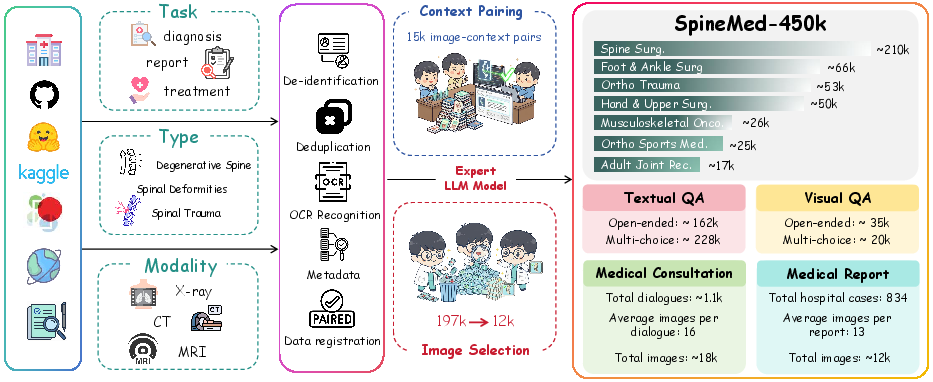
- The paper presents SpineBench, a level-aware benchmark powered by the large-scale, multimodal SpineMed-450k corpus.
- It introduces a rigorous, clinician-in-the-loop pipeline and a novel picture context matching algorithm for robust data alignment across imaging modalities.
- Benchmarking reveals that domain-specific models like SpineGPT significantly outperform general LVLMs in fine-grained spinal clinical reasoning.
SpineBench: A Clinically Salient, Level-Aware Benchmark Powered by the SpineMed-450k Corpus
Motivation and Problem Statement
Spinal disorders represent a major global health burden, requiring nuanced, multimodal, and level-specific clinical reasoning for accurate diagnosis and management. Existing AI systems for medical imaging and clinical decision support are constrained by the lack of large-scale, traceable, and clinically validated datasets that reflect the complexity of real-world spine care. General-purpose LVLMs and even medical-specific LLMs have demonstrated limited performance in fine-grained, vertebral-level reasoning, particularly when integrating information across X-ray, CT, and MRI modalities. The absence of standardized, spine-specific benchmarks further impedes progress in this domain.
SpineMed-450k: Dataset Construction and Characteristics
The SpineMed-450k dataset is a large-scale, multimodal, and provenance-rich instruction corpus specifically designed for orthopedic and spinal diagnosis. Its construction followed a rigorous clinician-in-the-loop pipeline, ensuring clinical validity and traceability at every stage.
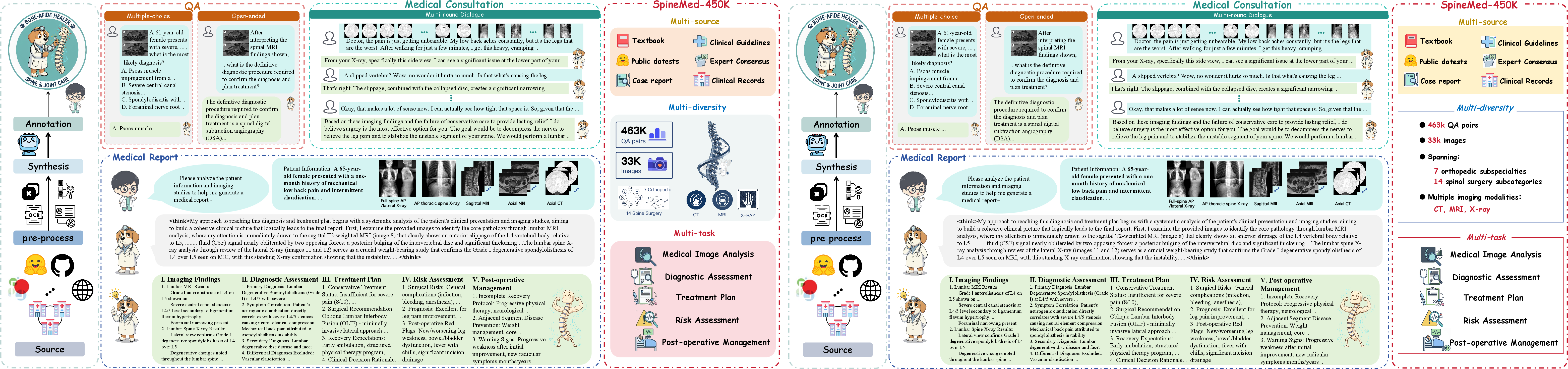
Figure 1: Overview of SpineMed-450k, illustrating the multi-source, multi-stage curation process and the diversity of data types.
Data Sources and Curation
A custom pipeline leveraging PaddleOCR and a novel picture context matching algorithm was developed to maintain the integrity of multimodal data and ensure precise mapping between images, captions, and contextual text.
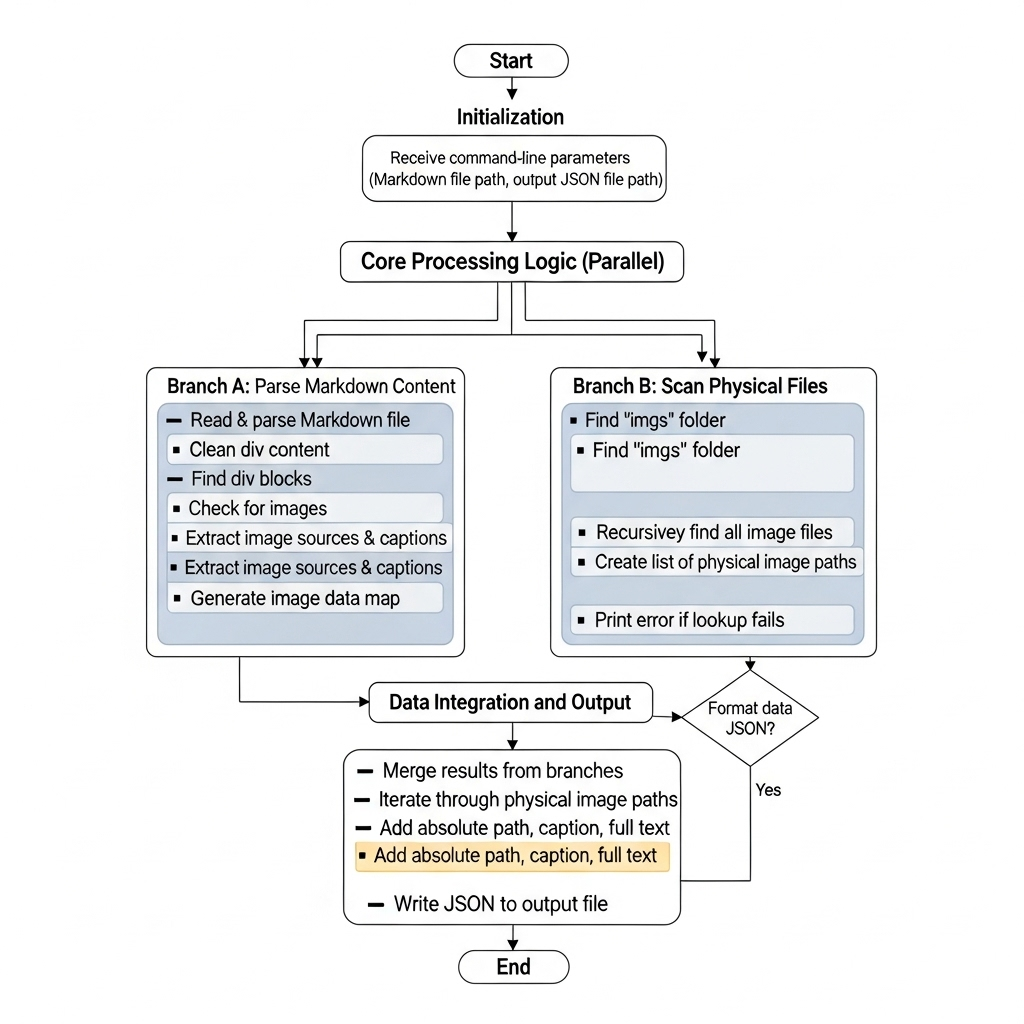
Figure 3: The picture context matching algorithm for robust multimodal data alignment.
Dataset Statistics
SpineMed-450k comprises over 450,000 instruction instances, with balanced coverage across seven orthopedic subspecialties and 14 spine subconditions. The dataset is demographically and institutionally diverse, with real clinical cases sourced from 11 hospitals over three years.
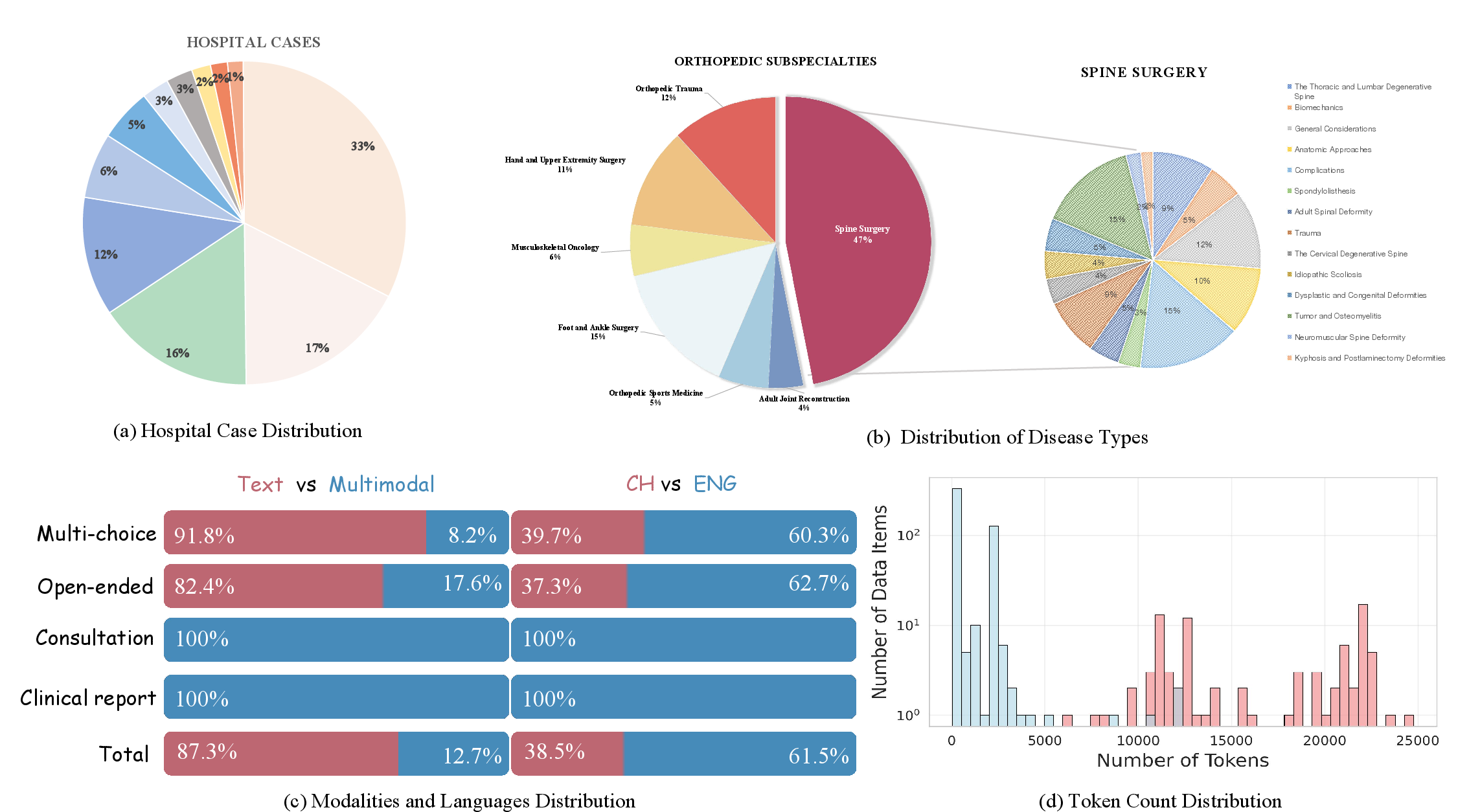
Figure 4: Statistics of SpineMed-450k, including hospital distribution, disease prevalence, modality/language breakdown, and token length distributions.
SpineBench: Benchmark Design and Evaluation Framework
SpineBench is a clinically grounded, level-aware benchmark derived from SpineMed-450k, designed to evaluate AI models on axes directly relevant to clinical practice.
Benchmark Construction
- Sampling: 500 multiple-choice questions and 100 medical report prompts, covering 14 spinal sub-diseases and multiple data sources.
- Validation: Triple-blind review by 17 board-certified orthopedic surgeons, ensuring high-quality, unbiased evaluation items.
Evaluation Metrics
A comprehensive, multi-dimensional scoring system was developed, integrating text-only and multimodal QA, as well as structured report generation. Report evaluation spans five key sections: imaging findings, AI-assisted diagnosis, treatment recommendations (patient and physician perspectives), risk/prognosis, and reasoning/disclaimer, each scored on a 1–5 scale with decimal granularity.
Experimental Results and Analysis
Model Training and Curriculum
The baseline model, SpineGPT, is a Qwen2.5-VL-7B-Instruct derivative, trained in three curriculum stages: (1) general/orthopedic foundational learning, (2) specialized spinal health, and (3) advanced report generation and dialogue. The ablation study demonstrates that domain-aligned orthopedic and spine-specific data are essential for high performance; general medical data alone is insufficient.

Figure 5: Benchmark performance of SpineGPT, demonstrating consistent improvements over open-source and proprietary LVLMs.
- Open-Source LVLMs: Qwen2.5-VL-72B and GLM-4.5V underperform on both QA and report generation, with pronounced deficits in multimodal tasks.
- Proprietary LVLMs: Gemini-2.5-Pro and GPT-5 achieve higher scores, but SpineGPT narrows the gap, outperforming several proprietary models on text-only QA and achieving the highest open-source report generation scores.
- Cross-Modal Alignment: All models exhibit a performance drop on image-based tasks, highlighting persistent challenges in vision-language integration for medical imaging.
Human-Expert Agreement
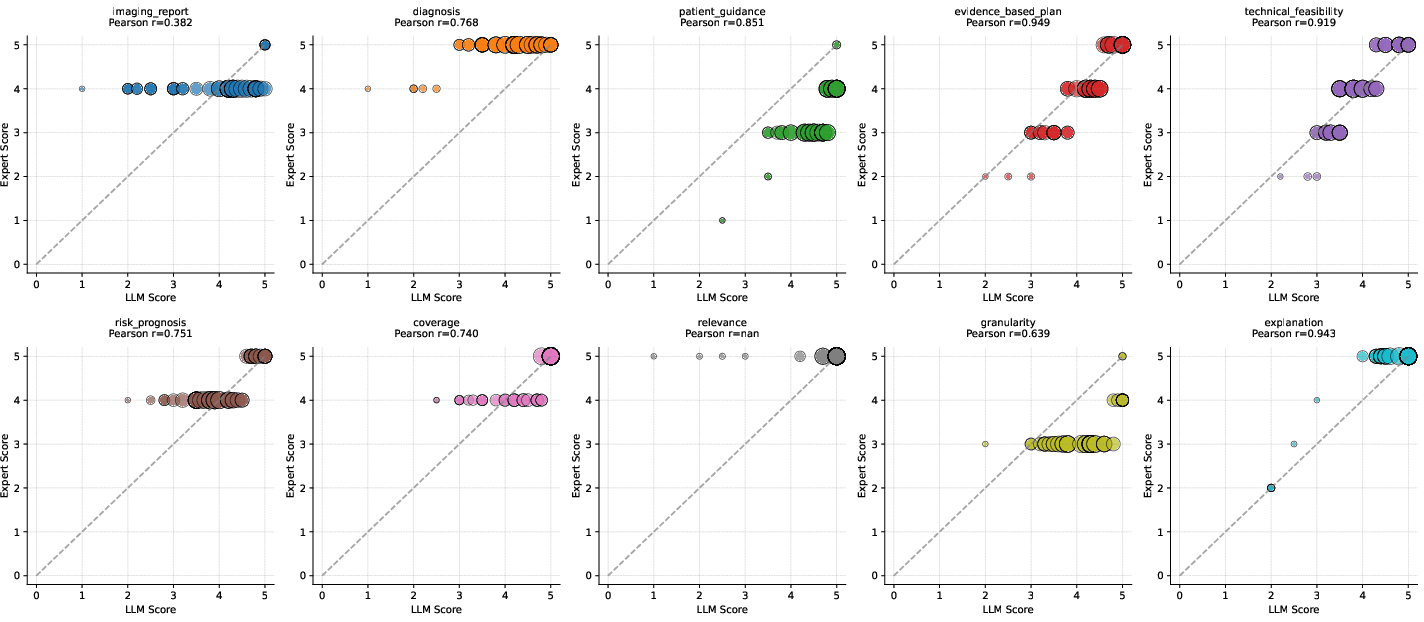
Figure 6: Consistency evaluation of large models and scores given by medical experts, showing strong alignment between LLM and expert assessments.
Pearson correlation coefficients between LLM and expert scores are consistently high (most >0.7), validating the reliability of the automated evaluation framework.
Qualitative Comparison: SpineGPT vs. Generalist LLMs

Figure 7: Comparative analysis of medical report generation for adolescent idiopathic scoliosis, showing SpineGPT's superior diagnostic depth and clinical reasoning compared to ChatGPT-4o.
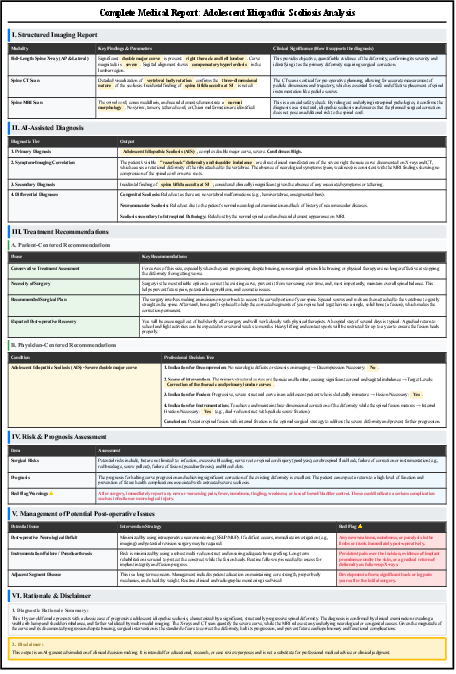
Figure 8: SpineGPT's structured medical report output, demonstrating comprehensive coverage of imaging, diagnosis, treatment, risk, and rationale.
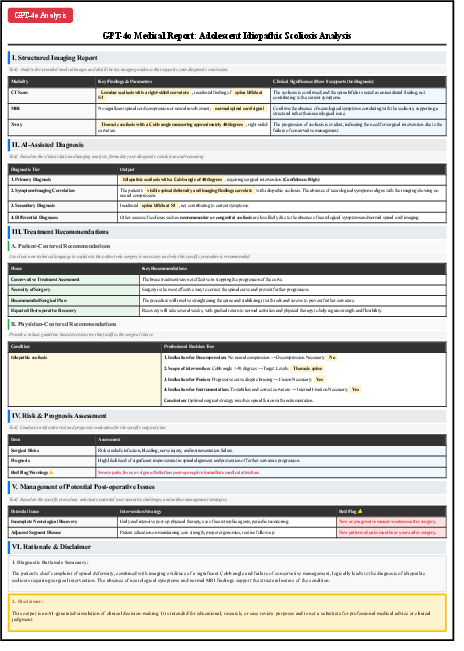
Figure 9: ChatGPT-4o's report output, illustrating the limitations of general-purpose LLMs in clinical specificity and depth.
SpineGPT produces 72% more detailed content, with quantified risk assessments, 3D surgical planning, and evidence-based protocols, while ChatGPT-4o provides only basic recommendations.
Implications and Future Directions
Practical Implications
- Clinical Utility: SpineMed-450k and SpineBench enable the development and rigorous evaluation of AI systems capable of clinically relevant, level-aware reasoning in spine care.
- Specialization vs. Generalization: The results underscore the necessity of domain-specific, provenance-rich instruction data for high-stakes clinical applications, as generalist models fail to meet the required granularity and accuracy.
- Automated Evaluation: The strong alignment between LLM-based and expert scoring supports scalable, reproducible benchmarking in medical AI.
Theoretical Implications
- Data-Centric AI: The study reinforces the paradigm that high-quality, domain-aligned data is a primary driver of performance in specialized clinical AI systems.
- Multimodal Reasoning: Persistent cross-modal performance gaps highlight the need for further research in vision-language alignment, particularly for complex medical imaging tasks.
Future Work
- Expansion of the dataset to additional institutions and pathologies.
- Scaling model size beyond 7B parameters and exploring reinforcement learning for further performance gains.
- Direct, comprehensive benchmarking against leading proprietary models (e.g., GPT-4, Gemini) to establish clearer performance boundaries.
Conclusion
SpineBench and SpineMed-450k represent a significant advance in the infrastructure for clinically relevant, level-aware AI in spine care. The results demonstrate that specialized, clinician-curated instruction data is essential for enabling fine-grained, multimodal reasoning in high-stakes medical domains. The benchmark exposes systematic weaknesses in current LVLMs and provides a robust foundation for future research and development of clinically deployable AI systems in orthopedics and beyond.