- The paper introduces a novel 3D-aware VLM that enriches non-robotic images with 3D cues to efficiently learn robot control policies.
- The paper employs a staged training pipeline combining VLM pretraining, 3D-aware fine-tuning, and action expert training to significantly reduce reliance on extensive robot demonstration data.
- The paper demonstrates state-of-the-art performance in both simulations and real-world tests, achieving up to 10% higher success rates with drastically fewer training frames.
SPEAR-1: Data-Efficient Robotic Foundation Models via 3D-Aware Vision-Language Backbones
Motivation and Problem Definition
The proliferation of vision-language-action (VLA) models has drawn attention to their inherent limitations in generalizing control policy across unseen robot embodiments, environments, and tasks. Central to this bottleneck is the over-reliance on internet-pretrained vision-LLMs (VLMs), which predominantly operate on 2D image-language pairs and lack grounded 3D spatial reasoning—an essential prerequisite for robotic manipulation in real-world environments. Directly bridging this gap with large-scale robot demonstration data is both costly and logistically unscalable, particularly for diverse scene distributions and camera intrinsics. SPEAR-1 addresses this defect by introducing explicit 3D awareness into the VLM backbone using comparatively accessible non-robotic image datasets, enriched with 3D spatial annotations, then bootstrapping these representations for efficient robot action policy learning.
Staged Training Pipeline and Architectural Innovations
The SPEAR-1 methodology consists of a progressive, three-stage pipeline that enables high transferability and zero-shot policy deployment in real-world robotic settings:
- General VLM Pretraining: SPEAR-1 inherits common-sense semantics from large-scale internet VLMs (e.g., PaliGemma).
- 3D-Aware VLM Fine-Tuning: By integrating a monocular depth encoder (MoGe) with SigLIP, the model is tasked to solve embodied VQA problems—such as 3D keypoint localization and object-to-object 3D distance estimation—on 2D images that have been enriched with automatically generated 3D cues.
- Action Expert Training: The model is further augmented with an action expert, trained on ∼45M frames from diverse Open X-Embodiment (OXE) datasets, to learn vision-language-action mappings via flow matching in mixed translation (R3) and rotation (S3 quaternion) spaces.
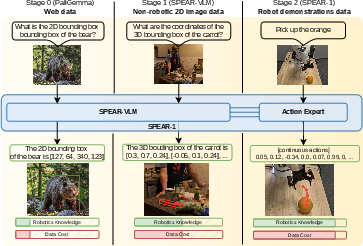
Figure 1: SPEAR-1's staged training schema learns first from internet-scale VLM corpora, then augments with depth cues and embodied VQA, and finally transitions to robot demonstration data for control policy learning.
This architecture allows SPEAR-VLM—SPEAR-1's backbone—to encode explicit geometric representations by fusing SigLIP and MoGe features and introducing 1024 dedicated 3D tokens into the language embedding space.
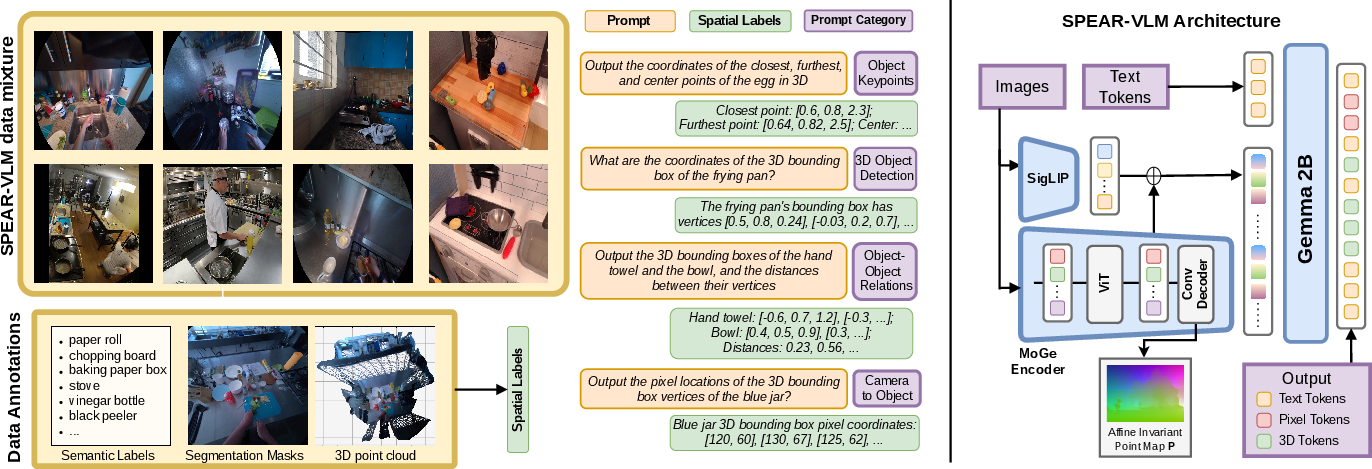
Figure 2: SPEAR-VLM architecture overview with explicit fusion of visual and depth features and embedding expansion for 3D tokenization.
3D VLM Enhancement and Data Annotation
Unlike prior attempts at spatially-aware robots, SPEAR-1 implements a rigorous VQA-driven pretraining protocol that targets explicitly control-relevant spatial reasoning. The annotation pipeline for 3D pretraining data leverages Gemini for 2D bounding box generation, SAM2 for instance segmentation, and MoGe for 3D point cloud prediction—even when only 2D images are available. Oriented bounding boxes, inter-object distances, and structured spatial prompts support both generalization and robustness to environmental diversity.
Experimental ablations confirm that object-level 3D VQA—rather than low-level pixel-based 3D cues—in SPEAR-VLM pretraining is the critical determinant of improved downstream VLA control performance. Models initialized with SPEAR-VLM significantly outperform those built upon vanilla PaliGemma when evaluated on both simulated and real distributions under substantial scene shift. Architecture-level ablations further emphasize that training both SigLIP and MoGe encoders before locking MoGe weights during VLA fine-tuning yields the highest success rates.

Figure 3: 3D ablation environments showcase training evaluation setups used to stress test zero-shot generalization over diverse backgrounds and object distributions.
Action Expert Design: Flow Matching on R3 and S3
The action expert leverages conditional flow matching across translation and rotation action components, with rotation modeled on the unit quaternion manifold for stability and robustness. This choice, in conjunction with global quantile normalization of control targets and action chunking at 5Hz, prevents dataset memorization and encourages shared policy learning across embodiments. Robust experimental design, including deterministic CUDA operations and EMA checkpointing, stabilizes evaluation outcomes.
Empirical Evaluation: Simulation and Real-World Robotic Manipulation
SPEAR-1 is extensively validated in both simulation (SIMPLER/WidowX) and real hardware (WidowX, Franka Research 3) platforms, using rigorous scoring rubrics across manipulation tasks with partial credit for sub-goal achievement. In simulation, SPEAR-1 achieves over 10% higher average success rate than SpatialVLA and OpenVLA. Real-world results are more striking: On WidowX, SPEAR-1 delivers an average task progress 10% higher than OpenVLA; on Franka, without any environment-specific fine-tuning, SPEAR-1 matches or noticeably outperforms both π0-FAST and π0.5 policies, despite being trained on 20× fewer robot demonstration frames and less diverse environments.
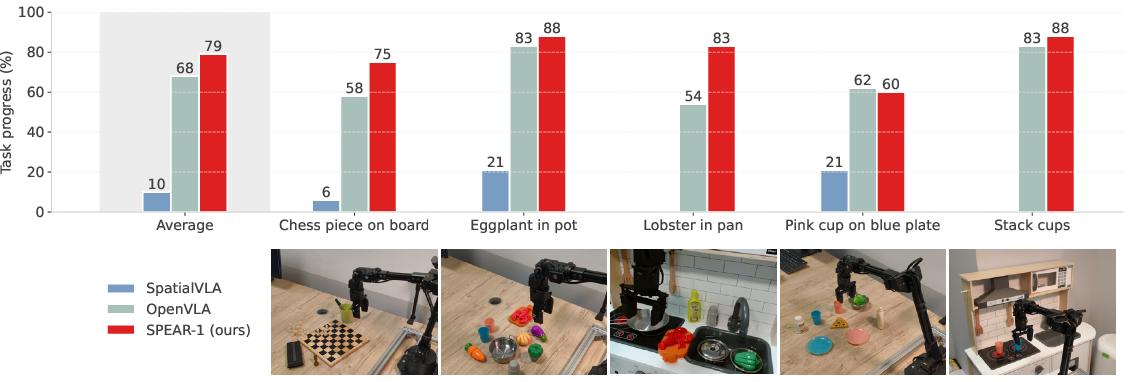
Figure 4: SPEAR-1's real-world performance on WidowX, exhibiting consistently higher task progress across a variety of manipulation challenges relative to OpenVLA.
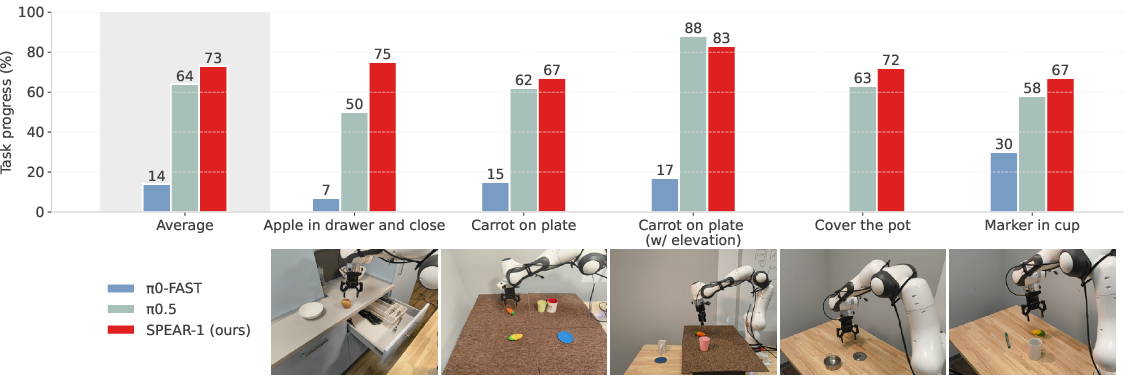
Figure 5: On Franka, SPEAR-1 matches π0.5 zero-shot performance and exceeds π0-FAST, with no target environment fine-tuning, demonstrating superior data efficiency.
Implications and Future Directions
SPEAR-1 provides compelling empirical evidence that substantial generalization in embodied robotic policies is achievable with dramatically less robot demonstration data if appropriately enriched VLM backbones are used. The findings suggest that explicit 3D pretraining on non-robotic image datasets presents a scalable alternative to large-scale robot data collection, particularly for diverse or out-of-distribution deployment scenarios. The approach catalyzes future work in model architectures capable of handling deformable or non-rigid objects and in refining metrics for VLM-derived 3D tokenization. There remains unexplored territory linking scaling laws for VLM pretraining data and transfer efficacy to robot control, as well as strategies for eliminating target-specific embodiment fine-tuning.
Conclusion
SPEAR-1 establishes that generalist robot policies can be robustly deployed across diverse platforms and environments, using an architecture that explicitly encodes 3D spatial reasoning in a vision-language backbone. Empirical results demonstrate state-of-the-art or superior performance with orders-of-magnitude less robot demonstration data, validating the hypothesis that non-robotic 3D annotation is a scalable proxy for acquiring control-relevant embodied knowledge. This work strongly advocates for future robotic foundation models to prioritize architectural and data-centric enhancements in the VLM pretraining stage to achieve substantial generalization and data efficiency in embodied AI.
Reference: SPEAR-1: Scaling Beyond Robot Demonstrations via 3D Understanding (2511.17411)