- The paper presents an adaptive scheduling mechanism that dynamically adjusts the step size for expert prefetching in MoE inference.
- It integrates a RandomForestRegressor predictor and a two-level LRU cache to achieve up to 99.9% reduction in waiting latency and 30% improvement in expert prediction accuracy.
- The system demonstrates practical benefits by optimizing memory coordination and cache-aware routing, enabling efficient deployment in resource-constrained settings.
ExpertFlow: Adaptive Expert Scheduling and Memory Coordination for Efficient MoE Inference
Introduction and Motivation
ExpertFlow introduces a runtime system for Mixture-of-Experts (MoE) inference that addresses the critical bottlenecks of memory capacity and expert routing latency in LLMs. MoE architectures, by activating only a subset of experts per input, enable scaling to billions of parameters without proportional computational cost. However, conventional MoE inference suffers from significant latency due to frequent expert parameter transfers and inflexible cross-layer prediction strategies. ExpertFlow mitigates these issues by adaptively scheduling expert activation and coordinating memory management, leveraging runtime statistics and token-level features to optimize inference efficiency.
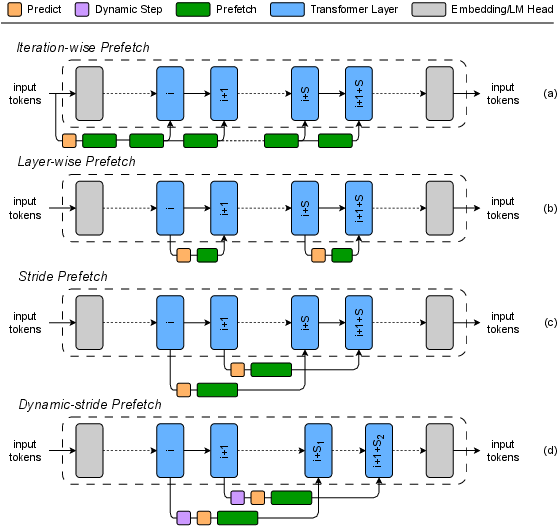
Figure 1: Candidate prefetch manners illustrating static, reactive, periodic, and adaptive expert scheduling strategies.
Adaptive Expert Prefetching and Cross-Layer Prediction
ExpertFlow's core innovation is the dynamic determination of the step size S—the number of layers for which expert predictions are made in advance. Unlike static or fixed-interval approaches, ExpertFlow continuously adjusts S based on hardware bandwidth, workload scale, and intra-batch token diversity. The system computes the cumulative Euclidean distance among token embeddings to estimate expert demand, providing a robust signal for adaptive scheduling.
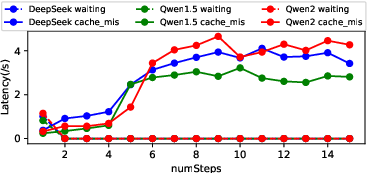
Figure 2: Latency comparison across different step sizes (S), demonstrating the trade-off between prediction horizon and cache miss rate.
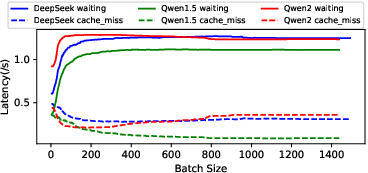
Figure 3: Latency comparison across batch sizes, highlighting the impact of workload scale and contention on expert loading.
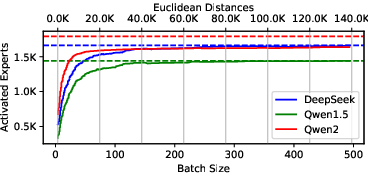
Figure 4: Variation of activated experts with batch size and Euclidean distance, quantifying semantic diversity as a predictor of expert demand.
The adaptive mechanism integrates pre-gate outputs (router logits) with token IDs and expert activation history, constructing feature vectors for a RandomForestRegressor that predicts future expert activations. This predictor is trained on structured logs of token sequences, layer indices, predicted and actual experts, and step sizes, enabling accurate prefetch planning and minimizing cache misses.
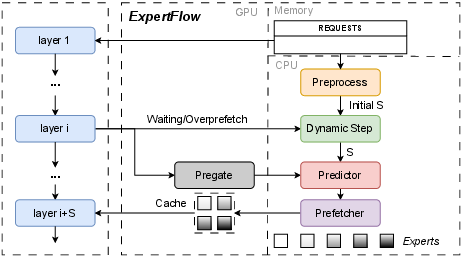
Figure 5: The System Architecture of ExpertFlow, showing the integration of adaptive scheduling, expert prediction, and memory management.
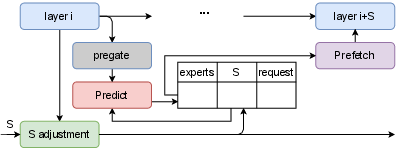
Figure 6: Mechanism for determining dynamic step size (S) using runtime feedback and expert activation statistics.
Memory Management and Cache-Aware Routing
ExpertFlow implements a two-level LRU cache to optimize expert residency in GPU memory. Frequently reused experts are retained in a high-priority cache, while less critical experts are evicted preferentially. This hierarchical caching strategy reduces memory pressure and swap-in latency, especially under constrained GPU memory.
Prefetch and cache coordination is achieved by querying cache occupancy before computing S, updating bandwidth estimates post-prefetch, and incorporating cache hit/miss statistics into the feedback loop. Cache-aware routing prioritizes tokens whose required experts are already resident, overlapping expert swap-in with ongoing computation to hide latency and improve throughput.
Experimental Evaluation
ExpertFlow was evaluated on NVIDIA A6000, H20, and Ascend 910B GPUs using DeepSeek, Qwen1.5, and Qwen2.0 MoE models. GPU memory was capped at 20GB to simulate resource-constrained environments. The system was compared against baselines including Transformers, ProMoE, and Yandex's pre-gate jobs.
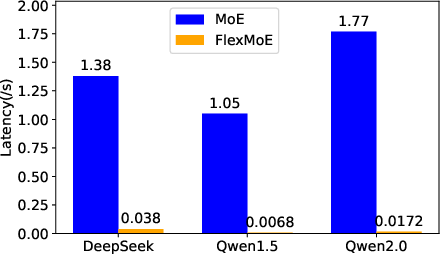
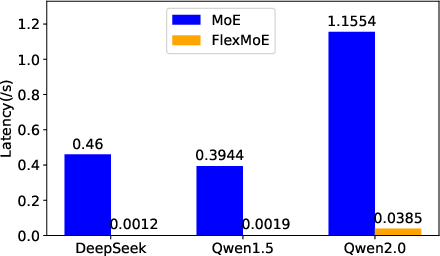
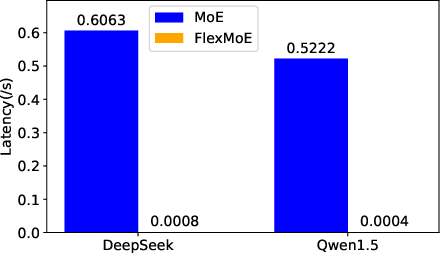
Figure 7: Overall waiting latency across devices and models, showing substantial reductions with ExpertFlow.
ExpertFlow reduced combined waiting and cache-miss latency by an average of 98.5%, with Qwen1.5 achieving over 99.9% reduction. Notably, the latency on H20 remained higher than A6000 despite superior hardware, attributed to disproportionate scaling of memory bandwidth versus compute power.
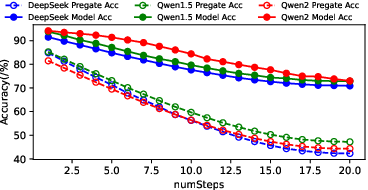
Figure 8: Accuracy of pre-gate and Predictor, demonstrating a 21.79% average improvement in expert selection accuracy.
The RandomForestRegressor-based predictor improved expert activation accuracy by up to 30.36% over pre-gate methods, with a stable advantage across all models. Latency measurements confirmed that higher prediction fidelity directly translates to reduced cache miss and waiting times.
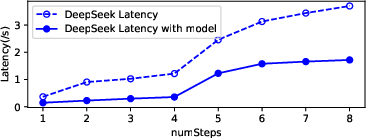
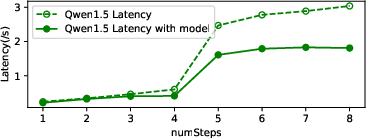
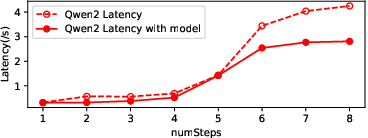
Figure 9: Latency of different models with pre-gate-based predictor, showing consistent reductions in cache miss latency.
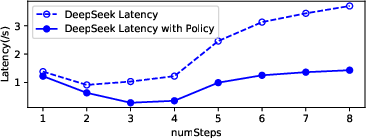
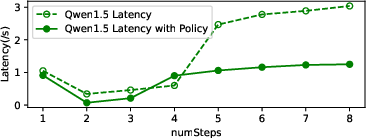
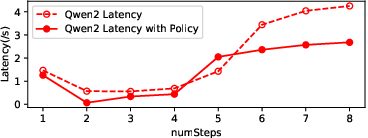
Figure 10: Latency of different models with new memory management, highlighting the impact of two-level LRU caching.
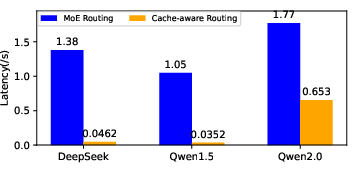
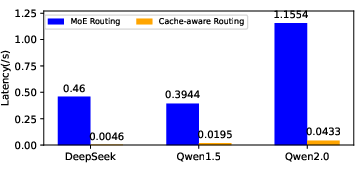
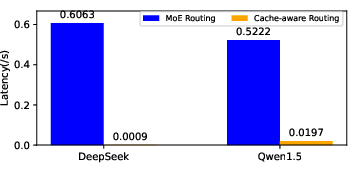
Figure 11: Comparison of latency with or without cache-aware routing, quantifying the benefit of prioritizing resident experts.
Cache-aware routing reduced latency by over 96.65% in DeepSeek and Qwen1.5, and by 55.58% in Qwen2.0, which already employed shared experts for cache efficiency.
Implementation Considerations
ExpertFlow's adaptive scheduling requires real-time monitoring of hardware bandwidth, batch statistics, and token diversity. The RandomForestRegressor predictor is CPU-based to avoid GPU contention, and the caching policy must be tightly integrated with the prefetch module for effective coordination. The system is compatible with standard MoE frameworks and can be deployed in environments with stringent memory constraints.
Performance metrics indicate that ExpertFlow eliminates up to 99.9% of waiting latency and improves expert prediction accuracy by over 30%, with stable scalability across diverse hardware and workloads. Resource requirements are modest, as the predictor operates asynchronously and memory management is lightweight.
Implications and Future Directions
ExpertFlow advances the state of MoE inference by combining adaptive expert scheduling, predictive caching, and cache-aware routing. The system demonstrates that dynamic, token-aware scheduling can substantially reduce latency and memory overhead without sacrificing model fidelity. Theoretical implications include the validation of semantic diversity as a runtime signal for expert demand and the efficacy of hierarchical memory management in large-scale sparse models.
Practically, ExpertFlow enables efficient deployment of MoE models in resource-constrained settings, supporting real-time applications and large-scale inference. Future developments may explore integration with hardware accelerators, extension to multimodal MoE architectures, and refinement of predictor models using lightweight neural networks or online learning.
Conclusion
ExpertFlow provides a comprehensive solution for efficient MoE inference, integrating adaptive cross-layer expert scheduling, hierarchical memory management, and cache-aware routing. The system achieves substantial reductions in waiting and cache-miss latency, improves expert prediction accuracy, and maintains robust performance across hardware platforms and workloads. These results underscore the importance of dynamic, data-driven scheduling and memory coordination in scalable sparse model inference, with broad implications for future AI system design.