- The paper introduces TemMed-Bench, a benchmark that evaluates LVLMs’ ability to reason over temporal changes using paired patient images.
- It employs multi-modal retrieval augmentation across VQA, report generation, and image-pair selection tasks to assess model performance.
- Experimental results reveal that even specialized medical LVLMs struggle with temporal reasoning, highlighting the need for enhanced retrieval and alignment strategies.
TemMed-Bench: A Benchmark for Temporal Medical Image Reasoning in Vision-LLMs
Motivation and Benchmark Design
TemMed-Bench addresses a critical gap in the evaluation of Large Vision-LLMs (LVLMs) for medical applications: the lack of temporal reasoning over longitudinal patient imaging. Existing benchmarks predominantly focus on single-visit image analysis, which diverges from clinical practice where physicians routinely compare current and historical images to assess disease progression or response to therapy. TemMed-Bench is constructed to evaluate LVLMs' ability to reason over temporal changes by providing paired images from different clinical visits and requiring models to analyze condition changes.
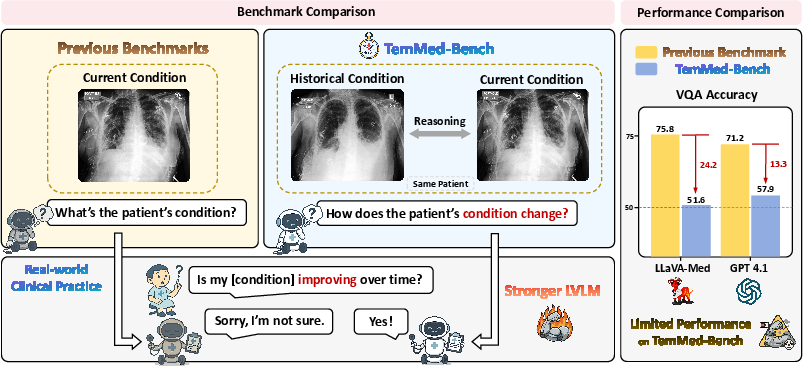
Figure 1: TemMed-Bench introduces temporal reasoning by requiring models to compare images from multiple visits, unlike previous single-visit benchmarks.
The benchmark comprises three tasks:
- Visual Question Answering (VQA): Binary questions about condition changes between two visits.
- Report Generation: Free-text reports describing changes between historical and current images.
- Image-Pair Selection: Given three image pairs and a medical statement, select the pair best matching the statement.
Each task is designed to probe different aspects of temporal reasoning, multi-image processing, and clinical language generation. The benchmark is supported by a knowledge corpus of over 17,000 instances, each containing an image pair and a corresponding change report.
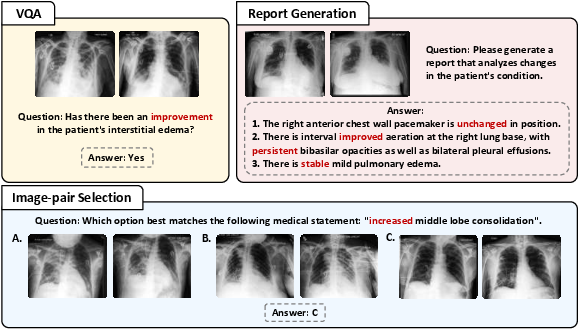
Figure 2: TemMed-Bench tasks challenge LVLMs to analyze condition changes, requiring comprehensive temporal reasoning.
Data Collection and Task Construction
Raw data is sourced from CheXpert Plus, leveraging reports that exclusively describe condition changes (e.g., "worsening effusion", "improved atelectasis"). Regular expressions and keyword matching are used to extract sentences indicating temporal changes. For each report, the corresponding current and most recent historical images are paired, resulting in 18,144 instances.
The VQA task is constructed by rephrasing each change-description sentence into a binary question using GPT-4o, with manual review for quality control. The image-pair selection task uses regular expressions to associate medical statements with image pairs, ensuring that distractor options share the same pathology but differ in change direction.
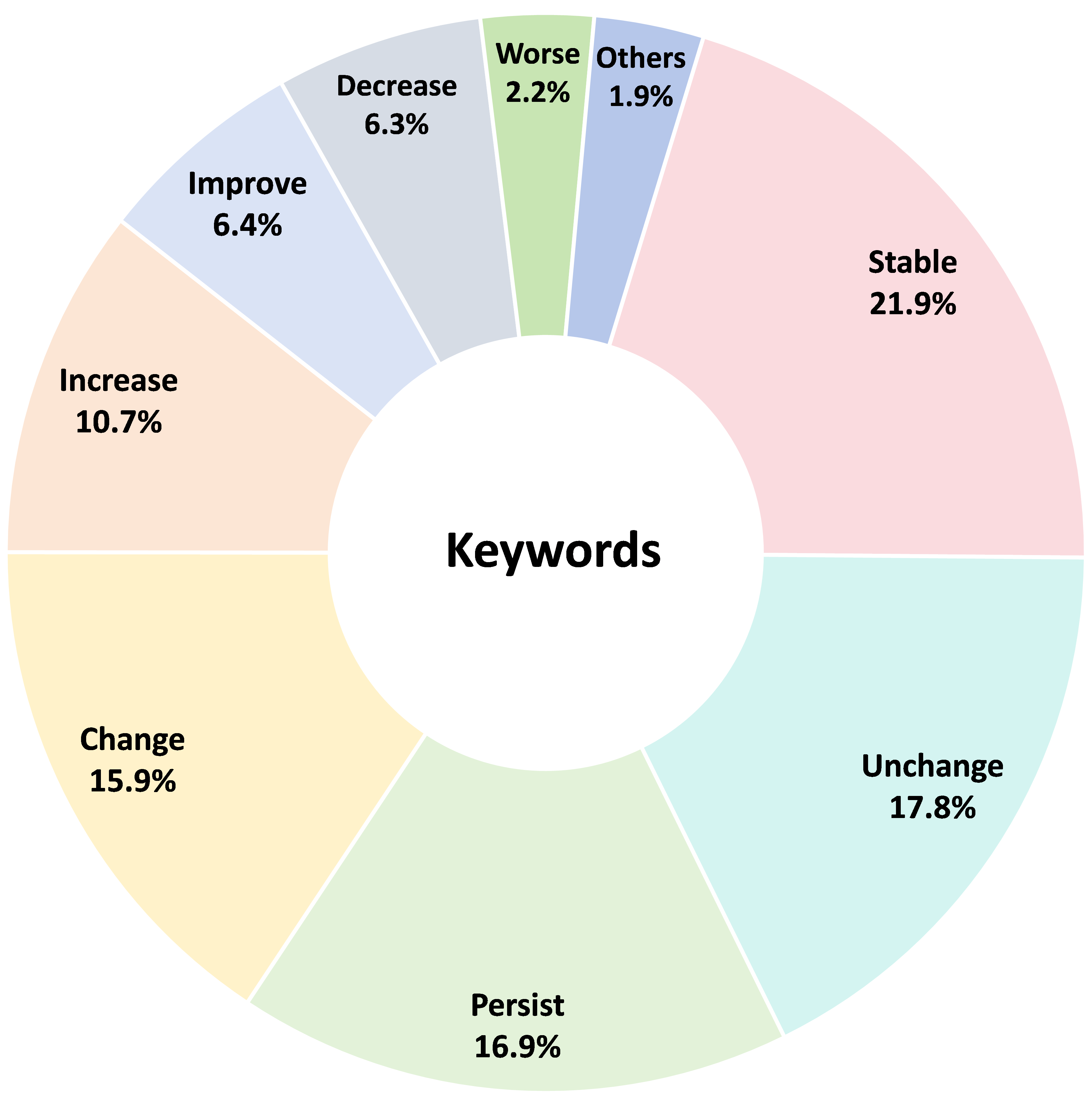
Figure 3: Distribution of keywords used to identify condition change sentences in the dataset.
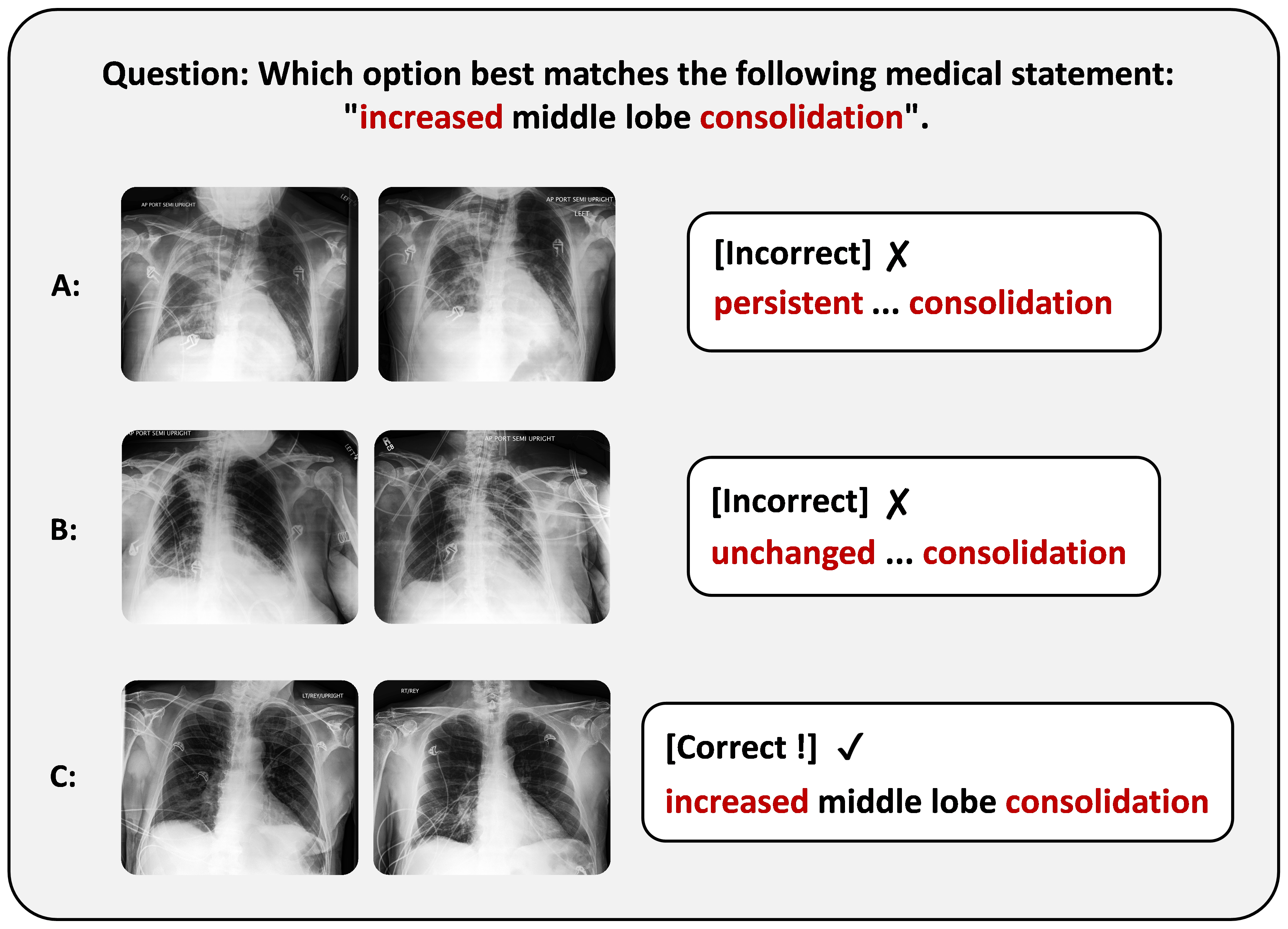
Figure 4: Example of image-pair selection data construction, illustrating the mapping of medical statements to image pairs.
Multi-Modal Retrieval Augmentation
TemMed-Bench enables evaluation of retrieval-augmented generation (RAG) in both text-only and multi-modal settings. The multi-modal RAG setting is novel in the medical domain, allowing retrieval of both images and associated reports. The retrieval process is formulated as follows:
- Pairwise Image Retrieval: For a query image pair (ih,ic), retrieve corpus instances (ih∗,ic∗,t∗) maximizing the sum of cosine similarities between historical and current images, ensuring alignment in both temporal states.
This approach outperforms conventional image-to-text and image-to-image retrieval, as the report semantics in TemMed-Bench are inherently tied to image pairs rather than single images.
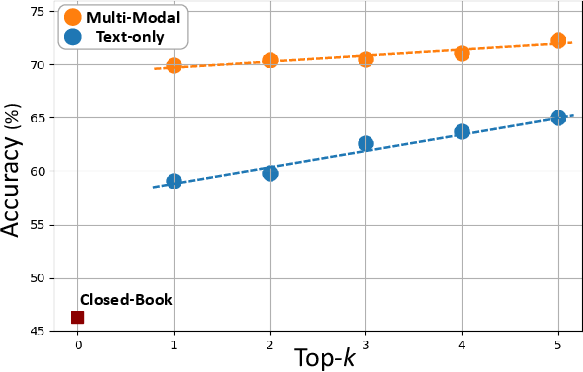
Figure 5: Ablation study demonstrates that pairwise image retrieval yields the highest accuracy and F1 in HealthGPT, especially in multi-modal RAG.
Experimental Results and Analysis
Twelve LVLMs (six proprietary, six open-source) are evaluated in both closed-book and retrieval-augmented settings. Metrics include accuracy and F1 for VQA, BLEU/ROUGE-L/METEOR for report generation, and accuracy for image-pair selection.
Closed-book results:
- Most LVLMs perform near random-guessing in VQA and image-pair selection.
- GPT o4-mini and Claude 3.5 Sonnet achieve the highest VQA accuracies (79.15% and 69.90%, respectively).
- Report generation scores are low across all models, with the best average at 20.67.
- Medical LVLMs do not outperform general-domain LVLMs, indicating that current medical fine-tuning erodes general reasoning capabilities.
Retrieval augmentation:
- Multi-modal RAG consistently yields higher performance gains than text-only RAG.
- HealthGPT shows a 23.6% increase in VQA accuracy with multi-modal RAG.
- Open-source LVLMs close the gap with proprietary models in VQA when augmented, but proprietary models retain superiority in report generation and image-pair selection.
- The image-pair selection task remains challenging for retrieval augmentation due to the need to align retrieved information with multiple candidate pairs, amplifying retrieval noise.
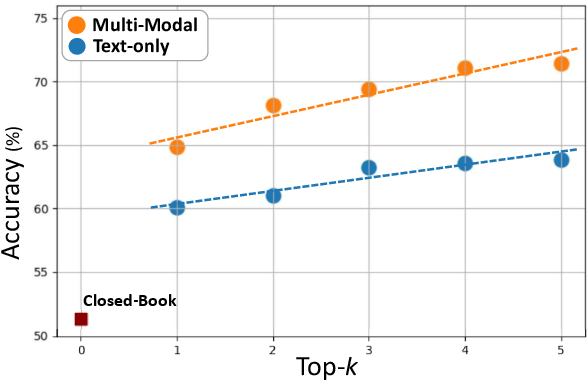
Figure 6: Top-1 to top-5 retrieval augmentation results for HealthGPT and GPT 4o, showing consistent gains for multi-modal RAG over text-only RAG.
Implications and Future Directions
TemMed-Bench reveals that current LVLMs lack robust temporal reasoning capabilities, a critical requirement for clinical deployment. The benchmark demonstrates that multi-modal retrieval augmentation is a promising direction, especially when retrieval is performed over image pairs rather than single images or text alone. However, the limited gains in complex tasks such as image-pair selection highlight the need for advanced retrieval and alignment strategies.
The finding that medical LVLMs do not generalize better than general-domain LVLMs suggests that future adaptation frameworks should preserve general reasoning while incorporating domain expertise. Additionally, the robustness of TemMed-Bench to top-1 retrieval hacks (i.e., simply copying the retrieved report) underscores its value for evaluating genuine reasoning rather than pattern matching.
Conclusion
TemMed-Bench provides a rigorous evaluation framework for temporal medical image reasoning in LVLMs, reflecting real-world clinical workflows. The benchmark exposes fundamental limitations in current models and demonstrates the efficacy of multi-modal retrieval augmentation. Future research should focus on developing LVLMs with enhanced temporal reasoning, robust multi-image processing, and improved integration of retrieved multi-modal information, with the ultimate goal of reliable clinical decision support.