- The paper proposes MoDES, a training-free framework that adaptively skips experts based on global layer importance and modality-specific thresholds.
- It employs globally-modulated local gating to compute token-wise expert importance and dual-modality thresholding to balance visual and textual token processing.
- Experiments demonstrate up to 10.67% accuracy improvements at high skipping ratios along with practical 2x inference speedups for large-scale multimodal models.
MoDES: Dynamic Expert Skipping for Efficient Mixture-of-Experts Multimodal LLMs
Introduction
The proliferation of multimodal LLMs (MLLMs), which integrate textual and visual modalities, responds to the increasing complexity and diversity of vision-language tasks. As these architectures scale, particularly with Mixture-of-Experts (MoE) layers, inference costs become a bottleneck for deployment in real-world scenarios. While MoE enables token-wise sparse activation to decouple parameter count from computation, static expert routing assumes uniform expert relevance, fundamentally limiting efficiency. Previous expert-skipping methods, designed for unimodal LLMs, fail to account for the heterogeneous global-layer contributions and modality-specific expert utility in MLLMs, resulting in pronounced performance degradation at high skipping ratios.
This paper introduces MoDES (Multimodal Dynamic Expert Skipping), a training-free inference acceleration framework for MoE MLLMs, leveraging globally-modulated local gating (GMLG) and dual-modality thresholding (DMT). MoDES adaptively skips experts conditioned on both layer-wise global importance and per-token modality, yielding superior efficiency–accuracy trade-offs, with strong empirical gains across diverse benchmarks and model architectures.
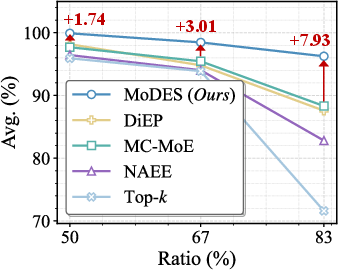
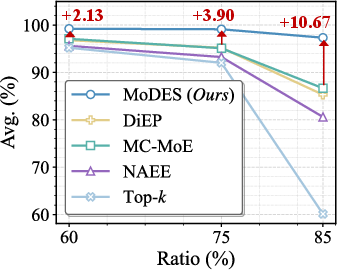
Figure 1: Average performance (%) plotted against expert skipping ratios (%) for Kimi-VL-A3B-Instruct and Qwen3-VL-MoE-30B-A3B-Instruct across multiple expert skipping algorithms.
Motivation: Global Layer Contribution and Modality Gap
Analysis of MoE MLLMs reveals two major factors absent from prior skip policies:
- Global Layer Importance: Shallow MoE layers exert disproportionate influence on final model outputs. Excessive expert skipping at early layers leads to amplified error propagation in downstream layers, causing severe performance drops. Empirically, top-k ablations confirm shallow-layer criticality, necessitating layer-aware skip schedules.
- Modality-Specific Expert Redundancy: The visual and textual token representations exhibit distinct dynamics through FFNs. t-SNE visualization (Figure 2, left) and cosine similarity quantification illustrate that vision tokens' representations change minimally after FFN passes, while text tokens undergo larger transformations. Angular analysis further attributes this to geometric orthogonality of vision tokens relative to expert weights.
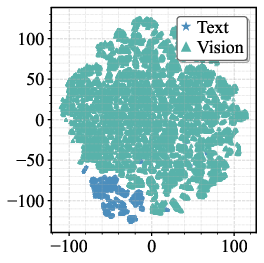
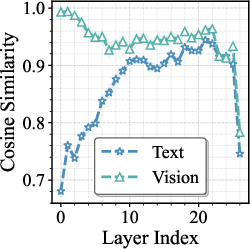
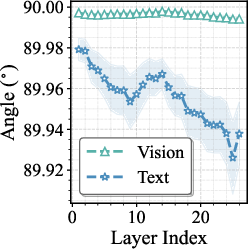
Figure 2: Left: t-SNE visualization demonstrates persistent modality-specific clustering of pre-FFN token embeddings across all layers.
Methods: Globally-Modulated Local Gating and Dual-Modality Thresholding
Globally-Modulated Local Gating (GMLG)
MoDES employs a composite token-wise expert importance score at each layer:
si(l)=α(l)⋅πi(l)
where πi(l) is the router's local activation probability, and α(l) is a calibrated global-layer factor quantifying the expected change in output distribution upon removal of all experts in layer l, computed via batchwise KL divergence over calibration samples. This approach efficiently couples data-informed output sensitivity (global) with instance-level token routing (local).
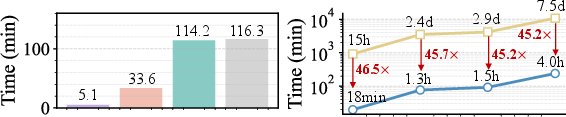
Figure 3: Left: Visualization of layerwise α(l) calibration times for MoDE models, demonstrating marked global importance for early layers.
Dual-Modality Thresholding (DMT)
Recognizing the modality gap, MoDES introduces token-type-specific thresholds: τt (text) and τv (vision). Only experts with si(l) above the respective threshold are activated for a given token. This design allows aggressive skipping for visually redundant layers without compromising textual prediction fidelity.
Threshold search leverages monotonicity assumptions for both accuracy degradation and computational savings as a function of thresholds. The frontier search algorithm efficiently finds optimal (τt,τv) pairs under target skipping ratios. Compared to naive grid search, this reduces calibration effort from si(l)=α(l)⋅πi(l)0 to si(l)=α(l)⋅πi(l)1, supporting large model deployment.
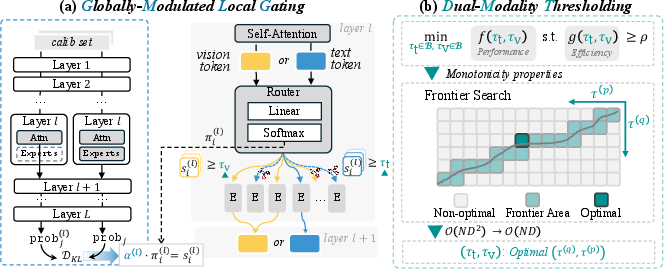
Figure 4: Schematic overview of MoDES token-wise inference routing: calculation of expert importance via GMLG and skip decision via DMT, with modality-aware thresholds.
Experimental Results
Comprehensive evaluations on 3 model families (Kimi-VL-A3B-Instruct, Qwen3-VL-MoE, InternVL-3.5) and 13 image/video benchmarks demonstrate that MoDES dominates prior baselines at every skipping ratio. For example, at an aggressive 88% skipping ratio in Qwen3-VL-MoE-30B-A3B-Instruct, MoDES improves accuracy by up to 10.67% over the strongest baselines while retaining 97.33% of the original model fidelity. High skipping ratios are feasible without significant accuracy loss due to modality-tailored schedules; in some cases, accuracy even increases due to removal of adversarial experts.
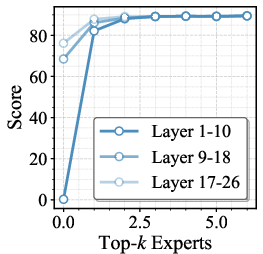
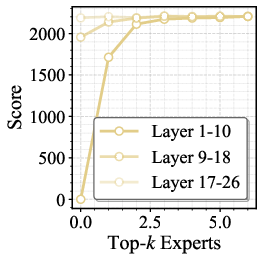
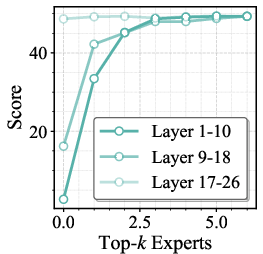
Figure 5: Performance curves on ChartQA, MME, and VideoMMMU as a function of number of routed experts applied to various layer ranges.
MoDES further supports synergistic compression: combined with mixed-precision quantization, it sustains over 90% accuracy for si(l)=α(l)⋅πi(l)23 bits-per-weight representation, outperforming previous skip+quantize methods by si(l)=α(l)⋅πi(l)34.5%. Inference profiling reveals practical speedups: %%%%14πi(l)15%%%% in prefilling and si(l)=α(l)⋅πi(l)61.2si(l)=α(l)⋅πi(l)7 in decoding. The method generalizes across backbone architectures and datasets, and threshold calibration is robust to the choice of dataset.
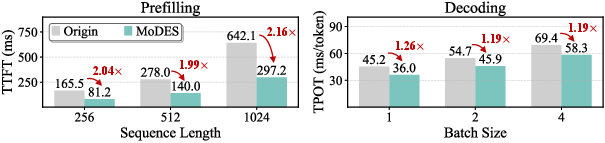
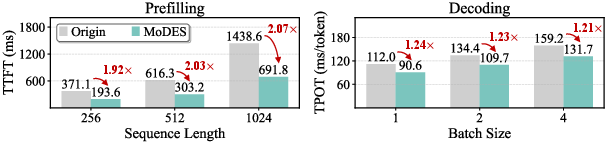
Figure 6: Inference speedups for Kimi-VL-A3B-Instruct (upper) and Qwen3-VL-MoE-30B-A3B-Instruct (lower) under high expert skipping ratios.
Ablation and Visualization
Ablation confirms the orthogonal value of GMLG and DMT: both substantially improve accuracy at matched efficiency, with the effect growing as skip ratio increases. Visualizations show that MoDES skips far more experts for vision tokens and in shallow layers, matching the analytic insights and justifying the dual-modality, layer-aware strategy.
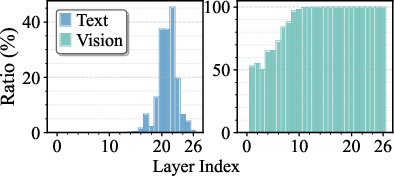
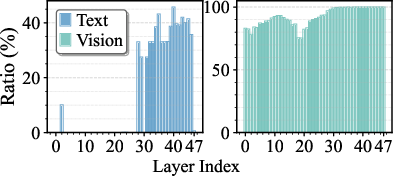
Figure 7: Layerwise expert skipping ratios for text and vision modalities in Kimi-VL-A3B-Instruct and Qwen3-VL-MoE-30B-A3B-Instruct, using high skip settings.
Qualitative examples confirm that model outputs under MoDES are consistently more accurate for multimodal reasoning tasks compared to prior methods.
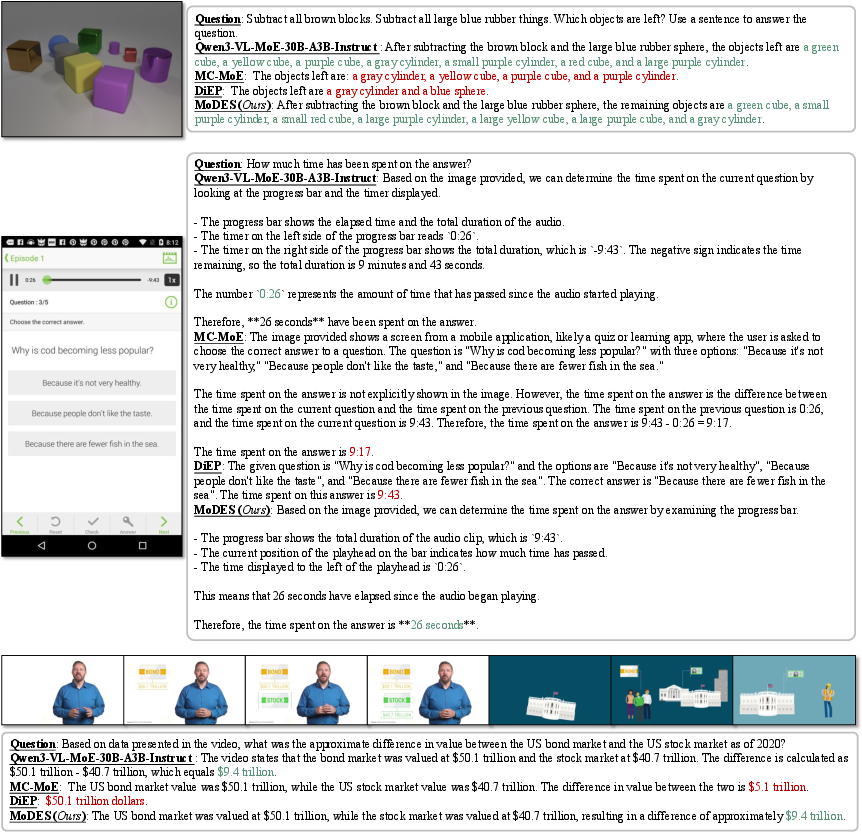
Figure 8: Visual understanding outputs from Qwen3-VL-MoE-A3B-Instruct under matched 88% skipping, colored by response correctness.

Figure 9: Visual understanding outputs from Kimi-VL-A3B-Instruct utilizing 83% skip ratio, showing strong factual consistency.
Implications and Future Directions
Practically, MoDES enables efficient and effective deployment of massive MoE MLLMs for production, serving large multimodal contexts and handling vision-language reasoning tasks at scale. Theoretically, its framework motivates further study into conditional, data-driven computation and routing within transformer-based systems. Future work may explore joint training of global-layer and local expert gating, advanced pruning/regrow strategies, and cross-modal transfer of skip policies. Extensions to speech and other modalities are natural candidates.
Conclusion
MoDES presents a principled, training-free approach for adaptive expert skipping in mixture-of-experts MLLMs, explicitly taking into account layerwise global importance and modality-specific expert redundancy. Its globally-modulated local gating combined with dual-modality thresholding consistently yields substantial inference speedup with minimal or zero compromise in accuracy, validated across multiple architectures and tasks. This direction paves the way for practical, scalable deployment of large MLLMs and sets a foundation for future advances in token-wise adaptive computation for multimodal reasoning systems.

