- The paper presents a novel co-evolutionary framework where a Challenger generates challenging tasks and a Solver improves its reasoning using uncertainty-based rewards.
- The framework achieves measurable performance gains, with improvements such as a 5.51 point increase on Qwen3-8B and notable transfer to general-domain reasoning tasks.
- The study demonstrates that self-generated pseudo-labels and iterative curriculum learning effectively serve as a foundation for subsequent supervised fine-tuning and scalable autonomous AI.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Introduction and Motivation
R-Zero introduces a fully autonomous framework for self-evolving LLMs that eliminates the need for any human-curated tasks or labels. The core innovation is a co-evolutionary loop between two independently optimized models—a Challenger and a Solver—both initialized from a single base LLM. The Challenger is incentivized to generate tasks at the edge of the Solver’s current capabilities, while the Solver is trained to solve these increasingly difficult tasks. This process yields a self-improving curriculum, enabling the LLM to bootstrap its reasoning abilities from scratch.
(Figure 1)
Figure 1: (Left) R-Zero employs a co-evolutionary loop between Challenger and Solver. (Right) R-Zero achieves strong benchmark gains without any pre-existing tasks or human labels.
The framework is motivated by the limitations of prior self-evolving and label-free RL approaches, which either require a pre-existing corpus of tasks or rely on external oracles for verification. R-Zero addresses these bottlenecks by leveraging internal uncertainty and self-consistency as reward signals, thus enabling scalable, fully unsupervised reasoning improvement.
Methodology
Co-Evolutionary Framework
R-Zero operates in an iterative loop, alternating between Challenger and Solver training phases. Both models are initialized from the same base LLM but are optimized independently. The Challenger is trained to generate maximally challenging questions for the current Solver, while the Solver is fine-tuned to solve these questions.
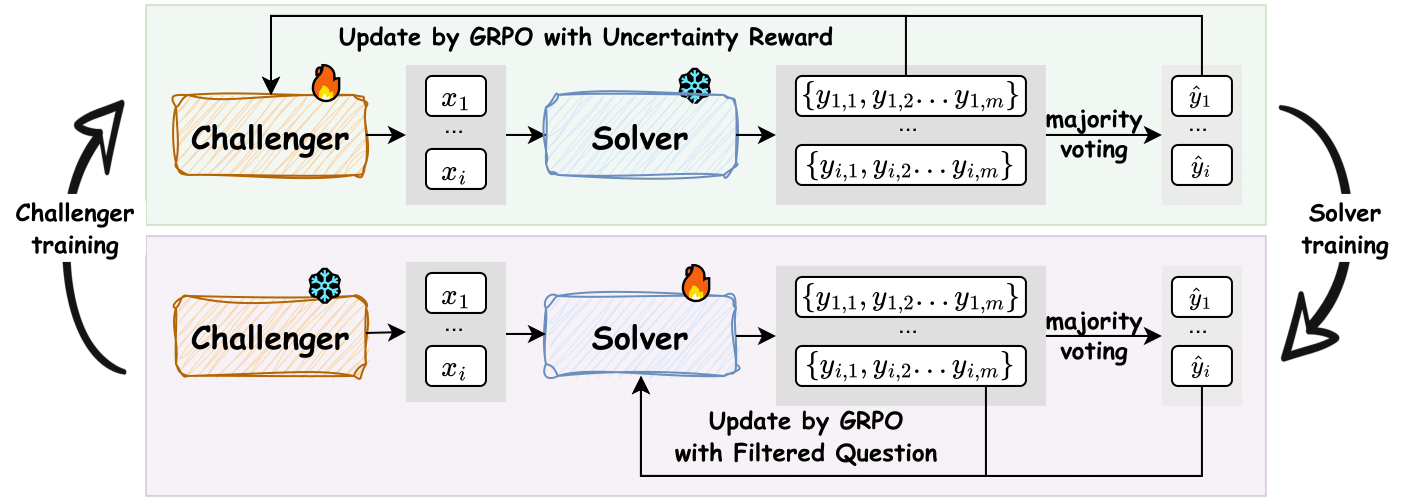
Figure 2: Overview of the R-Zero framework, illustrating the co-evolution of Challenger and Solver via GRPO and self-consistency-based rewards.
Challenger Training
- Objective: Generate questions that maximize the Solver’s uncertainty.
- Reward Signal: The Challenger receives a reward based on the self-consistency of the Solver’s answers. For each generated question, the Solver produces m answers; the empirical accuracy p^ is the fraction matching the majority-vote pseudo-label. The uncertainty reward is runcertainty=1−2∣p^−0.5∣, maximized when the Solver is maximally uncertain (i.e., p^≈0.5).
- Diversity Penalty: A repetition penalty is applied using BLEU-based clustering to discourage semantically similar questions within a batch.
- Format Check: Only questions adhering to a strict output format are considered valid; others receive zero reward.
- Optimization: Group Relative Policy Optimization (GRPO) is used for stable RL-based policy updates.
Solver Dataset Construction
- Filtering: From a large pool of Challenger-generated questions, only those with empirical correctness within a band around 50% (e.g., ∣p^−0.5∣≤δ) are retained. This ensures the curriculum is neither too easy nor too hard and filters out ambiguous or ill-posed questions.
- Pseudo-Labeling: The majority answer from the Solver is used as the pseudo-label for each question.
Solver Training
- Objective: Fine-tune the Solver to answer the curated set of challenging questions.
- Reward Signal: For each question, the Solver’s answers are compared to the pseudo-label; a binary reward is assigned.
- Optimization: GRPO is again used for policy updates.
Theoretical Motivation
The uncertainty-based reward is theoretically justified by curriculum learning theory: the KL divergence between the Solver’s current and optimal policies is lower-bounded by the variance of the reward, which is maximized when the Solver’s success probability is 0.5. Thus, the Challenger is incentivized to generate maximally informative tasks for the Solver at each stage.
Experimental Results
Mathematical Reasoning
R-Zero was evaluated on a suite of mathematical reasoning benchmarks (AMC, Minerva, MATH-500, GSM8K, Olympiad-Bench, AIME-2024/2025) using Qwen3 and OctoThinker models at 3B, 4B, and 8B scales. Across all architectures, R-Zero produced consistent, monotonic improvements over both the base model and a baseline where the Solver is trained on questions from an untrained Challenger.
- Qwen3-8B-Base: Average score increased from 49.18 (base) to 54.69 (+5.51) after three R-Zero iterations.
- Qwen3-4B-Base: Average score increased by +6.49 points.
- OctoThinker-3B: Improved from 26.64 to 29.32 (+2.68).
Performance gains were observed to be progressive and stable across iterations, confirming the efficacy of the co-evolutionary curriculum.
General-Domain Reasoning
Despite being trained only on self-generated math problems, R-Zero-trained models exhibited significant transfer to general-domain reasoning benchmarks (MMLU-Pro, SuperGPQA, BBEH):
- Qwen3-8B-Base: General-domain average improved by +3.81 points.
- OctoThinker-3B: Improved by +3.65 points.
This demonstrates that the reasoning skills acquired via self-evolution in mathematics generalize to broader domains.
Ablation Studies
Ablations on the Qwen3-4B-Base model revealed that all core components—RL-based Challenger, repetition penalty, and difficulty-based filtering—are critical. Disabling any of these led to substantial performance drops, with the largest degradation observed when RL training for the Challenger was removed.
Analysis of Co-Evolution Dynamics
- Question Difficulty: The Challenger generates progressively harder questions across iterations, as evidenced by declining Solver performance on fixed question sets.
- Pseudo-Label Accuracy: The accuracy of self-generated pseudo-labels decreases as question difficulty increases (from 79% to 63% over three iterations), indicating a trade-off between curriculum difficulty and label reliability.
- Reward Calibration: The framework successfully maintains the Solver’s success rate near 50% on contemporary Challenger questions, as intended by the reward design.
Synergy with Supervised Fine-Tuning
R-Zero provides a strong initialization for subsequent supervised fine-tuning. Models first improved by R-Zero achieve higher performance when later fine-tuned on labeled data, with gains of +2.35 points over direct supervised training. This demonstrates that R-Zero is complementary to, rather than redundant with, supervised approaches.
Implementation Considerations
- Resource Requirements: All experiments used BF16 mixed precision and FlashAttention 2 for efficiency. Training was performed with batch sizes of 128 and learning rates of 1×10−6.
- Scalability: The framework is model-agnostic and effective across different architectures and scales.
- Limitations: The current approach is best suited for domains with objective correctness criteria (e.g., mathematics). Extending to open-ended generative tasks remains an open challenge due to the lack of reliable internal reward signals.
Implications and Future Directions
R-Zero demonstrates that LLMs can self-evolve their reasoning abilities from zero external data, relying solely on internal uncertainty and self-consistency signals. This has significant implications for scalable, autonomous AI development, particularly in domains where human-labeled data is scarce or unavailable. The framework’s ability to generalize reasoning skills beyond the training domain suggests potential for broader applications.
Future work should address the declining reliability of pseudo-labels as task difficulty increases, explore more robust self-labeling mechanisms, and extend the paradigm to subjective or open-ended tasks. Additionally, integrating more sophisticated internal verifiers or leveraging model-based reward models could further enhance the framework’s applicability.
Conclusion
R-Zero establishes a fully autonomous, co-evolutionary framework for self-improving LLMs, achieving substantial gains in both mathematical and general reasoning without any human-provided data. The approach is theoretically grounded, empirically validated, and model-agnostic. While current limitations confine its applicability to domains with objective evaluation, R-Zero represents a significant advance toward scalable, self-evolving AI systems.

