- The paper introduces RSPO, a router-aware RL algorithm that mitigates unstable router fluctuations and reward collapse in MoE models.
- It leverages a router shift ratio and geometric mean aggregation to stabilize token-level importance sampling across policy updates.
- Experimental results show that RSPO outperforms GRPO, GSPO, and GMPO with consistent gains on diverse mathematical reasoning benchmarks.
Stable and Effective Reinforcement Learning for Mixture-of-Experts
Introduction
This paper addresses the instability and inefficiency of reinforcement learning (RL) in Mixture-of-Experts (MoE) architectures, a critical challenge for scaling LLMs with sparse activation. While RL has driven significant advances in LLM reasoning and generation, most prior work focuses on dense models, leaving MoE-specific RL training underexplored. The central issue is router fluctuation: the set of experts selected for a given token can vary substantially across policy updates, leading to high variance in importance sampling (IS) weights and frequent reward collapse. Existing stabilization strategies, such as router freezing and routing replay, either restrict model adaptability or degrade exploration, failing to resolve the underlying instability. The paper introduces Router-Shift Policy Optimization (RSPO), a router-aware RL algorithm that quantifies routing deviation and adaptively reweights updates, achieving stable and efficient training for MoE models.
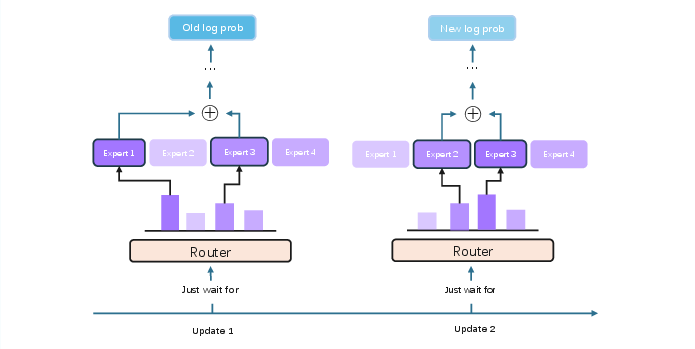
Figure 1: Router fluctuation in off-policy training, illustrating the instability in expert selection across policy updates.
GRPO, GSPO, and GMPO
Group Relative Policy Optimization (GRPO) extends PPO by removing the value model and using group-relative advantage estimation, but suffers from high computational cost and variance mismatch when applied to MoE models. GSPO and GMPO address the misalignment between sequence-level rewards and token-level IS ratios by aggregating IS ratios at the sequence level using geometric means, which is more robust to extreme token-level ratios and better suited for MoE architectures.
Methodology: Router-Shift Policy Optimization (RSPO)
RSPO introduces a router shift ratio, γi,t, which measures the deviation in router distributions between the current and previous policies for each token. This ratio is computed by averaging the log-probability differences of the top-K experts across all layers, then exponentiating and applying a floor γmin to prevent over-suppression. The router shift ratio is used to reweight token-level IS ratios after clipping, down-weighting tokens with excessive routing drift while preserving router flexibility. RSPO aggregates IS ratios using a geometric mean at the sequence level, further stabilizing training.
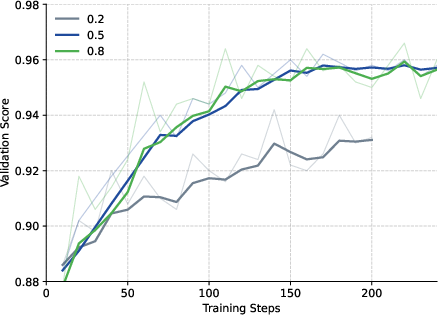
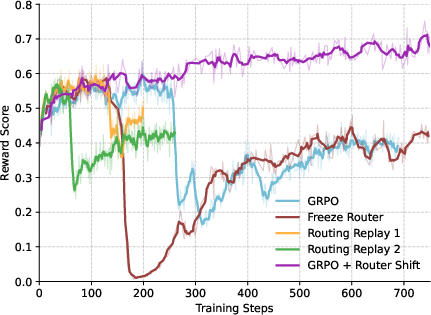
Figure 2: Ablation of γmin, demonstrating the impact of the router shift ratio floor on training stability and performance.
The PyTorch implementation involves three steps: computing the router shift ratio, clipping extreme values, and applying the ratio to smooth the IS weights. Gradients are stopped through γi,t to prevent variance amplification.
Experimental Results
RSPO is evaluated on Qwen2.5 and Qwen3-30B-A3B models across five mathematical reasoning benchmarks (AIME24, AMC23, MATH500, Minerva, OlympiadBench) using the Pass@1 metric. RSPO consistently outperforms GRPO, GSPO, and GMPO, with particularly strong gains on Minerva and OlympiadBench. Notably, GRPO exhibits reward collapse and high volatility, while RSPO maintains stable and superior validation scores throughout training.
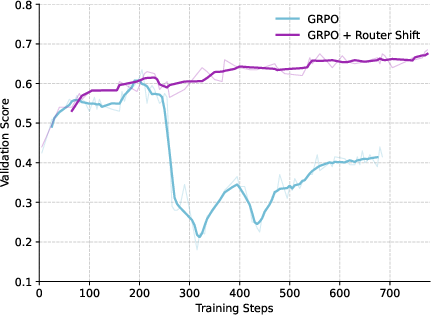
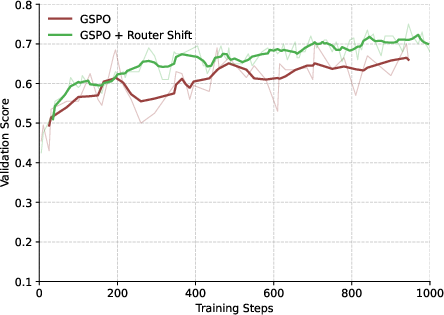
Figure 3: Validation score of GRPO, highlighting instability and reward collapse compared to RSPO and other baselines.
Ablation studies show that backpropagating through γ leads to early collapse, while stopping gradients yields smooth optimization. Setting γmin too low suppresses learning signals, while moderate values maintain stability. Alternative router stabilization strategies (freezing, copying logits, reusing expert indices) fail to improve stability, underscoring the necessity of router-aware reweighting.
RSPO is compatible with other RL algorithms; integrating router shift with GSPO or GRPO further improves stability and performance, demonstrating its generality.
Training Stability Analysis
RSPO maintains higher token entropy during training, preserving expert diversity and preventing premature collapse. The ratio of non-shifted routing increases as training progresses, indicating that the policy naturally aligns with prior routing decisions and reduces the need for shift corrections.
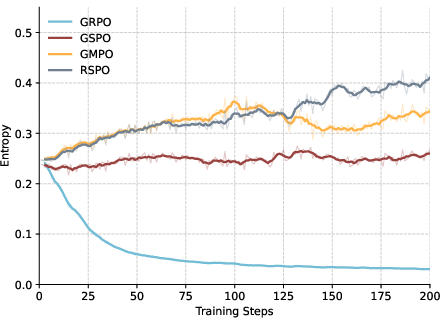
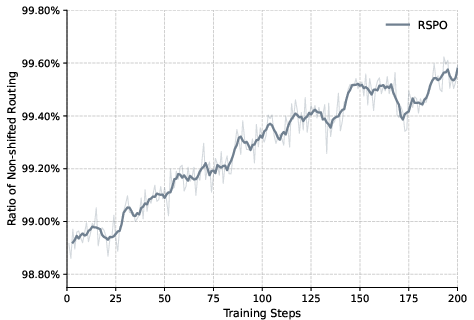
Figure 4: Entropy during training, showing that RSPO preserves higher token entropy and expert diversity compared to baselines.
Implications and Future Directions
RSPO provides a principled solution to the instability of RL in MoE models by explicitly accounting for router shift and leveraging geometric mean aggregation. This approach enables reliable deployment of large-scale expert models for complex reasoning tasks. The findings suggest that router-aware reweighting is essential for stable off-policy RL in sparse architectures, and that geometric mean aggregation should be preferred over arithmetic mean for IS ratios.
Future research may explore adaptive mechanisms for router shift ratio computation, integration with differentiable routing techniques, and extension to multimodal or hierarchical MoE architectures. Understanding the interplay between routing dynamics, gradient variance, and RL credit assignment remains an open direction, with potential impact on scaling LLMs to even larger capacities.
Conclusion
RSPO stabilizes RL training for MoE models by combining sequence-level importance sampling with router shift-aware reweighting, outperforming existing baselines in both stability and effectiveness. The method maintains high token entropy, mitigates reward collapse, and generalizes across tasks and algorithms. RSPO represents a significant advance in RL algorithmic design for sparse expert architectures, facilitating robust and efficient training of large-scale reasoning models.

