- The paper introduces the DED framework that breaks scaling laws using minimal, high-quality data for advanced reasoning and code generation.
- It employs innovative teacher model selection, rigorous corpus filtering, and trajectory diversity to enhance model robustness and out-of-domain generalization.
- Empirical results demonstrate SOTA performance on benchmarks like AIME, MATH-500, and LiveCodeBench with significantly reduced training datasets.
Data-Efficient Distillation for Reasoning: A Comprehensive Analysis of the DED Framework
Introduction
The paper "Beyond Scaling Law: A Data-Efficient Distillation Framework for Reasoning" (2508.09883) addresses the limitations of prevailing scaling laws in reasoning-focused LLM distillation. The authors propose a data-efficient distillation (DED) framework that systematically optimizes teacher selection, corpus curation, and trajectory diversity to achieve state-of-the-art (SOTA) reasoning and code generation performance with a minimal number of high-quality examples. This essay provides a technical analysis of the DED framework, its empirical results, and its implications for the development of efficient, generalizable reasoning models.
Motivation and Background
Recent advances in LLM reasoning have been driven by two main approaches: reinforcement learning with verifiable reward (RLVR) and supervised fine-tuning (SFT) using distilled chain-of-thought (CoT) traces. While scaling up the size of the distillation corpus and model parameters has led to improved performance, this approach is computationally expensive and often degrades out-of-domain (OOD) generalization. The DED framework is motivated by the need to break the scaling law trend and achieve high reasoning performance with limited, carefully curated data.
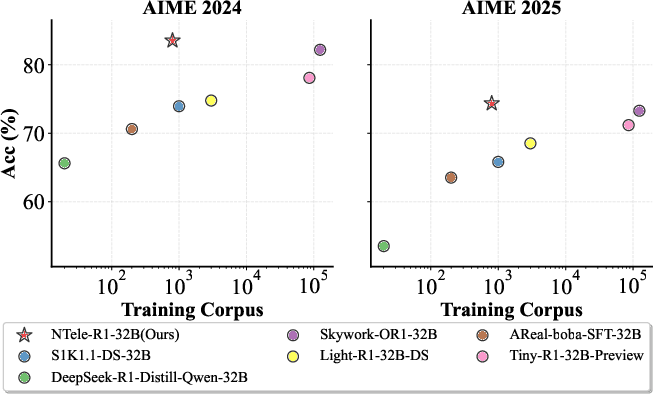
Figure 1: The performance on AIME 2024/2025 varies with the scale of the training corpus. Models fine-tuned from DeepSeek-R1-Distill-Qwen-32B exhibit a potential reasoning scaling law. Our model, NTele-R1-32B, breaks out of this trend and advances the Pareto frontier.
DED Framework: Methodological Innovations
The DED framework is structured around three core components: teacher model selection, corpus filtering and compression, and trajectory diversity enhancement.
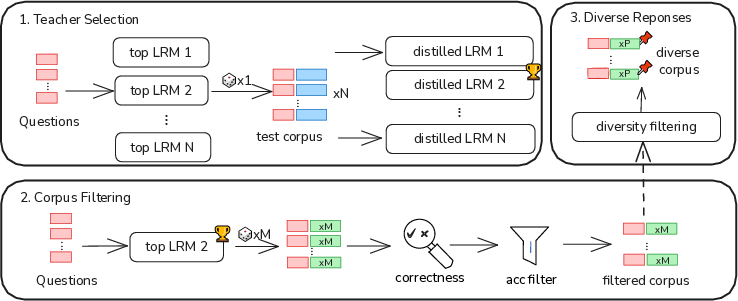
Figure 2: Overview of our data-efficient distillation framework.
Teacher Model Selection
Contrary to the common practice of selecting the teacher model with the highest benchmark scores, DED introduces a smoke-test-based selection protocol. Multiple candidate teacher models are evaluated by distilling a small set of CoT responses and measuring the downstream performance of the student model. Empirical results demonstrate that the most capable teacher on benchmarks is not always the most effective for distillation, as evidenced by QwQ-32B outperforming DeepSeek-R1 and Qwen3-235B-A22B as a teacher, despite the latter's higher raw scores.
Corpus Filtering and Compression
DED employs a two-stage corpus curation process:
- Quality and Correctness Filtering: Responses are filtered for length, format, and correctness using both rule-based and LLM-as-a-judge verification.
- Question Compression: Easy questions (high pass rate by the student) are removed, retaining only hard examples that challenge the student model. This compression can reduce the corpus size by up to 75% with minimal performance loss.
Trajectory Diversity
Inspired by RL rollouts, DED augments each question with multiple diverse reasoning trajectories, selected via maximal Levenshtein distance. This diversity is shown to be critical for robust reasoning skill transfer and generalization.
Empirical Results
Mathematical Reasoning
DED achieves SOTA results on AIME 2024/2025 and MATH-500 using only 0.8k curated examples, outperforming models trained on much larger corpora and even surpassing the teacher models themselves.
- AIME 2024: 81.87% (DED) vs. 79.2% (DeepSeek-R1) and 85.7% (Qwen3-235B-A22B)
- AIME 2025: 77.29% (DED) vs. 70% (DeepSeek-R1) and 81.5% (Qwen3-235B-A22B)
- MATH-500: 95.2% (DED) vs. 97.3% (DeepSeek-R1) and 98.0% (Qwen3-235B-A22B)
Notably, DED-trained models advance the Pareto frontier, achieving higher accuracy with fewer training samples.
Code Generation
On LiveCodeBench (LCB), DED demonstrates strong improvements, particularly on medium and hard subsets, with performance gains concentrated on challenging problems. Using only 230 hard samples (augmented to 925 via diversity), DED achieves SOTA on LCB, outperforming both the base and teacher models.
Cross-Domain Generalization
Mixed training on both math and code corpora yields SOTA results in both domains and improves OOD benchmarks such as MMLU, CMMLU, and Aider Polyglot, with the Aider score doubling from 12.4 to 25.8.
Analytical Insights
Corpus Length and Response Length
Empirical analysis reveals that neither the length of the training corpus nor the response length is a dominant factor in distillation performance. Models trained on shorter QwQ-32B responses outperform those trained on longer DeepSeek-R1 responses, challenging prior assumptions that longer CoT traces are inherently superior.
Token Entropy
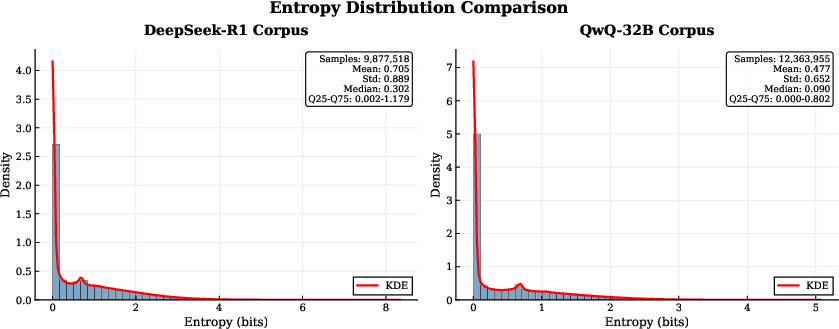
Figure 3: Comparison of token entropy distribution of teacher models.
Token entropy analysis shows that QwQ-32B-generated corpora have significantly lower entropy than DeepSeek-R1, indicating more predictable and structured token distributions. Lower entropy correlates with improved convergence, robustness, and OOD generalization in the student model.
Latent Representation Stability
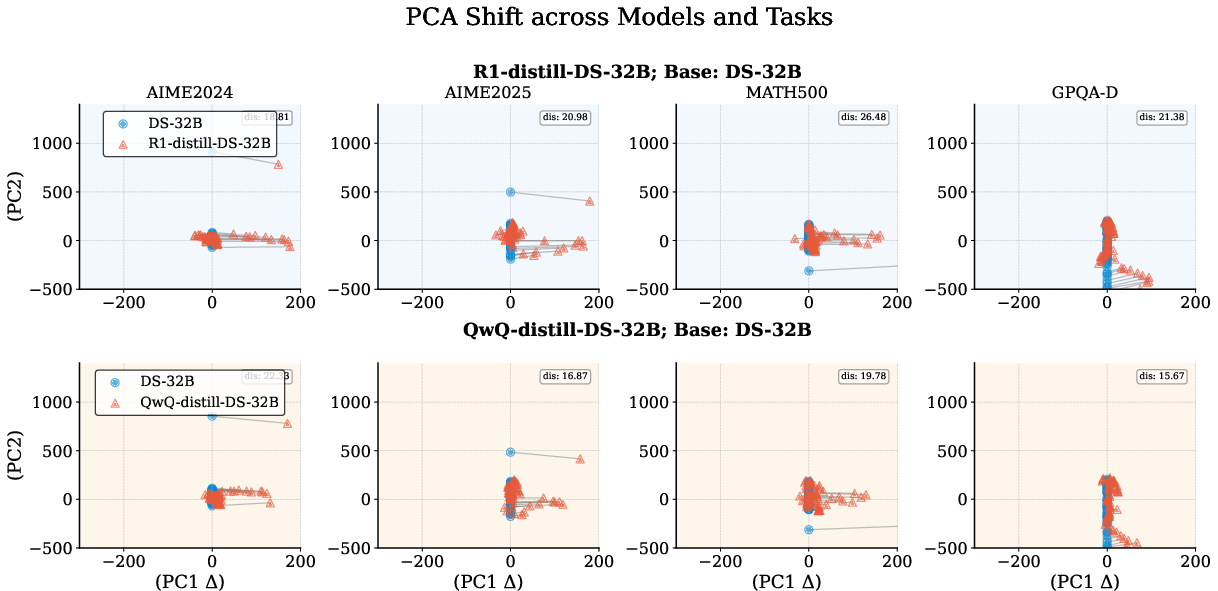
Figure 4: PCA offset of DS-32B across various teacher models and tasks. dis represents the Euclidean distance between the centroids of latent representations before and after training. Models trained on the QwQ-32B corpus exhibit smaller PCA offsets than DeepSeek-R1 across most tasks, indicating greater stability in their latent representations.
PCA shift analysis demonstrates that DED-trained models exhibit smaller latent representation shifts, particularly when distilled from QwQ-32B. This stability is associated with superior generalization and robustness, supporting the hypothesis that corpus affinity and representational consistency are key to effective distillation.
Implications and Future Directions
The DED framework provides a principled approach to efficient reasoning distillation, emphasizing teacher selection, data quality, and trajectory diversity over brute-force scaling. The findings challenge several prevailing assumptions:
- Scaling Law Limitations: High reasoning performance can be achieved with minimal, well-curated data, breaking the traditional scaling law.
- Teacher Model Selection: Benchmark performance is not a sufficient criterion for teacher selection; token entropy and corpus affinity are more predictive.
- Corpus Construction: Quality and diversity of reasoning traces are more important than length or superficial difficulty metrics.
Practically, DED enables the development of compact, high-performing reasoning models suitable for resource-constrained environments and rapid domain adaptation. Theoretically, it motivates further research into the interplay between token entropy, latent representation dynamics, and generalization in LLMs.
Conclusion
The DED framework represents a significant advance in data-efficient reasoning distillation, achieving SOTA results with a fraction of the data and compute previously considered necessary. By systematically analyzing and optimizing teacher selection, corpus curation, and trajectory diversity, DED demonstrates that the scaling law is not a fundamental barrier to reasoning performance. Future work should extend DED to broader domains, investigate its interpretability, and further elucidate the mechanisms underlying efficient knowledge transfer in LLMs.

