- The paper introduces a novel fusion of sparse MoE and masked diffusion modeling that activates only a fraction (1.4B) of its 7B parameters per inference step.
- It employs a Transformer backbone with 64 experts and top-8 expert routing per token, enhancing both computational efficiency and specialization.
- Empirical results show that LLaDA-MoE outperforms dense MDMs and rivals autoregressive models on tasks including knowledge, code generation, and mathematical reasoning.
LLaDA-MoE: A Sparse MoE Diffusion LLM
Introduction and Motivation
LLaDA-MoE presents a novel integration of the Mixture-of-Experts (MoE) architecture into the Masked Diffusion Model (MDM) paradigm for large language modeling. The work addresses the computational inefficiency of dense MDMs by leveraging sparse expert routing, activating only a fraction of the total parameters per token during inference. This approach is motivated by the empirical success of MoE in autoregressive (AR) models, where sparse activation yields competitive performance with reduced resource requirements. LLaDA-MoE is trained from scratch on 20T tokens, maintaining a 7B parameter pool but activating only 1.4B parameters per inference step.
Model Architecture and Generation Process
LLaDA-MoE employs a Transformer backbone with RMSNorm, SwiGLU activations, rotary positional embeddings, and QK-layernorm in multi-head attention. The MoE layers consist of 64 experts, with the router selecting the top-8 experts per token. This design enables efficient computation and expert specialization.
The generation process follows the MDM paradigm: starting from a fully masked sequence, the model iteratively predicts masked tokens and unmasks them, progressing from t=1 (fully masked) to t=0 (fully unmasked). The MoE router dynamically selects experts for each token, and outputs are weighted combinations of the selected experts.
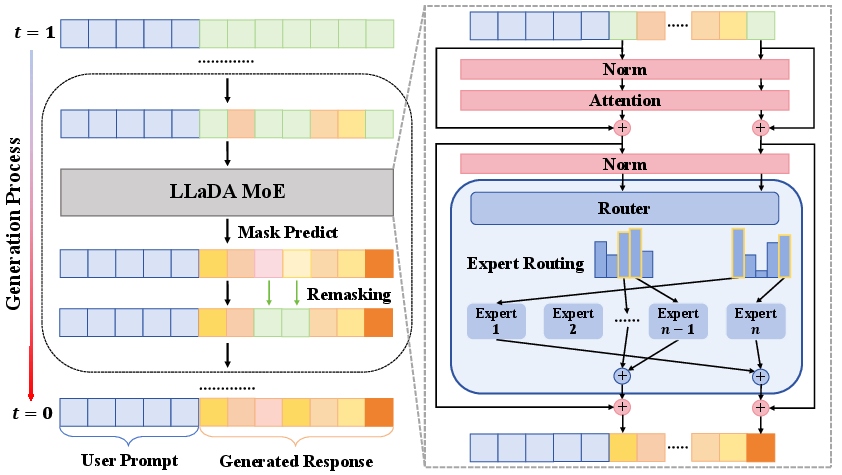
Figure 1: Overview of the iterative masked diffusion generation process and MoE architecture with top-2 expert routing per token.
Training Pipeline and Objectives
The training pipeline consists of multiple stages:
The pretraining objective is a variational lower bound on the log-likelihood, reconstructing masked tokens from partially observed context. Variable-length training is employed for 1% of steps to reduce train–test context mismatch. MoE routing is regularized with auxiliary load-balancing and Z-losses to prevent expert collapse and ensure balanced expert utilization.
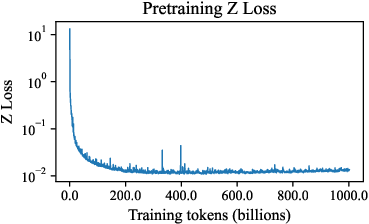
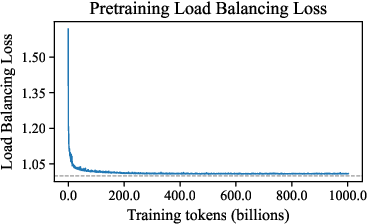
Figure 3: Training dynamics of auxiliary losses (Z-loss and load-balancing loss) over the first 1T tokens, showing rapid stabilization.
Inference and Sampling Strategies
Inference begins with a fully masked sequence, iteratively reducing the noise level and sampling tokens at masked positions using the mask predictor. Semi-autoregressive blockwise sampling is adopted, partitioning the sequence into blocks and decoding masked positions in parallel within each block. Low-confidence remasking is used to refine outputs, improving sample quality.
Empirical Results
LLaDA-MoE is evaluated on a comprehensive suite of benchmarks covering knowledge, reasoning, mathematics, coding, agent, and alignment tasks. Despite activating only 1.4B parameters, LLaDA-MoE consistently outperforms prior dense 8B MDMs (LLaDA, LLaDA 1.5, Dream) and achieves performance comparable to Qwen2.5-3B-Instruct, an AR model.
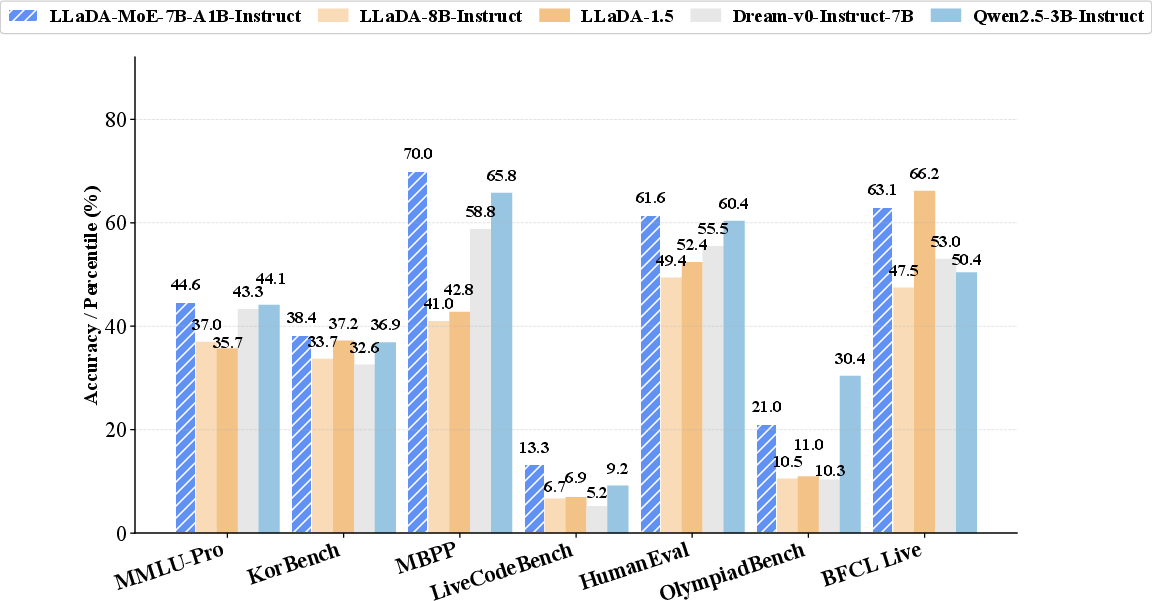
Figure 4: Benchmark results showing LLaDA-MoE outperforming larger MDMs and matching Qwen2.5-3B-Instruct across diverse tasks with fewer activated parameters.
Notably, LLaDA-MoE-7B-A1B-Instruct achieves strong results in knowledge understanding, code generation, mathematical reasoning, and agent tasks, trailing Qwen2.5-3B-Instruct by only a small margin. The model demonstrates robust generalization and parameter efficiency, with average scores exceeding those of larger dense MDMs.
Implementation Considerations
- Resource Efficiency: Sparse MoE activation reduces memory and compute requirements, enabling deployment on hardware with limited resources.
- Expert Specialization: The MoE architecture facilitates expert specialization, potentially improving performance on heterogeneous tasks.
- Training Stability: Auxiliary losses (load-balancing, Z-loss) are critical for stable expert routing and preventing collapse.
- Context Window: Expansion to 8k context during annealing supports long-sequence modeling, but SFT is limited to 4k due to sample length distribution.
- Sampling Strategy: Semi-autoregressive blockwise sampling and remasking enhance inference efficiency and output quality.
Implications and Future Directions
The integration of MoE into MDMs establishes a new direction for efficient large language modeling, combining the strengths of diffusion-based generation and sparse expert routing. The results suggest that MoE architectures can be effectively adapted to non-autoregressive paradigms, opening avenues for further scaling and specialization.
Future work may explore:
- Scaling LLaDA-MoE to larger parameter pools and more experts.
- Advanced expert routing mechanisms (dynamic, hierarchical).
- Multimodal extensions leveraging MoE for cross-domain tasks.
- Optimized inference strategies for real-time and low-latency applications.
Conclusion
LLaDA-MoE demonstrates that sparse MoE architectures can be successfully integrated into masked diffusion LLMs, yielding strong performance with reduced active parameter budgets. The model surpasses prior dense MDMs and matches AR baselines across diverse tasks, establishing MoE as a viable foundation for efficient diffusion-based language modeling. This work opens a broad design space for future research in scalable, resource-efficient LLMs.
