- The paper introduces a dual-memory approach that leverages shared and task-specific modules to mitigate catastrophic forgetting.
- It employs an adaptive memory expansion and pruning strategy that balances learning new tasks while preserving past knowledge.
- Orthogonal regularization is used to segregate feature representations, aligning current models with joint-learning benchmarks.
Expandable and Differentiable Dual Memories with Orthogonal Regularization for Exemplar-free Continual Learning
Introduction
"Expandable and Differentiable Dual Memories with Orthogonal Regularization for Exemplar-free Continual Learning" presents a novel framework to address catastrophic forgetting in continual learning (CL) settings without relying on exemplars. The paper identifies existing limitations in regularization and architecture-based approaches, which often inhibit neural networks from leveraging shared knowledge across tasks due to interference. The authors propose a method that utilizes two complementary memory systems for learning transferable features and task-specific details.
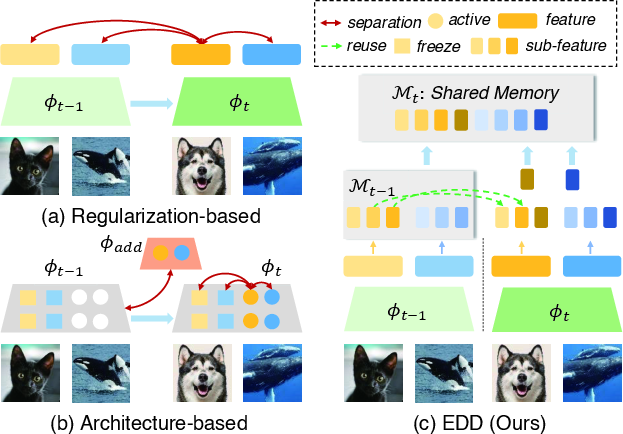
Figure 1: Comparison of the proposed method with regularization- and architecture-based approaches.
Proposed Method: Differentiable Dual Memory
The EDD framework integrates two learnable memories, each designed to autonomously adapt as new tasks are introduced. The shared memory captures features that can be generalized across tasks, while the task-specific memory focuses on unique discriminative features. This is accomplished using a differentiable memory system, which unifies feature decomposition and retrieval.
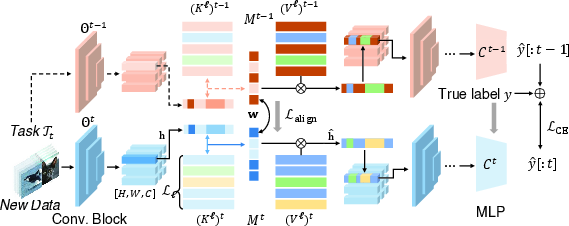
Figure 2: Overview of the proposed method.
Memory Adjustment: Expansion and Pruning
Critical to the functioning of EDD is its memory adjustment strategy, which involves adaptive pruning and expansion. This provides the dual benefits of preserving essential knowledge from previous tasks while maintaining adaptability for learning new concepts. By pruning slots that encode significant aspects of past tasks and introducing new slots for future tasks, EDD maintains an efficient balance between stability and plasticity.
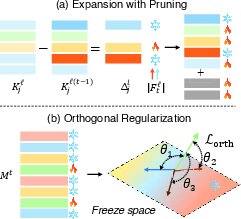
Figure 3: Schematic diagram of memory expansion, knowledge pruning and orthogonal regularization.
Orthogonal Regularization
To prevent interference between old and new learned features, EDD uses orthogonal regularization. This approach enforces geometric separation between preserved and newly added memory slots within the task-specific memory, encouraging disentangled representation learning and mitigating feature overlap.
Memory-Guided Representation Alignment
A memory-guided distillation process promotes the alignment of current model representations with those stored by the previous model, enabling effective recall of shared features and thereby reducing the burden of forgetting. The distillation aligns internal representations, ensuring the retrieval process leverages prior knowledge across tasks.
Experimental Analysis
EDD's performance was measured against state-of-the-art CL approaches using benchmarks such as CIFAR-10, CIFAR-100, and TinyImageNet. The results indicated substantial improvements in average accuracy, with EDD outperforming exemplar-based methods despite operating in an exemplar-free setting. Notably, accuracy gains were achieved even as task sequences became longer and more complex.
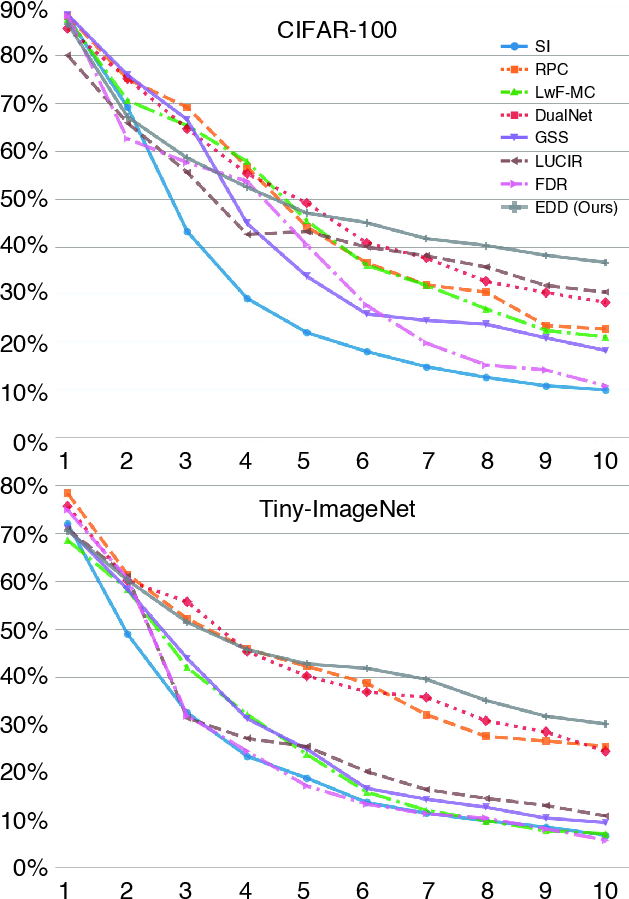
Figure 4: Task-wise accuracy for various CL methods on CIFAR-100 and TinyImageNet under 10 tasks.
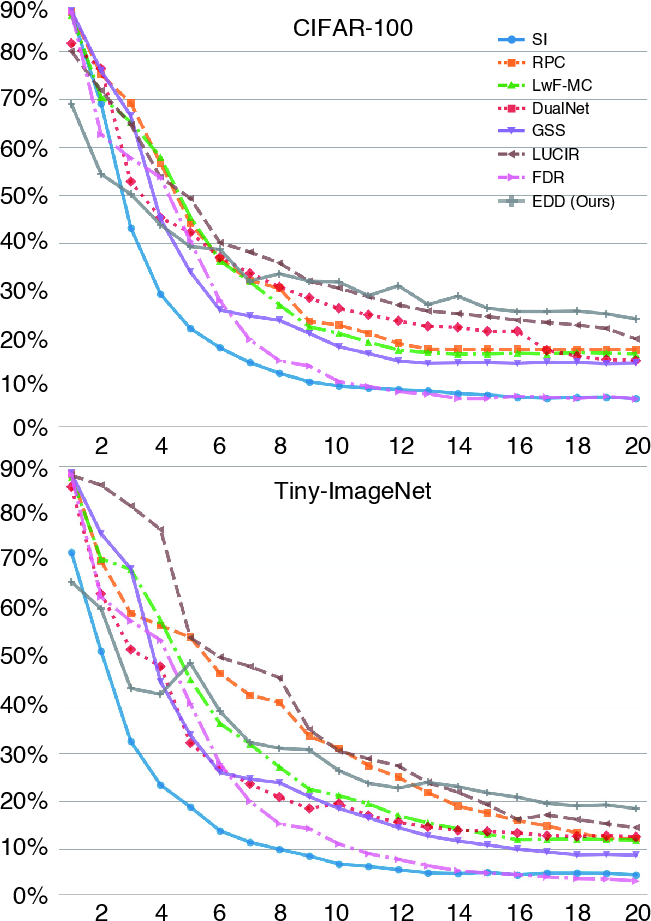
Figure 5: Task-wise accuracy for various CL methods on CIFAR-100 and TinyImageNet under 20 tasks.
Ablation Studies
Ablation studies corroborated the efficacy of each component within EDD. Memory alignment improved performance by a significant margin, orthogonal regularization contributed additional gains, and batch adaptation further enhanced model accuracy across varied scenarios.
Alignment with Joint Learning Representations
EDD's ability to maintain feature representations akin to joint learning was rigorously tested. Metrics such as cosine similarity, KL divergence, and Wasserstein distance confirmed that EDD achieves near-complete alignment with joint-trained models in feature space, underscoring its effective reuse of shared representations across tasks.
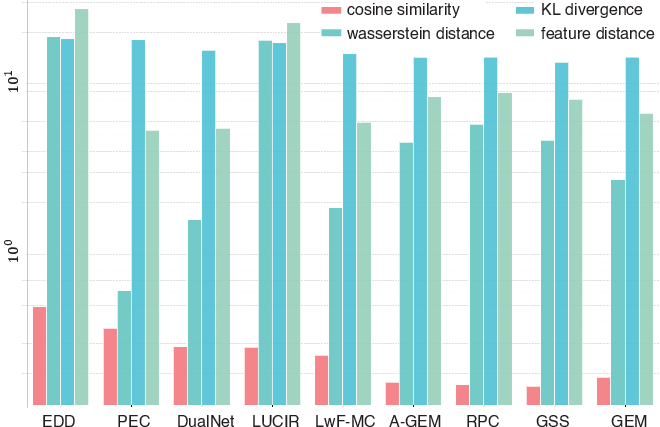
Figure 6: Alignment of class-incremental features with joint-learning representations.
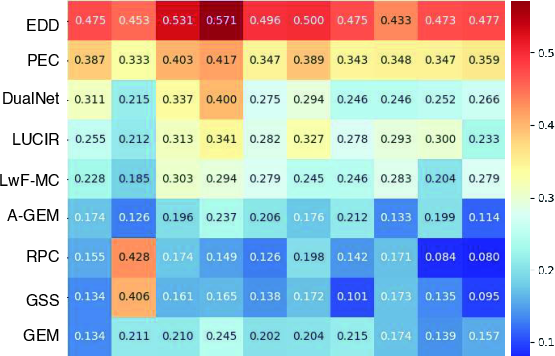
Figure 7: Per-class cosine similarity to joint learning for CIFAR-10. Each value shows how similarity evolves over the 5 two-class tasks.
Computational Complexity and Limitations
EDD introduces additional computational overhead due to its differentiable memory operations and orthogonal regularization during training. However, this is manageable and does not significantly impact runtime or growth. Despite its robust design, potential limitations include scaling challenges for very large output spaces or extreme task shifts where shared memory struggles to capture divergent knowledge.
Conclusion
EDD presents a significant advancement in exemplar-free continual learning by efficiently balancing stability and plasticity through sophisticated memory management and regularization techniques. The dual memory approach promises both theoretical insights into task relationships and practical enhancements in model performance. Future directions could include expanding the framework's applicability to transformer architectures or longer task sequences, aiming to solidify its role as a scalable paradigm in CL.