- The paper presents DataMind, a scalable pipeline that synthesizes diverse multi-format data and generates a high-quality trajectory dataset (DataMind-12K).
- It introduces a dynamic hybrid SFT/RL training approach that leverages recursive query composition and self-consistency filtering to enhance agent performance.
- Empirical results show DataMind models (7B and 14B) outperform open-source baselines with scores up to 71.16% on multi-step data analysis benchmarks.
Scaling Generalist Data-Analytic Agents: A Technical Analysis
Introduction
The paper "Scaling Generalist Data-Analytic Agents" (2509.25084) presents DataMind, a comprehensive pipeline for constructing open-source, generalist data-analytic agents capable of robust multi-step reasoning over diverse, large-scale data formats. The work addresses three principal challenges: (1) the scarcity of high-quality, trajectory-annotated data for agent training, (2) the instability and suboptimality of conventional SFT-then-RL training paradigms, and (3) the technical difficulties of multi-turn code-based rollouts under constrained computational resources. DataMind introduces a scalable data synthesis and agent training recipe, culminating in the release of DataMind-12K, a high-quality trajectory dataset, and two agent models (DataMind-7B and DataMind-14B) that set new performance standards on multiple data analysis benchmarks.
Data Synthesis: Task Taxonomy and Query Generation
DataMind's data synthesis pipeline begins with the aggregation of heterogeneous data files (.csv, .xlsx, .sqlite) from public sources, followed by rigorous filtering to ensure quality and diversity. The core innovation is a fine-grained task taxonomy comprising 18 distinct categories, enabling the generation of queries that span aggregation, ranking, causal analysis, multi-hop reasoning, and more.
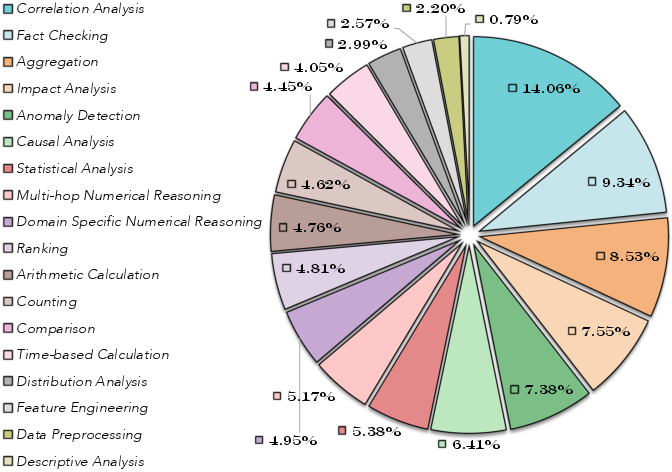
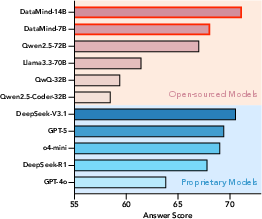
Figure 1: Task taxonomy used in DataMind, enabling fine-grained and diverse query synthesis across 18 categories.
Query generation leverages automated scripts to extract metadata and utilizes LLMs (DeepSeek-V3) for query synthesis, guided by few-shot exemplars and recursive easy-to-hard composition. This recursive chaining amplifies task complexity, producing multi-hop analytic challenges that stress agent reasoning capabilities beyond single-step tasks.
Trajectory Sampling and Filtering
Expert trajectory sampling is performed using a knowledge-augmented framework. For each query, a high-level workflow is manually crafted to steer the expert model (DeepSeek-V3.1) during trajectory synthesis. Multiple trajectories are sampled per query, and a judge model (GPT-4o-mini) enforces self-consistency filtering: only trajectories converging to the same answer are retained, and the most concise/accurate is selected for training. Failed trajectories are revised using external critique from the judge model, enriching the diversity of reasoning patterns.
Rule-based filtering further enforces format compliance, length control, and linguistic integrity, resulting in DataMind-12K—a dataset of 11,707 high-quality trajectories.
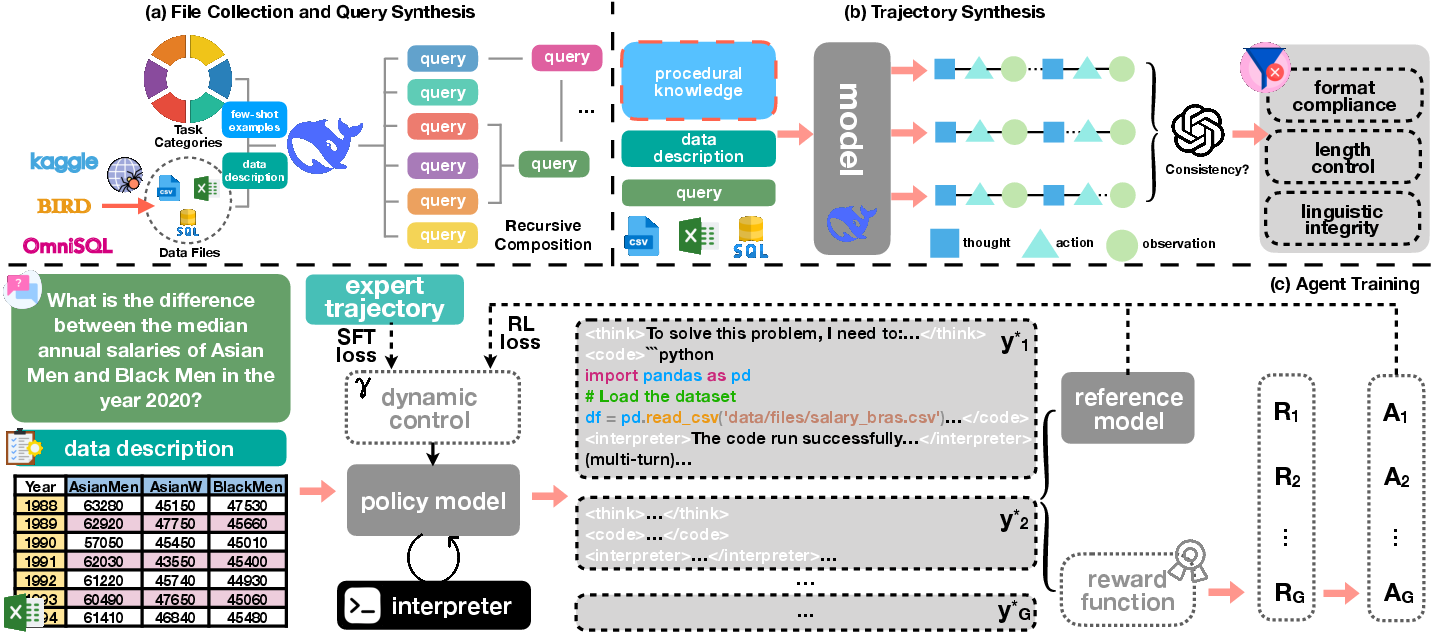
Figure 2: The DataMind pipeline: task taxonomy, recursive query composition, knowledge-augmented trajectory sampling, dynamic SFT/RL training, and memory-frugal multi-turn rollout.
Agent Training: Dynamic SFT/RL Optimization
DataMind adopts a hybrid SFT+RL training paradigm, dynamically balancing supervised fine-tuning (SFT) and reinforcement learning (RL) via a time-varying coefficient γ. SFT loss is masked to exclude environment feedback, focusing optimization on agent-generated tokens. RL is implemented using the DAPO algorithm, with group-wise trajectory sampling and reward normalization. The final objective is a weighted sum of SFT and RL losses, with γ annealed from high to low to transition from knowledge absorption to exploration.
Void turns (agentic loops failing to produce valid code/answers) are masked to prevent trajectory collapse. Multi-turn rollout is stabilized via asynchronous code execution, chunked code maintenance, and strict sandboxing of execution environments.
Reward design integrates format, answer, and length components, with model-as-judge evaluation for descriptive answers and length-based penalties to discourage verbosity.
Empirical Results
DataMind-14B achieves an average score of 71.16% across DABench, TableBench, and BIRD, outperforming proprietary models (DeepSeek-V3.1, GPT-5) and all open-source baselines. DataMind-7B leads among open-source models with 68.10%. Notably, DataMind models maintain robust performance across diverse data formats and task types, whereas specialized models degrade sharply on unseen formats.
Ablation and Analysis
Self-Consistency Filtering
Ablation studies reveal that self-consistency filtering is more critical than best trajectory selection. Removing consistency checks results in pronounced performance degradation, while random selection of consistent trajectories can match or exceed explicit best selection, suggesting that diversity in reasoning patterns is beneficial.
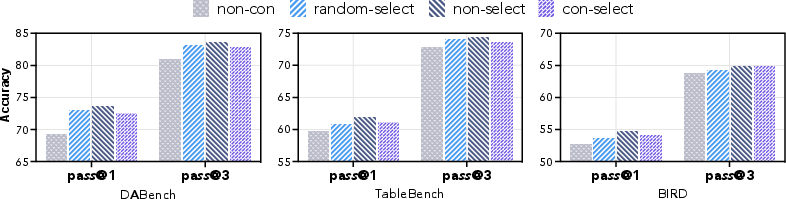
Figure 3: Analysis of self-consistency filtering and trajectory selection strategies; diversity of consistent trajectories enhances reasoning capability.
SFT Loss as Stabilizer and Limitation
SFT loss stabilizes RL training, preventing policy collapse in early stages. However, persistent dominance of SFT loss leads to overfitting and entropy collapse, stifling exploration. Dynamic γ scheduling maintains policy entropy and enables stable, effective training.
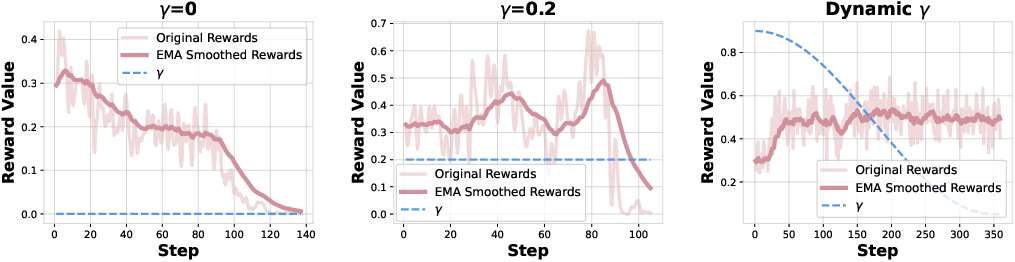
Figure 4: Influence of SFT loss weight (γ) on RL training stability; dynamic scheduling prevents collapse and supports exploration.
RL and Base Model Capacity
RL narrows the performance gap between base models but cannot reverse their order; most knowledge is acquired during SFT, with RL primarily unlocking latent potential. Excessive cold start leaves little room for RL improvement, raising open questions about the saturation of policy space and reward model limitations.
Implementation Considerations
- Data Synthesis: Automated metadata extraction and LLM-based query generation require robust scripting and prompt engineering. Recursive composition should be parameterized for task complexity control.
- Trajectory Sampling: Integration of expert models and judge models necessitates scalable orchestration and feedback loops for trajectory revision.
- Training: Dynamic SFT/RL optimization can be implemented via cosine annealing of γ; masking strategies for void turns and environment feedback are essential for stability.
- Rollout: Asynchronous code execution and chunked maintenance reduce memory footprint; strict sandboxing and security controls are mandatory for safe multi-turn rollouts.
- Evaluation: Model-as-judge protocols should be standardized for both numerical and descriptive answers, with pass@1 and pass@3 metrics for diversity assessment.
Implications and Future Directions
DataMind demonstrates that high-quality, diverse, and well-filtered trajectory data, combined with dynamic SFT/RL training, can enable open-source models to match or surpass proprietary agents in complex data analysis tasks. The findings challenge the notion that RL alone can compensate for base model deficiencies and highlight the importance of trajectory diversity and dynamic training objectives.
Future work should extend DataMind to predictive and visualization tasks, scale backbone models beyond 14B, and explore advanced RL algorithms for continual learning. The open release of DataMind-12K and agent models will facilitate reproducibility and further research in generalist agentic intelligence.
Conclusion
DataMind provides a scalable, reproducible framework for training generalist data-analytic agents, setting new standards for open-source performance in multi-step, multi-format data analysis. The pipeline's innovations in data synthesis, trajectory filtering, and dynamic training offer actionable insights for the development of robust agentic systems in scientific and industrial domains.