- The paper presents a joint MLLM-WM architecture that bridges semantic reasoning with physics-aware simulation for robust embodied AI.
- It demonstrates how multimodal large language models enable dynamic task decomposition and long-horizon planning in physical environments.
- It highlights practical applications in robotics, UAVs, and industrial automation while outlining future research directions for lifelong learning and explainability.
Embodied AI: Integrating LLMs and World Models
Introduction and Conceptual Foundations
The paper "Embodied AI: From LLMs to World Models" (2509.20021) presents a comprehensive survey and synthesis of the embodied AI paradigm, emphasizing the convergence of LLMs, Multimodal LLMs (MLLMs), and World Models (WMs) as the foundation for advancing artificial general intelligence (AGI) in physical environments. Embodied AI is defined as the closed-loop integration of active perception, embodied cognition, and dynamic interaction, with hardware embodiment as a critical enabler for real-world deployment under latency and energy constraints.
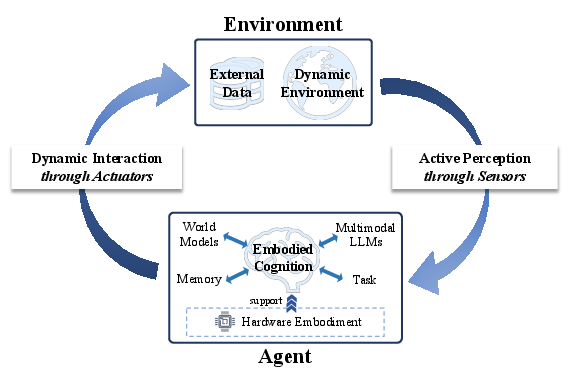
Figure 1: The concept of embodied AI, illustrating the closed-loop between perception, cognition, and interaction.
The historical trajectory of embodied AI is traced from Turing’s embodied intelligence hypothesis, through behavior-based robotics, to the current learning-driven paradigm. The paper identifies the limitations of unimodal approaches and motivates the shift to multimodal integration, which is essential for robust, adaptive agents in dynamic environments.
Key Technologies and Multimodal Evolution
Embodied AI is driven by advances in five foundational areas: Computer Vision (CV), NLP, Reinforcement Learning (RL), LLMs/MLLMs, and WMs. The integration of these technologies enables agents to interpret high-dimensional sensory inputs, understand and decompose tasks, and learn through interaction.
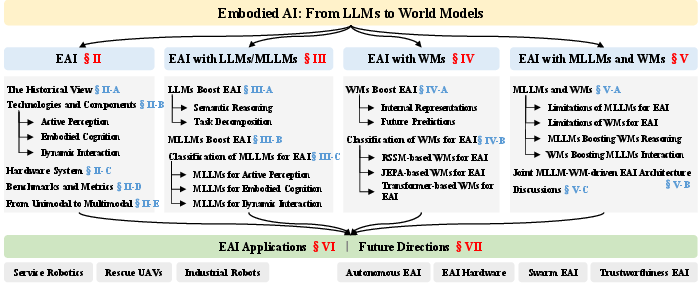
Figure 2: Overview of embodied AI basics, the role of LLMs/MLLMs and WMs, and the proposed joint architecture.
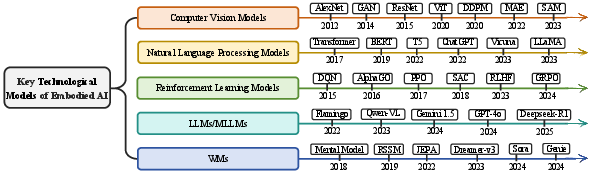
Figure 3: Key technological models of embodied AI, highlighting the contributions of CV, NLP, RL, LLMs/MLLMs, and WMs.
The transition from unimodal to multimodal embodied AI is analyzed, with unimodal systems shown to be limited by narrow information scope and poor cross-module transfer. Multimodal systems, leveraging MLLMs and WMs, enable mutual enhancement across perception, cognition, and interaction.
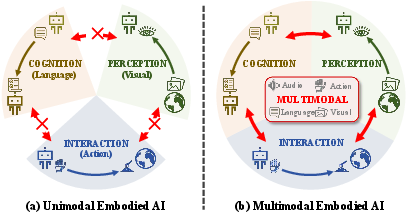
Figure 4: Comparison of unimodal and multimodal embodied AI, demonstrating the superiority of multimodal integration.
Embodied AI with LLMs and MLLMs
LLMs empower embodied AI through semantic reasoning and hierarchical task decomposition, mapping high-level natural language instructions to actionable steps. However, LLM-driven systems are constrained by static action libraries and limited adaptability to new robots and environments.
MLLMs extend LLMs by enabling cross-modal comprehension and end-to-end embodied applications. Vision-LLMs (VLMs) and Vision-Language-Action models (VLAs) are discussed as key architectures for integrating perception and action. MLLMs facilitate semantic reasoning from multimodal inputs and dynamic task decomposition, but often lack grounding in physical constraints and real-time adaptation.
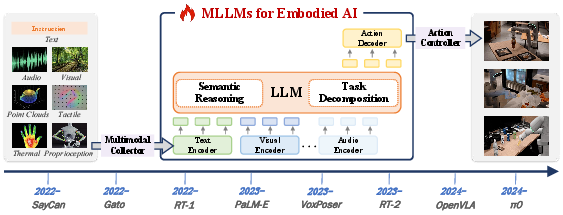
Figure 5: Development roadmap of MLLMs for embodied AI, highlighting conceptual and practical milestones.
MLLMs are shown to enhance active perception (semantic SLAM, 3D scene understanding), embodied cognition (self-planning, memory-driven reflection), and dynamic interaction (action control, behavioral trajectories, collaborative decision-making).
Embodied AI with World Models
WMs provide internal representations and future predictions of the external world, enabling agents to simulate and plan actions in compliance with physical laws. The paper categorizes WMs into RSSM-based, JEPA-based, and Transformer-based architectures, each with distinct strengths in temporal modeling, semantic abstraction, and memory-intensive reasoning.
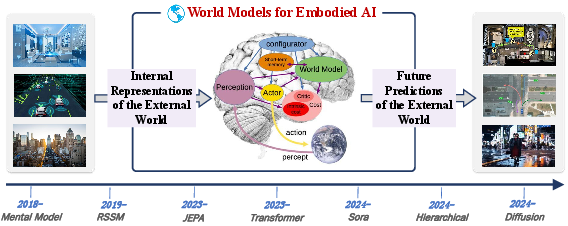
Figure 6: Development roadmap of WMs for embodied AI, showing key architectural milestones.
RSSM-based WMs (e.g., Dreamer family) optimize latent trajectory planning via probabilistic and deterministic state decomposition. JEPA-based WMs prioritize semantic feature extraction in abstract latent spaces, supporting transfer learning and generalization. Transformer-based WMs leverage attention mechanisms for persistent memory and explicit reasoning, with frameworks like Genie enabling large-scale self-supervised video pretraining for synthetic environment generation.
Joint MLLM-WM Architectures: Synergy and Limitations
The paper argues for a joint MLLM-WM-driven architecture, where MLLMs inject semantic knowledge for task decomposition and long-horizon reasoning, while WMs provide physics-aware simulation and real-time predictive control. This synergy bridges the gap between high-level semantic intelligence and grounded physical interaction.
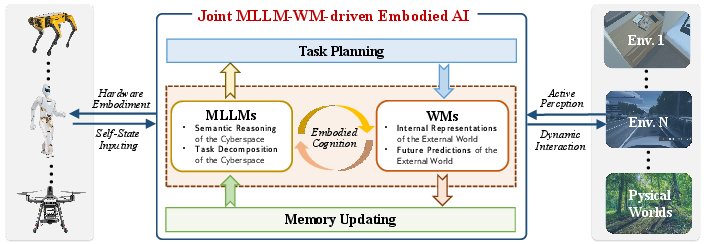
Figure 7: Joint MLLM-WM architecture for embodied AI, illustrating bidirectional enhancement between semantic reasoning and physical simulation.
MLLMs alone suffer from poor physics compliance and real-time adaptation; WMs alone lack abstract reasoning and generalizable task decomposition. The joint architecture enables semantic plans to be refined through physical feasibility checks, supports lifelong learning via structured memory, and enhances cross-task generalization.
A qualitative comparison (see Table IV in the paper) demonstrates that the joint MLLM-WM approach achieves high performance across semantic understanding, task decomposition, physics compliance, future prediction, real-time interaction, memory structure, and scalability.
Applications and Practical Implications
Embodied AI is applied in service robotics, rescue UAVs, industrial robots, and other domains. In service robotics, joint MLLM-WM architectures enable flexible, long-horizon task execution and robust adaptation to changing environments. In rescue UAVs, embodied AI supports real-time environmental sensing, autonomous decision-making under uncertainty, and multi-agent coordination. Industrial robots benefit from adaptive manipulation and path planning, leveraging multimodal perception and world modeling.
The paper highlights the limitations of current approaches in handling long-horizon reasoning and autonomy, and positions joint MLLM-WM architectures as the key to overcoming these challenges.
Future Directions
The paper identifies several future research directions:
- Autonomous Embodied AI: Development of agents capable of lifelong, adaptive operation in open environments, integrating dynamic perception, environmental awareness, and real-time physical interaction.
- Embodied AI Hardware: Advances in model compression, compiler optimization, domain-specific accelerators, and hardware-software co-design for efficient, real-time deployment.
- Swarm Embodied AI: Collaborative perception and decision-making among multiple agents, requiring shared world models, multi-agent representation learning, and natural human-swarm interfaces.
- Explainability and Trustworthiness: Benchmarks and mechanisms for real-time, human-understandable justifications, ethical decision-making, safety guarantees, and robustness against adversarial conditions.
- Lifelong Learning and Human-in-the-Loop: Continuous skill acquisition, memory management, and integration of human feedback for improved performance and alignment with human values.
Conclusion
This paper provides a rigorous synthesis of embodied AI, emphasizing the necessity of integrating MLLMs and WMs to achieve robust, adaptive, and generalizable intelligence in physical environments. The joint architecture addresses the limitations of unimodal and single-model approaches, enabling agents to balance semantic reasoning with physics-based interaction. The implications for real-world deployment are substantial, with applications spanning robotics, UAVs, manufacturing, education, and space exploration. Future research must address challenges in real-time synchronization, semantic-physical alignment, scalable memory management, and explainability to realize the full potential of embodied AI systems.

