- The paper presents WALL-OSS, a novel framework that tightly couples vision, language, and action via a Mixture-of-Experts transformer.
- It introduces a staged training curriculum integrating embodied VQA and continuous action modeling to enhance spatial reasoning and action synthesis.
- Empirical evaluations demonstrate WALL-OSS achieves superior manipulation, zero-shot instruction following, and chain-of-thought reasoning compared to baselines.
WALL-OSS: Tightly Coupled Vision-Language-Action Foundation Model for Embodied AI
Motivation and Problem Statement
The paper addresses the persistent limitations of current vision-LLMs (VLMs) in embodied AI, specifically their insufficient spatial and action understanding when transferred to domains requiring physical interaction. Existing VLMs, despite their multimodal reasoning capabilities, are fundamentally disembodied: they lack the ability to generate executable actions and adapt through feedback from the physical world. This deficiency is rooted in three core gaps: (1) modality and data scale mismatch, (2) pretraining distribution misalignment, and (3) incompatible training objectives for action modeling.

Figure 1: Current VLMs lack sufficient spatial and action understanding for embodied AI; WALL-OSS bridges this gap, enabling complex action generation.
Architectural Innovations
WALL-OSS introduces a tightly coupled Mixture-of-Experts (MoE) transformer architecture that unifies vision, language, and action modalities. Unlike prior mixed or decoupled paradigms, which either disrupt pretrained VLM priors or fail to tightly bind semantics to control, WALL-OSS assigns distinct feed-forward networks (FFNs) to different training tasks, enabling robust cross-modal association and preserving VL priors during action learning.
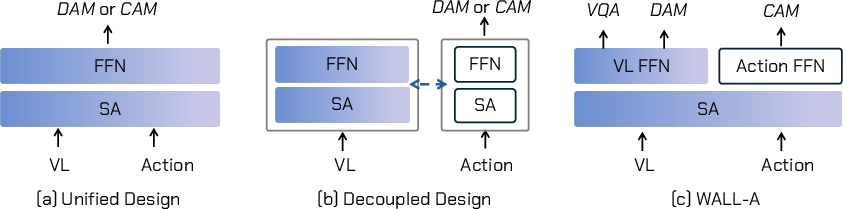
Figure 2: Paradigms for transferring VLMs to action modeling: mixed, decoupled, and WALL-OSS’s tightly coupled MoE design.
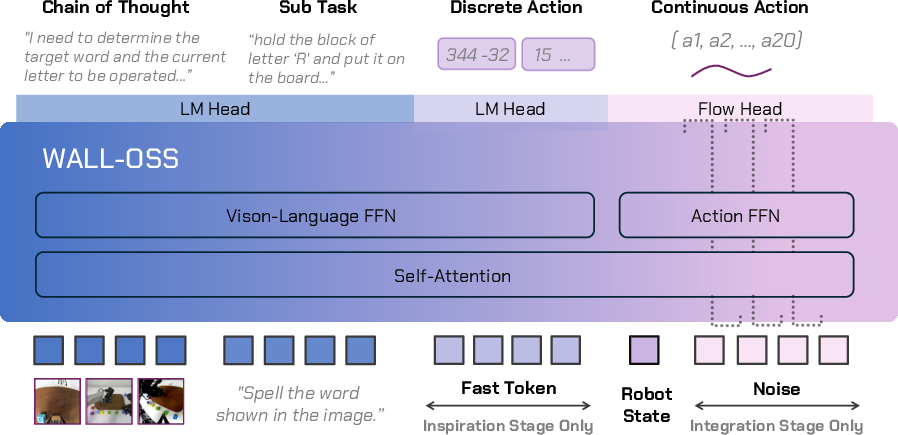
Figure 3: Architecture of WALL-OSS, showing multimodal input processing and expert routing for vision, language, and action.
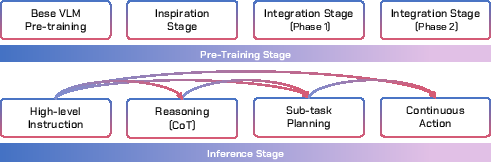
Training Curriculum: Inspiration and Integration
The training pipeline is staged to systematically address the modality, distribution, and objective gaps:
Unified Cross-Level Chain-of-Thought (CoT)
WALL-OSS generalizes chain-of-thought reasoning to span the full semantic-to-sensorimotor spectrum: from high-level instructions, through reasoning and subtask decomposition, to continuous actions. The model supports flexible forward mapping, allowing it to condition on or bypass intermediate reasoning steps as needed. This end-to-end differentiable framework avoids the error accumulation and non-differentiable interfaces of pipeline-based agents, enabling robust instruction following and long-horizon planning.
Data Composition and Multisource Aggregation
To overcome the scarcity of aligned vision-language-action (VLA) data, the authors construct a multisource dataset exceeding 10,000 hours, comprising:
Experimental Evaluation
The evaluation suite includes an embodied VQA benchmark and six manipulation tasks, targeting instruction understanding, long-horizon planning, and action accuracy. Tasks range from single-instruction (Pick-Up-Waste, Place-by-Color) to complex, multi-stage routines (Set-Table, Tidy-Bedroom).

Figure 6: Overview of evaluation tasks, spanning single-instruction and long-horizon reasoning challenges.
WALL-OSS is compared against π0 (VLM+flow matching) and Diffusion-Policy (action diffusion without VLM initialization), under both flat and subtask-decomposition training paradigms. Rigorous blind third-party testing ensures objective assessment.
Results
Embodied Scene Understanding
WALL-OSS achieves substantial improvements over the base VLM in embodied VQA:
| Model |
Object Grounding |
Scene Captioning |
Action Planning |
| Qwen2.5-VL-3B |
46.1% |
57.7% |
59.8% |
| WALL-OSS |
91.6% |
87.6% |
69.0% |
Pretraining injects robot-centric scene knowledge, enabling accurate localization and description in manipulation contexts.
Zero-Shot Generalization
WALL-OSS demonstrates strong zero-shot instruction following, achieving 85% progress on seen-object instructions and 61% on novel-object instructions. Failures are primarily due to pose inaccuracies, not semantic misinterpretation.
Action Accuracy and Robustness
With sufficient demonstrations, WALL-OSS and π0 reach 100% success on in-distribution tasks, while Diffusion-Policy lags at 80%. For more complex or data-scarce tasks, WALL-OSS maintains >90% success, whereas DP drops below 20%. In out-of-distribution settings, WALL-OSS and π0 retain >80% success, while DP fails completely.
Subtask Generation and Long-Horizon Planning
WALL-OSS, trained with only 1% subtask-labeled data, reliably generates high-quality subtask instructions, outperforming baselines on Set-Table and Tidy-Bedroom. Baselines suffer from stage confusion and error accumulation, while WALL-OSS maintains coherent progression and disambiguates plausible actions.
Chain-of-Thought Reasoning
CoT prompting is essential for reasoning-intensive tasks. In Place-by-Color and Block-Spell, WALL-OSS significantly outperforms baselines, especially under conditions requiring intermediate logical inference. Baseline models fail to align high-level policy with low-level execution, leading to poor performance.
Multi-modal Co-training
Joint training on action, CoT/subtask generation, and 2D referring expression grounding yields superior instruction-following accuracy:
| Block Type |
WALL-OSS (Co-training) |
WALL-OSS (Action-only) |
π0 (Action-only) |
| Letter |
87% |
26% |
9% |
| Number |
95% |
80% |
35% |
Multi-modal co-training is critical for fine-grained instruction adherence.
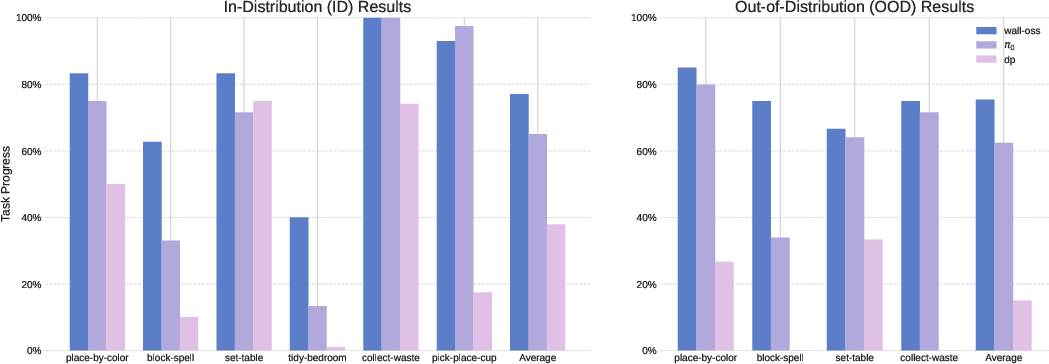
Figure 7: Performance comparison with state-of-the-art policies across all evaluation tasks, showing both in-distribution and out-of-distribution results.
Theoretical and Practical Implications
WALL-OSS demonstrates that tightly coupled multimodal reasoning and action modeling can be achieved without a zero-sum trade-off between VL and action capabilities. The staged curriculum and MoE architecture enable scalable, unified mapping from high-level instructions to fine-grained actions, supporting flexible inference and robust generalization.
The results suggest that end-to-end differentiable architectures, augmented with embodied VQA and unified CoT, are key to advancing embodied foundation models. The approach validates the feasibility of scaling VLMs to embodied intelligence, with strong empirical gains in reasoning, planning, and manipulation.
Future Directions
The paper highlights the qualitative distinctness of action signals—sparse, high-dimensional, and requiring alignment between high-level reasoning and low-level control. Intermediate modalities (e.g., 3D perception, future-frame prediction) may further reduce the difficulty of VL→A mapping. The relative efficiency of strictly end-to-end versus intermediate-route approaches remains an open question, contingent on data and algorithmic advances in adjacent industries.
Conclusion
WALL-OSS establishes a principled framework for bridging the semantic-sensorimotor divide in embodied AI. Through architectural coupling, staged curriculum, and unified CoT reasoning, it achieves state-of-the-art performance in manipulation, reasoning, and instruction following. The open-sourcing of code and checkpoints facilitates reproducible research and community development, marking a significant step toward general-purpose embodied foundation models.