- The paper introduces a novel 800-problem, contamination-resistant benchmark spanning 7 scientific fields to advance evaluation of LLM scientific reasoning capabilities.
- It employs a hybrid human-AI pipeline that uses expert problem generation along with adversarial filtering to ensure original, complex, and reliable challenges.
- Evaluation results reveal significant gaps in current models' reasoning abilities, providing diagnostic insights and future directions for AI in scientific discovery.
"ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning" (2511.14366)
Introduction to Benchmark Saturation and Evaluation Needs
The rapid progress in LLMs has led to a "benchmark saturation" where traditional evaluation sets can no longer effectively differentiate advanced models. Benchmarks like MMLU have been surpassed by state-of-the-art models with very high accuracy, making them ineffective for assessing nuanced capabilities. This saturation highlights the need for more challenging benchmarks that can propel AI advancements, particularly in scientific reasoning, an area identified as crucial for future breakthroughs in AI.
Simultaneously, existing high-difficulty benchmarks have limitations regarding narrow disciplinary focus and susceptibility to data contamination. ATLAS addresses these issues by providing a multidisciplinary evaluation tool specifically designed to test scientific reasoning capabilities—a step forward in guiding AI development in science-focused applications.
ATLAS Design and Construction
ATLAS is meticulously designed to confront challenges of benchmark saturation and contamination. Its construction incorporates high-difficulty and rigorous contamination-resistant methodologies. It contains approximately 800 expertly crafted problems across seven core scientific disciplines, setting the difficulty to ensure a pass rate below 20% for current leading models. The problems retain real-world complexity and require answers that reflect deep scientific reasoning.
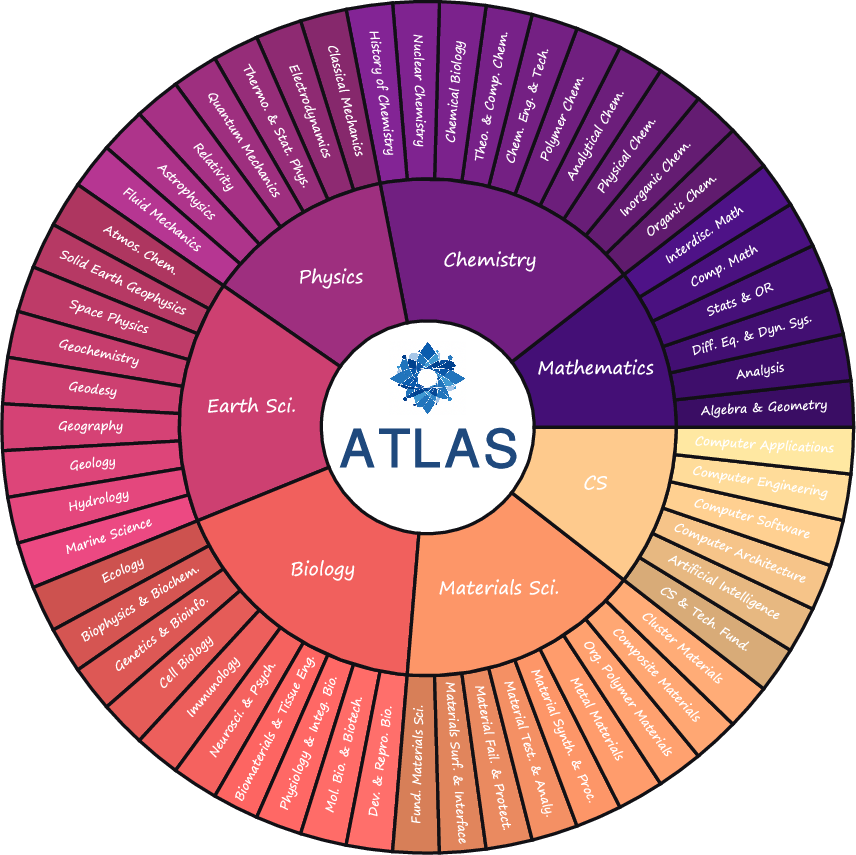
Figure 1: Overview of ATLAS, which contains 7 stem subjects and 57 corresponding sub-fields.
ATLAS employs a hybrid human-AI pipeline, utilizing expert problem-generation complemented with adversarial filtering by state-of-the-art models. This rigorous process ensures problem originality and appropriate complexity, while also facilitating scalable evaluation through its judgment workflow. Responses are parsed and judged using sophisticated LLMs to verify natural and symbolic answer formats, allowing real-world problem retention.
Evaluation and Dataset Analysis
ATLAS provides a robust platform for evaluating LLMs' performance on scientific reasoning tasks. Through detailed analysis, models are prompted to solve problems with outputs formatted for rigorous machine-led judgment. The dataset reveals a broad distribution of subjects and problem types, emphasizing complex reasoning and structured multi-part answers.
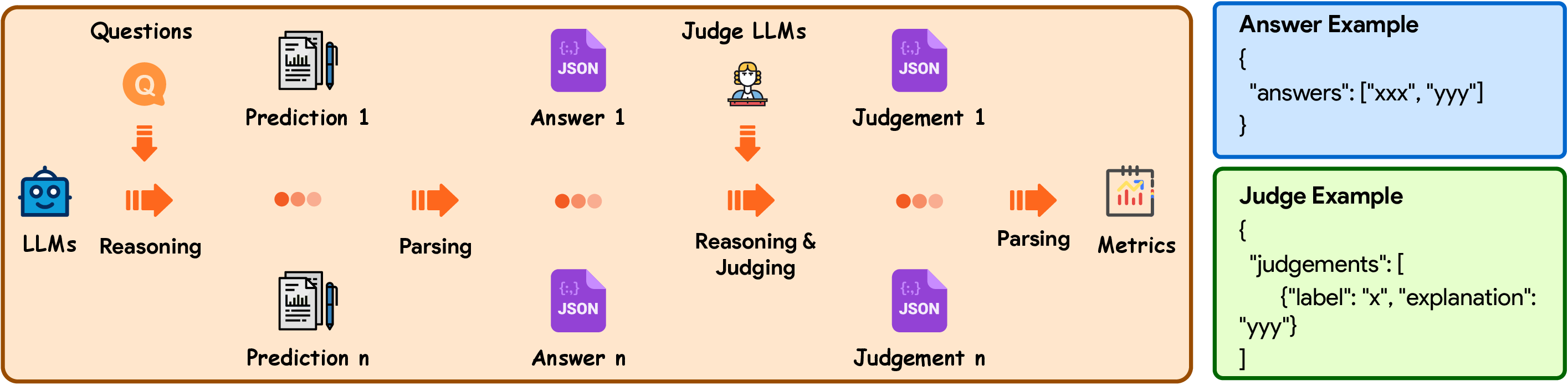
Figure 2: Overview of the evaluation workflow. During the evaluation process, the LLM is prompted to provide formatted predictions, from which the answers are extracted and input into the Judge LLMs for the computation of evaluation metrics.
The quantitative and qualitative analyses of ATLAS highlight its ability to distinguish high-quality reasoning capabilities among models. With a comprehensive suite of tests, ATLAS provides insights into models' grasp on diverse scientific subjects, from molecular biology to materials science.
Benchmark Results and Observations
The evaluation results indicate that current models, while advanced, still have notable gaps in expert-level scientific reasoning. OpenAI GPT-5-High emerges as a leading model across subjects, yet all models exhibit significant variance in effectiveness, pointing to areas needing improvement. The benchmark provides diagnostic insights into common errors, including precision in numerical outputs and the handling of complex reasoning chains.
Implications and Future Directions
The findings from ATLAS underscore the criticality of developing benchmarks that prioritize real-world scientific reasoning: an essential domain in the pursuit of AGI. By focusing on the interdisciplinary nature of science, ATLAS sets a quantitative standard for measuring scientific capabilities in AI models.
ATLAS aims to evolve as a long-term platform, actively expanding its scope and fostering community collaboration. Its ongoing development seeks to incorporate more languages and scientific fields, aiming to establish itself as a sustainable resource for evaluating and advancing AI's role in scientific discovery.
In conclusion, ATLAS represents a meaningful shift towards benchmarks that more accurately reflect the complexities of scientific reasoning, offering both immediate insights into current model capabilities and strategic directions for future research in AI for Science.