Solving a Million-Step LLM Task with Zero Errors
Abstract: LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations, and societies has remained out of reach. The models have a persistent error rate that prevents scale-up: for instance, recent experiments in the Towers of Hanoi benchmark domain showed that the process inevitably becomes derailed after at most a few hundred steps. Thus, although LLM research is often still benchmarked on tasks with relatively few dependent logical steps, there is increasing attention on the ability (or inability) of LLMs to perform long range tasks. This paper describes MAKER, the first system that successfully solves a task with over one million LLM steps with zero errors, and, in principle, scales far beyond this level. The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents. The high level of modularity resulting from the decomposition allows error correction to be applied at each step through an efficient multi-agent voting scheme. This combination of extreme decomposition and error correction makes scaling possible. Thus, the results suggest that instead of relying on continual improvement of current LLMs, massively decomposed agentic processes (MDAPs) may provide a way to efficiently solve problems at the level of organizations and societies.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to make AI systems (specifically LLMs, or LLMs) complete very long, step‑by‑step tasks without making any mistakes. The authors build a system called MAKER that solves a million‑step puzzle perfectly. Instead of trying to make one super‑smart AI do everything, they break the big task into many tiny jobs, have multiple small AIs do each tiny job, and use voting and “red flags” to catch and fix errors as they go.
What questions did the researchers ask?
- Can LLMs be trusted to complete very long tasks (thousands or millions of steps) with zero errors?
- If a single LLM tends to make occasional mistakes, is there a better approach than just trying to make the LLM “smarter”?
- How should we design AI systems to scale to huge tasks—like those people, companies, and governments do—without failing?
How did they try to answer these questions?
The puzzle they used: Towers of Hanoi
They tested their ideas on a classic puzzle called Towers of Hanoi. You have three pegs and a stack of disks of different sizes. You must move the stack from the first peg to the third, one disk at a time, never placing a larger disk on a smaller one. The puzzle grows in difficulty quickly: with 20 disks, it takes just over a million moves. That makes it a great test for whether an AI can execute a long plan perfectly.
Break the big job into tiny jobs (Maximal Agentic Decomposition)
Think of building a skyscraper: it’s not one person doing everything; it’s thousands of small tasks done by specialists. The authors apply the same idea to AI:
- They split the entire task into the smallest possible steps—each step asks for exactly one move in the puzzle.
- Each “micro‑agent” (a small LLM) focuses on one step, using only the information it needs right now. This keeps the AI from getting confused by a long history, which often causes mistakes in long tasks.
- Because steps are tiny, smaller and cheaper models can often do the job.
Analogy: It’s like an assembly line where each worker does exactly one simple action perfectly, then hands the result to the next worker.
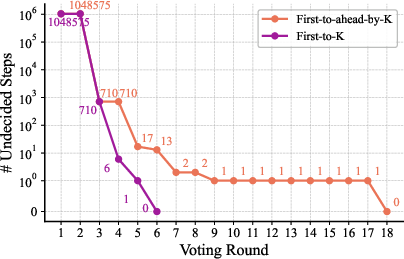
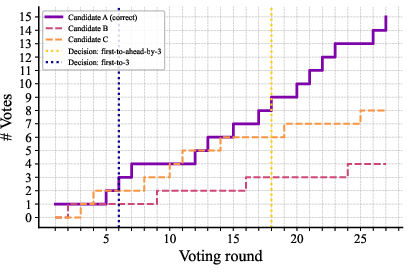
Double‑check each tiny job (Voting)
Even small models can make occasional errors. To catch them:
- The system asks several micro‑agents to solve the same tiny step independently.
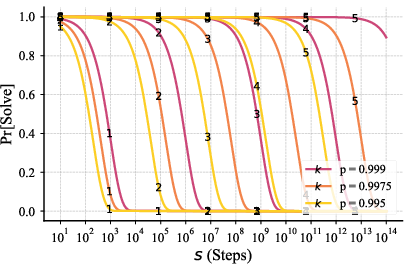
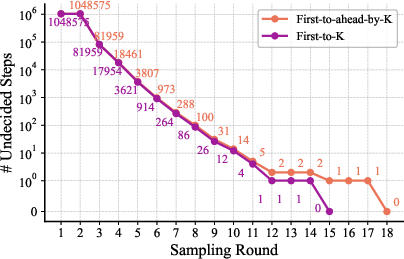
- It keeps sampling answers until one choice is clearly ahead by a margin (called “first‑to‑ahead‑by‑k”).
- The winning answer is used as the step’s result.
Analogy: Imagine several students answer the same mini‑question. The teacher goes with the choice that clearly wins by a few votes, reducing the chance of a wrong answer slipping through.
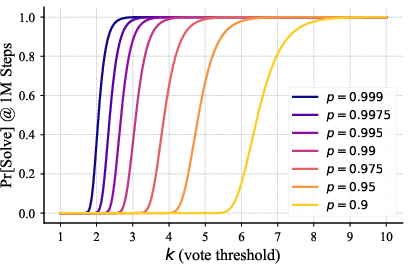
Why this works: If a correct answer is just a bit more likely than a wrong one, repeated independent voting makes the correct one win with very high probability. The authors show that the number of extra votes needed grows slowly (about like “logarithm of steps”), so even million‑step tasks stay practical.
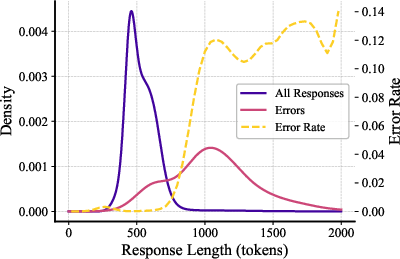
Watch for “red flags”
The system also ignores answers that look risky, such as:
- Answers that are way too long when only a short answer is needed.
- Answers in the wrong format (e.g., not following “move = ...” and “next_state = ...”).
Analogy: If someone turns in a messy, overly long response to a simple question, they may be confused—so the system discards it and asks another micro‑agent.
These “red flags” help avoid not just single mistakes, but patterns of correlated mistakes (when being confused makes multiple errors more likely).
What did they find?
- They solved a million‑step Towers of Hanoi task (20 disks) with zero errors using MAKER.
- Breaking the task into one‑step micro‑agents plus voting is powerful. It shows a “multi‑agent advantage”: a system design that can succeed where a single agent fails.
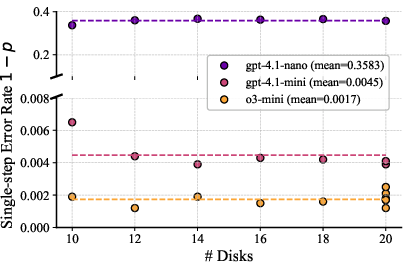
- Smaller, cheaper “non‑reasoning” models were often good enough when paired with extreme decomposition and voting. You don’t always need the biggest, smartest model.
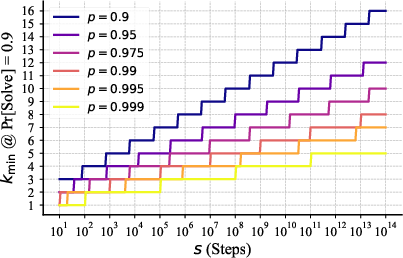
- Error rates stayed stable as the puzzle got larger when using this method—an encouraging sign for scaling to very large tasks.
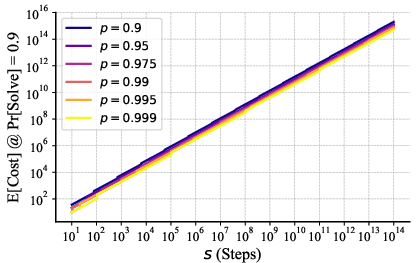
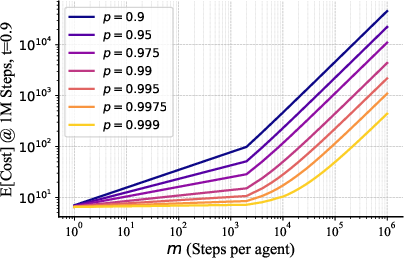
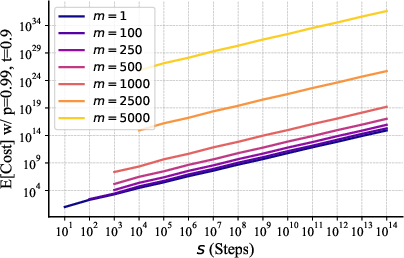
- The cost to solve the whole task grows roughly like “number of steps × a slow growth factor.” That slow factor (the votes needed per step) increases gently with task size, which means the method scales well. Because votes can be done in parallel, the time grows almost just with the number of steps.
Why does this matter?
Real‑world systems—hospitals, tax agencies, factories, research labs, and more—depend on executing long chains of steps reliably. A single percent of error per step becomes a guaranteed failure over thousands of steps. This paper suggests a different path to trustworthy AI at scale:
- Instead of only trying to make LLMs smarter, make the process smarter.
- Split tasks into tiny parts, use multiple independent checks, and filter out risky answers.
- This MDAP (Massively Decomposed Agentic Processes) approach can unlock reliable AI for tasks at the scale of organizations and societies.
Key takeaways
- One super‑AI isn’t necessary; many small, focused AIs plus voting can perform better on long tasks.
- Extreme decomposition (one step per micro‑agent) keeps each decision simple and reduces confusion.
- Voting and red‑flagging provide strong error correction, making zero‑error execution possible even across a million steps.
- Smaller, cheaper models can be the best choice when paired with the right process.
- This design points to a new way to scale AI safely and efficiently for complex, real‑world operations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, articulated to be concrete and actionable for future research.
- Generalization beyond Towers of Hanoi: Evidence is limited to a deterministic, fully observable, discrete task with a known optimal strategy. It remains unclear how MAKER performs on:
- Stochastic or partially observable environments.
- Tasks with continuous action/state spaces.
- Real-world workflows involving tool use, external systems, or uncertain feedback.
- Tasks that require discovering a strategy rather than executing a provided one.
- Dependence on a pre-specified decomposition and strategy: The approach assumes an a priori “correct” step definition and global strategy. There is no method for:
- Automatically discovering optimal decompositions (granularity of steps).
- Learning or refining strategies when none is available or when strategies are noisy/ambiguous.
- Adapting decomposition level over time based on observed errors or difficulty.
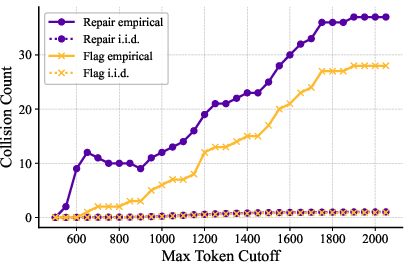
- Independence and stationarity assumptions in voting: The scaling laws and success guarantees tacitly assume that samples (votes) are independent and identically distributed with a stationary per-step success rate . Open issues include:
- Measuring and mitigating correlation between samples generated by the same model and prompt (e.g., due to shared context, provider-side caching, or temperature settings).
- Handling non-stationarity of across the million-step horizon (e.g., varying state complexity or model fatigue).
- Quantifying how much correlation invalidates the first-to-ahead-by- stopping rule and how to correct for it.
- Multi-candidate race simplification: Analysis treats the “worst case” as a two-candidate race (correct vs one most-likely alternative), which is favorable to larger but unrealistic. Needed:
- Closed-form or empirical characterization of first-to-ahead-by- voting with multiple competing incorrect candidates and unequal probabilities.
- Robustness analysis when the incorrect probability mass is spread across many near-ties.
- Formal derivation rigor and reproducibility: Several equations appear incomplete or typographically incorrect (e.g., undefined references, malformed terms). To improve trust and reuse:
- Provide a fully verified, self-contained derivation of , hitting probabilities, hitting times, and expected cost under the actual voting protocol.
- Release code to reproduce all plots from the analytical formulas.
- Include confidence intervals and sensitivity analyses for all modeled parameters.
- Tie-handling and stopping criteria in voting: The protocol returns when one candidate is ahead by , but it does not specify:
- Handling of ties and near-ties under non-i.i.d. sampling.
- Adaptive stopping based on estimated or empirical disagreement.
- Safety mechanisms for prolonged races and pathological cases (e.g., oscillations).
- Semantic equivalence and aggregation: The system requires exact-matching outputs per step; semantically equivalent alternatives are not recognized. Research is needed on:
- Designing and validating LLM-based or symbolic equivalence checkers per subtask.
- Weighting or clustering semantically consistent samples to reduce cost and increase robustness.
- Correlated error detection and red-flagging efficacy: Red-flagging relies on two heuristics (response length and format correctness), but there is no quantitative analysis of:
- How these flags affect and (valid response rate) across step positions and models.
- False positives/negatives and their impact on total cost and reliability.
- Whether additional red flags (e.g., perplexity spikes, contradiction tests, self-verification failures) materially reduce correlated errors.
- Calibration of red-flag thresholds: The thresholds (e.g., 2048 tokens) are ad hoc. Work is needed to:
- Optimize thresholds per model and per step type to maximize and minimize cost.
- Explore dynamic, step-aware gating policies that adapt to state complexity.
- Empirical validation of scaling laws for : The paper argues cost explodes with larger , but does not report experiments for intermediate values. Needed:
- Systematic empirical evaluation of with matched budgets and models.
- Measurement of the onset of exponential cost and how it depends on , , and model diversity.
- Robustness to model updates and deployment variability: API models change over time and exhibit variability. The approach does not address:
- How provider-side updates affect , , and the stability of the voting distribution.
- Versioning, regression tests, and fallback strategies to maintain reliability over long horizons.
- Ensemble diversity: All votes appear to be sampled from the same base model with minor parameter changes. To reduce correlated errors:
- Evaluate heterogeneous ensembles (different models, decoding strategies, seeds).
- Quantify diversity vs. cost trade-offs and their effect on .
- Resource and latency characterization: The paper asserts parallelization of votes reduces wall-clock time but does not report:
- End-to-end latency for the million-step run.
- Rate-limits, batching behavior, failures/retries, and their effect on cost/time.
- Infrastructure requirements, scaling bottlenecks, and energy/compute footprint.
- Verification of next_state: Agents produce both move and next_state strings, but there is no systematic validation that next_state matches the move applied to the prior state. Needed:
- Deterministic, programmatic verification (symbolic/state-machine) to reject inconsistent next_state outputs.
- Analysis of how such verification affects , , and cost.
- Difficulty-aware policies: The protocol treats all steps uniformly. Open questions:
- Can the system detect “hard” steps (e.g., transitions with higher error rates) and allocate more votes or stricter flags adaptively?
- Does step position correlate with error likelihood, and can policies exploit that?
- Temperature and decoding calibration: Only limited temperature comparisons are shown. More work is needed to:
- Map how decoding parameters (temperature, nucleus sampling, repetition penalties) affect , diversity, and correlation.
- Develop adaptive decoding policies that target a desired balance between correctness and variance.
- Statistical evidence of “zero errors”: The claim of a million-step, zero-error solve is not accompanied by:
- Detailed run logs, seeds, model versions, and verification traces.
- Replication across multiple independent runs with confidence intervals.
- Postmortem of near-failures and the margin by which voting prevented errors.
- Cost estimation variance and confidence: Expected cost calculations use average token counts and assume stable pricing. To improve operational planning:
- Report cost variance, tail behavior (heavy outputs), and sensitivity to and estimation errors.
- Model provider-side outages, retries, and billing anomalies in the cost envelope.
- Safety, security, and adversarial robustness: The approach does not discuss:
- Prompt injection or adversarial inputs affecting many-step pipelines.
- Defensive measures (content filters, anomaly detection) integrated with red-flagging.
- Privacy/compliance risks of large-scale API usage and logging.
- Integration with tools and programmatic checks: The experiments exclude tool-augmented models. Open directions:
- Combine MAKER with lightweight tools (parsers, validators, simulators) to raise and lower .
- Study how external verification affects correlated errors and cost.
- Applicability to insight-generation tasks: The paper argues non-reasoning models suffice for execution, but does not explore:
- When higher-level reasoning or planning is truly necessary (e.g., dynamic strategies, changing goals).
- Hybrid pipelines that separate “insight” and “execution” agents with interfaces and guarantees.
- Human-in-the-loop and escalation policies: No mechanisms are described for:
- Detecting when voting fails or becomes inefficient and escalating to human review.
- Logging and summarizing disagreements for auditability and learning.
- Open-source reproducibility: To facilitate adoption:
- Release full code, prompts, parsers, and scripts used for estimation and the million-step run.
- Provide standardized benchmarks beyond Towers of Hanoi to measure MDAP vs single-agent systems.
- Environmental footprint: The scalability claim focuses on token cost; there is no analysis of:
- Energy consumption, carbon footprint, and sustainability of million-step MDAP runs.
- Optimization strategies (e.g., local inference for SLMs) to reduce environmental impact.
These gaps outline a concrete agenda: formalize and verify the math under realistic sampling; measure and mitigate correlation; develop adaptive, tool-augmented, and diversity-aware voting; validate across heterogeneous tasks; and provide full reproducibility, operational metrics, and safety analyses.
Glossary
- AALPs analysis: A method of estimating expected cost by expressing it in terms of calls to low-level LLM primitives. "It is now possible to write down the expected cost in terms of calls to LLM primitives, i.e., perform AALPs analysis \cite{meyersonposition}."
- Auto-regressive: A property of models that generate each token conditioned on previously generated tokens, making outputs increasingly dependent on context. "Because LLMs are auto-regressive, when generating the th action, a single agent is increasingly burdened by the context produced in generating actions ."
- Ensembling: Combining multiple model outputs (e.g., via voting) to improve accuracy and robustness. "voting, or ensembling, which has been a core machine learning technique for decades \cite{opitz1999popular, mienye2022survey, ganaie2022ensemble}, and is now commonly used to boost the accuracy of LLM-based systems \cite{Trad2025voting}."
- First-to-ahead-by- voting: A sequential voting scheme where sampling continues until one candidate is ahead by votes, then that candidate is selected. "a first-to-ahead-by- voting process is used, motivated by the optimality of such an approach in the sequential probability ratio test (SPRT) \cite{wald2004sequential, lee2025consol}."
- Gambler's ruin: A classic stochastic process modeling the probability that one competitor wins a random walk race to an absorbing boundary. "This process is a generalization of the classic gambler's ruin problem \cite{bernoulli1713ars}, but with simultaneous dependent races between all pairs of candidates \cite{ross2025first}."
- Grammar-constrained (JSON/CFG) decoding: Constraining generation to a prescribed grammar (e.g., JSON schema or CFG) to enforce structure and improve downstream parsing. "Grammar-constrained (JSON/CFG) decoding reliably enforces structure and often improves downstream pipelines \cite{geng2025jsonschemabench,openai2024structured},"
- Hitting probability: The probability that a stochastic process reaches a particular threshold or boundary; used to analyze voting selection. "where Eq.~\ref{eq:assume} comes from plugging and into the hitting probability formula for gambler's ruin \cite{ross2025first}."
- Hitting time: The expected number of steps for a stochastic process to reach a threshold; used to estimate expected cost in sequential voting. "where Eq.~\ref{eq:sub_cost} comes from plugging Eq.~\ref{eq:assume} into the hitting time for gambler's ruin \cite{bernoulli1713ars},"
- Language-based algorithms (LbAs): Algorithms implemented through natural language interfaces, with LLMs executing language-defined computational processes. "LLMs now serve as the basis of another substrate of computing, linguistic computing, whose constituent processes are language-based algorithms (LbAs) \cite{meyersonposition, chen2024design}."
- Long-horizon execution: Performing long sequences of dependent steps where reliability typically degrades as horizon length increases. "While this work identified a fundamental liability of LLMs in long-horizon execution, it also presented an opportunity: Even small improvements in individual subtask performance could lead to exponential improvements in achievable task lengths \cite{sinha2025}."
- Massively decomposed agentic processes (MDAPs): A framework that breaks tasks into many minimal subtasks solved by specialized agents, enabling scalability via local error correction. "Such an approach is proposed in this paper: Massively decomposed agentic processes (MDAPs)."
- Maximal Agentic Decomposition (MAD): The extreme decomposition where each subtask contains exactly one step, maximizing modularity for error correction. "(1) Maximal Agentic Decomposition (MAD; Section~\ref{sec:mad}): By breaking a task with steps into subtasks, each agent can focus on a single step;"
- Microagents: Very small, focused agents assigned to tiny subtasks to reduce complexity and error. "The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents."
- Multi-agent advantage: A capability achieved by multiple coordinated agents that a single monolithic agent cannot match. "The results demonstrate an instance of multi-agent advantage (akin to quantum advantage \cite{harrow2017quantum}), that is, a solution to a problem that is not solvable by a monolithic single-agent system."
- Quantum advantage: The phenomenon where quantum algorithms outperform classical ones, used here as an analogy for multi-agent benefits. "multi-agent advantage (akin to quantum advantage \cite{harrow2017quantum}),"
- Red-flagging: Discarding outputs that exhibit structural signs of unreliability (e.g., excessive length or bad formatting) to reduce errors. "(3) Red-flagging (Section~\ref{sec:red_flagging}): Reliability can be further boosted by discarding any response with high-level indicators of risk."
- Scaling laws: Mathematical relationships describing how success probability or cost changes with task parameters (e.g., steps, decomposition). "A formalization of this framework that yields scaling laws, e.g., how probability of success and expected cost change w.r.t. the number of total steps and level of task decomposition."
- Semantic density: The consistency of semantic content across multiple samples; higher density correlates with correctness. "For example, work on semantic density shows that the semantic content most consistently sampled from an LLM for a given prompt is more likely to be correct than a greedy decoding \cite{xin2024semantic}."
- Sequential probability ratio test (SPRT): An optimal sequential hypothesis testing procedure dictating when to stop sampling and decide between alternatives. "motivated by the optimality of such an approach in the sequential probability ratio test (SPRT) \cite{wald2004sequential, lee2025consol}."
- Small LLM (SLM) agents: Lightweight LLMs deployed as focused agents for subtasks, often favored for reliability and cost. "The rise of decomposing tasks into subtasks solvable by focused ``small LLM'' (SLM) agents in industry, motivated by both reliability and cost \cite{belcak2025smalllanguagemodelsfuture},"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by leveraging the paper’s MAKER framework for massively decomposed agentic processes (MDAPs), first-to-ahead-by-k voting, and red-flagging to achieve error-free execution across very long task horizons.
- Enterprise back-office reliability (finance, supply chain, insurance)
- Use case: High-volume, rule-based processing (e.g., invoice normalization, claims adjudication, purchase order matching, reconciliation of ledgers at scale).
- Workflow: Define atomic micro-steps per record and field; apply per-step voting among small, low-cost models; enforce structured decoding; discard red-flagged outputs (overly long or misformatted); chain validated state to the next step.
- Potential tools/products: “Agent Voting Plug-in” for BPM/ERP systems (e.g., SAP, Oracle, ServiceNow, Camunda); “Red-Flag Validator” for structured output enforcement (JSON/CFG).
- Assumptions/dependencies: Deterministic rules per step; per-step correct output more probable than any single incorrect output; batch APIs for parallel sampling; privacy and audit logging in regulated environments.
- Data engineering and ML pipelines (software/data)
- Use case: Error-intolerant schema transformations, ETL row-level normalization, constraint-preserving data cleaning across millions of rows.
- Workflow: Microagent per row or field transform; grammar-constrained outputs; first-to-ahead-by-k voting; red-flagging for long/invalid responses; maintain per-step state lineage.
- Potential tools/products: “MAKER ETL Orchestrator” (integrates with Airflow/Prefect/Dagster), “AALPs Cost Planner” to choose the best model by cost/success ratio.
- Assumptions/dependencies: Clear per-step schema/constraints; ability to parallelize votes; accurate state representation between steps.
- Codebase-wide refactoring and migration (software engineering)
- Use case: Atomic, repetitive code edits (API changes, linting fixes, deprecation updates) across monorepos with zero tolerance for format and syntax errors.
- Workflow: Treat each edit as a single step; require exact match plus unit tests; majority voting among small LLMs; red-flag verbose or misformatted diffs; commit gating via CI.
- Potential tools/products: “Stepwise Refactorer” (Git/CI integration), structured patch generators with JSON/CFG constraints.
- Assumptions/dependencies: Tests or static analysis as ground truth; atomic edit design; reliable parsers for diffs.
- SRE/DevOps runbook execution (software operations)
- Use case: Large runbooks comprising thousands of checks and small corrective actions (config validation, policy enforcement, rollout gating).
- Workflow: Microagent per check/action; enforce strict output formats; per-step voting; red-flag escalation; attach evidence blobs to state for audit.
- Potential tools/products: “Reliable Runbook Executor” for Kubernetes/CloudOps; parallel vote runners leveraging batch APIs.
- Assumptions/dependencies: Low-latency sampling infrastructure; fine-grained, well-specified steps; access control and rollback plans.
- Clinical administration and coding (healthcare)
- Use case: ICD/CPT coding, prior authorization packet assembly, payer rule normalization at scale with near-zero format errors.
- Workflow: Micro-steps per code assignment or rule check; per-step voting; red-flagging; enforce JSON schema for outputs; preserve provenance for audit.
- Potential tools/products: “Clinical Coding Assistant” (EHR integration), structured decoders aligned with payer rule schemas.
- Assumptions/dependencies: Deterministic, well-specified coding rules; PHI protections; human-in-the-loop escalation on ambiguous cases.
- Procurement and regulatory document compliance (public sector and enterprise policy)
- Use case: Clause-by-clause compliance checks across large contracts or RFPs; standard form validation; policy conformance at scale.
- Workflow: Microagent per clause check; voting; schema-constrained outputs; red-flag formatting; assemble verified compliance reports from per-step states.
- Potential tools/products: “Regulatory Checker” (contracts/RFPs), audit-ready output schemas.
- Assumptions/dependencies: Codified policies; exact-match or semantically equivalent answer classification; governance for override paths.
- Assessment generation and verification (education)
- Use case: Large-scale item bank construction with step-by-step solutions and rubric alignment, ensuring error-free formatting and logic chains.
- Workflow: Micro-steps for stem generation, solution step validation, rubric tagging; per-step voting; red-flag responses exceeding length or violating schema.
- Potential tools/products: “Assessment Generator,” structured solution validators.
- Assumptions/dependencies: Clear rubrics; constraint schemas; human review for borderline items.
- Personal task dispatch with safeguards (daily life)
- Use case: Email triage, calendar scheduling, bill payment reminders with strict formatting (ICS, CSV) and deterministic outcomes.
- Workflow: Microagent per message/event; voting; red-flag outputs; strict schema for calendar entries and reminders; summary review queue.
- Potential tools/products: “Personal Dispatcher” with vote-parallelization for busy inboxes.
- Assumptions/dependencies: User approval for flagged items; error-tolerant domains kept minimal; secure data access.
Long-Term Applications
The following use cases require additional research, integration, scaling, or safety validation before deployment, but are directly enabled by the paper’s methods and findings.
- Safety-critical execution (healthcare, aviation, industrial control)
- Use case: Medication dispensing, radiation therapy planning, air traffic procedure execution, high-voltage switching.
- Path to deployment: Combine MDAP with formal verification, certified tool-use (calculators, databases), semantic-equivalence voting, and continuous monitoring; rigorous validation and regulatory approvals.
- Potential tools/products: “Safety-Critical MDAP Stack” (formal methods + microagent orchestration), certified semantic vote classifiers.
- Assumptions/dependencies: Verified step definitions; independent error sampling; certified models and toolchains; robust incident handling.
- Autonomous robotics and manufacturing (robotics, industrial engineering)
- Use case: Multi-thousand-step assembly procedures, task-level controllers with micro-steps (grasp-check-place loops), maintenance procedures at plant scale.
- Path to deployment: Integrate MDAP with perception/tool-use, sensor feedback, and low-level controllers; semantic voting over action candidates; real-time red-flagging.
- Potential tools/products: “Robotics Orchestrator” (MDAP + PLC/ROS integration), action-equivalence voters.
- Assumptions/dependencies: Accurate state modeling; low-latency inference; physical safety constraints; domain-specific simulators for validation.
- Large-scale civic processes (government)
- Use case: Tax return processing, social benefit eligibility determinations, procurement oversight—millions of dependent steps with near-zero errors.
- Path to deployment: MDAP embedded in case management; standardized step schemas; cost modeling (AALPs) for budget predictability; auditability-by-design.
- Potential tools/products: “Government Reliability Stack” (MAKERflow + case systems), reliable red-flag channels to human reviewers.
- Assumptions/dependencies: Clear statutory rules; privacy and access controls; governance; transparent model selection based on cost/success ratios.
- Automated research workflows (academia, biotech, labs)
- Use case: Multi-step lab protocols, simulation-experiment pipelines, data curation for large studies, systematic reviews with structured outputs.
- Path to deployment: MDAP integrated with lab instruments and ELNs; per-step voting; red-flagging; provenance and reproducibility tooling.
- Potential tools/products: “Labflow Orchestrator,” microagent registries for protocol steps; reliability dashboards.
- Assumptions/dependencies: Instrument APIs; protocol codification; safety validation; IRB/regulatory compliance for human-involved studies.
- Automatic task decomposition discovery (software + AI research)
- Use case: Learning optimal micro-step granularity for new domains where step definitions aren’t given a priori.
- Path to deployment: Research on step discovery via reinforcement learning, program synthesis, or demonstration clustering; evaluate per-step success probability (>0.5) and correlated error mitigation.
- Potential tools/products: “Decomposer” service; step-quality estimators; decomposition A/B testing harnesses.
- Assumptions/dependencies: Sufficient data for learning; domain-specific constraints; evaluation benchmarks for million-step tasks beyond Hanoi.
- Semantic-equivalence voting and red-flags (cross-sector)
- Use case: Voting not only on exact matches but on semantically equivalent outputs; richer red-flag signals (uncertainty, contradiction, entropy spikes).
- Path to deployment: Classifiers for semantic equivalence; uncertainty-aware sampling; adaptive k based on per-step confidence.
- Potential tools/products: “Semantic Vote Classifier,” “Adaptive-k Controller.”
- Assumptions/dependencies: Reliable semantic assessors; calibration; guardrails against correlated misclassification.
- Reliability-as-a-Service platforms (software/enterprise)
- Use case: Turnkey MDAP orchestration with cost planning, model selection, parallel vote infrastructure, auditability, and scaling guarantees.
- Path to deployment: Hosted orchestration layer; AALPs-based model chooser (minimize cost/success ratio c/p); automatic batch API exploitation; parallel vote “farms.”
- Potential tools/products: “MAKERflow,” “Reliability Planner,” “Vote Farm.”
- Assumptions/dependencies: Vendor APIs for batch/parallel use; observability; SLAs; governance over model updates.
- Standards and certification for linguistic computing error correction (policy/industry consortia)
- Use case: Industry-wide protocols for MDAP reliability, audit trails, and error-correction claims; certification for high-stakes domains.
- Path to deployment: Multi-stakeholder standards (output schemas, step provenance, voting transparency); conformance test suites for million-step reliability.
- Potential tools/products: Certification frameworks; conformance harnesses; public benchmarks.
- Assumptions/dependencies: Consensus bodies; alignment with regulators; reproducible evaluations.
Cross-cutting assumptions and dependencies
- Steps must be defined such that the correct output is more likely than any single incorrect output (i.e., per-step success probability p > 0.5).
- Errors across samples should be sufficiently decorrelated; voting improves correctness under independence or weak correlation.
- Reliable state representation and parsers are critical; structured decoding (JSON/CFG) should be enforced to support red-flagging and state passing.
- Cost and latency budgets depend on parallel vote execution (first-to-ahead-by-k) and availability of batch APIs.
- Red-flagging policies should be tuned to balance increased p (success rate) vs. discard costs; richer signals (format, length, uncertainty) can further reduce correlated errors.
- Model selection should minimize cost/success ratio (c/p); smaller, non-reasoning models often suffice under extreme decomposition.
- Governance, auditability, and data privacy must be integrated from the start, especially in regulated sectors.
Collections
Sign up for free to add this paper to one or more collections.