EvoLMM: Self-Evolving Large Multimodal Models with Continuous Rewards (2511.16672v1)
Abstract: Recent advances in large multimodal models (LMMs) have enabled impressive reasoning and perception abilities, yet most existing training pipelines still depend on human-curated data or externally verified reward models, limiting their autonomy and scalability. In this work, we strive to improve LMM reasoning capabilities in a purely unsupervised fashion (without any annotated data or reward distillation). To this end, we propose a self-evolving framework, named EvoLMM, that instantiates two cooperative agents from a single backbone model: a Proposer, which generates diverse, image-grounded questions, and a Solver, which solves them through internal consistency, where learning proceeds through a continuous self-rewarding process. This dynamic feedback encourages both the generation of informative queries and the refinement of structured reasoning without relying on ground-truth or human judgments. When using the popular Qwen2.5-VL as the base model, our EvoLMM yields consistent gains upto $\sim$3\% on multimodal math-reasoning benchmarks, including ChartQA, MathVista, and MathVision, using only raw training images. We hope our simple yet effective approach will serve as a solid baseline easing future research in self-improving LMMs in a fully-unsupervised fashion. Our code and models are available at https://github.com/mbzuai-oryx/EvoLMM.
Sponsor


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces EvoLMM, a way for a vision-and-language AI (a “multimodal” model that understands both pictures and text) to teach itself to think better without any help from humans. Instead of using labeled examples or an outside “judge,” the model creates its own practice questions from images and then tries to answer them. Over time, it improves by rewarding itself when its answers become more consistent and well-structured.
Key Objectives
The paper asks a simple question: Can a multimodal AI improve its reasoning abilities all by itself, using only raw images and no human-written answers or external scoring rules?
To explore this, the authors set three goals:
- Let the model generate its own questions from images (so it doesn’t need human-made datasets).
- Let the model try multiple answers and score itself based on how consistent those answers are.
- Use a smooth, continuous scoring system (not “all-or-nothing”) so learning is steady and doesn’t get stuck.
Methods and Approach
Think of EvoLMM like a student who studies without a teacher:
The two roles: Proposer and Solver
- Proposer: Like a student writing their own quiz questions based on a picture (for example, a chart or diagram). The question must be about the image, not random.
- Solver: Like the same student attempting to answer those questions. The Solver doesn’t just answer once—it answers several times to see if the answers agree.
Continuous self-reward (a smooth scoring system)
- The Solver gets a higher score when most of its repeated answers match each other. If sometimes they match and sometimes they don’t, it still gets some points—just fewer. This is “continuous” because the score changes smoothly depending on how much agreement there is, rather than only awarding points when all answers match perfectly.
- The Proposer also gets a score—but for writing questions that are not too easy and not too hard. This stays in a “Goldilocks zone” (just right). If the Solver’s answers are too certain (all the same), the question might be too easy. If the answers are all over the place, the question might be too confusing. The Proposer learns to aim for the middle, where the question still challenges the Solver but can be solved.
The training loop (how learning happens)
- The model starts with only raw images—no answer keys, no labels.
- Step 1: Proposer looks at an image and generates a question about it.
- Step 2: Solver answers the question multiple times.
- Step 3: The model checks how similar the answers are (agreement) and how mixed they are (uncertainty).
- Step 4: It gives smooth scores to both Proposer and Solver:
- Solver is rewarded when its answers are consistent and well-formatted.
- Proposer is rewarded for questions that lead to “moderate” uncertainty (challenging but solvable).
- Step 5: Using these scores, both parts update themselves and try again on new images, getting better over time.
Technical note in simple terms:
- They use a learning method called reinforcement learning where the model improves based on rewards.
- They add a safety check (called KL regularization) to keep the model close to its original abilities so it doesn’t “forget” how to read images or go off track.
- They use “LoRA” adapters, a lightweight way to fine-tune big models without changing all their parameters, which helps keep training stable.
Main Findings
- With no human-made question–answer pairs and no external judge, EvoLMM improved a popular multimodal model (Qwen2.5-VL-7B) by about 2–3% on several benchmarks that test visual math and reasoning (like ChartQA, MathVista, MathVision, and ScienceQA).
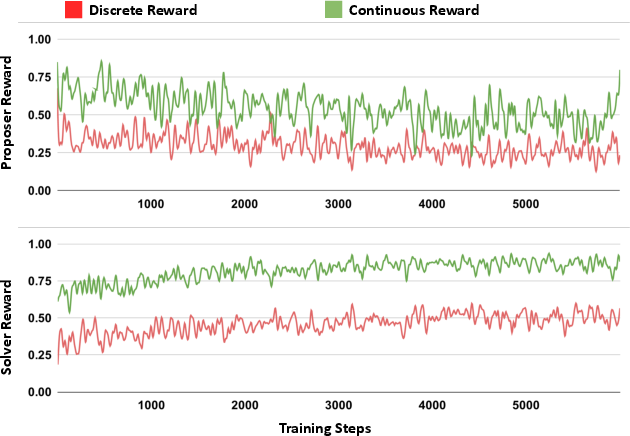
- The continuous reward (smooth scoring) worked much better than a simple “majority vote” method (which only rewards when most answers match exactly). The smooth scoring helped the model learn even when it was only partly correct, making training more stable.
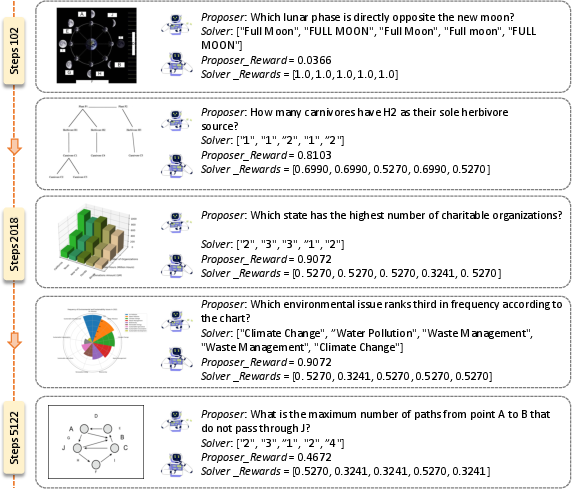
- The Proposer started asking better questions over time—moving from easy or confusing ones to mid-level questions that steadily teach the Solver.
- LoRA (the lightweight tuning method) gave the strongest, most stable improvements compared to full fine-tuning, which sometimes overfit and hurt performance.
- The approach worked across different model families and sizes, and larger models gained even more, showing that the method scales.
Implications and Impact
EvoLMM shows that multimodal AIs can improve themselves using only images and their own internal feedback, without expensive human labeling or external judges. This is useful when:
- You have lots of images but no annotations (like charts, diagrams, medical scans, or satellite photos).
- You want a model to keep learning and adapting on its own.
- You need stable training signals that don’t depend on perfect answers.
In short, EvoLMM points toward a future where AI systems can build their own curriculum, test themselves, and steadily get better at complex visual reasoning—making them more autonomous, scalable, and practical in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of gaps and unresolved questions that future work could address to strengthen and generalize EvoLMM.
- Agreement metric is under-specified: How exactly is
p(y_i | x, q)computed for open-ended, free-form answers (e.g., token log-probabilities vs. empirical frequency among samples)? Clarify normalization, handling of synonyms/paraphrases, numeric rounding/tolerance, and the impact of answer tokenization on “agreement.” - Entropy calibration and scale: The Proposer reward uses solver entropy
H(x, q)with fixedμ_Handσ_H, but the entropy scale depends on the answer space (e.g., number of unique strings withN=5). How shouldHbe normalized across tasks/backbones to ensure a consistent difficulty band? - Sensitivity to sampling hyperparameters: The framework relies on multi-sample decoding. What is the sensitivity of performance to
N, temperature, top-p/top-k, and repetition penalties? Is there an optimalNthat balances reward resolution and compute? - Consensus vs. correctness: Continuous self-consistency optimizes agreement, not ground-truth correctness. Under what conditions does agreement reliably track correctness, and how can the system detect or mitigate “confident but wrong” consensus?
- Reward hacking via diversity suppression: Could the Solver artificially boost rewards by reducing sampling diversity (e.g., lowering temperature) or by defaulting to stereotyped answers? How can decoding policy or diversity constraints be incorporated to prevent this?
- Mid-entropy band selection: The Proposer reward is a fixed Gaussian band-pass centered at
μ_H. Without dynamic adaptation, the “moderate difficulty” window may become suboptimal as the Solver improves. Canμ_Handσ_Hbe learned or automatically scheduled? - Validity and grounding of proposed questions: No quantitative measure ensures that generated questions are truly image-grounded or syntactically/semantically valid. How can automatic validators (without external models) or self-checking mechanisms detect ungrounded, ambiguous, or malformed questions?
- Handling numeric answers and tolerance: Exact string matching for numeric outputs is brittle (formatting, units, rounding). What is a robust, unsupervised way to assess agreement for numeric answers (e.g., tolerance bands, canonicalization)?
- Robustness to paraphrase and template diversity: The method may overcount unique strings due to minor phrasing differences. Can clustering, canonicalization, or edit-distance thresholds be integrated to reduce spurious entropy?
- Chain-of-thought vs. length penalty: The Solver reward penalizes pre-
<answer>word count, potentially discouraging useful reasoning steps. What is the trade-off between rationale quality and brevity, and how does this affect generalization? - KL regularization budget and stability: The adaptive token-level KL controller is crucial for stability but lacks thorough ablation. What are safe KL ranges, controller settings, and their interaction with full fine-tuning vs. parameter-efficient tuning?
- Role separation and capacity: Both Proposer and Solver are adapters on the same backbone. How does adapter rank/placement, shared vs. separate backbones, or prompt conditioning affect role specialization, capacity, and interference?
- Curriculum emergence validation: The “implicit curriculum” is inferred via entropy distribution shifts, but not causally validated. Can we measure whether question difficulty progression truly drives solver improvements, versus correlating with other training dynamics?
- Failure mode analysis: There is limited analysis of Proposer degeneration (e.g., repetitive templates), Solver mode collapse, or persistent ambiguity. What diagnostic metrics and safeguards can detect and correct these modes online?
- Domain generalization: Training used ~6k images from specific math/diagram datasets; generalization to out-of-domain images (photographs, complex scenes, video) is untested. How does the method transfer to non-math, open-ended visual reasoning?
- Scale-up and data diversity: How does performance scale with much larger unlabeled corpora, different image sources (web-scale), and increased visual/text diversity? What are compute–accuracy trade-offs and diminishing returns?
- Statistical robustness: Reported gains (~2–3%) lack variance estimates, confidence intervals, or multi-seed runs. Are improvements statistically significant across seeds and data resampling?
- Benchmark coverage and metrics: Evaluations focus on accuracy; no assessment of rationale faithfulness, calibration, or robustness to adversarial perturbations. Can richer metrics (consistency, uncertainty calibration, explanation quality) be incorporated?
- Comparison to alternative unsupervised signals: The paper primarily contrasts discrete majority-vote vs. continuous consensus. How does EvoLMM compare to unsupervised/weakly supervised baselines (e.g., reconstruction, contrastive pretraining, pseudo-labeling) under matched compute?
- Answer-space normalization across tasks: Different datasets yield different answer cardinalities and entropy behaviors. How can the reward be normalized or adapted across heterogeneous answer formats (multi-choice, numeric, free-text)?
- Decoding policy coupling to reward: The training-time decoding policy can shape reward dynamics (e.g., top-p values alter entropy). Should decoding be learned or constrained jointly to avoid conflating sampling strategy with learning progress?
- Multi-turn and long-horizon reasoning: The current loop is single-turn propose–solve per image. How can self-evolution extend to multi-step tasks (planning, tool use, external memory) while remaining unsupervised?
- Multi-image/video contexts: The approach is image-only and single-instance. What changes are needed for temporal reasoning, multi-image comparisons, or spatial grounding across frames?
- Safety and alignment: In broader domains, unsupervised question generation may produce harmful, biased, or privacy-invasive content. How can alignment constraints or safe reward shaping be integrated without external judges?
- Reproducibility details: Critical training details (e.g., exact decoding parameters, KL targets, controller hyperparameters) are not fully specified in the text. A standardized protocol for reproducing results across backbones and datasets is needed.
- Compute efficiency reporting: Wall-clock time, GPU hours, and scaling efficiency are not reported. What is the cost-performance profile vs. alternative fine-tuning methods?
- Use of evaluation-set images during training: Training samples images from benchmark training sets, but the paper does not detail strict separation from validation/test images across all datasets. Clarify data splits to rule out inadvertent leakage.
- Majority definition and tie-breaking: With small
N, ties are likely. How are ties handled in practice, and what is their effect on entropy estimation and reward smoothness? - Extending rewards beyond final answers: Agreement over intermediate rationales or extracted facts (e.g., OCR snippets) might provide richer self-supervision. Can the reward be extended to multi-level consistency (perception, steps, final answer) without external evaluators?
Glossary
- Adaptive KL controller: Mechanism that adjusts the strength of KL regularization to keep the learned policy close to a reference model. "Each policy employs an exponential moving-average baseline for variance reduction and a dynamic KL controller that adjusts to maintain a target divergence budget:"
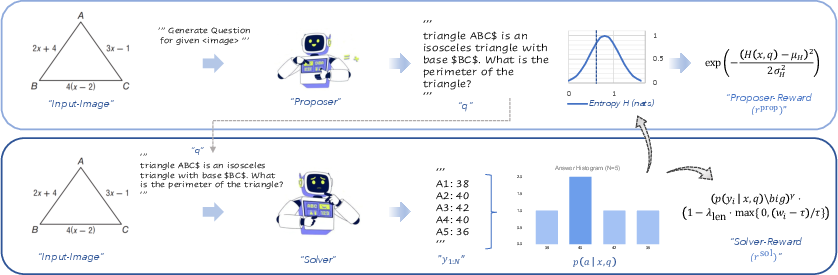
- Answer entropy: The entropy of the solver’s empirical answer distribution, used as a proxy for question difficulty or uncertainty. "the Proposer receives a smooth band-pass reward based on the Solverâs answer entropy:"
- Automatic curriculum: Emergent training progression where question difficulty adapts to the solver’s evolving capability without external supervision. "forming an automatic curriculum without external supervision."
- Band-pass reward: A reward function that peaks at moderate uncertainty, discouraging trivial and unsolvable questions. "the Proposer receives a smooth band-pass reward based on the Solverâs answer entropy:"
- bfloat16 precision: A 16-bit floating-point format that improves efficiency and stability in training large models. "Training runs on a single node with 8 AMD MI250X GPUs using bfloat16 precision."
- Closed-loop training signal: A feedback loop where model-generated outputs produce the rewards that train the model. "forming a closed-loop training signal that drives both modules to co-evolve."
- Continuous self-consistency reward: A dense reward that scales with agreement among multiple sampled answers, providing smooth gradients. "Our continuous self-consistency reward enables the Proposer and Solver to co-evolve smoothly,"
- Exponential moving-average (EMA) baseline: A running baseline used to reduce variance in policy-gradient updates. "Each policy employs an exponential moving-average baseline for variance reduction"
- Gaussian entropy reward: A reward shaped by a Gaussian centered at a target entropy to encourage mid-difficulty questions. "a Gaussian entropy reward for the proposer centered at with "
- Image-level reconstruction: Reconstructing entire images to strengthen visual perception during self-evolution. "leverages image-level and instance-level reconstructions in a two-stage RL loop"
- Instance-level reconstruction: Reconstructing specific visual instances or objects to improve perception. "leverages image-level and instance-level reconstructions in a two-stage RL loop"
- Kullback–Leibler (KL) divergence: A measure of divergence between probability distributions, used to regularize deviation from a reference model. "measures per-token divergence from a frozen reference model."
- Length penalty: A penalty that enforces concise answer formatting during training. "modulated by a length penalty that constrains the Solver's response format."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method for large models. "LoRA achieves the strongest improvements, e.g., â on ChartQA"
- Majority-vote reward: A discrete reward based on whether multiple sampled answers match exactly. "However, SQLM relies on a discrete majority-vote reward, which we empirically show to be sub-optimal"
- Policy gradient: A reinforcement learning approach that optimizes policies via gradients of expected rewards. "we adopt a REINFORCE policy gradient"
- Proposer: An agent that generates visually grounded questions from unlabeled images. "a Proposer, which generates diverse and visually grounded mathematical questions from unlabeled images"
- Proposer–Solver: A cooperative pairing of roles that generate and answer questions in a closed loop. "We apply the same Proposer--Solver continuous self-consistency training"
- QLoRA: Quantized LoRA; a memory-efficient fine-tuning method using low-bit quantization with high-precision adapters. "The quantized variant QLoRA (4-bit base + high-precision adapters) reduces memory usage by nearly ,"
- Quantization noise: Degradation in model performance due to low-precision numerical representation. "However, quantization noise slightly weakens solver consistency,"
- REINFORCE: A classic Monte Carlo policy-gradient algorithm for reinforcement learning. "we adopt a REINFORCE policy gradient"
- Reference model: A frozen baseline policy used to measure and regularize divergence during training. "measures per-token divergence from a frozen reference model."
- Reward distillation: Training reward models via knowledge distillation; avoided in this work. "in a purely unsupervised fashion (without any annotated data or reward distillation)."
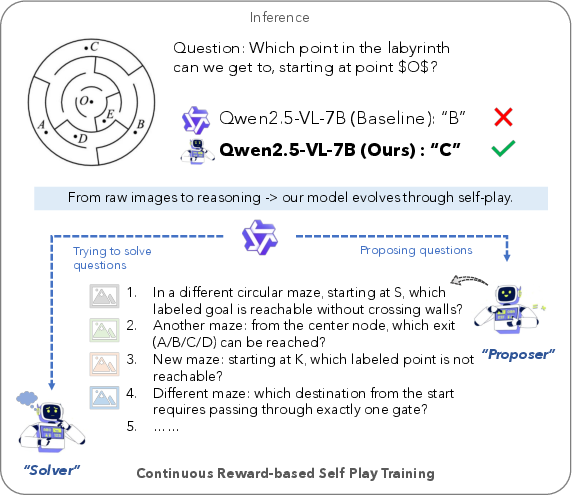
- Self-evolving: A training paradigm where a model improves autonomously by generating and solving its own tasks. "Illustration of our fully unsupervised self-evolving LMM framework (EvoLMM)."
- Self-play: A training technique where agents learn by interacting with versions of themselves. "alternates between self-play and verifiable reinforcement learning (RLVR)"
- Semantic similarity-based scoring: Evaluating outputs based on their semantic closeness rather than exact matches. "semantic similarity-based scoring."
- Token-level KL regularization: KL-based regularization applied at each token to constrain policy updates. "token-level KL regularization to monitor deviation from the pretrained base LMM."
- Verifiable reinforcement learning (RLVR): RL that incorporates external verification signals for correctness. "alternates between self-play and verifiable reinforcement learning (RLVR)"
Practical Applications
Immediate Applications
Below are applications that can be deployed now with modest engineering effort, leveraging EvoLMM’s self-evolving Proposer–Solver loop, continuous self-consistency rewards, and parameter-efficient fine-tuning (e.g., LoRA).
- Industry (Software/Analytics): Chart and infographic QA assistant for BI platforms
- Use case: Auto-generate and answer questions about internal dashboards (sales trends, KPIs, A/B test plots) without labeled QA pairs.
- Sector: Software, finance, retail operations.
- Potential tools/products/workflows: A “ChartQA” plugin for Tableau/Power BI; pipeline that ingests raw dashboard images → Proposer generates mid-difficulty grounded questions → Solver answers with multi-sample agreement → continuous reward tracks reliability → deploy as an assistant in BI interface.
- Assumptions/dependencies: Requires a reasonably capable base LMM (e.g., Qwen2.5-VL family), access to unlabeled dashboard images, and MLOps to run REINFORCE with KL control; internal consistency correlates with correctness on charts, but human review is advised for critical decisions.
- Academia and Publishing: Figure auditing in manuscripts and preprints
- Use case: Automatically generate questions about plots/diagrams (axes, trends, ratios) to surface inconsistencies or ambiguous figure design.
- Sector: Scientific publishing, research integrity.
- Potential tools/products/workflows: “FigureCheck” for PDF viewers/editors that highlights low-consensus questions and flags plots for human review; batch processing of submissions with agreement/entropy reports.
- Assumptions/dependencies: Effective on math/diagram-heavy figures; internal consistency is a proxy, not a proof—human-in-the-loop needed; privacy-safe processing for preprints.
- Education: STEM tutoring from textbook diagrams and class materials
- Use case: Generate varied, visually grounded math/science questions from diagrams, charts, and lab illustrations for formative assessment.
- Sector: Education/EdTech.
- Potential tools/products/workflows: Classroom assistant that takes images from slides/textbooks → Proposer builds mid-entropy questions → Solver answers with confidence scores; teacher dashboard surfaces items with moderate entropy (best learning signal) and evolvable difficulty.
- Assumptions/dependencies: Works best on structured visual content (charts, geometry, labeled diagrams); requires simple guardrails (e.g., response format control) and teacher oversight.
- Data Annotation and Curation: Label bootstrapping from unlabeled images
- Use case: Create candidate QA pairs from enterprise visual assets (charts, dashboards) to seed supervised datasets.
- Sector: Data labeling services, ML teams.
- Potential tools/products/workflows: Proposer–Solver pipeline generates Q&A with agreement scores; pairs exceeding a threshold move to human verification queue; entropy used to triage items.
- Assumptions/dependencies: Agreement ≠ ground truth; use human verification for gold labels; domain shift can affect grounding.
- Model Evaluation and Governance: Internal consistency monitoring for multimodal reasoning
- Use case: Track solver agreement and entropy as deployment metrics to detect drift or degraded visual reasoning.
- Sector: Software, MLOps, AI governance.
- Potential tools/products/workflows: “Consistency dashboards” showing entropy histograms, majority-answer rates, KL divergence trends to a reference model; alerts on rising uncertainty.
- Assumptions/dependencies: Consistency is a useful but imperfect proxy; needs calibration per domain and regular benchmarking with labeled test sets.
- Enterprise Document Intelligence: Q&A over operations reports
- Use case: Answer data-grounded questions over internal reports and infographics for non-technical staff.
- Sector: Operations, HR analytics, compliance.
- Potential tools/products/workflows: A document assistant that runs propose–solve on figures within PDFs and presents concise answers plus confidence; integration with SharePoint/Confluence.
- Assumptions/dependencies: Requires OCR/PDF rendering integration; privacy controls; best with standardized report templates.
- Parameter-Efficient On-Prem Adaptation: LoRA-based self-improvement in constrained environments
- Use case: Continual improvement of in-house LMMs from raw visual streams without moving data off-prem.
- Sector: Regulated industries (finance, government), enterprise IT.
- Potential tools/products/workflows: LoRA adapters for Proposer and Solver, adaptive KL controller to keep close to a reference model, scheduled proposer updates for stability.
- Assumptions/dependencies: Some GPU availability; modest engineering for RL loop; careful KL budgeting to avoid drift.
Long-Term Applications
The following applications require further research, scaling to new domains, or stronger verification (e.g., domain-specific evaluators, safety guardrails), but are promising directions enabled by EvoLMM’s unsupervised, continuous-reward design.
- Healthcare: Visual reasoning over clinical charts and diagrammatic workflows
- Use case: Generate and answer process-level questions about treatment pathways, lab trend charts, and guideline flow diagrams.
- Sector: Healthcare.
- Potential tools/products/workflows: “Clinical diagram tutor” that supports care teams by questioning and explaining visuals; entropy used to flag ambiguous documentation.
- Assumptions/dependencies: Strict safety validation; domain-tuned backbones; HIPAA-compliant pipelines; internal consistency must be complemented with external clinical correctness checks.
- Medical Imaging QA (non-diagnostic support)
- Use case: Self-evolving models that ask/answer grounded questions about scan annotations, measurement diagrams, and radiology reports’ figures.
- Sector: Healthcare imaging.
- Potential tools/products/workflows: Visual QA to check report–figure alignment; anomaly surfacing where entropy is high.
- Assumptions/dependencies: Not for primary diagnosis; requires medical-specific pretraining and human oversight; robust image-grounding beyond charts.
- Robotics and Autonomous Systems: Self-evolving visual task creation from onboard cameras
- Use case: Generate mid-entropy vision tasks (e.g., spatial relations, object counting, layout reasoning) to improve onboard perception-reasoning without labels.
- Sector: Robotics, autonomous vehicles.
- Potential tools/products/workflows: On-robot propose–solve loop for continual learning; curriculum emerges as difficulty stays near the decision boundary.
- Assumptions/dependencies: Extension from static images to video/temporal reasoning; integration with control policies; strong safety guardrails; simulators for early-stage training.
- Public Policy and Data Transparency: Citizen-facing assistants for government dashboards
- Use case: Question and explain trends in public statistics portals; surface ambiguous figures for review.
- Sector: Government, civic tech.
- Potential tools/products/workflows: “PolicyChart Assistant” that generates explanations and QA for public dashboards; moderation pipeline for misinformation or confusing graphics.
- Assumptions/dependencies: Accessibility and fairness checks; multilingual support; public feedback loops; governance over model updates.
- Finance: Chart reasoning for market analysis and risk reporting
- Use case: Internal assistants that question and answer visual market reports; assist analysts with grounded insights.
- Sector: Finance.
- Potential tools/products/workflows: Self-evolving chart reasoning modules embedded in research tools; continuous-reward monitoring of reliability.
- Assumptions/dependencies: Domain adaptation; stringent compliance; avoid autonomous trading decisions; external verification needed.
- Industrial IoT and Energy: Self-auditing visual dashboards
- Use case: Generate and answer questions about plant dashboards and grid visualizations to flag anomalies or confusing displays.
- Sector: Energy, manufacturing.
- Potential tools/products/workflows: “Ops QA” agents that monitor dashboard images; entropy-based alarms; operator-facing explanations.
- Assumptions/dependencies: Integration with time-series/data backends; domain-specific correctness checks; resilience to visual noise and layout changes.
- Scientific Discovery Support: Deep figure understanding across disciplines
- Use case: Cross-figure reasoning (e.g., linking plots and diagrams across a paper) with self-evolved questions to test internal coherence.
- Sector: Academia, R&D.
- Potential tools/products/workflows: “Paper Figure Reasoner” that proposes multi-step, cross-figure questions and tracks solver agreement; used in peer review and research summarization.
- Assumptions/dependencies: Multimodal chaining across textual content and figures; scale beyond single-image QA; evaluation frameworks for scientific correctness.
- Generalized Multimodal Self-Evolution SDK
- Use case: A developer toolkit to add propose–solve, continuous rewards, entropy-guided curricula, and KL-regularized policy updates to any LMM-backed product.
- Sector: Software platforms, AI tooling.
- Potential tools/products/workflows: “Self-Evolve SDK” with modules for question generation, multi-sample inference, reward computation, adaptive KL controller, and monitoring dashboards.
- Assumptions/dependencies: Base model quality; reward hyperparameters tuned per domain; guardrails to prevent reward hacking and mode collapse.
- Education (Autonomous Curricula): Full-spectrum adaptive learning across modalities
- Use case: End-to-end systems that construct and grade curricula from images, videos, and diagrams with emergent difficulty pacing.
- Sector: EdTech.
- Potential tools/products/workflows: Personal tutors that use entropy bands to keep learners in a productive challenge zone; analytics on solver agreement to estimate mastery.
- Assumptions/dependencies: Robust multimodal grounding; content safety and age appropriateness; alignment to standards; hybrid human–AI assessment.
In all long-term cases, reliability hinges on complementing internal consistency with domain-grounded validators, calibrating reward design to the task, and preserving alignment via KL-controlled updates. Continuous self-reward enables scalable improvement without labels, but deployment in high-stakes settings requires human oversight, auditing, and robust governance.
Collections
Sign up for free to add this paper to one or more collections.