MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
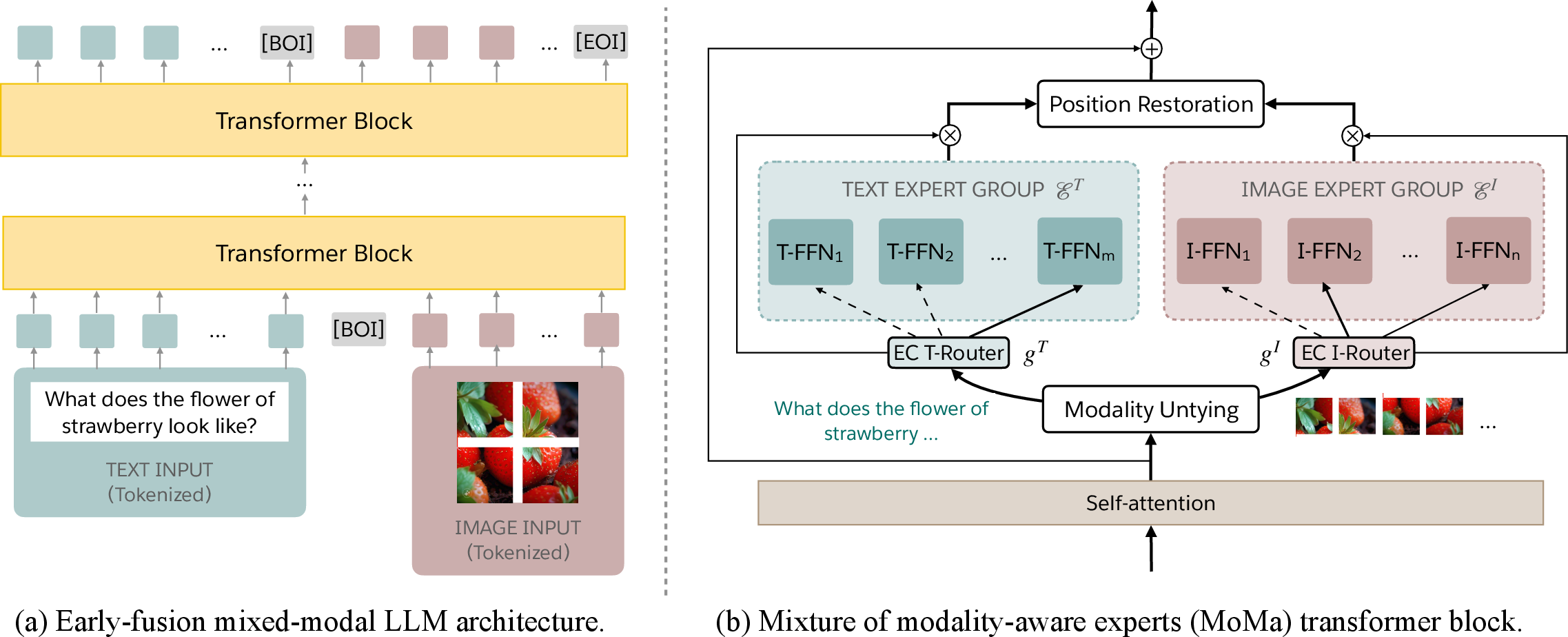
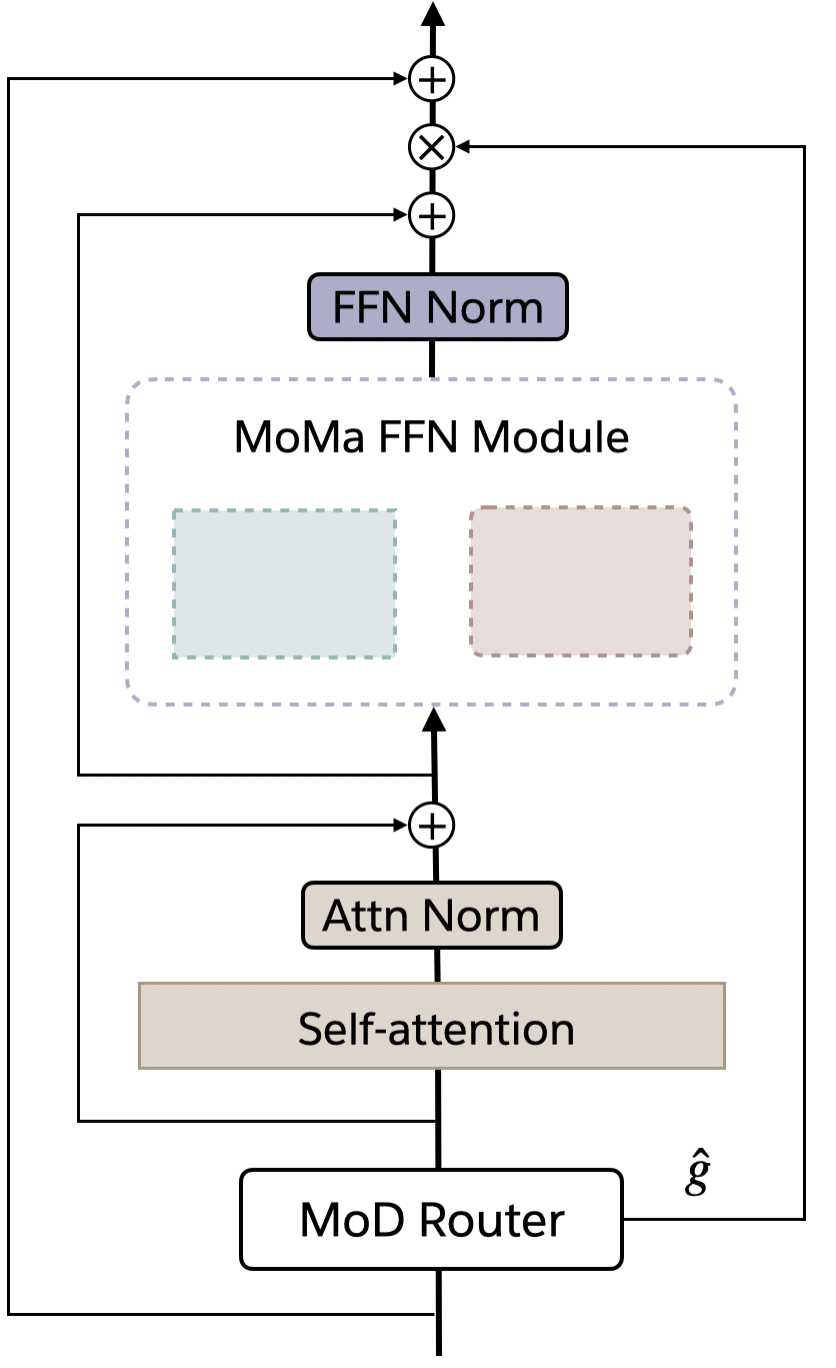
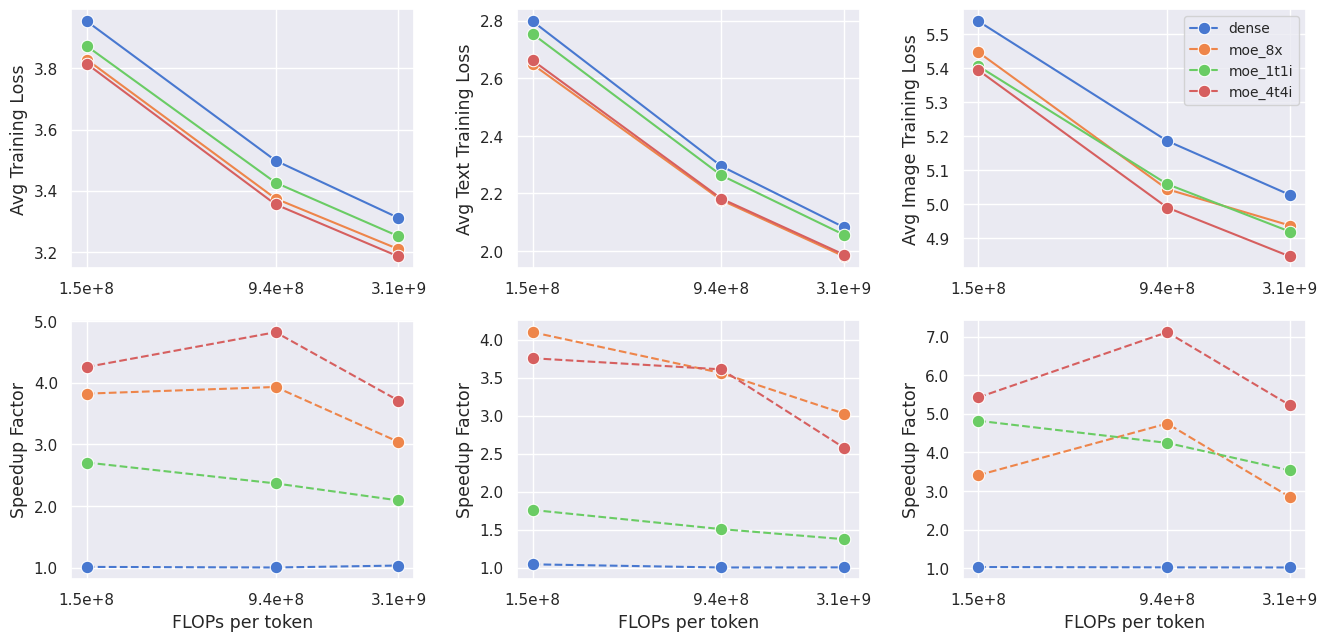
Abstract: We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion LLMs. MoMa processes images and text in arbitrary sequences by dividing expert modules into modality-specific groups. These groups exclusively process designated tokens while employing learned routing within each group to maintain semantically informed adaptivity. Our empirical results reveal substantial pre-training efficiency gains through this modality-specific parameter allocation. Under a 1-trillion-token training budget, the MoMa 1.4B model, featuring 4 text experts and 4 image experts, achieves impressive FLOPs savings: 3.7x overall, with 2.6x for text and 5.2x for image processing compared to a compute-equivalent dense baseline, measured by pre-training loss. This outperforms the standard expert-choice MoE with 8 mixed-modal experts, which achieves 3x overall FLOPs savings (3x for text, 2.8x for image). Combining MoMa with mixture-of-depths (MoD) further improves pre-training FLOPs savings to 4.2x overall (text: 3.4x, image: 5.3x), although this combination hurts performance in causal inference due to increased sensitivity to router accuracy. These results demonstrate MoMa's potential to significantly advance the efficiency of mixed-modal, early-fusion LLM pre-training, paving the way for more resource-efficient and capable multimodal AI systems.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024. URL https://arxiv.org/abs/2403.05530.
- Gpt-4 technical report, 2024. URL https://arxiv.org/abs/2303.08774.
- Unified-io 2: Scaling autoregressive multimodal models with vision, language, audio, and action, 2023. URL https://arxiv.org/abs/2312.17172.
- Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models, 2024. URL https://arxiv.org/abs/2405.09818.
- Gshard: Scaling giant models with conditional computation and automatic sharding, 2020. URL https://arxiv.org/abs/2006.16668.
- Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2022. URL https://arxiv.org/abs/2101.03961.
- Unified scaling laws for routed language models, 2022. URL https://arxiv.org/abs/2202.01169.
- Mixtral of experts, 2024. URL https://arxiv.org/abs/2401.04088.
- Mixture-of-depths: Dynamically allocating compute in transformer-based language models, 2024. URL https://arxiv.org/abs/2404.02258.
- Multimodal contrastive learning with limoe: the language-image mixture of experts, 2022. URL https://arxiv.org/abs/2206.02770.
- Foundations and trends in multimodal machine learning: Principles, challenges, and open questions, 2023. URL https://arxiv.org/abs/2209.03430.
- Vlmo: Unified vision-language pre-training with mixture-of-modality-experts, 2022. URL https://arxiv.org/abs/2111.02358.
- Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442, 2022a.
- Scaling vision-language models with sparse mixture of experts. arXiv preprint arXiv:2303.07226, 2023.
- Mixture-of-experts with expert choice routing, 2022. URL https://arxiv.org/abs/2202.09368.
- PyTorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019.
- Sparse upcycling: Training mixture-of-experts from dense checkpoints, 2023. URL https://arxiv.org/abs/2212.05055.
- Image as a foreign language: Beit pretraining for all vision and vision-language tasks, 2022b. URL https://arxiv.org/abs/2208.10442.
- Swin transformer v2: Scaling up capacity and resolution, 2022a. URL https://arxiv.org/abs/2111.09883.
- Layerskip: Enabling early exit inference and self-speculative decoding, 2024. URL https://arxiv.org/abs/2404.16710.
- Openmoe: An early effort on open mixture-of-experts language models, 2024. URL https://arxiv.org/abs/2402.01739.
- Gumbel-attention for multi-modal machine translation, 2022b. URL https://arxiv.org/abs/2103.08862.
- How does selective mechanism improve self-attention networks?, 2020. URL https://arxiv.org/abs/2005.00979.
- Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023.
- Megablocks: Efficient sparse training with mixture-of-experts. Proceedings of Machine Learning and Systems, 5:288–304, 2023.
- Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. 2024.
- Efficient large scale language modeling with mixtures of experts. CoRR, abs/2112.10684, 2021. URL https://arxiv.org/abs/2112.10684.
- Obelisc: An open web-scale filtered dataset of interleaved image-text documents. arXiv preprint arXiv:2306.16527, 2023.
- Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, pages 7432–7439, 2020.
- Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728, 2019.
- Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.
- Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019.
- Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015.
- Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017.
- Perceiver io: A general architecture for structured inputs & outputs. arXiv preprint arXiv:2107.14795, 2021.
- Nüwa: Visual synthesis pre-training for neural visual world creation. CoRR, abs/2111.12417, 2021. URL https://arxiv.org/abs/2111.12417.
- Cm3: A causal masked multimodal model of the internet. arXiv preprint arXiv:2201.07520, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

