- The paper demonstrates that prolonged RL training enhances LLM reasoning by leveraging diverse tasks with verifiable rewards.
- It employs advanced GRPO techniques, including decoupled clipping and controlled KL regularization, to balance exploration and exploitation.
- Experiments reveal performance gains of up to 54.8% on logic puzzles, highlighting robust scalability and improved generalization.
Essay: "Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training"
Introduction
This paper addresses the enhancement of reasoning capabilities in LLMs through sustained reinforcement learning (RL) training, focusing on unlocking diverse reasoning across various domains such as mathematics, coding, and logical puzzles. The authors introduce a new RL framework incorporating modifications to Group Relative Policy Optimization (GRPO) and highlight the importance of verifiable reward signals and diverse training datasets. The study demonstrates significant performance improvements over existing strong baselines, positioning the proposed framework as a robust approach for reasoning-intensive tasks.
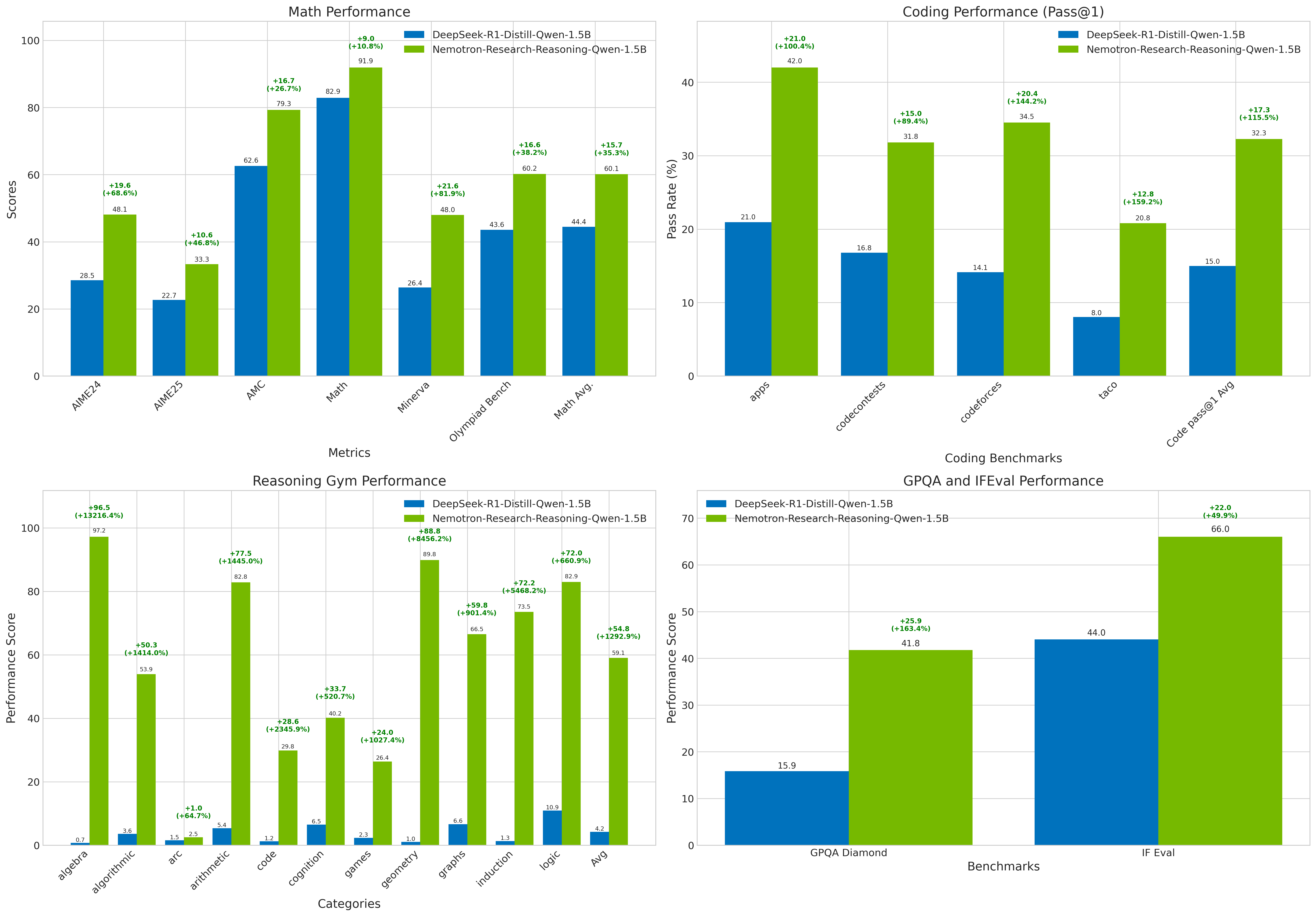
Figure 1: Performance comparison between DeepSeek-R1-Distill-Qwen-1.5B and Nemotron-Research-Reasoning-Qwen-1.5B across multiple benchmarks.
Diverse Training Data
The core of the training methodology involves leveraging a wide range of tasks with clear, verifiable rewards. This data diversity ensures that the model learns robust decision-making strategies across disparate environments, enhancing generalization. Key domains include mathematics, coding, STEM, logical puzzles, and instruction following. Each domain provides distinct correctness criteria, which are critical for evaluating and improving the reasoning ability of the model.
Reinforcement Learning Framework
The paper utilizes Group Relative Policy Optimization (GRPO) and introduces several enhancements inspired by DAPO, such as decoupled clipping and dynamic sampling. These innovations aim to maintain exploration by controlling entropy and leveraging diverse training experiences. One of the critical techniques discussed is controlled KL regularization, employed to manage the balance between exploration and exploitation effectively. Additionally, the paper suggests periodic reference policy resets to mitigate performance plateaus, thus enabling continuous model improvement throughout prolonged training.
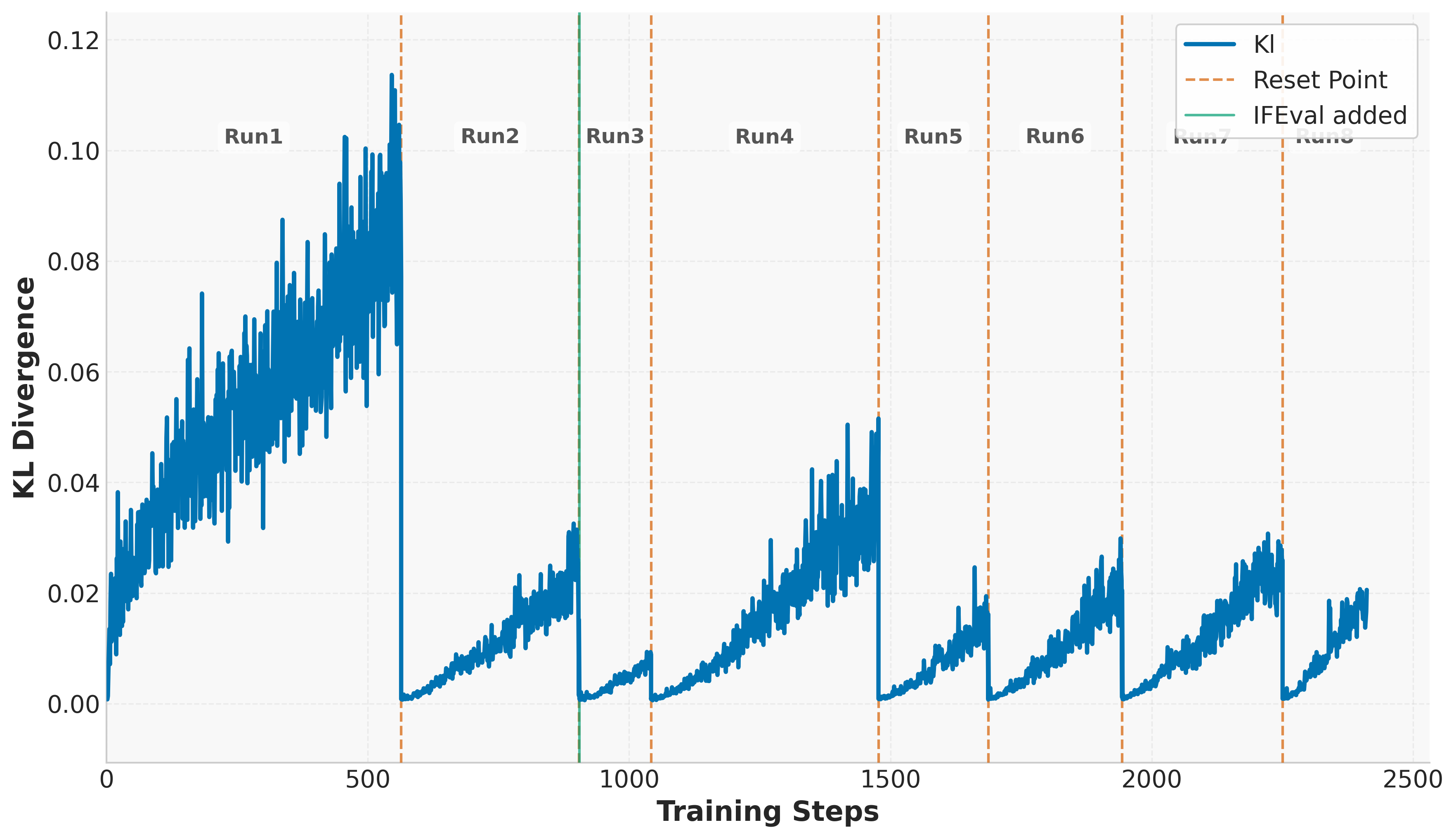
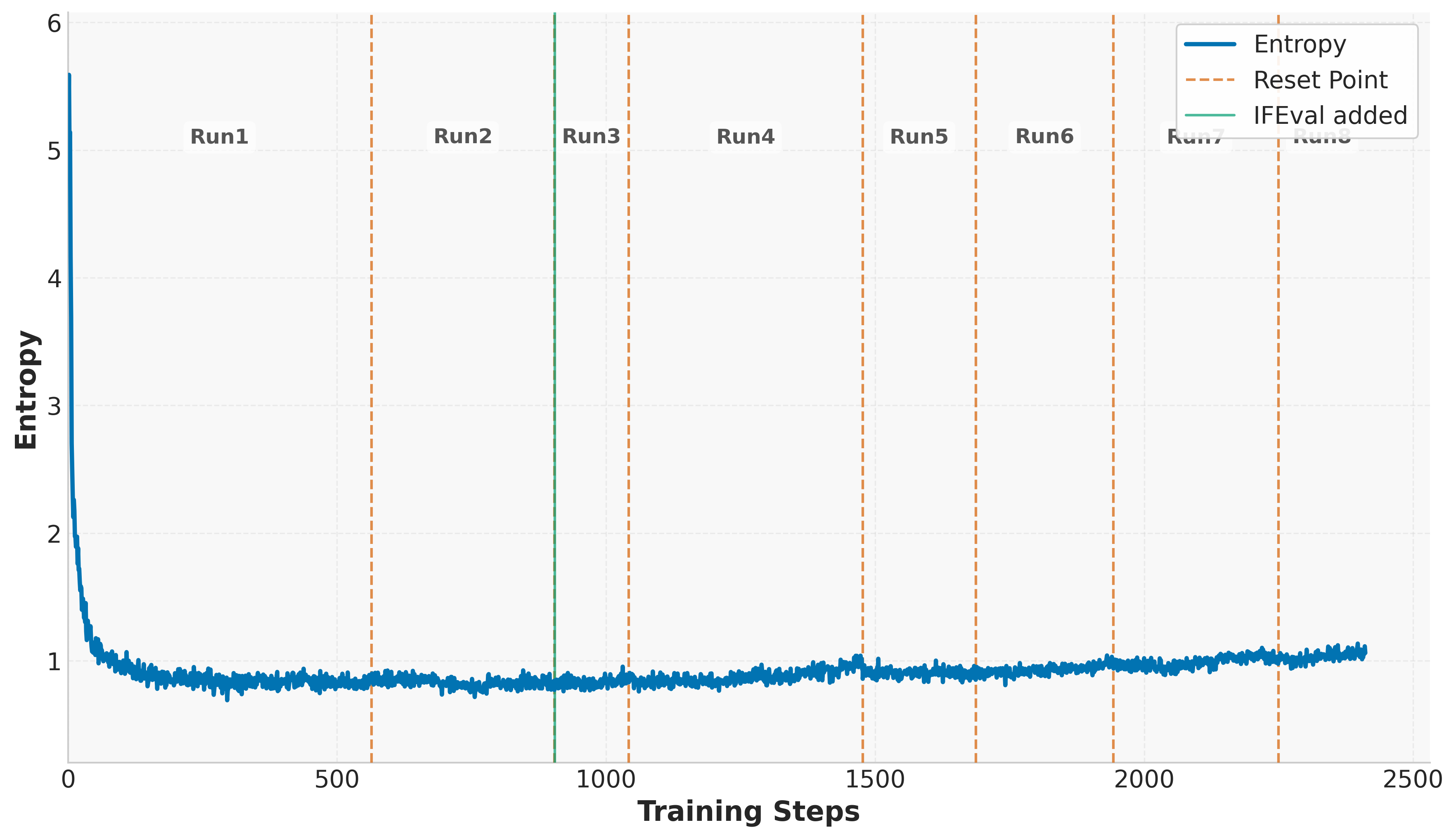
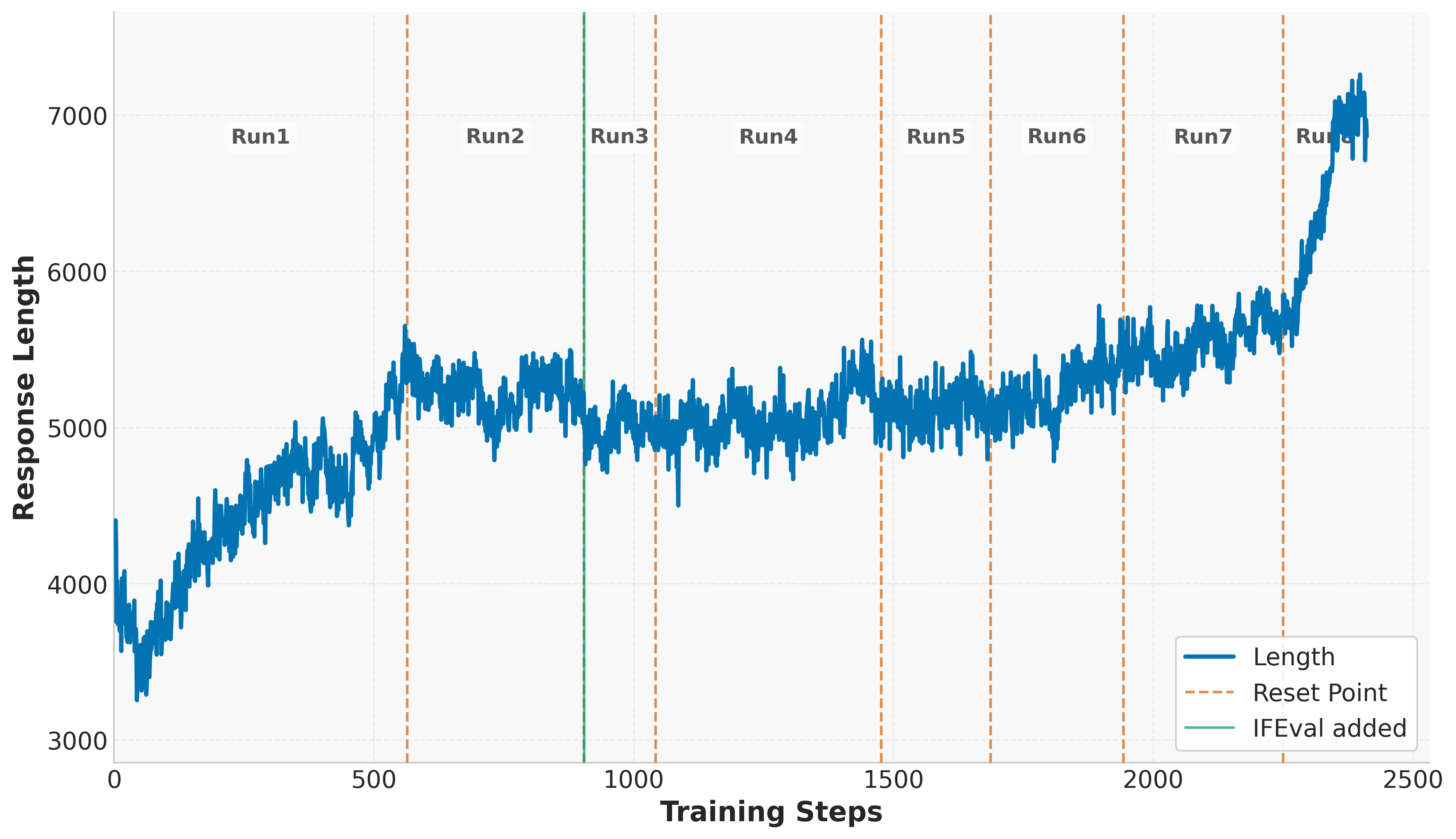
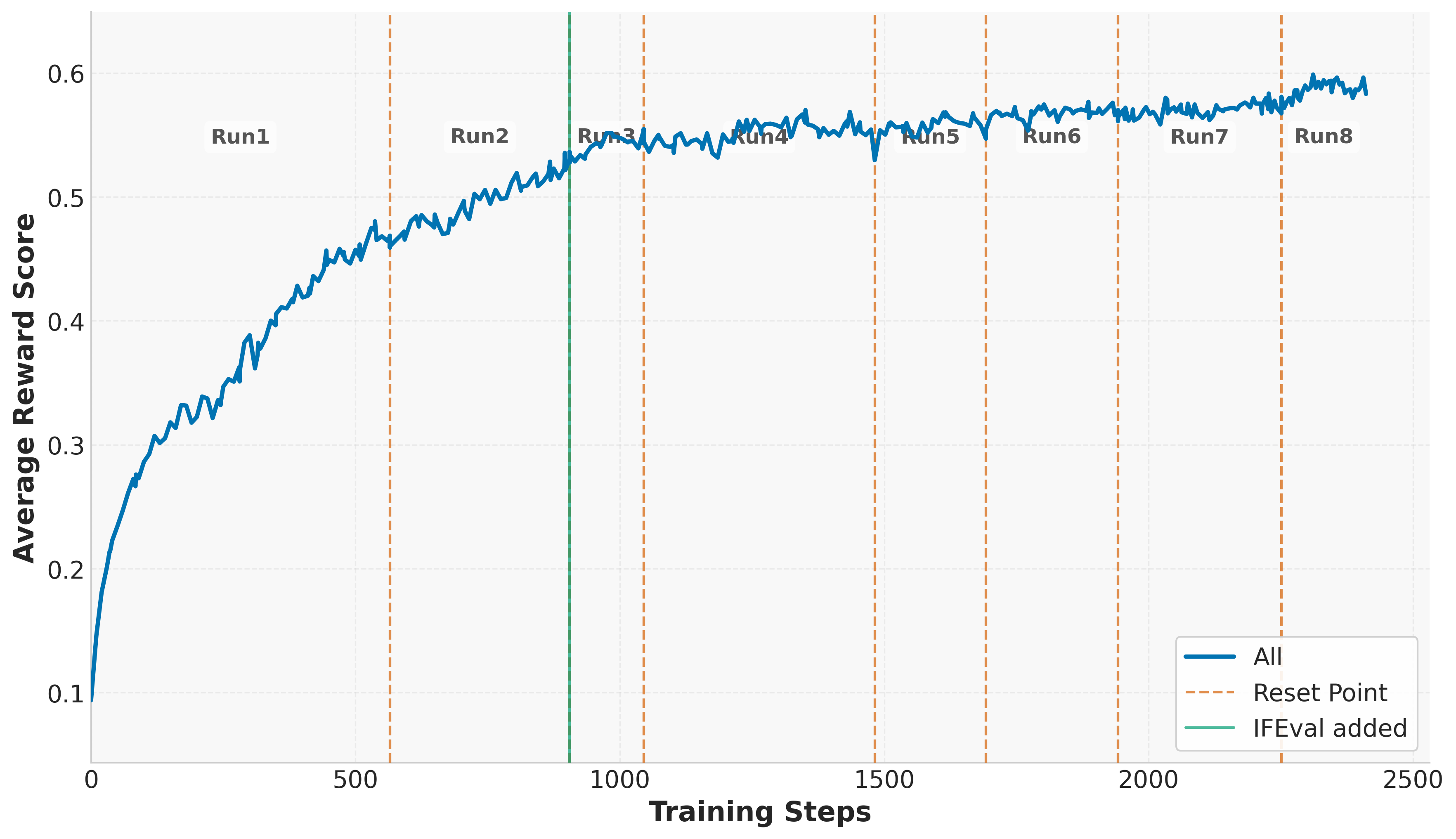
Figure 2: KL divergence.
Implementation Details
The implementation involves a sandboxed reward server architecture to handle the complexity and security requirements of diverse tasks. This architecture facilitates tailored execution environments without affecting the core training processes. By distributing reward evaluations across clusters, the paper ensures high throughput and efficient management of computational resources, supporting the scalable deployment of reinforcement learning strategies.
Experiment Results
Numerical results highlight significant improvements across several reasoning tasks, with increases of up to 54.8% on logic puzzles, 14.7% on mathematics, and 13.9% on coding tasks as compared to existing baselines. Evaluation on a robust validation set shows that the proposed model, Nemotron-Research-Reasoning-Qwen-1.5B, not only outperforms its predecessors but also maintains competitive performance even when juxtaposed with domain-specialized models like DeepScaleR-1.5B and DeepCoder-1.5B.
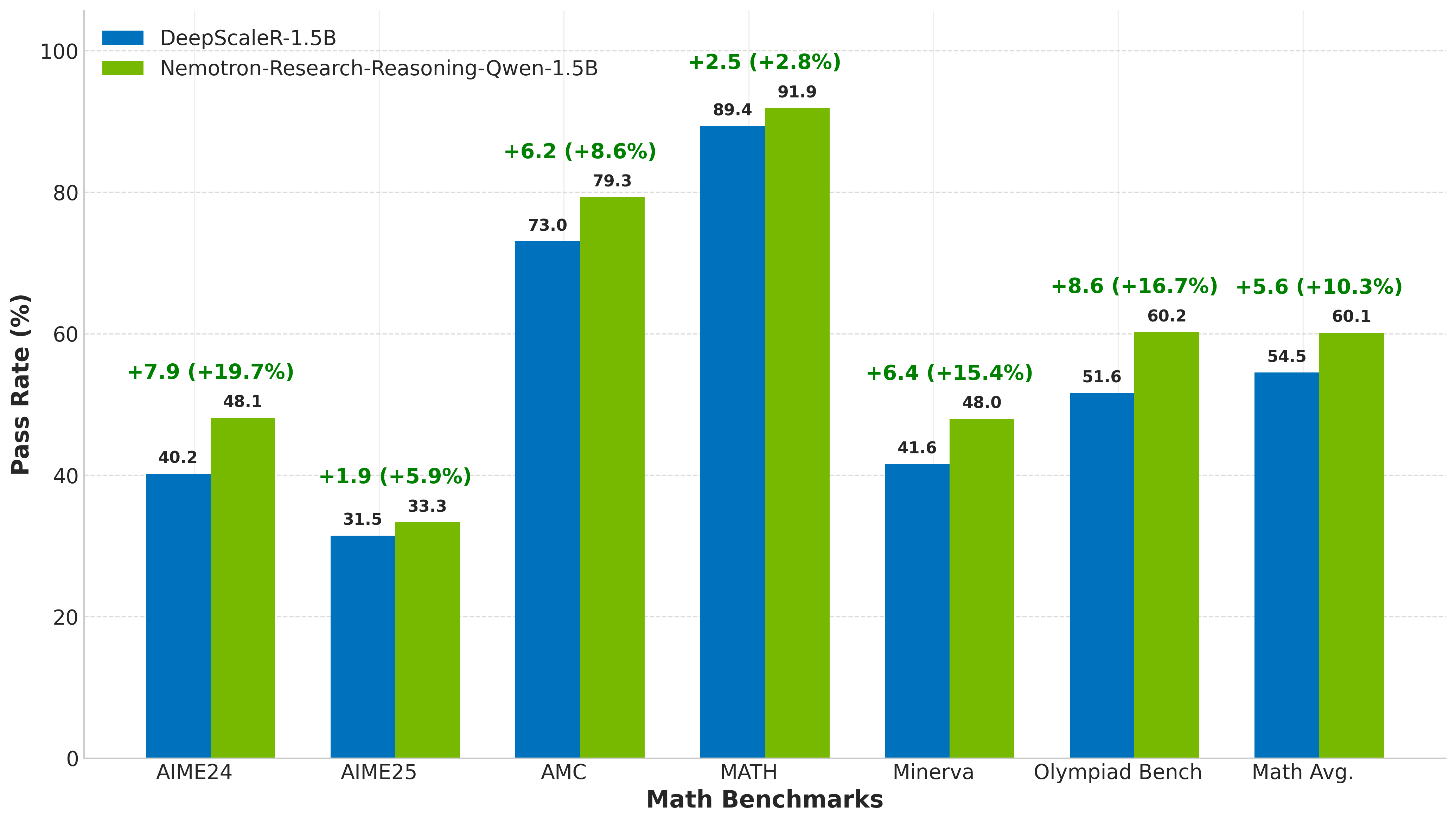
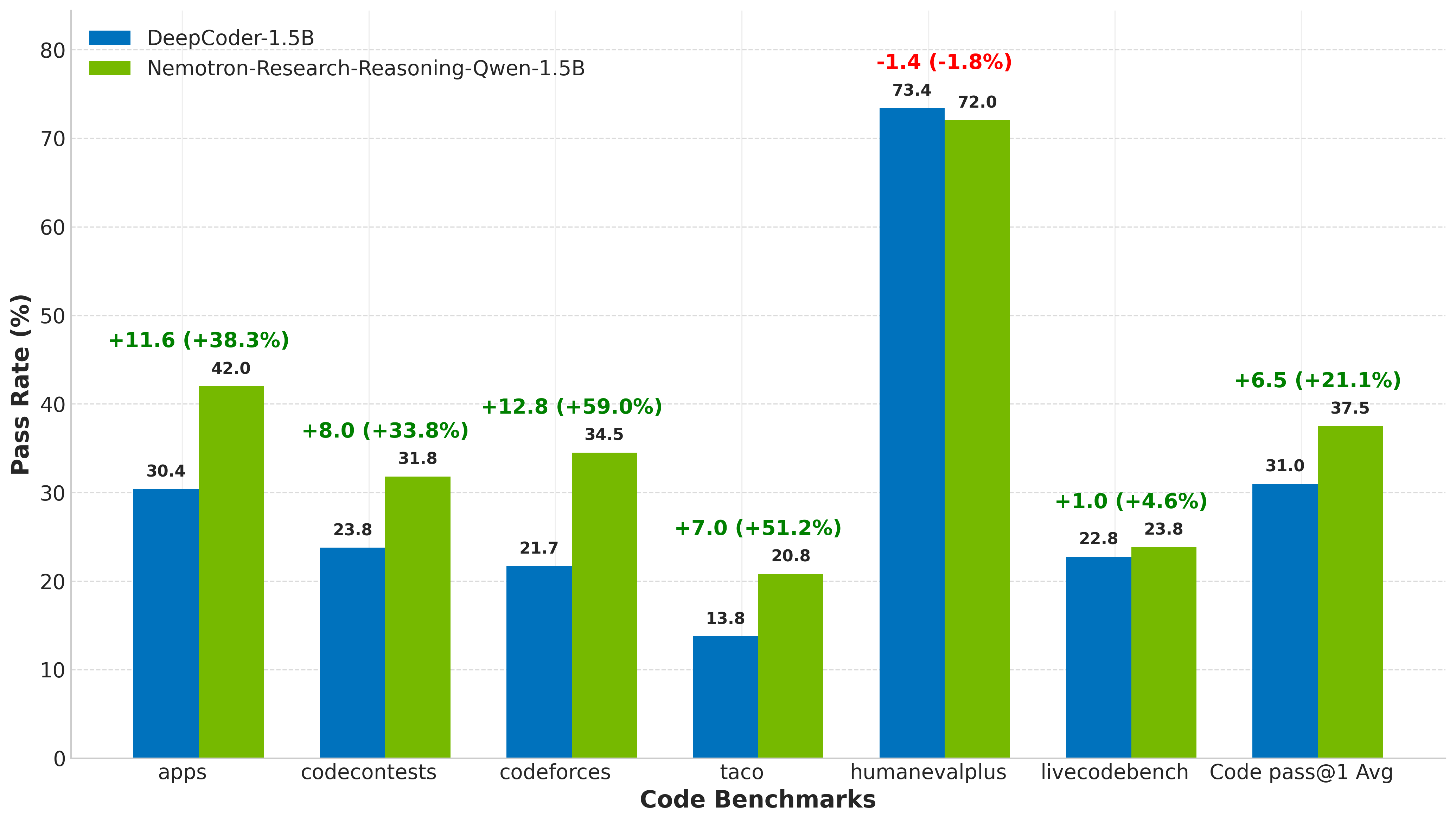
Figure 3: Comparision with DeepScaleR-1.5B~\cite{deepscaler2025}.
Ablation Studies
Ablation studies conducted address the impact of different model components and configurations. The analysis of temperature sampling reveals that higher temperatures promote exploration, thereby sustaining learning over extended durations. The proactive resetting of reference policies emerges as a critical factor in maintaining model stability and preventing stagnation.
Conclusion
Through careful design and sustained reinforcement learning, the study showcases substantial gains in reasoning capabilities of LLMs. By open-sourcing the Nemotron-Research-Reasoning-Qwen-1.5B model, the paper contributes valuable insights and resources to the broader research community, potentially advancing further studies in model alignment, optimization, and reasoning across limited computational demands. These findings underscore the transformative potential of prolonged training strategies in enhancing the intellectual capabilities of LLMs across diverse domains.

