- The paper introduces MarsRL's RL framework that jointly optimizes Solver, Verifier, and Corrector agents via agent-specific reward decoupling.
- It employs agentic pipeline parallelism and grouped rollouts to reduce latency and memory bottlenecks during ultra-long multi-agent trajectories.
- Experiments demonstrate accuracy gains from 86.5% to 93.3% and from 64.9% to 73.8%, highlighting robust cross-agent generalization.
MarsRL: Reinforcement Learning for Multi-Agent Reasoning Systems with Agentic Pipeline Parallelism
Introduction
MarsRL presents a novel agentic reinforcement learning framework designed to advance the capabilities of multi-agent reasoning systems. The fundamental design targets joint optimization of three agent roles—Solver, Verifier, and Corrector—by introducing agent-specific reward decoupling and agentic pipeline parallelism to enhance both training efficiency and performance. This framework addresses two core challenges in agentic RL: reward noise due to undifferentiated credit assignment and the computational inefficiency endemic to ultra-long multi-agent rollouts. Empirical results on rigorous reasoning benchmarks such as AIME-2025 and BeyondAIME indicate substantial performance improvements, outperforming larger open-source LLMs when applied to Qwen3-30B-A3B-Thinking-2507, with accuracy gains from 86.5% to 93.3% and from 64.9% to 73.8%, respectively.
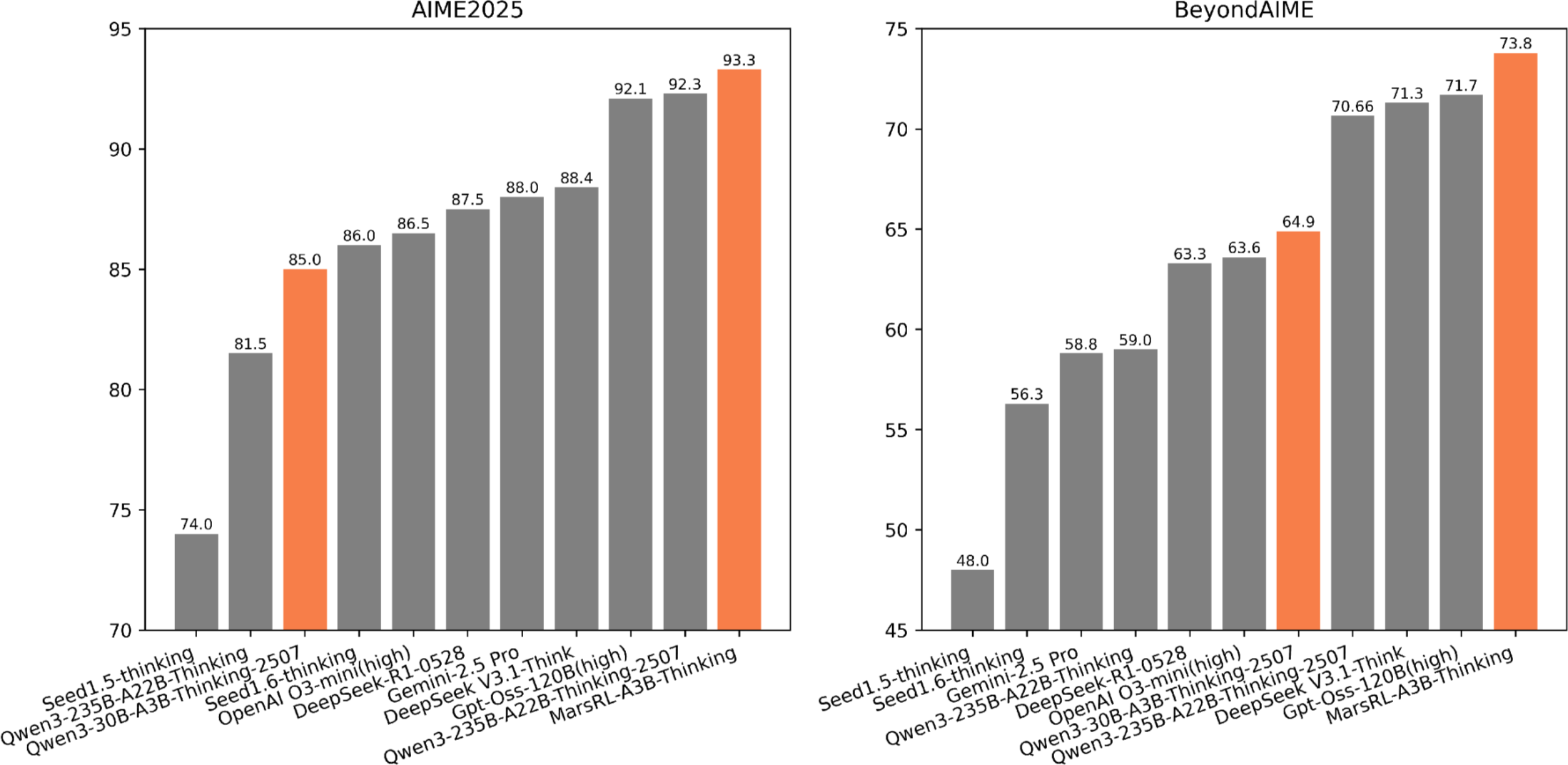
Figure 1: MarsRL system interface illustrating multi-agent reasoning processes governed by RL-driven agentic pipeline parallelism.
Multi-Agent Reasoning Systems: Architecture and Problems
Recent literature has demonstrated that multi-agent systems, including pipelines leveraging iterated self-verification and solution refinement, can surpass the reasoning limits of single-agent LLM approaches, especially for complex mathematical and scientific domains. The V-C (Verifier-Corrector) system reframes previous iterative refinement pipelines into three modular agents: Solver produces a solution; Verifier detects errors; Corrector amends outputs according to error reports. Transferability of this architecture is limited in open-source models due to deficient critic/correction capabilities.
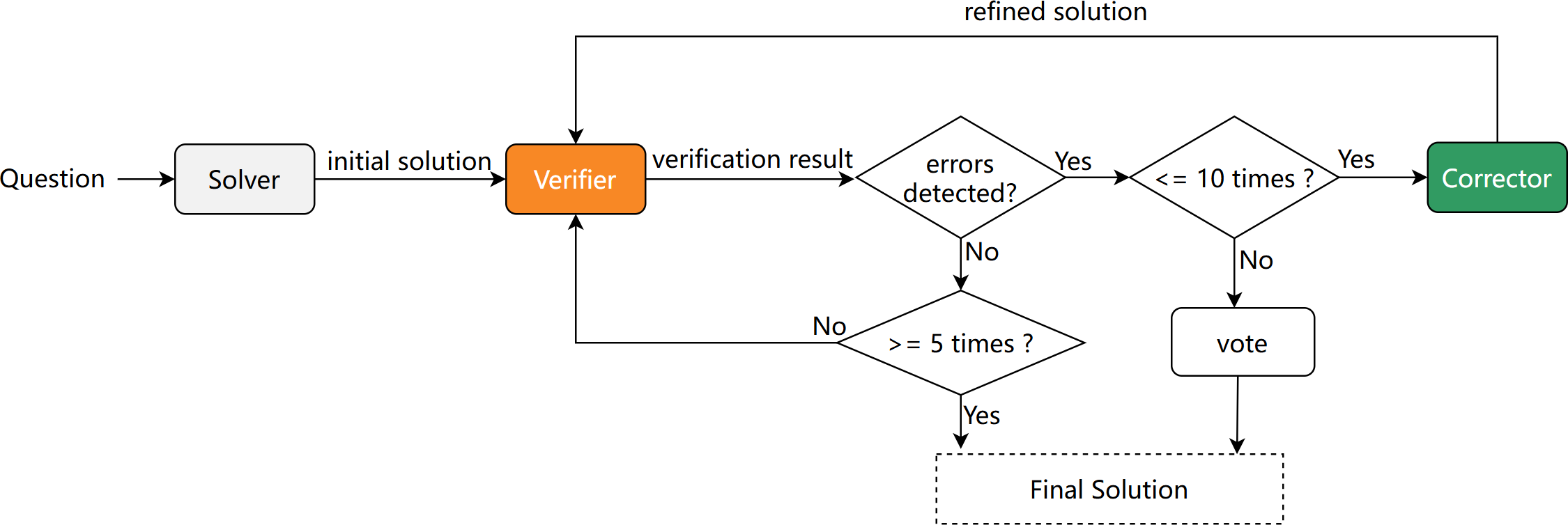
Figure 2: Overview of the Verifier-Corrector Reasoning System, including the modularization of agent roles.
MarsRL addresses this paucity via agentic RL, orchestrating joint optimization of all agent roles to cultivate robust critic and correction ability, thereby extending practical applicability to open-source LLMs without reliance on closed-source pretraining artifacts.
Agentic RL Modeling and Reward Assignment
MarsRL models the multi-agent V-C reasoning pipeline as a time-stepped RL process, where each agent's output serves as input for the subsequent agent. The pipeline is instantiated for up to five sequential agent steps per problem (Solver → Verifier1 → Corrector1 → Verifier2 → Corrector2), followed by alternating Verifier2/Corrector2 invocations until termination criterion is met.
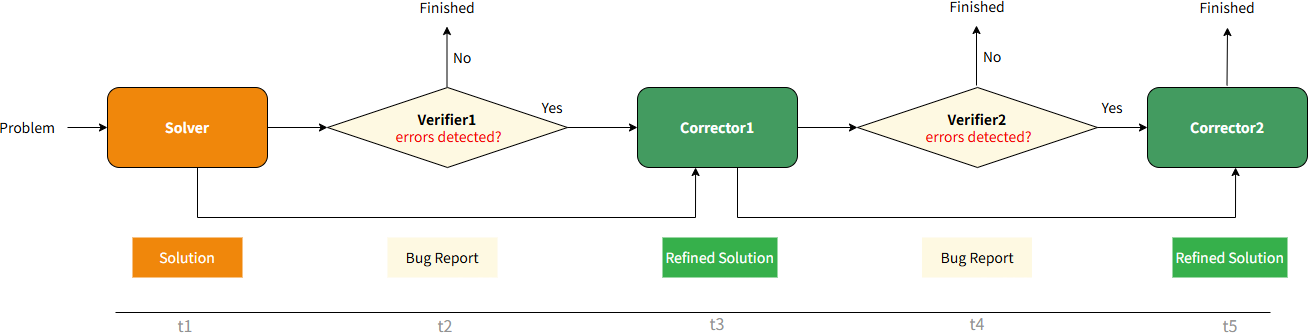
Figure 3: Sequential modeling of the multi-agent V-C reasoning system within an agentic RL framework.
MarsRL's primary innovation is agent-specific verifiable rewards:
- Solver: Reward is binary, contingent on exact solution match to ground truth;
- Corrector: Reward parallels Solver, applied to refinement outputs;
- Verifier: Reward depends on correct error identification or acceptance, penalizing both false positives and false negatives.
This decoupled reward assignment eliminates misaligned credit assignment and subsequent reward noise that arises in traditional multi-agent RL, which typically assigns a trajectory-level reward irrespective of agent performance.
Agentic Pipeline Parallelism and Grouped Rollouts
To optimize the throughput of ultra-long multi-agent trajectories, MarsRL introduces agentic pipeline parallelism inspired by GPipe. Rollout and training queues are decomposed to agent-level granularity, enabling immediate training on each agent's output upon completion, thus mitigating latency and memory bottlenecks from extended serialization.
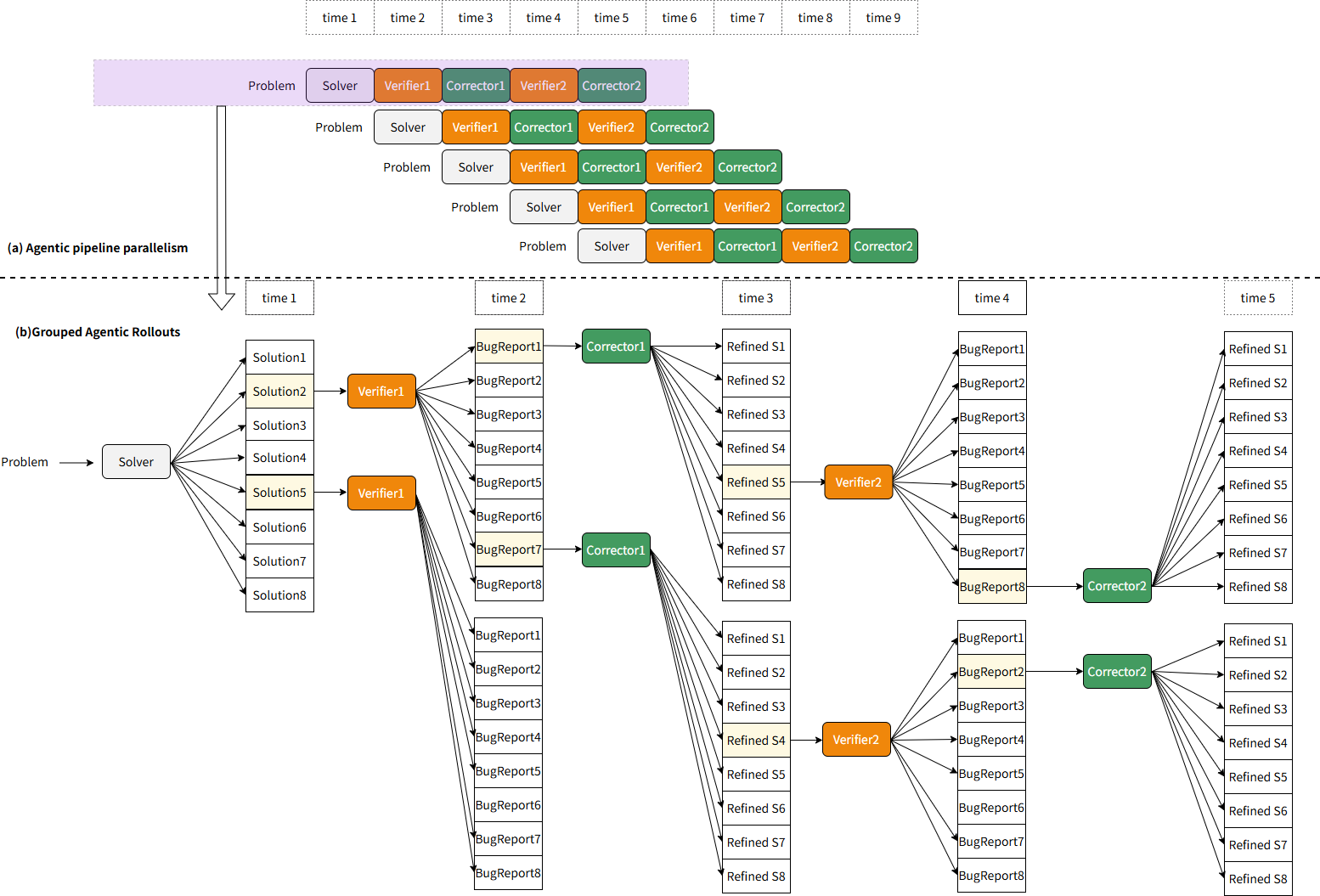
Figure 4: Illustration of agentic pipeline parallelism and arranged grouped rollouts among agents for efficient training.
MarsRL further utilizes grouped agentic rollouts. Each agent samples multiple outputs per input (group size 8), allowing subsequent agents to select representative pairs for further analysis, with specific routines ensuring error-targeted correction steps and early termination when no errors remain.
Sampling Strategies and Training Efficiency
Sampling strategy selection directly influences error detection and correction efficacy. MarsRL explores Random, Negative-Positive Balanced, and Negative-Positive Adaptive strategies. Empirical evaluation demonstrates superior performance and more robust Verifier error detection under the Adaptive strategy, which preferentially samples negative instances for verification and positive instances for correction.
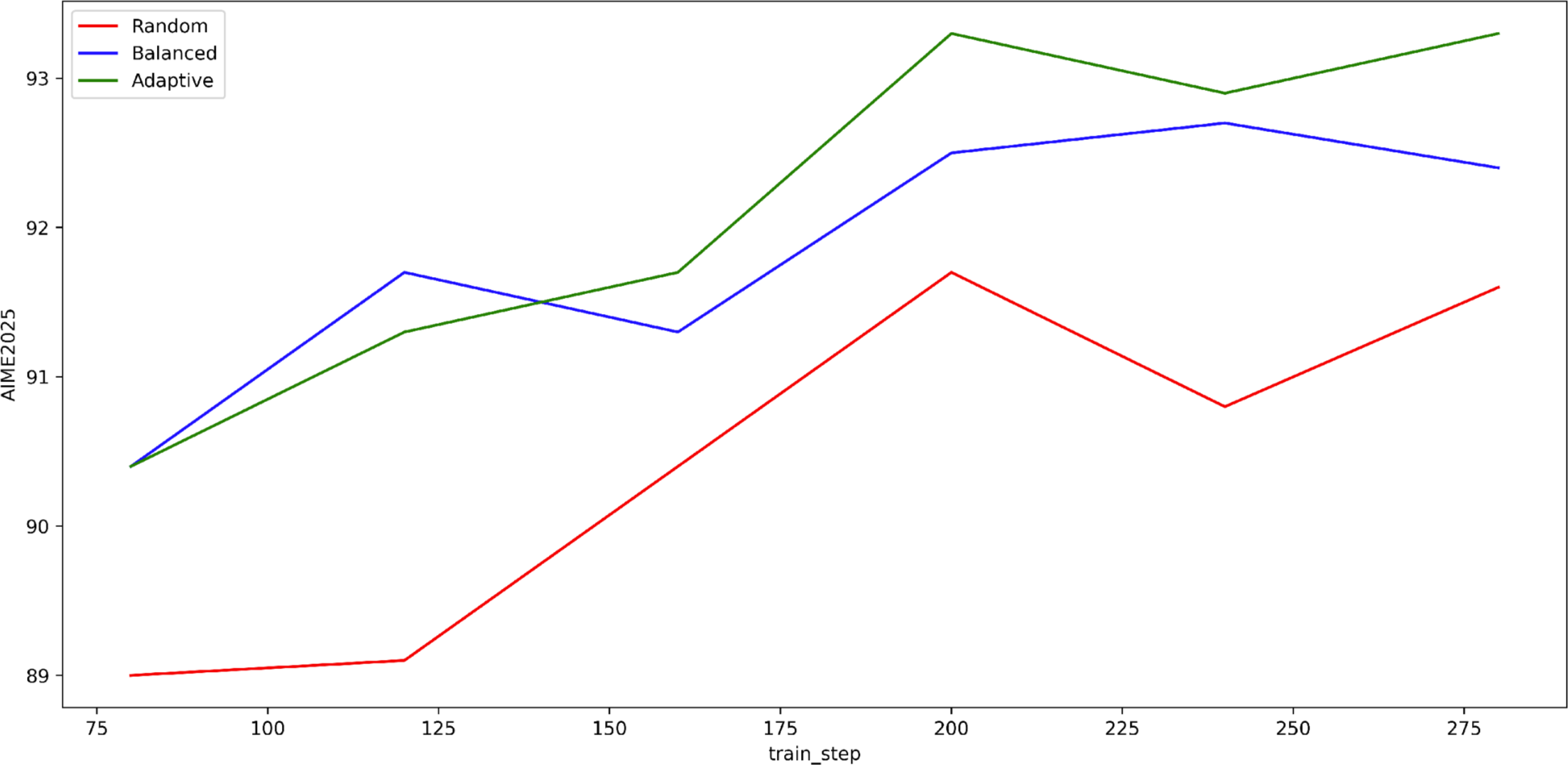
Figure 5: AIME-2025 benchmark accuracy for different agentic sampling strategies, highlighting adaptive sampling superiority.
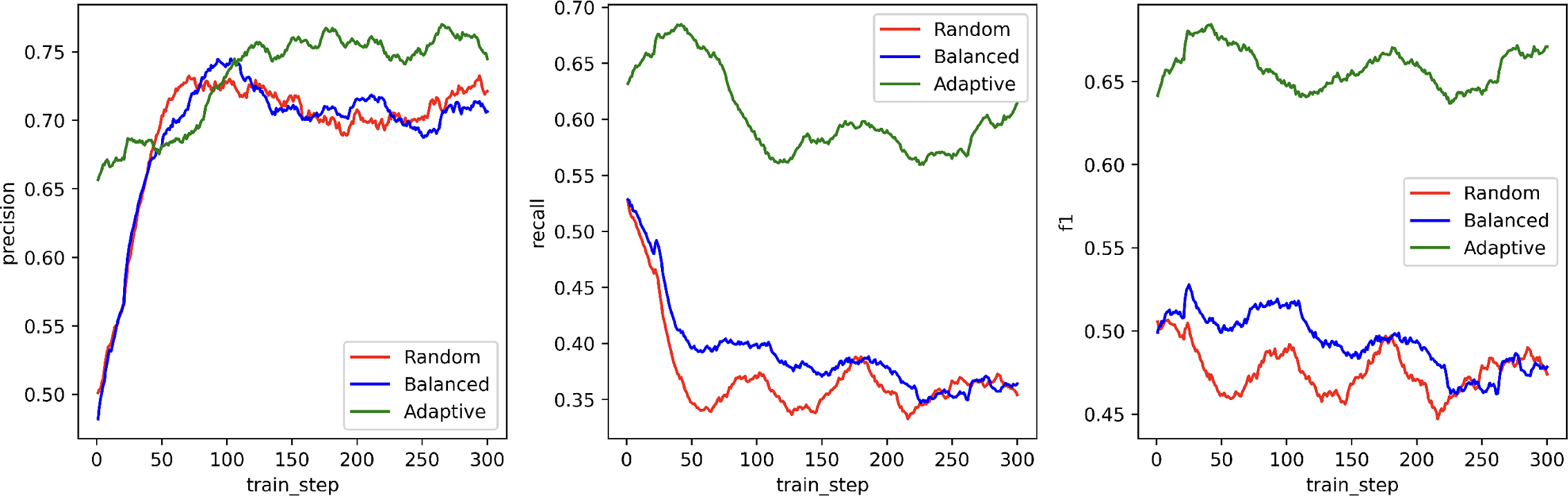
Figure 6: Training dynamics of Verifier error detection accuracy and recall across MarsRL sampling configurations.
Agentic pipeline parallelism combined with segment rollout reduces training delays and long-tail latency in generating ultra-long trajectories (maximum output length of 320k tokens), further improving memory utilization and iteration speed.
Experiments and Quantitative Analysis
A comprehensive set of experiments on Qwen3-30B-A3B-Thinking-2507 validates MarsRL. Ablation analyses isolating agent training indicate that optimizing Verifier/Corrector roles (MarsRL-VC) can yield greater improvements to the Solver's reasoning capabilities, as compared to directly training the Solver (MarsRL-S). This is evidenced by increased response length and depth of reasoning in previously untrained Solver outputs when paired with trained Verifier/Corrector modules, indicating implicit generalization via agent collaboration.
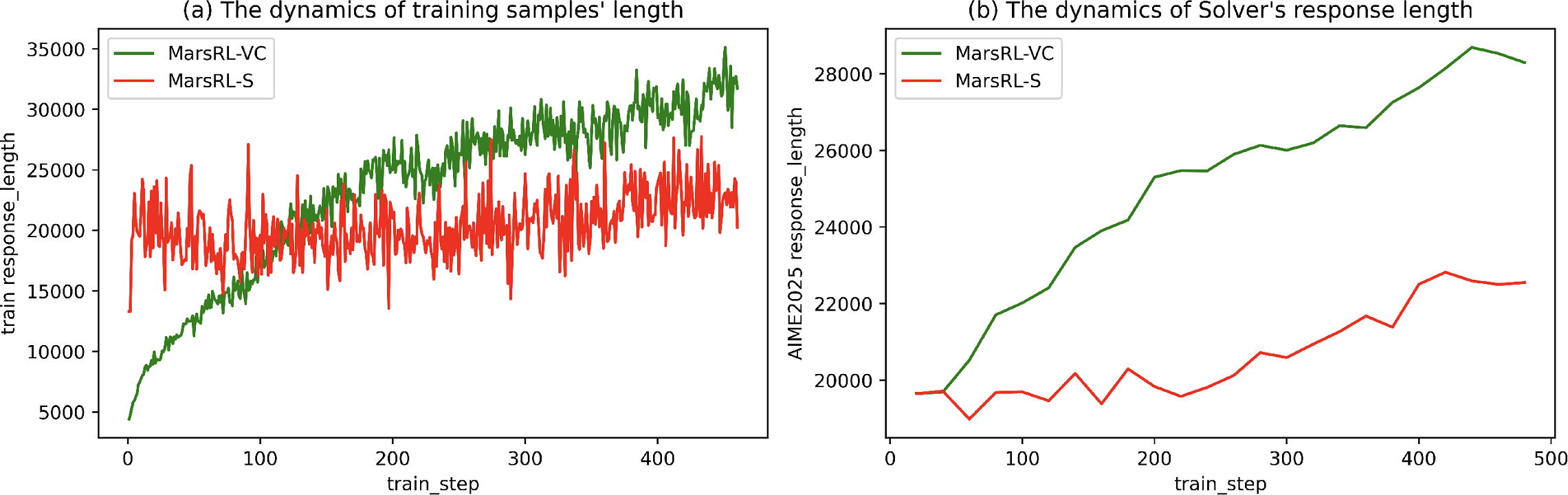
Figure 7: Dynamics of response lengths for MarsRL-S versus MarsRL-VC models, demonstrating depth-of-reasoning improvements.
Cross-agent generalization tests, with trained MarsRL Verifier/Corrector paired to various open-source Solvers, consistently outperform baseline Solvers across all tested benchmarks, underscoring the robustness and transferability of agentic RL training.
Implications and Future Directions
MarsRL demonstrates the viability of agentic RL frameworks for multi-agent reasoning architectures, particularly in open-source LLMs. By systematically addressing credit assignment and computational bottlenecks, this approach paves the way for scalable, modular multi-agent systems capable of decomposing and solving large, complex reasoning tasks with interpretable intermediate steps. The significant performance gains and demonstrated generalization suggest application potential in diverse reasoning domains (mathematics, code synthesis, scientific inference).
The agentic pipeline parallelism and agent-specific reward assignment implemented in MarsRL lay groundwork for future explorations of hierarchical agentic RL, collaborative LLM optimization, and scalable reasoning system deployment in distributed environments. Further research could focus on dynamically adaptive agent roles, more fine-grained reward signal structuring, and integration of external verification or symbolic reasoning modules to enhance system robustness.
Conclusion
MarsRL constitutes a formal advancement in agentic RL for multi-agent reasoning systems, systematically decoupling rewards and efficiently orchestrating agent pipelines. Empirical analysis validates substantial accuracy improvements and cross-agent generalization on open-source LLMs. MarsRL’s framework provides a scalable template for modular reasoning system optimization, with implications for improved LLM performance in multi-step, high-depth reasoning scenarios.

