- The paper introduces a novel MoE approach by integrating heterogeneous expert sizes to dynamically match token complexity.
- It demonstrates significant empirical gains, such as MMLU accuracy improvements from 26.5% to 29.9% and SIQA EM increases from 42.9% to 60.9%.
- It ensures balanced computational load through an expert-pair allocation strategy, preserving inference efficiency in multi-GPU environments.
Mixture of Diverse Size Experts: A Comprehensive Analysis
Introduction
The "Mixture of Diverse Size Experts" (MoDSE) presents a significant architectural advancement for Mixture-of-Experts (MoE) models, addressing fundamental limitations of homogeneous expert structures in scaling LLMs. This work explores token-level adaptation to variable expert expressivity by introducing experts with heterogeneous parameter sizes within each MoE layer. The central claim is that routing tokens to experts of diverse sizes enhances model performance, especially for complex generative tasks, without increasing total parameter count or incurring substantial inference overhead. The paper also proposes an expert-pair allocation strategy that maintains computational load balance across multi-GPU training environments.
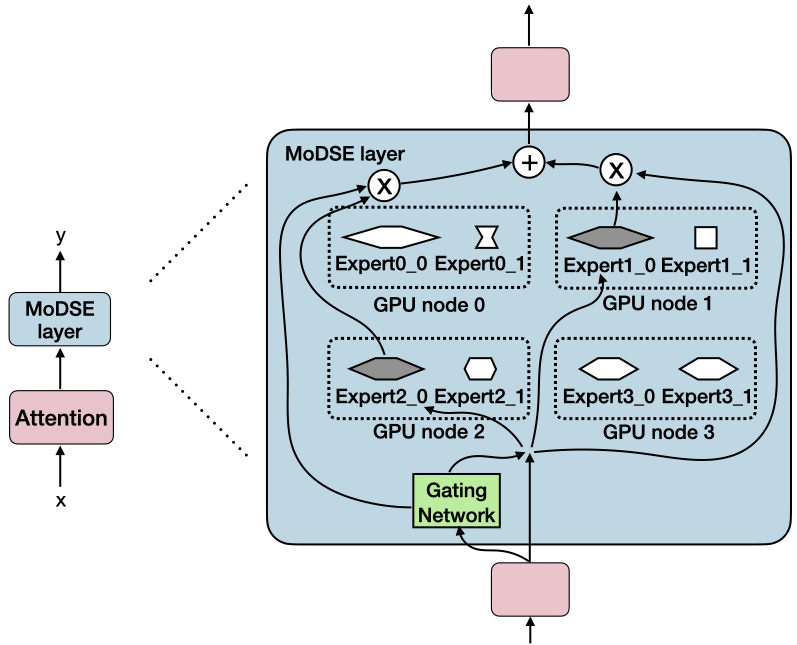
Figure 1: Overview of a MoDSE layer with different sizes of experts. In this case, expert1_0 and expert2_0 are selected. With the output of the gating network, the outputs of two experts are integrated.
Architecture and Methodology
MoDSE extends the conventional MoE/Transformer paradigm by allowing each expert within an MoE layer to have a distinct hidden dimension and parameter count. Gating networks are trained to route input tokens to those experts best suited, in terms of capacity, for handling tokens of varying prediction difficulty. Expert pairs are defined such that the sum of hidden dimensions across each pair remains constant, preserving both the total parameter budget and facilitating balanced distribution across devices. The auxiliary load balancing objective from Switch Transformer is retained and paired with the new expert-pair allocation strategy to enforce uniform expert utilization and workload distribution.
The architecture thereby enables adaptive allocation of representation capacity—difficult tokens are routed more frequently to larger experts, while simpler ones are serviced by smaller, more efficient networks.
Experimental Results
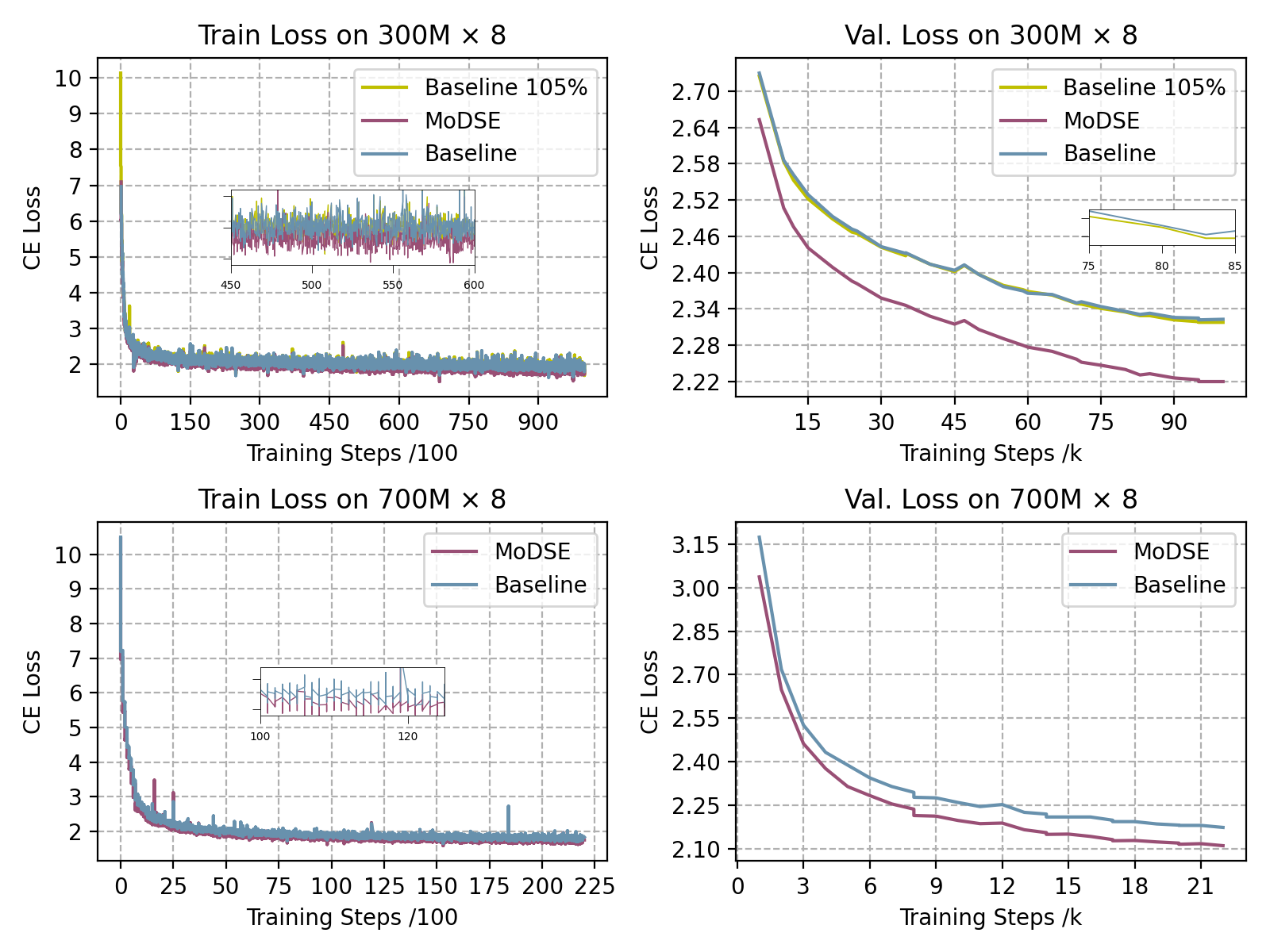
Experiments encompass models with 300M and 700M trainable parameters, each under both standard MoE and MoDSE settings. Downstream evaluation spans benchmarks including AGIEval, MMLU, GSM8K, LAMBADA, MATH, TriviaQA, PIQA, SIQA, and a custom intent classification task.
Key empirical findings:
Analysis of token routing reveals that, while early epochs display routing imbalances with preference toward smaller experts, the combination of routing regularization and expert-pair allocation leads to a nearly uniform token–expert mapping by the end of training.
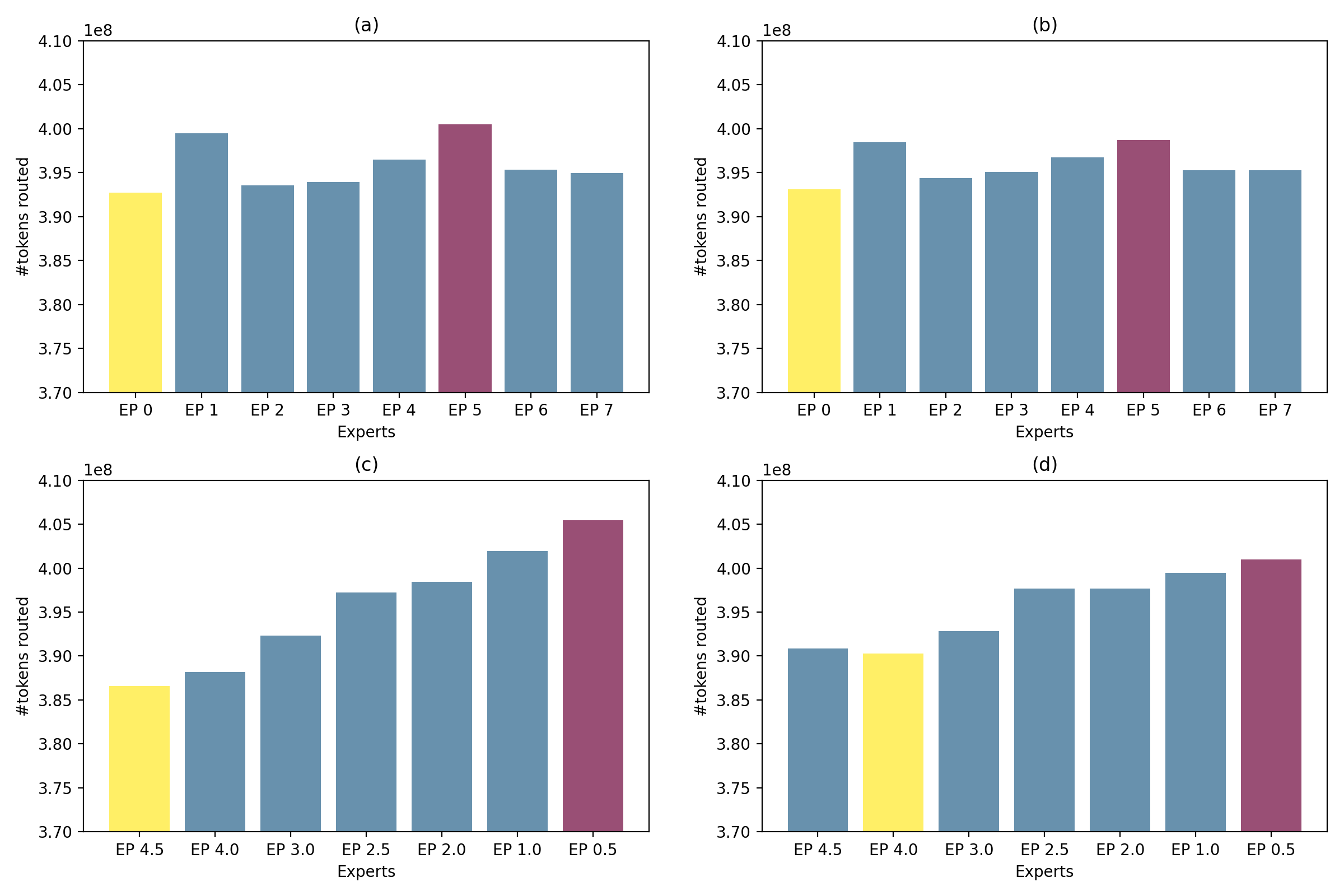
Figure 3: The number of tokens routed to each expert. The bar is the sum of the number across the layers. Figure (a) shows results in Baseline in epoch 2, and (b) in the last epoch. Figure (c) shows results in MoDSE in epoch 2, and (d) in the last epoch. The purple bar indicates the most routed expert, and the yellow indicates the least.
Finally, the analysis demonstrates that for high-loss tokens, the top-1 routing frequency is more than double for larger experts compared to smaller ones.
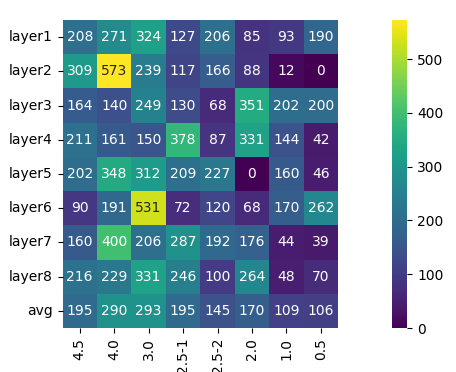
Figure 4: The top one expert choice of difficult tokens across eight layers. More tokens are routed to larger experts, distributed on the left half of the heat map.
Practical Implications
This heterogeneous expert design allows MoE LLMs to maximize the utility of their parameter budget, allocating greater model capacity on-demand. Such adaptation is especially effective for tasks characterized by large intra-distribution variance in token difficulty—common in long-form or code generation as well as multi-lingual and multi-domain datasets.
The expert-pair allocation mechanism supports deployment scalability by ensuring homogeneous computational load, critical for achieving linear scaling in distributed environments.
Importantly, despite the introduction of highly parameter-imbalanced expert sets, inference throughput remains comparable with standard MoEs due to the balancing effect of the routing and allocation setup.
Theoretical Considerations and Future Directions
MoDSE challenges the prevailing assumption that homogeneity among experts is a necessary condition for MoE efficiency or training stability. Empirical observations herein suggest that diversity in expert size not only provides a more expressive conditional computation graph but also, with appropriate auxiliary losses and scheduling, does not compromise training dynamics.
Future directions should:
- Investigate scaling MoDSE to the multi-billion parameter and trillion-token regimes typical of frontier LLMs, where issues such as routing instability, workload skew, and knowledge partitioning may be exacerbated.
- Extend analysis to multilingual, multi-modal, and code-focused settings, capitalizing on expert heterogeneity for domain-adaptive specialization.
- Explore integration with emergent routing paradigms such as soft routing or differentiable expert selection.
- Examine the interaction of expert size heterogeneity with knowledge redundancy and specialization, possibly in the context of transfer learning or continual learning.
Conclusion
Mixture of Diverse Size Experts introduces heterogeneity in expert capacities at the MoE layer level and demonstrates both improved downstream performance and favorable convergence characteristics without incurring inference or computational penalties. The findings indicate that dynamically matching expert expressivity to token complexity is preferable to parameter-homogeneous routing and that proper allocation strategies are sufficient to maintain workload balance. This shift in MoE design philosophy bears significant implications for the further scaling and specialization of sparse LLMs and merits extensive further investigation.
Reference: "Mixture of Diverse Size Experts" (2409.12210)