- The paper presents a comprehensive dataset and benchmark designed to evaluate quantitative tasks in anatomical detection, tumor/lesion size estimation, and angle/distance measurement.
- It demonstrates that supervised fine-tuning significantly improves metrics such as IoU, MRE, and MAE, enhancing the performance of vision-language models.
- Despite these improvements, challenges remain in detecting small anatomical structures and precisely measuring minute angles, highlighting areas for future research.
MedVision: Dataset and Benchmark for Quantitative Medical Image Analysis
Introduction
Medical decision-making predominantly relies on not just qualitative but quantitative assessments. Despite the proliferation of vision-LLMs (VLMs) which can seamlessly integrate visual inputs with language outputs, current models primarily excel in categorical and qualitative tasks. MedVision aims to fill the gap in quantitative reasoning capabilities by providing a comprehensive dataset and benchmarking platform. This platform focuses on three key tasks in medical image analysis: detection of anatomical structures, tumor/lesion (T/L) size estimation, and angle/distance (A/D) measurement.
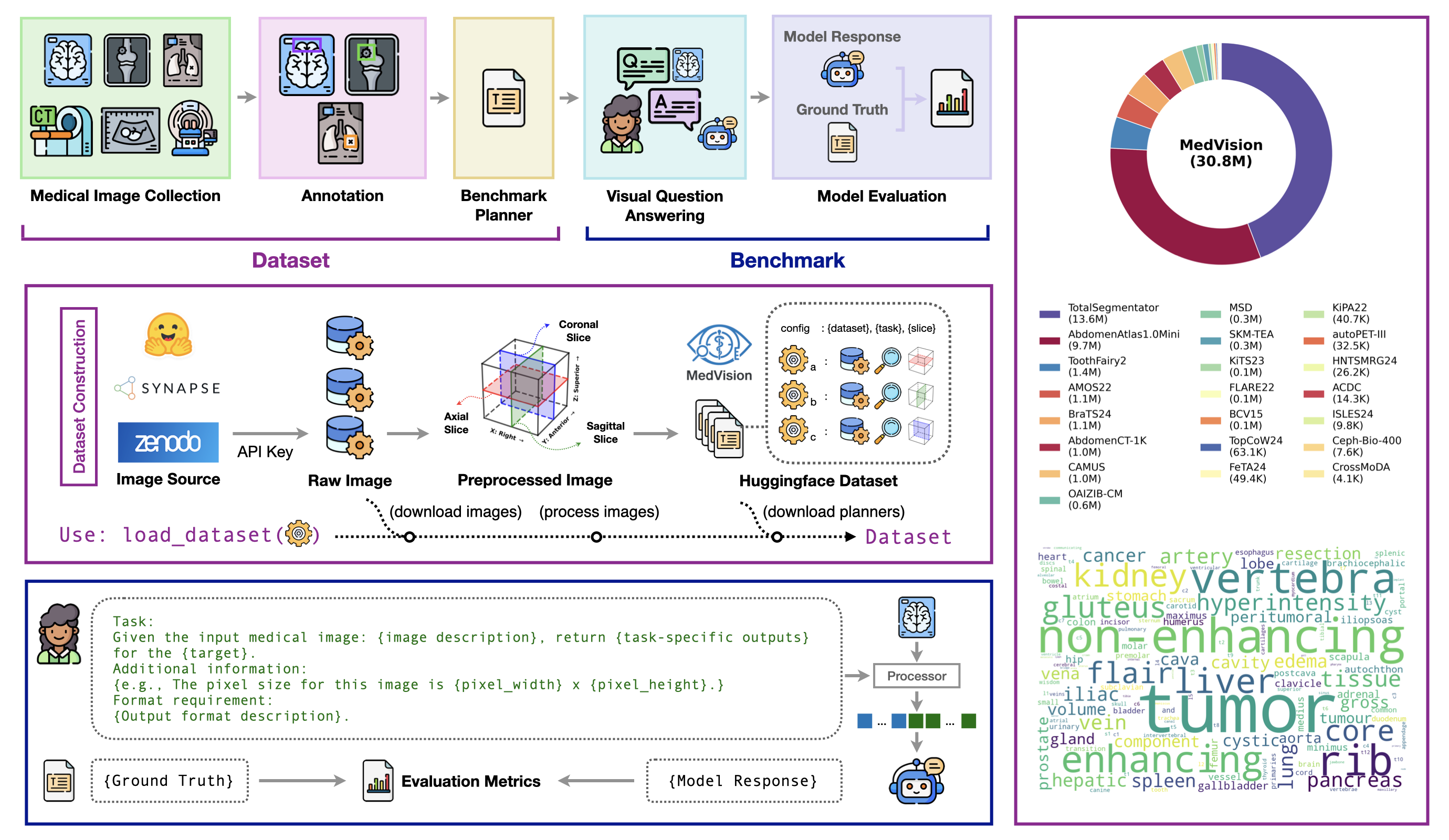
Figure 1: Overview of MedVision dataset construction and benchmark design (left), and dataset summary (right).
Dataset and Benchmark Design
MedVision aggregates a whopping 30.8 million image-annotation pairs from 22 diverse public datasets spanning various anatomies and imaging modalities. It provides structured annotations aimed explicitly at quantitative tasks. The benchmark design involves three specific tasks:
- Detection of Anatomical Structures: Involves localization and identification of healthy anatomical structures and abnormalities.
- T/L Size Estimation: Focuses on bidirectional dimensions of tumors/lesions, crucial for disease monitoring.
- A/D Measurement: Involves calculating angles and distances, underlining critical geometric relationships in medical contexts.
The dataset is finely split into training and testing sets for rigorous model evaluation and supervised fine-tuning allows VLMs to calibrate their numeric reasoning abilities.
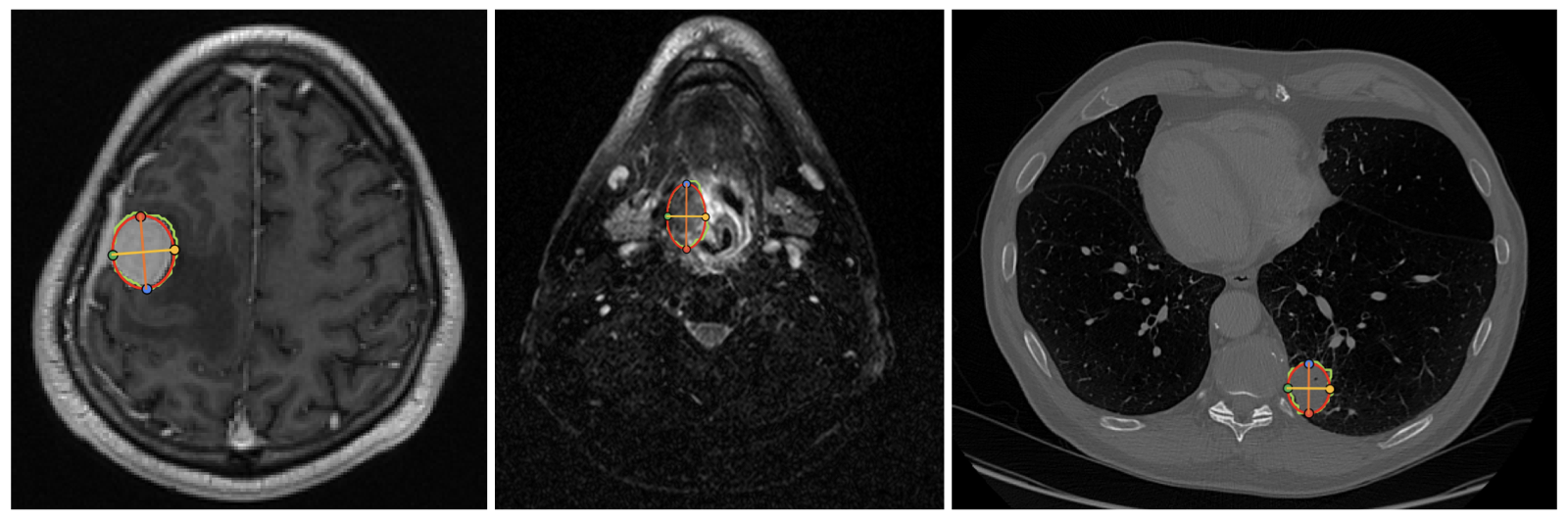
Figure 2: Tumor/lesion size annotation. An ellipse is fitted to the tumor/lesion mask and 4 landmarks are recorded. The largest diameter and its perpendicular diameter are measured.
Results Analysis
Baseline VLMs generally exhibit high success rates in generating bounding-box coordinates but falter in localization precision, with IoU metrics showing limitations below 15% for healthy anatomical structures and below 10% for tumors/lesions. Supervised fine-tuning drastically improves recall, precision, and IoU metrics, but small objects remain challenging for these models.

Figure 3: SFT improves VLM performance on healthy anatomical structures and tumor/lesion detection tasks, while the latter remains more challenging.
OOD performance showcases better generalization in SFT models, highlighting their ability to adapt across different datasets and target abnormalities.
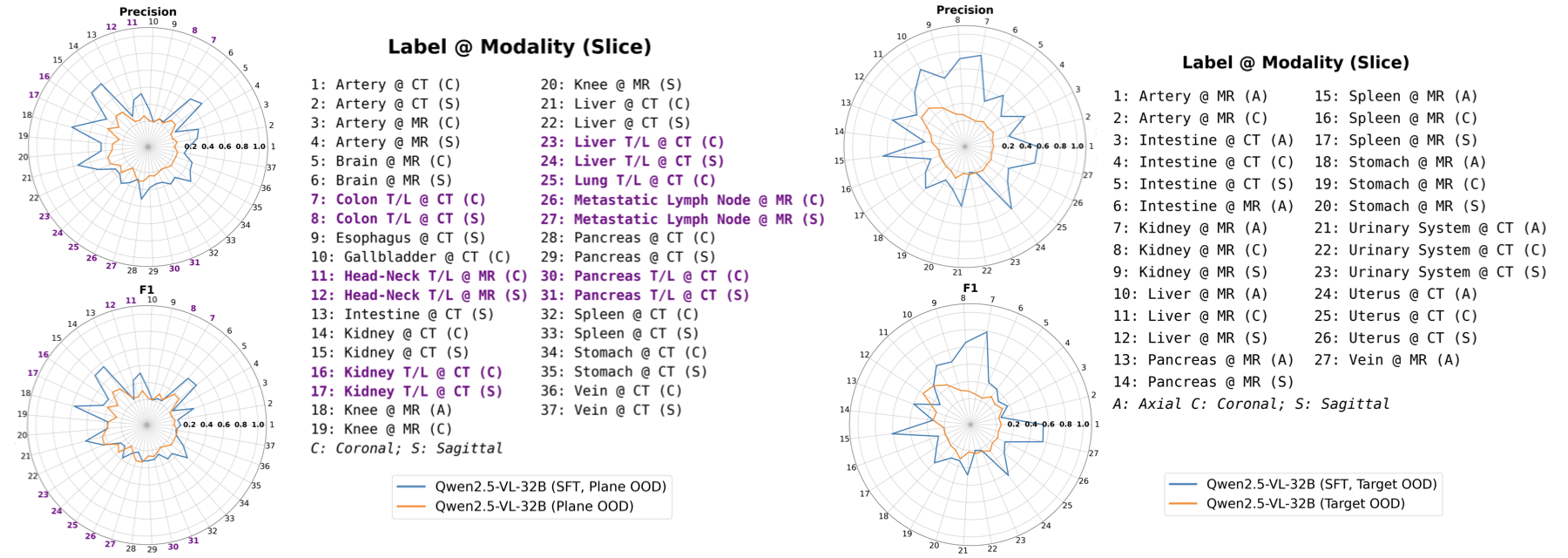
Figure 4: Detection performance on plane-OOD (left) and target-OOD (right) data. Tumor/lesion (T/L) labels are shown in color. The SFT model shows better generalizability.
T/L Size Estimation
Pretrained VLMs exhibit substantial errors in T/L size estimation tasks, however, post SFT, models achieve notable MRE reductions from over 50% to approximately 30%. This implies enhanced measurement accuracy post-training.
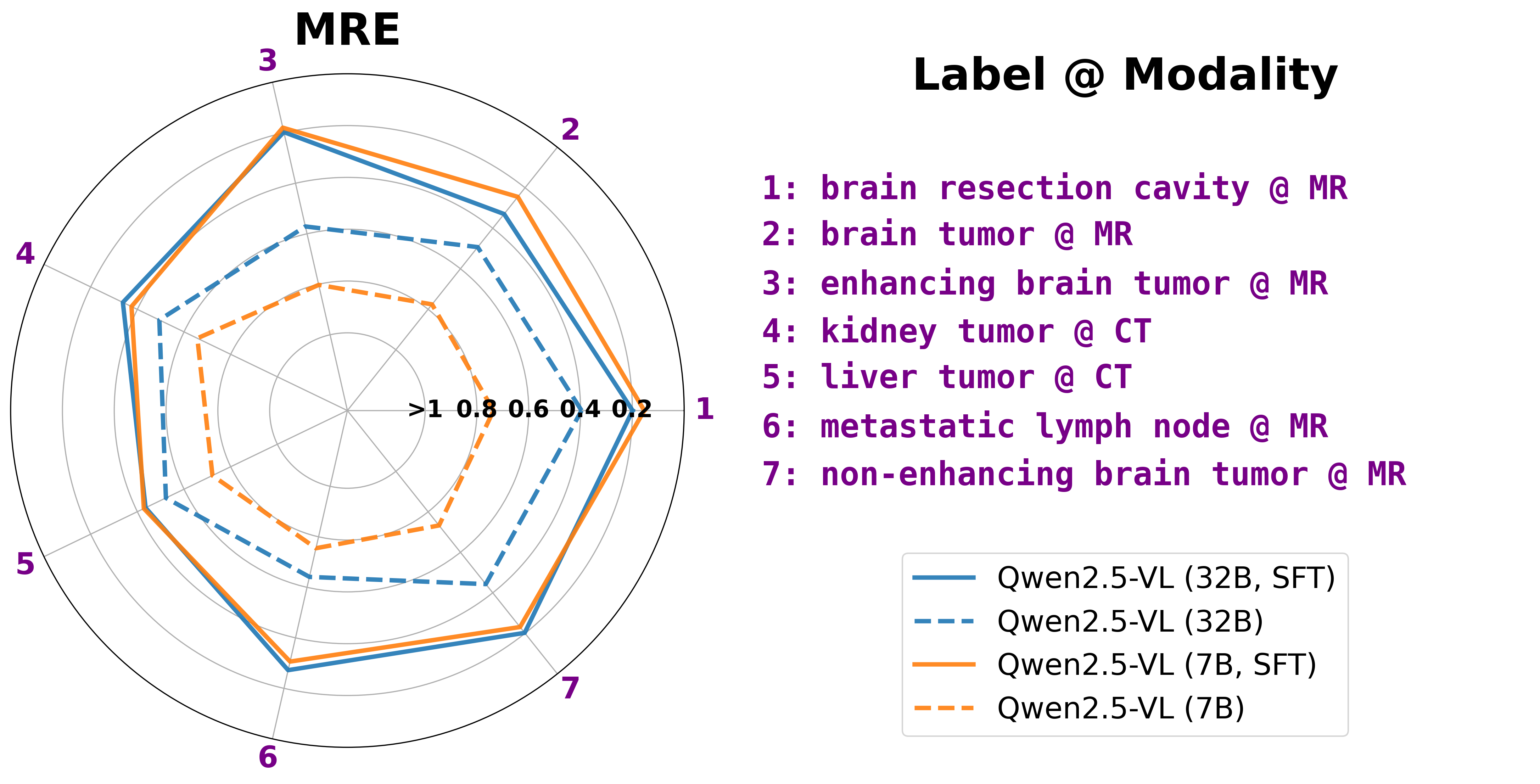
Figure 5: SFT improves T/L size estimation performance.
Angle and distance measurement tasks reveal that baseline models often miscalculate these metrics, yet SFT enhances predictions, reducing MAE to below 4.5 mm for distances and 4° for angles. The challenge persists in predicting smaller angles accurately.
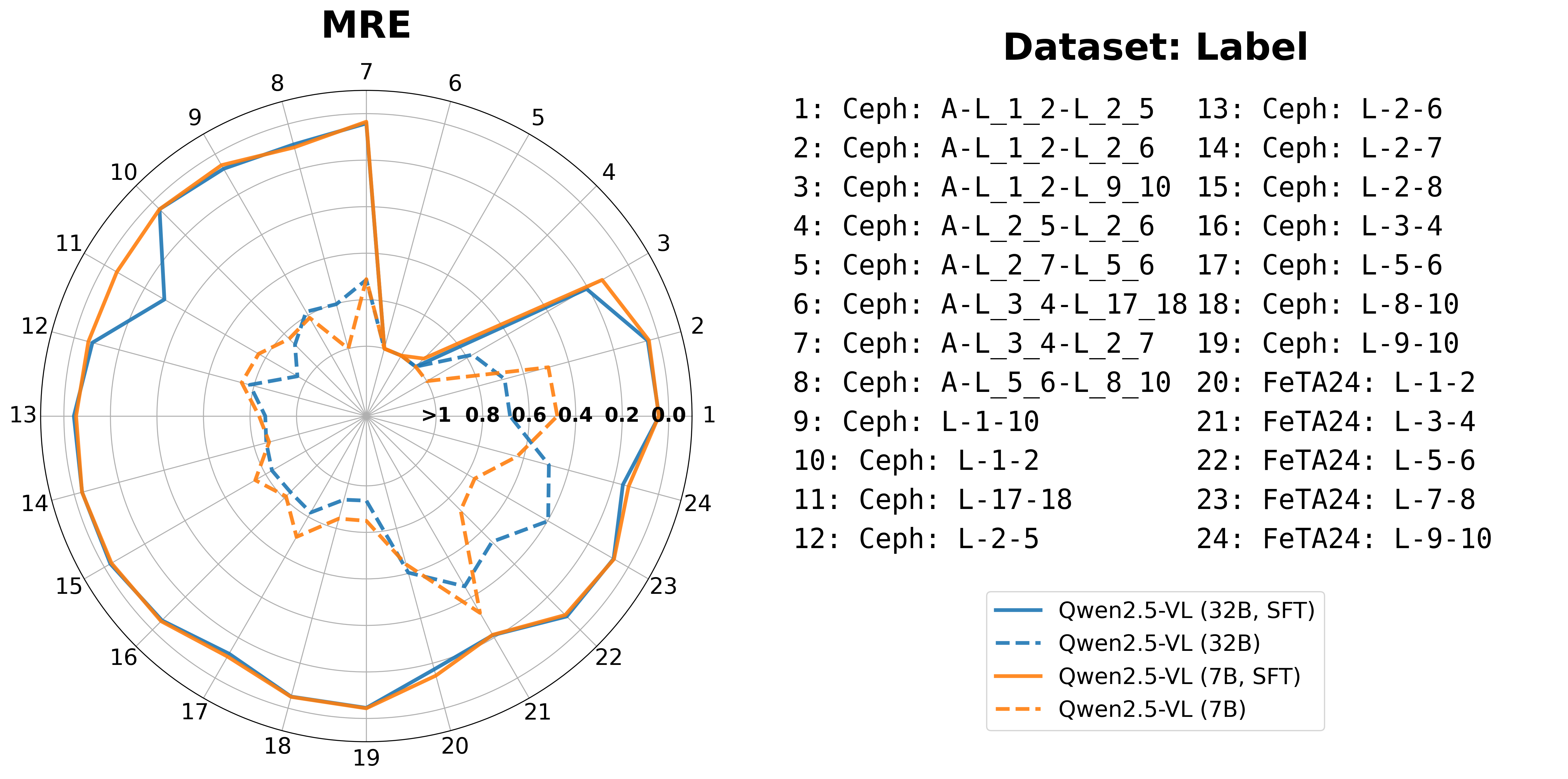
Figure 6: SFT improves VLM performance in A/D size measurement tasks.
Conclusion
MedVision sets a foundational benchmark in quantitative reasoning for medical VLMs. Despite enhancing performance with supervised fine-tuning, challenges persist in small structure detection and measurement. By providing a large-scale dataset and structured quantitative tasks, MedVision enables a pathway forward for model developers seeking to strengthen quantitative capabilities in medical image analysis. Future research should aim at further addressing these persistent limitations, refining VLM architectures and training objectives to produce calibrated numeric outputs consistently anchored in clinical relevance.


