- The paper introduces SeqTopK, a novel routing method that shifts from token-level to sequence-level expert allocation, addressing token complexity variance.
- It demonstrates how adaptive expert utilization leads to significant performance improvements, especially under sparse activation regimes.
- The method integrates seamlessly with existing MoE frameworks, maintaining computational efficiency with negligible overhead.
Sequence-Level Routing for Token-Based Mixture-of-Experts Models
Introduction
The paper "Route Experts by Sequence, Not by Token" (2511.06494) introduces a novel routing strategy called Sequence-level TopK (SeqTopK) for Mixture-of-Experts (MoE) architectures in LLMs. MoE models scale efficiently, leveraging sparse activation of expert modules, usually regulated through TopK routing, where each token claims a fixed number of experts. However, this token-level consistency does not reflect token complexity variability—trivial tokens and complex tokens are treated equally. SeqTopK proposes reallocation of expert budgets at a sequence level, adapting dynamically to token difficulties, thus improving efficiency without substantial architectural changes.
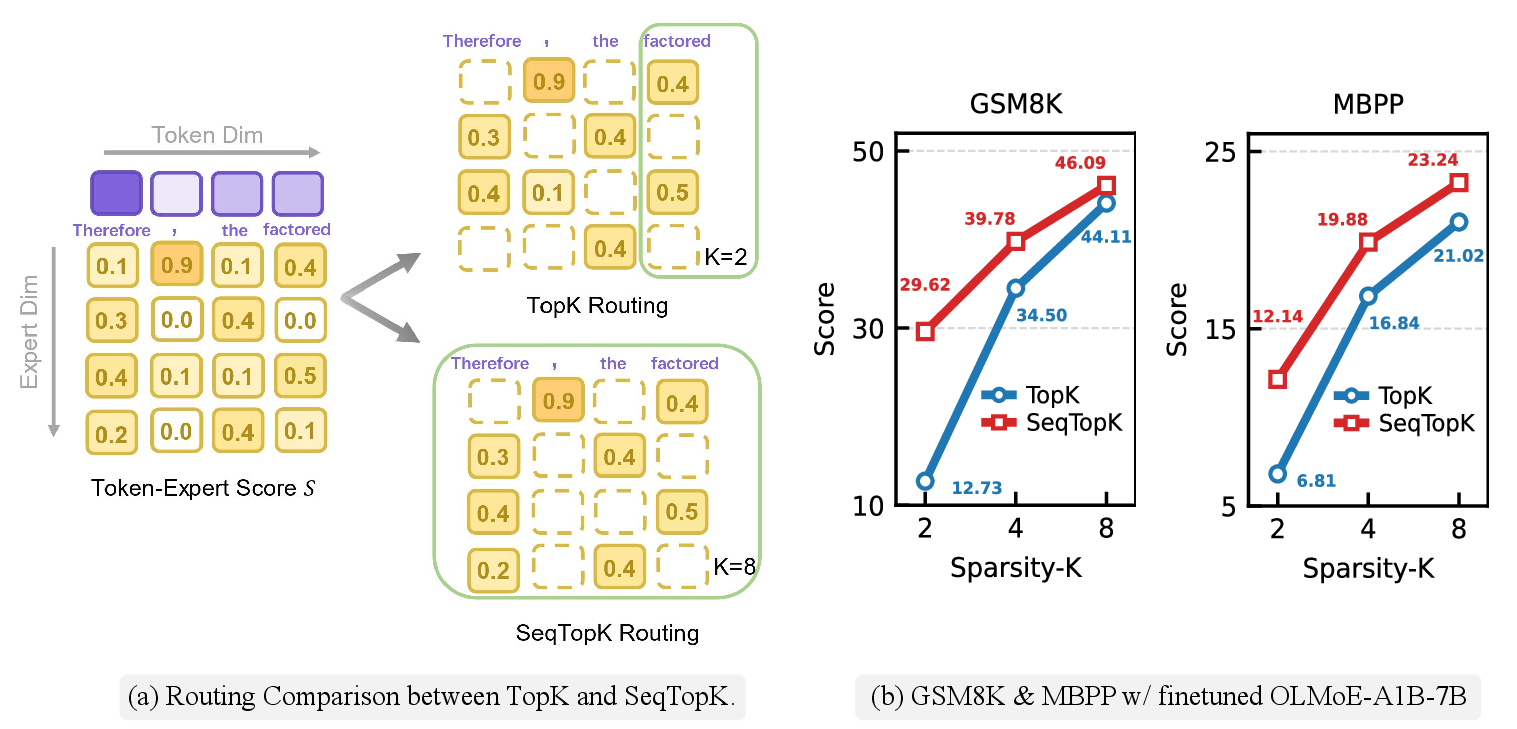
Figure 1: Overview of SeqTopK method enabling dynamic expert allocation across sequences, outperforming TopK under varied expert budgets.
SeqTopK Framework
Token-Level Heterogeneity and SeqTopK Routing
Standard TopK routing assigns a static number of experts (K) per input token, disregarding token-specific complexity. SeqTopK removes this rigidity by redistributing the expert budget across a sequence. It implements sequence-level routing, where the top T⋅K experts are selected across all T tokens, allowing more complex tokens to utilize more experts.
SeqTopK ensures end-to-end training compatibility, maintains computational cost, and retains pretrained model compatibility, requiring minimal code changes and resulting in negligible computational overhead. The method is practical for direct integration into existing MoE frameworks.
Adaptive Expert Utilization
SeqTopK's approach circumvents previous methods’ limitations by enabling dynamic routing without additional parameters or hyperparameters. The flexible allocation of experts based on token difficulty improves performance under higher sparsity, as demonstrated by significant gains across sparse regimes in practical settings.
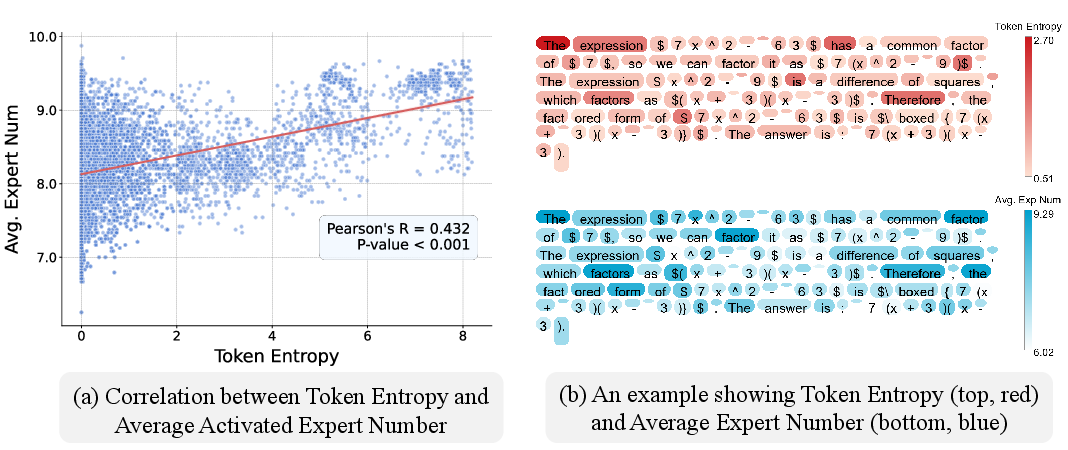
Figure 2: Correlation between token entropy and expert activation pattern under SeqTopK routing.
Benchmark and Efficiency Assessment
Fine-Tuning and Zero-Shot Evaluation
SeqTopK was evaluated across five diverse domains—math, coding, law, and writing—demonstrating consistent improvements over standard TopK and adaptive routing methods. Experimental results indicated substantial performance gains, especially under extreme sparsity scenarios, highlighting SeqTopK’s aptness for scalable next-generation LLMs.
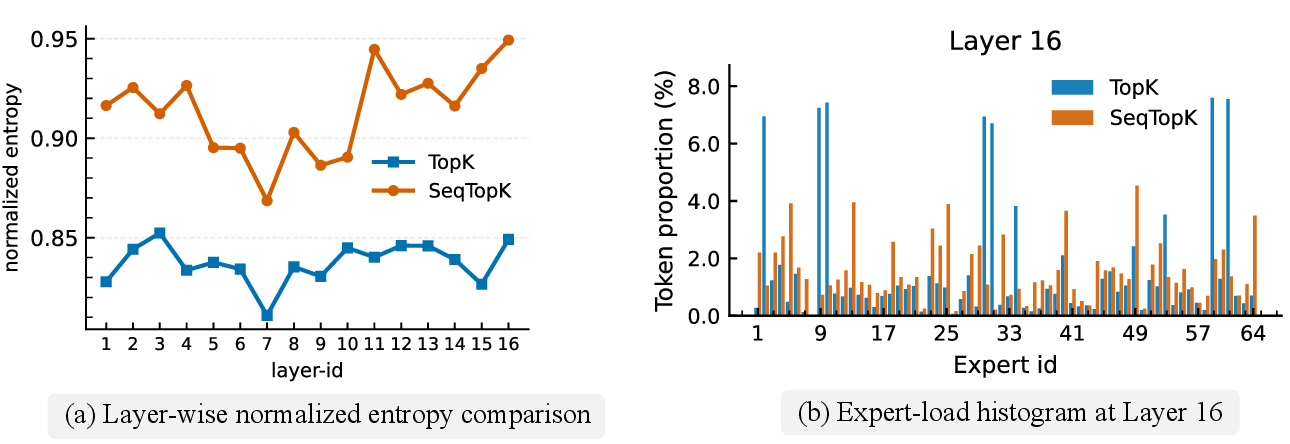
Figure 3: Comparison of routing dynamics between SeqTopK and TopK, illustrating more balanced expert utilization with SeqTopK.
Efficiency Analysis
Efficiency experiments revealed SeqTopK’s negligible overhead during both training and inference phases. The method’s use of an Expert Cache during autoregressive decoding aligns resource use with existing KV-cache mechanisms, ensuring scalability and reduced operational cost.
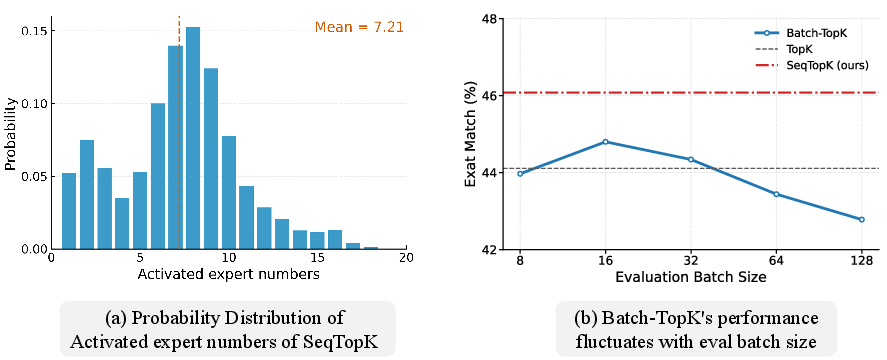
Figure 4: Effect of batch size sensitivity on expert activation pattern with SeqTopK compared to BatchTopK.
Conclusion
SeqTopK embodies a strategic shift in MoE routing by advancing token-aware computation, proving essential for efficient LLM scaling. Its compatibility with existing frameworks marks a significant step in the integration of adaptive systems for real-world applications, demonstrating both efficacy and practical deployability.
The study opens avenues for further exploration, such as combining SeqTopK with advanced token-level specialization methods, potentially revolutionizing sparse architectural design paradigms in LLMs.