
- Generates several options,
- Compares how good each option is relative to the group,
- Nudges itself toward the better ones without changing too much at once.
How the Reasoner learns
To train the Reasoner without real answers, the system creates “silver” answers (not guaranteed perfect, but good enough):
- For each question, the Reasoner answers multiple times.
- The most common answer (the majority vote) becomes the “pseudo-label” (the silver answer).
- The training focuses on questions where the Reasoner is moderately confident—neither too sure (too easy) nor too unsure (too noisy).
- The Reasoner then practices choosing the silver answer using GRPO, which rewards answers that match the pseudo-label.
The loop (self-evolution)
Here’s the cycle they repeat:
- The Questioner creates diverse, challenging questions about an image.
- The Reasoner answers each question several times; the system measures how uncertain it is.
- The Questioner gets rewarded for well-balanced, interesting questions (and not repeating itself), and improves.
- The Reasoner trains on a curated set of those questions using the majority-vote answers, and improves.
- Repeat. Each round, the Questioner asks tougher, cleaner questions, and the Reasoner becomes a sharper problem-solver.
What did they find?
Across many tests, VisPlay made different models smarter and more reliable without human-written training data. Highlights include:
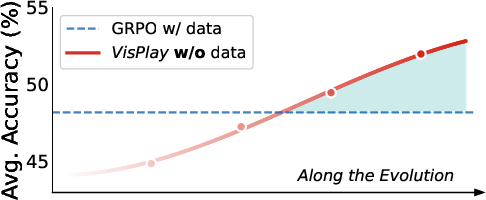
- Consistent gains on multiple benchmarks that check visual understanding, visual math, and general reasoning. For example, one 3-billion-parameter model improved its overall average score from about 31 to about 47 after a few rounds.
- Big reduction in hallucinations (saying things that aren’t in the image). In one case, the hallucination score jumped from about 33 to about 95, meaning the model became much more grounded in what it actually sees.
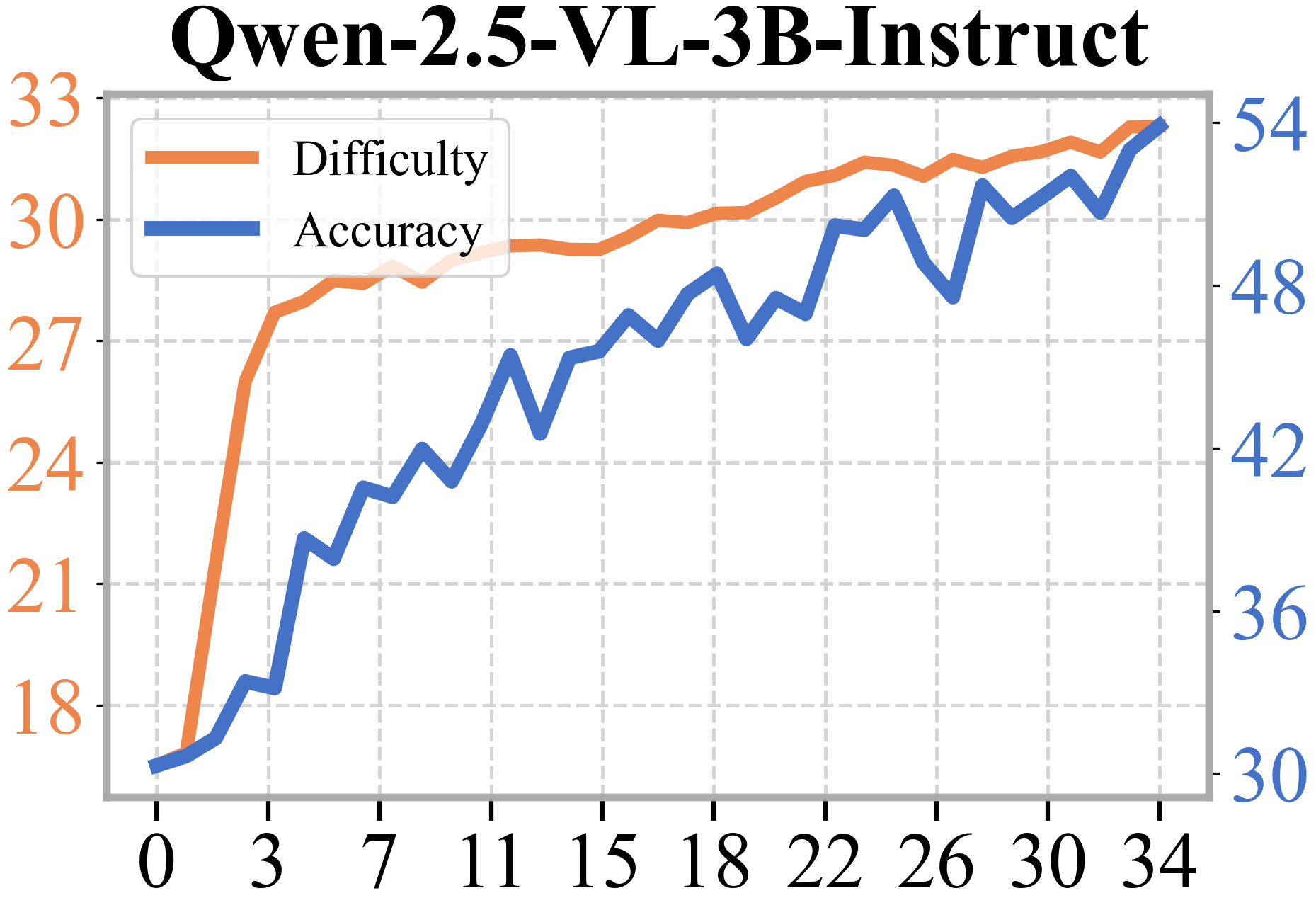
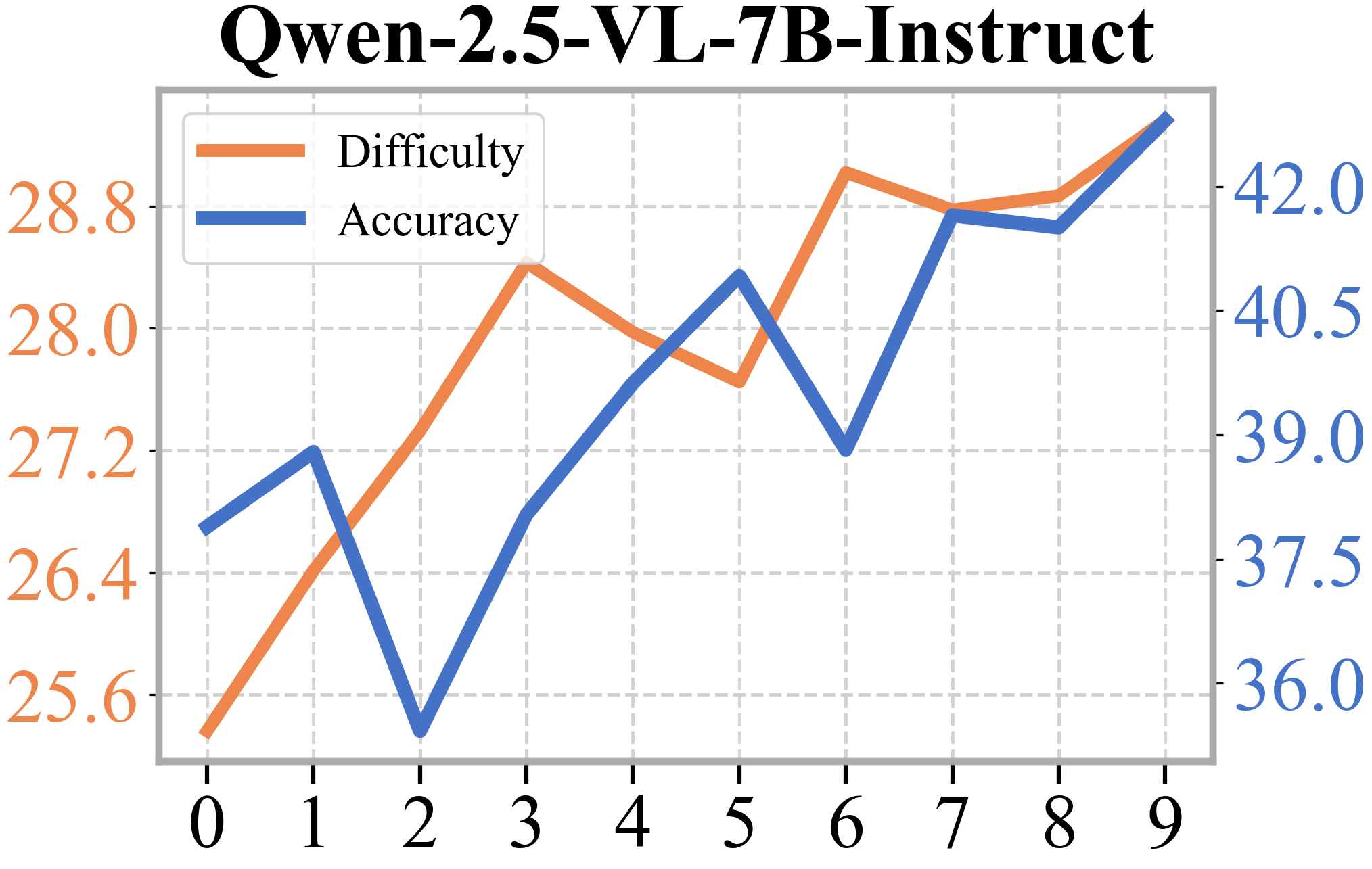
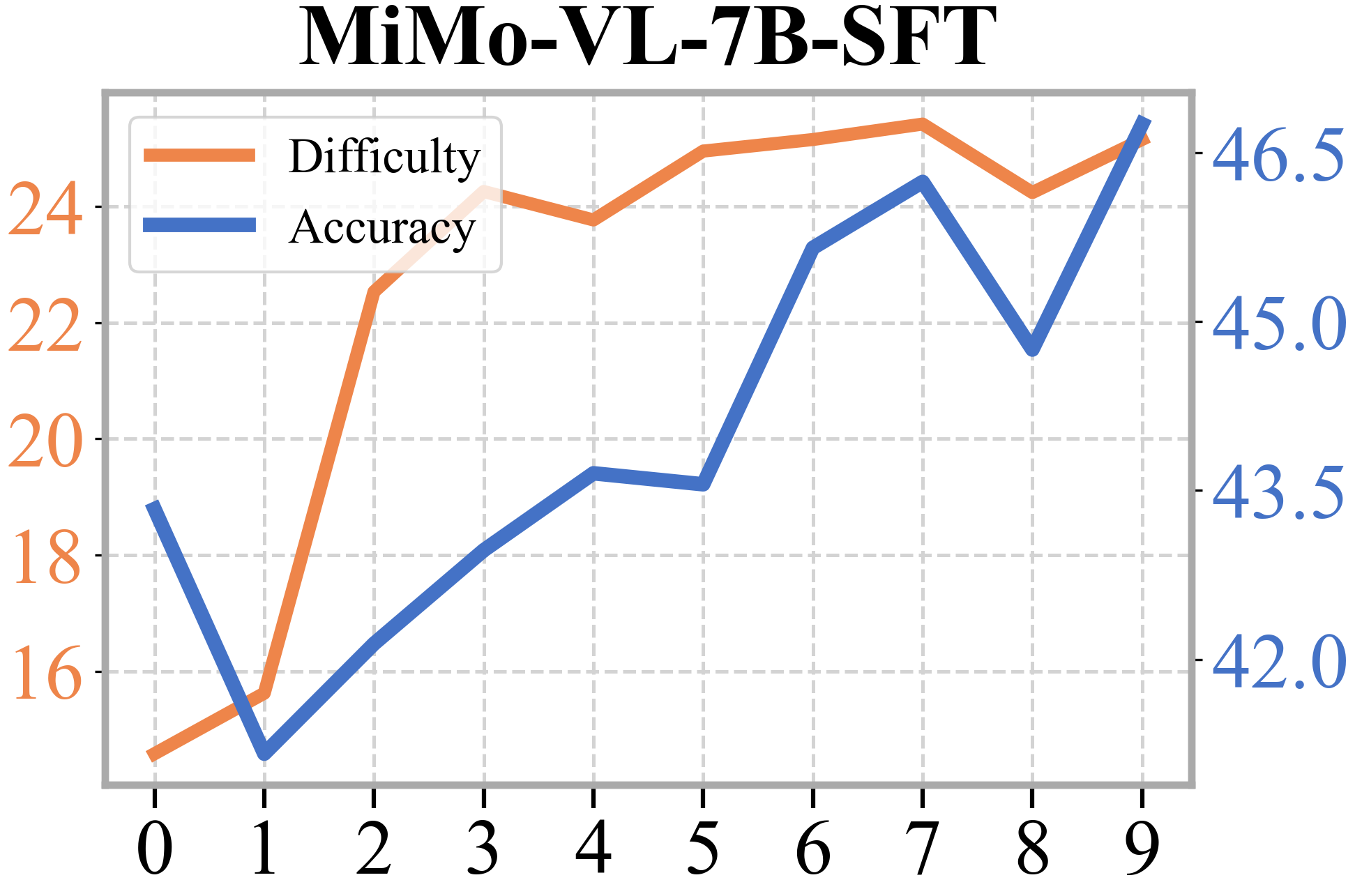
- The Questioner’s questions got harder over time, and the Reasoner kept up, solving more and more of these tougher questions. This shows the two roles truly co-evolve.
- Even compared to a standard training method that uses human-labeled data, VisPlay’s self-training achieved competitive accuracy—and often better grounding (fewer hallucinations).
Why is this important?
VisPlay shows that AI can get better at multimodal reasoning by learning from the internet’s vast supply of images without depending on expensive, slow human labeling. This makes training more scalable and opens the door to models that continuously improve themselves—asking better questions, sharpening their answers, and adapting to new domains on their own.
Limitations and what’s next
- The team tested on mid-sized models; it’s not yet clear how well this scales to much larger ones.
- The system relies on “silver” answers from the model itself. While clever filtering helps, it’s not a perfect guarantee of correctness. Future work could add stronger automatic checks to keep errors from stacking up.
Overall, VisPlay is a promising step toward AI that can teach itself to see and reason—safely, steadily, and at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper and would benefit from targeted follow-up work:
- Robustness of answer equivalence: The pseudo-labeling relies on strict string equality among sampled answers, which is brittle for free-form outputs (paraphrases, synonyms, units, rounding). How should answers be canonicalized and matched (e.g., semantic similarity, structured extraction, unit normalization) to avoid mislabeling and distorted uncertainty estimates?
- Ambiguity vs. difficulty: The uncertainty reward maximizes at , potentially incentivizing ambiguous or ill-posed questions rather than genuinely difficult, answerable ones. How can the framework distinguish and penalize ambiguity while rewarding legitimate hard questions (e.g., via image-grounded answerability checks, entailment, or counterfactual tests)?
- Diversity metric adequacy: Question diversity is enforced via BLEU-based clustering, which favors lexical variation but misses semantic diversity and image-grounding diversity (e.g., covering different regions/attributes of the same image). What metrics (embedding-based, entailment-based, region/attribute coverage) better capture meaningful diversity, and how do they affect learning?
- Hyperparameter sensitivity and selection: Key choices (group size , number of reasoner samples , candidate pool size , diversity weight , confidence thresholds $0.25$ and $0.75$) are not justified or ablated. How sensitive is performance to these parameters, and can thresholds be adapted dynamically (curriculum or competence-based filtering)?
- Stability and convergence guarantees: The co-evolution loop alternates training and freezing of roles, yet there is no theoretical or empirical analysis of stability, convergence conditions, or failure modes (e.g., cycles, collapse, drift). Under what conditions does VisPlay provably improve or at least avoid degradation?
- Noise-robust learning from pseudo-labels: Binary rewards in the reasoner stage treat pseudo-labels as ground truth despite known inaccuracies (Table shows pseudo-label accuracy drops from 72% to 61% with iterations). What noise-robust RL strategies (confidence-weighted rewards, bootstrapping with ensembles, debiasing, label smoothing) can mitigate error accumulation?
- Curriculum design: The current filter retains only “moderate” confidence samples (). Can an explicit curriculum (progressing from high-confidence to moderate/low-confidence, or from simpler to harder question families) further stabilize and accelerate learning?
- Evaluation reliability: The paper uses LLM-as-a-judge for correctness but does not report agreement, calibration, or judge bias analyses. How does judge choice affect rankings, and can human verification, multiple judges, or standardized verifiers reduce evaluation bias?
- Hallucination measurement validity: Large gains on HallusionBench may reflect yes/no bias or dataset specifics rather than true grounding improvements. Can more rigorous hallucination audits (e.g., POPE, CHAIR, localized grounding tests, adversarial distractors) validate that hallucination reduction generalizes beyond one benchmark?
- Generalization across architectures and scales: Experiments are limited to Qwen2.5-VL and MiMo-VL at ≤7B parameters. How does VisPlay scale to ≥10B models, different encoders/architectures (e.g., hybrid Mamba–Transformer, mixture-of-encoders), and what are compute/efficiency trade-offs?
- Efficiency and cost: VisPlay requires multiple samples per question and per image (both and are sampled repeatedly), yet compute, wall-clock cost, and sample efficiency are not reported. What are the minimal sampling regimes that still yield gains, and can distillation/compression reduce inference overhead?
- Reward design alternatives: The uncertainty reward is linear and the final reward uses ReLU clipping with a KL regularizer (GRPO). Would alternative designs (entropy bonuses, margin-based uncertainty, mutual information with image features, advantage baselines, or PPO-style value functions) improve learning stability and quality?
- Role asymmetry and ensemble benefits: Both roles share the same backbone, potentially limiting specialization. Would heterogeneous architectures, ensembles, or cross-model judging (e.g., different models as questioner/reasoner/verifier) yield better co-evolution and reduce confirmation bias?
- Answerability and grounding verification: The framework lacks automated checks that generated questions are image-grounded and answerable. Can vision tools (OCR, object detectors, segmentation), grounding losses, or entailment verifiers be integrated to filter or score questions for faithfulness?
- Failure analysis and task-level trade-offs: Several benchmarks fluctuate or degrade across iterations (e.g., VisNumBench, MMMU in some steps), but the paper does not analyze causes (shortcut learning, overfitting to certain visual patterns, drift in numerical reasoning). What diagnostics (error taxonomy, per-skill tracking) can guide targeted fixes?
- Compositional generalization measurement: The paper claims improvements but does not include explicit compositionality metrics or controlled tests (e.g., ood compositions, systematicity). How should compositional generalization be measured in VLMs, and does VisPlay truly improve it?
- Iteration depth and saturation: Figure mentions Evo 1–5 while results present up to Iter 3; the impact of longer self-evolution loops remains unclear. Do gains saturate, reverse, or oscillate with more iterations, and what stopping/early-warning criteria are appropriate?
- Data distribution and bias: Vision-47K images are web-collected (including medical/exam content) but the distribution, licensing, and potential biases (domain skew, demographics, context) are not analyzed. How do these biases affect learned behaviors, and how can data curation mitigate them?
- Open-ended answer extraction: For numeric, multi-choice, or structured visual math, robust extraction of “final answers” is crucial; for open-ended QA, semantic grading is needed. What unified answer normalization and grading pipeline (parsing, unit checks, rubric-based judges) should be integrated to support diverse question types?
- Safety and ethics: The system may generate and learn from medical or sensitive imagery without expert oversight, raising safety and misuse concerns. What safeguards (content filters, harm detectors, ethical review) are needed during question generation and training?
- Multi-modal extensions: The approach is image-only. How does VisPlay extend to video, temporal reasoning, audio, or 3D, and what new verifiers/rewards are needed to ensure answerability and difficulty in richer modalities?
- Component ablations: Despite claiming “extensive ablations,” the paper does not show the effect size of each component (uncertainty reward, diversity penalty, format constraint, confidence thresholds). Which pieces are necessary, which are sufficient, and how do they interact?
- Theoretical framing of self-evolution: Beyond empirical gains, a formal perspective (e.g., game-theoretic view of questioner–reasoner interaction, fixed-point analysis, or bounds on performance improvement with noisy verifiers) is missing. What theory can explain and guide self-evolving dynamics in multimodal RL?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage VisPlay’s self-evolving framework (Image-Conditioned Questioner + Multimodal Reasoner trained with GRPO, uncertainty/difficulty rewards, diversity regularization, and majority-vote pseudo-labeling) using unlabeled images.
- Zero-label data engine for multimodal model improvement (software/MLOps)
- What: Turn existing unlabeled image repositories (e.g., product images, scanned documents, screenshots) into a continuous training signal via the Questioner-Reasoner loop and uncertainty-based curation (retain samples with confidence in the 0.25–0.75 band).
- Tools/products/workflows:
- “Questioner-Reasoner Trainer” service integrated into MLOps.
- “Uncertainty-driven data curator” that auto-selects informative samples.
- Weekly GRPO fine-tuning jobs with drift control via KL regularization and diversity penalties.
- Assumptions/dependencies: Requires a sufficiently strong base VLM; compute budget for group sampling (G) and multi-sample inference (m); image usage must comply with IP/privacy; thresholds may need domain tuning.
- Automated attribute extraction and alt-text generation (retail/e-commerce, accessibility)
- What: Generate attribute-focused questions (e.g., color, size, brand, materials) and reasoned answers for product images; produce grounded alt-text and captions with reduced hallucination (benchmarked HallusionBench gains up to >90%).
- Tools/products/workflows:
- “Self-improving product tagger” that incrementally updates attribute ontologies.
- CMS/DAM plugins that backfill alt-text and product attributes.
- Assumptions/dependencies: Domain-specific attribute schema; monitoring for error accumulation in pseudo-labels; human-in-the-loop spot checks on high-impact categories.
- Document and form understanding without labels (finance, public sector, enterprise ops)
- What: From invoices, receipts, IDs, forms, and contracts, the Questioner generates targeted extraction prompts (e.g., “What is the invoice total?”), while the Reasoner returns structured fields; the uncertainty filter curates learning samples.
- Tools/products/workflows:
- “Self-curated OCR+VQA extractor” that pairs OCR with question-answer verification.
- Active-learning dashboard showing confidence histograms and exception queues.
- Assumptions/dependencies: OCR pipeline availability; data governance for sensitive PII; periodic evaluation with ground-truth subsamples.
- Packaging and compliance checks from images (manufacturing, CPG, logistics)
- What: Generate challenge questions that probe label presence, expiry dates, safety icons, and regulatory markings; use moderate-confidence items for continual improvement.
- Tools/products/workflows:
- “Visual compliance auditor” that flags missing/incorrect markings and learns new templates over time.
- Assumptions/dependencies: Clear compliance rule library; lighting/angle variability; enforcement requires audit trails and spot auditing to prevent drift.
- Visual QA safety layer to reduce hallucinations in production assistants (software, customer support)
- What: Wrap existing multimodal assistants with a Reasoner that re-asks itself targeted questions to validate claims about images before responding to users.
- Tools/products/workflows:
- “Hallucination guardrail” middleware using majority-vote pseudo-labels and rejection on overconfident disagreement.
- Assumptions/dependencies: Latency overhead from multi-sampling; fallback policies for uncertain cases.
- Pre-annotation in medical imaging workflows (healthcare; non-diagnostic)
- What: Generate structured question-answer pairs (e.g., presence of lines, devices, obvious markers) for radiographs and other modalities to speed clinician labeling or triage non-critical tasks.
- Tools/products/workflows:
- PACS/RIS-integrated “pre-annotation assistant” that highlights candidate findings for review.
- Assumptions/dependencies: Strict human oversight; medical-device regulatory constraints; privacy-compliant data access; limited to non-diagnostic support unless clinically validated.
- Curriculum generation for STEM diagrams and textbooks (education)
- What: Automatically create progressively harder questions from textbook figures, charts, and geometry diagrams; use the Reasoner to verify answerability and remove trivial/noisy items via confidence thresholds.
- Tools/products/workflows:
- “Diagram question generator” LMS plugin producing tiered practice sets and solution steps.
- Assumptions/dependencies: Instructor review for high-stakes assessments; alignment with curriculum standards.
- Visual content moderation and policy checks (platform safety, policy)
- What: Self-improving visual QA that asks targeted questions to detect policy violations (e.g., weapons, explicit content, unsafe behavior).
- Tools/products/workflows:
- “Policy questioner” templates per category; uncertainty-based triage to human moderation queues.
- Assumptions/dependencies: Policy definitions and evidence logging; fairness and false-positive monitoring; regional regulatory compliance.
- Assistive technologies for users with visual impairments (daily life, accessibility)
- What: More reliable scene descriptions and Q&A grounded in images with reduced hallucination; supports follow-up questions that the Questioner anticipates and the Reasoner answers.
- Tools/products/workflows:
- Mobile “describe my surroundings” apps that learn from user photo streams without manual labels.
- Assumptions/dependencies: On-device or private-cloud processing; consent for continual learning; careful handling of private environments.
Long-Term Applications
These require further research, scaling, validation, or integrations beyond the paper’s current scope (e.g., larger models, robust verification, expansion to video/robotics).
- Autonomous multimodal learners from live camera streams (robotics, smart manufacturing, smart cities)
- What: Extend VisPlay to video and streaming sensors so agents learn from unlabelled footage (factory lines, warehouses, traffic cams), generating their own curricula and improving perception/reasoning over time.
- Tools/products/workflows:
- “Stream-based Questioner-Reasoner” with temporal reasoning, memory, and drift detection.
- Assumptions/dependencies: Video-capable extensions; compute-efficient GRPO at scale; safety monitors in dynamic environments.
- Regulatory-grade verification pipelines for self-evolving models (policy, healthcare, automotive)
- What: Formal verifiers and audits that track pseudo-label quality, uncertainty bands, and KL-regularized policy shifts to certify model updates in regulated domains.
- Tools/products/workflows:
- “Self-evolution audit trail” including sample selection logs, reward distributions, and bias analyses; external spot-verification suites.
- Assumptions/dependencies: Community benchmarks and accepted verification protocols; governance standards for synthetic labels.
- Domain-specialized self-evolving medical assistants (healthcare; diagnostic potential)
- What: With clinically validated verifiers (e.g., tool-driven segmentation checks, rule-based measurements), the framework could learn complex diagnostic cues from large unlabelled archives.
- Tools/products/workflows:
- “Radiology self-evolution sandbox” that integrates PACS and third-party clinical tools for verifiable rewards beyond majority vote.
- Assumptions/dependencies: IRB/regulator approval; medically sound verifiers; robust bias and safety studies.
- Foundation data engines for enterprise knowledge graphs from images (enterprise software, knowledge management)
- What: Build multimodal knowledge bases from product photos, manuals, whiteboards, and diagrams by self-generating QA triples and linking them to SKUs or internal IDs.
- Tools/products/workflows:
- “Visual-to-graph builder” that converts curated QA into triples with entity/relation extraction.
- Assumptions/dependencies: Entity resolution pipelines; human curation of high-value nodes; IP-safe ingestion.
- Continual on-device learning for AR glasses and mobile agents (consumer devices)
- What: AR devices refine their visuolinguistic reasoning locally from users’ daily scenes, aided by privacy-preserving self-evolution and diversity constraints to avoid collapse.
- Tools/products/workflows:
- Federated/self-evolution client with energy-aware GRPO and local clustering for diversity.
- Assumptions/dependencies: Efficient models and sampling on edge; privacy-preserving telemetry; robust catastrophic-drift controls.
- Self-evolving fact-checking for visual journalism and OSINT (media, public sector)
- What: Agents that pose adversarial questions to images and cross-validate claims with external evidence, improving their own detection of misleading visuals over time.
- Tools/products/workflows:
- “Adversarial Questioner” linked to retrieval tools for multi-hop visual-text verification.
- Assumptions/dependencies: Reliable retrieval/verifiers; provenance tracking and watermarking; editorial standards.
- Autonomous exam and benchmark construction in multimodal domains (academia, EdTech)
- What: Large-scale generation of graded, difficulty-balanced multimodal exams from open educational images and diagrams, with iterative refinement using difficulty/uncertainty dynamics.
- Tools/products/workflows:
- “Multimodal benchmark builder” for labs and vendors to stress-test reasoning without hand-labeling.
- Assumptions/dependencies: Ground-truth estimation beyond majority vote (e.g., solver toolchains); content licensing; psychometric validation.
- Visual risk and fraud analysis from screenshots and scans (finance, cybersecurity)
- What: Self-play reasoning over UI screenshots, checks, IDs, and phishing images to discover evolving fraud patterns with minimal labels.
- Tools/products/workflows:
- “Fraud Questioner” that probes artifacts (mismatched fonts, tampered regions) and curates mid-confidence anomalies for analyst review and model training.
- Assumptions/dependencies: Secure handling of sensitive artifacts; adversarial robustness; human verification loops.
Cross-cutting assumptions and dependencies
- Base model capability: The paper’s gains are demonstrated on 3B–7B VLMs; scaling to ≥10B and to video remains untested and may change compute/memory budgets.
- Data legality and privacy: Using web or internal images must meet licensing, privacy (e.g., GDPR/CCPA/PHI), and retention policies.
- Verifiability: Current pseudo-labeling relies on majority vote; without task-specific verifiers, errors can accumulate. Incorporating domain tools and spot-checks is essential for high-stakes uses.
- Compute and latency: GRPO with group sampling and multi-answer inference introduces cost and latency; production systems need batching, caching, or selective activation.
- Thresholds and diversity: Confidence thresholds (0.25–0.75) and BLEU-based clustering may require domain-specific tuning; poor settings can bias curricula or cause mode collapse.
- Evaluation fidelity: LLM-as-a-judge and benchmark gains may not fully predict in-the-wild performance; real-world A/B tests and human QA remain important.
- Safety and bias: Self-evolution can amplify dataset biases; periodic audits, red-teaming, and gated deployment strategies are required.
Glossary
- Advantage (response-level): A normalized measure of how much better a sampled response is compared to others from the same prompt, used to scale policy gradients. Example: "Rewards are normalized within the group to compute response-level advantages:"
- Autoregressive policy: A model that generates the next token conditioned on previously generated tokens, used here for question generation. Example: "The Questioner is an autoregressive policy denoted by ."
- BLEU score: A metric for text similarity based on n-gram overlap, used here to cluster and penalize duplicate questions. Example: "We cluster these generated questions based on pairwise similarity (BLEU score) to identify duplicates."
- Clipped surrogate objective: An RL objective that limits the change in policy probability ratios to stabilize training (as in PPO/GRPO). Example: "The policy is then optimized using a clipped surrogate objective, regularized by a KL term to constrain policy drift:"
- Compositional generalization: The ability to generalize to novel combinations of known components or skills. Example: "VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks including MM-Vet and MMMU,"
- Confidence score: The estimated certainty of a pseudo-label, often computed as the majority frequency among sampled answers. Example: "We then define the confidence score for this pseudo-label as:"
- Cross-modal reasoning: Reasoning that integrates information across different modalities (e.g., vision and text). Example: "MMMU~\cite{mmmu} evaluates cross-modal reasoning and subject knowledge through 11.5K college-level, four-choice questions spanning six academic disciplines."
- Diversity regularization: A penalty or regularizer encouraging varied outputs to avoid mode collapse or repetition. Example: "To prevent the model from collapsing~\citep{dai2025cde,chen2025pass,zhou2025evolving,liu2025vogue,cheng2025reasoning} into generating repetitive questions for a given image , we introduce a redundancy penalty within its generated group ."
- Group Relative Policy Optimization (GRPO): An RL algorithm that optimizes a policy by comparing samples within a group, avoiding explicit value functions. Example: "GRPO~\citep{grpo} provides a practical RL algorithm without a value function by using relative rewards among multiple samples from the same prompt."
- Hallucination (in VLMs): Generation of content not grounded in the visual input or facts, often measured and reduced by training. Example: "VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks including MM-Vet and MMMU,"
- Kullback–Leibler (KL) term: A regularization term measuring divergence between the updated policy and the old policy to limit drift. Example: "regularized by a KL term to constrain policy drift:"
- LLM-as-a-judge: An evaluation setup where a LLM assesses the correctness or quality of outputs. Example: "We use LLM-as-a-judge to assess the correctness of the answers to ensure more robust evaluation~\cite{gu2025surveyllmasajudge, li-etal-2025-LLM-judge}."
- Majority voting: An aggregation method selecting the most frequent answer among multiple model samples to form a pseudo-label. Example: "and derive the pseudo-label via majority voting~\citep{huang2025efficient}:"
- Multimodal Reasoner: The agent/model role that answers questions given both images and text in this framework. Example: "and a Multimodal Reasoner that generates silver responses."
- Optical Character Recognition (OCR): Technology for extracting text from images, used as a capability in some benchmarks. Example: "MM-Vet~\cite{Mm-vet} provides a unified LLM-based score across recognition, OCR, and visual math tasks."
- Policy drift: Undesirable large deviations of the updated policy from the prior policy during RL updates. Example: "regularized by a KL term to constrain policy drift:"
- Pseudo-label: A label inferred from model predictions (rather than human annotation), often via aggregation. Example: "and derive the pseudo-label via majority voting~\citep{huang2025efficient}:"
- R1-style training: A family of RL-based post-training methods that enhance reasoning without explicit supervision. Example: "In particular, R1-style training~\cite{deepseekai2025deepseekr1incentivizingreasoningcapability,zheng2025parallel,jin2025search} has gained attention for its ability to enhance reasoning and visual understanding without explicit supervision."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm where outputs receive rewards based on rule-checkable correctness. Example: "Reinforcement Learning with Verifiable Rewards (RLVR)~\citep{rlvr}\nis a paradigm for training VLMs in domains where the correctness of model outputs can be verified."
- Rule-based verifier: A deterministic procedure to check whether a model’s output meets correctness criteria, yielding binary rewards. Example: "A rule-based verifier assigns a binary reward to each generation :"
- Self-evolving: A learning setup where a model improves by generating its own training signals and iteratively refining itself. Example: "We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning capabilities from massive unlabeled image data."
- Self-play: A training paradigm where agents generate data for each other (or themselves), enabling learning without external labels. Example: "We introduce VisPlay, a self-play reinforcement learning framework designed to evolve VLMs without human-annotated data."
- Silver responses (silver labels): Automatically generated responses/labels of intermediate reliability (below gold human labels but above raw predictions). Example: "and a Multimodal Reasoner that generates silver responses."
- Supervised fine-tuning (SFT): Post-training of a model on labeled data to align it with desired behaviors or tasks. Example: "Recent research in post-training of vision-LLMs (VLMs) has shifted from supervised fine-tuning (SFT) toward reinforcement learning (RL) paradigms,"
- Uncertainty reward: A reward shaping term that encourages generating questions at a difficulty where the model is maximally uncertain. Example: "We define the uncertainty reward to penalize deviations from the point of maximum uncertainty:"
- Value function (in RL): A function estimating expected returns, often used in policy gradient methods; GRPO avoids requiring it. Example: "GRPO~\citep{grpo} provides a practical RL algorithm without a value function by using relative rewards among multiple samples from the same prompt."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs to perform multimodal tasks. Example: "Reinforcement learning (RL) provides a principled framework for improving Vision-LLMs (VLMs) on complex reasoning tasks."
Collections
Sign up for free to add this paper to one or more collections.