Collaborative Document Editing with Multiple Users and AI Agents
Abstract: Current AI writing support tools are largely designed for individuals, complicating collaboration when co-writers must leave the shared workspace to use AI and then communicate and reintegrate results. We propose integrating AI agents directly into collaborative writing environments. Our prototype makes AI use transparent and customisable through two new shared objects: agent profiles and tasks. Agent responses appear in the familiar comment feature. In a user study (N=30), 14 teams worked on writing projects during one week. Interaction logs and interviews show that teams incorporated agents into existing norms of authorship, control, and coordination, rather than treating them as team members. Agent profiles were viewed as personal territory, while created agents and outputs became shared resources. We discuss implications for team-based AI interaction, highlighting opportunities and boundaries for treating AI as a shared resource in collaborative work.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Short overview
This paper is about making it easier for groups of people to write together with help from AI, without leaving their shared document. The authors built a prototype (a special version of a Google Docs–style editor) where “AI agents” live inside the document. These agents can be customized, given tasks, and they leave their suggestions as comments, so everyone can see and discuss them.
What questions did the researchers ask?
- How do people in a team create and set up AI helpers (agents) when they’re writing together?
- How do they actually work with those shared AI agents while co-writing?
How did they study it?
The tool they built
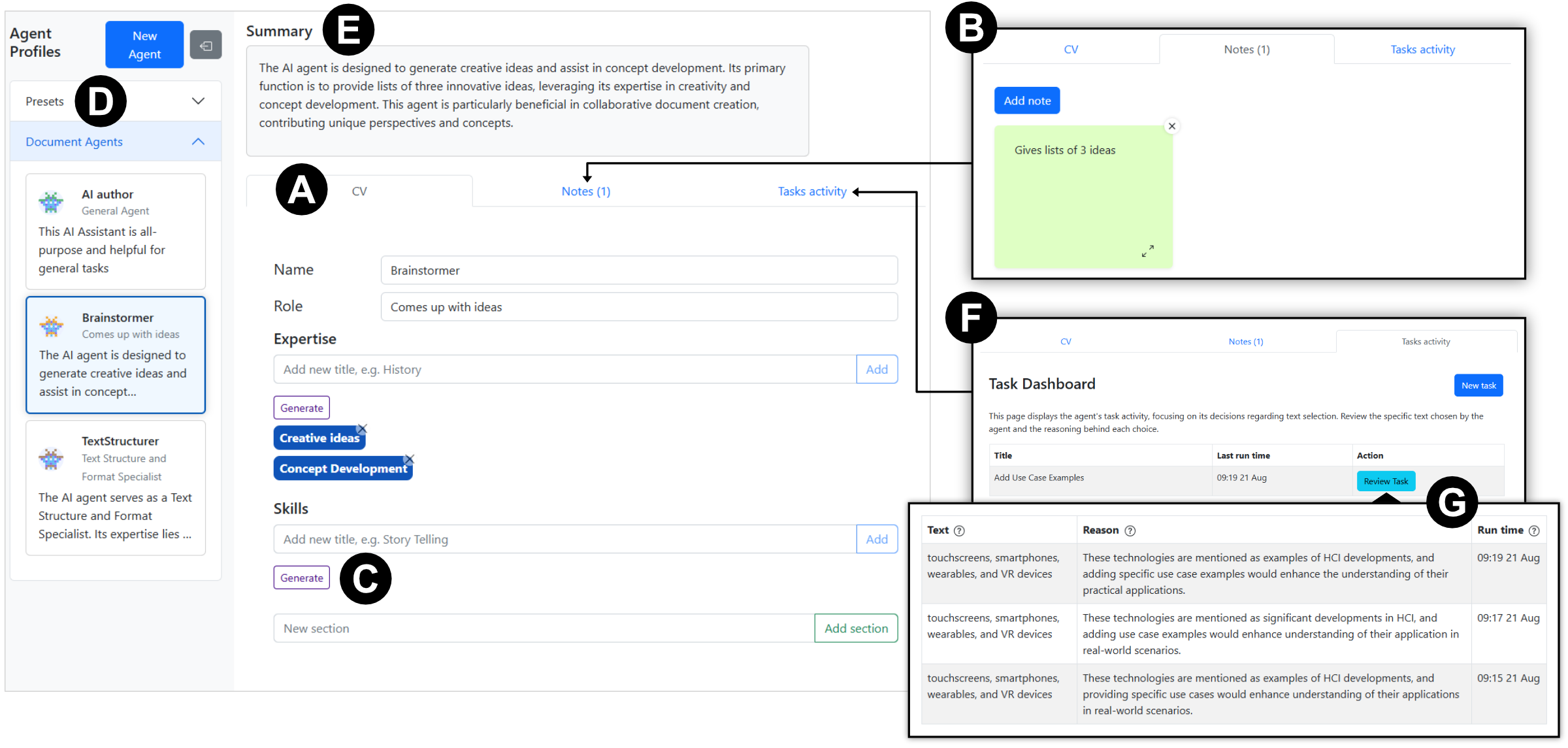
Think of AI agents as smart, customizable helpers inside a shared doc. The tool has three big ideas:
- Agent profiles: Each agent has a profile (like a mini CV) with a name, role, skills, and notes. This helps teams create different helpers, like a “Brainstormer,” a “Reviewer,” or an “English coach.”
- Tasks: There’s a shared to-do list for the AI. A task is a clear instruction like “Suggest examples for section 2” or “Summarize this paragraph.” Tasks can be run by a person (manually) or automatically at certain times (for example, after the document is saved or when everyone logs off).
- Comments: Agents never change the text directly. Instead, they answer inside comment threads. People can then choose to “Append” (add) or “Replace” text and must approve the change. This keeps humans in control and makes AI help visible to everyone.
In everyday terms: profiles = who the helper is, tasks = what the helper should do, comments = where the helper speaks up.
The study with people
- 30 participants worked in 14 teams for one week.
- They used the prototype to work on a real or practice writing task.
- The researchers collected:
- Interaction logs (what features people used and when)
- Surveys about usability and creativity support
- Group interviews about what worked, what didn’t, and how teams felt using the agents
What did they find?
Here are the main takeaways, explained simply:
- Teams saw agents as tools, not teammates. People treated AI like a shared resource they could use and direct—not like another person in the group.
- Setting up agents felt personal; using them felt shared. The person who created an agent often edited its profile, like it was their “territory.” But once an agent existed, everyone used its output as a shared resource.
- One helper vs. many helpers was a real choice. Some teams liked a single, general-purpose agent because it was faster and simpler. Others preferred multiple specialized agents (like “Grammar Guru,” “Structure Coach,” “Idea Generator”) to get diverse feedback—and to save prompting effort later.
- Keeping humans in charge matters. Because AI only suggested changes in comments and never edited the document directly, teams stayed comfortable and in control. People could review, discuss, and approve changes.
- The familiar comment system made AI help feel natural. Seeing AI replies in the same place as human comments fit well with how teams already work.
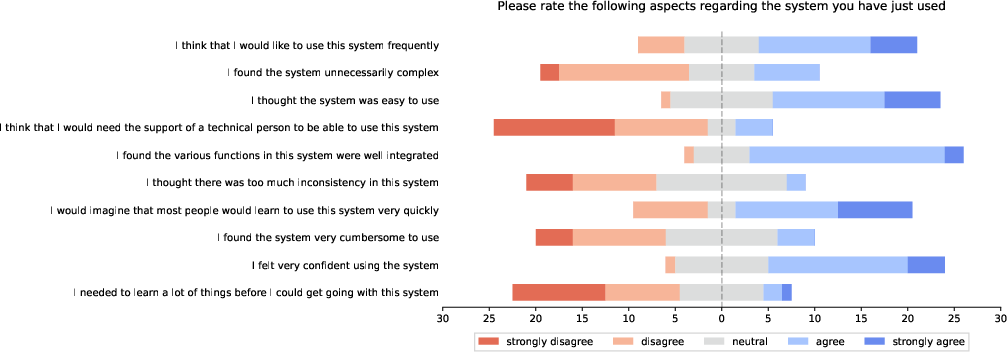
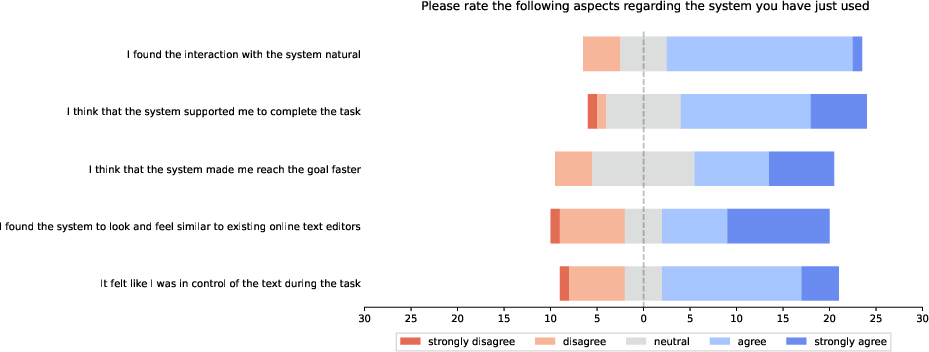
- The tool was useful but still early. People generally felt it helped them work more efficiently and was enjoyable, but some still felt a bit out of control at times. Overall usability scores were near average for new tools.
A few light numbers to give you a sense of scale:
- Teams created around 40 custom agents in total.
- Most agent setups used the structured “CV” fields (role, skills) rather than free-form notes.
- Teams created about 70 reusable tasks.
- There were many comments overall; most were AI suggestions added by running tasks, and short human–AI exchanges were common.
Why does this matter?
This research shows a practical way to bring AI into the place where collaboration already happens: the shared document. It suggests some design rules for team writing with AI:
- Make AI help public and reviewable. Put AI responses in comments, not direct edits, so teams can discuss and approve changes.
- Let people customize helpers but keep them visible to everyone. Profiles feel personal, outputs are shared.
- Support both quick help and deeper structure. Provide a default general agent plus ways to create specialized agents and repeatable tasks.
- Offer both manual and automatic timing. Sometimes a human should trigger a task; other times it’s handy if AI runs after saves or when people are offline.
In the long run, tools like this could reduce the friction of switching between chatbots and documents, help teams coordinate who does what, and keep AI as a transparent, shared helper. It won’t replace teamwork—instead, it can make teamwork smoother by giving everyone clear, controllable AI support right where they work together.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The points below identify what remains missing, uncertain, or unexplored in the paper and prototype, framed to guide actionable future research.
- External validity and sampling
- Generalizability beyond small academic teams: participants were largely university-affiliated and frequent LLM users; effects in industry, non-academic, or low-LLM-literacy teams remain unknown.
- Short deployment (one week): lacks evidence on long-term adoption, evolving practices, sustainability, and drift in team norms or agent usage.
- Task heterogeneity: allowing “own task” vs. provided essay introduces confounds; controlled comparisons across task types and difficulty are missing.
- Evaluation design and outcome measures
- No baseline/control condition: lacks comparison to standard collaborative editors with external AI use (e.g., separate ChatGPT tab), making it unclear what the integrated design actually improves.
- Absent quality metrics: no objective measures of writing quality, correctness, originality, readability, or audience impact; no expert blind ratings or rubric-based evaluation.
- Unknown productivity effects: no time-on-task, throughput, or revision efficiency metrics (e.g., number of accepted suggestions per hour).
- Acceptance and editing behavior: acceptance rates of AI suggestions, degree of human edits prior to approval, and predictors of acceptance (e.g., agent type, task type, location in text) were not analyzed.
- Costs vs. benefits of autonomy: no quantitative assessment of comment/thread clutter, interruption cost, or cognitive load induced by autonomous tasks.
- Feature-level uncertainties
- Ownership and permissions for agents: while agent profiles were treated as personal territory, the system offers no explicit ownership, privacy, or permission model (e.g., private vs shared agents, locking, versioning). Effects of such controls on collaboration and conflict are unknown.
- Agent multiplicity vs. single generalist: the trade-offs between one flexible agent and several role-specific agents are not systematically tested (e.g., setup cost, prompt reuse benefits, diversity of perspectives, error rates).
- Trigger design for autonomous tasks: trigger choices (idle time, saves, “collaborative edits,” etc.) were elicited but not evaluated for appropriateness, false positives/negatives, or user trust. Optimal thresholds, personalization, and interruptibility policies remain open.
- Comment-channel fit: agents only propose through comments, never direct edits. When (if ever) should direct edits be allowed, and which safeguards (e.g., gated auto-accept, constrained scopes) minimize social friction without adding overhead?
- Ad-hoc vs. reusable tasks: relative value of comment-summoned ad-hoc tasks vs. curated task-list shortcuts is unclear; how to surface, organize, and retire task templates over time is unexplored.
- Scrutability aids: the utility of agent task histories, rationales, and side-by-side diffs for trust and error detection was not measured; which transparency features truly help teams?
- Model, safety, and robustness considerations
- Model dependence: only one model (gpt-4o-mini) was used; effects of model quality, latency, cost, and provider policies on collaboration dynamics are unknown.
- Prompt injection and adversarial text: multi-author documents are vulnerable to embedded instructions; no defenses, detection, or sanitization strategies were evaluated.
- Hallucinations and bias: no measurement of factuality, citation integrity, bias amplification, or style homogenization; impact on group decision quality is unknown.
- Auto-assignee reliability: the 85% confidence threshold for auto selection was not validated; misassignment rates and downstream effects are unreported.
- Scalability and performance: behavior with large documents, many concurrent users, or many autonomous tasks (comment flooding, latency spikes, rate limits, cost control) was not tested.
- Collaboration dynamics and social factors
- Team roles and power dynamics: how agent-mediated suggestions interact with unequal expertise, seniority, or authorship credit remains unexamined.
- Accountability and provenance: the system merges accepted AI text without persistent, fine-grained provenance; how to attribute contributions and ensure accountability over time is open.
- Norms for AI involvement: guidelines for disclosure, crediting AI, and editorial responsibility in co-authorship are not addressed.
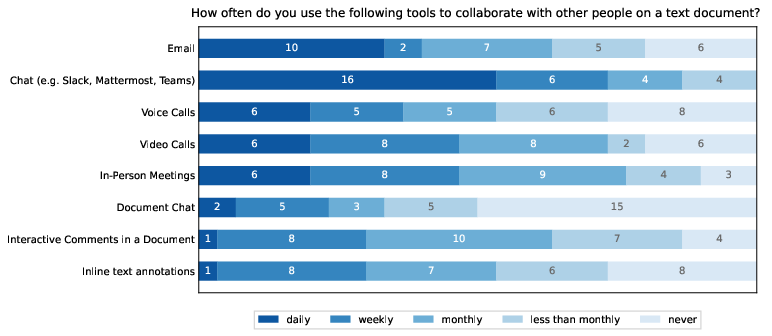
- Cross-tool ecologies: many groups used external chat tools; how integrated agents should interoperate with chat, issue trackers, or reference managers remains unexplored.
- Learnability and onboarding
- Training needs: after early feedback, an intro session was added, suggesting nontrivial learning costs. Optimal onboarding flows and their impact on outcomes were not studied.
- Novice vs. expert differences: the paper does not analyze how prior LLM experience modulates benefits, errors, or reliance patterns.
- Domain and language coverage
- Beyond academic prose: utility for journalism, policy writing, legal drafting, technical docs, grant proposals, or mixed media content (figures, tables) is unknown.
- Multilingual and accessibility support: effectiveness for non-English text, code-switching, and accessibility needs (screen readers, keyboard-only workflows) is untested.
- Governance, policy, and ethics
- Data governance and privacy: risks of sending sensitive document content to external LLMs and remedies (on-prem models, redaction, DLP) are not addressed.
- IP and licensing: implications for ownership of AI-generated text and compliance with publisher/organizational policies are not discussed.
- Anthropomorphism and trust calibration: how agent persona cues influence over-trust, under-trust, or misuse remains an open design question.
- Design space extensions and alternatives
- Permissioned territories: mechanisms that align with perceived territoriality (e.g., private agents, team-owned agents, sub-team scoping) and their effects need study.
- Agent learning from team feedback: whether agents should adapt to team norms via ratings, corrections, or RLHF-like signals, and how to avoid unwanted drift.
- Multi-agent coordination: systematic exploration of agent–agent “conversations,” conflict resolution policies, and orchestration strategies is missing.
- Richer integrations: applying the paradigm to other collaborative media (slides, spreadsheets, code), citations management, or structured editing workflows is open.
- Methodological improvements for future work
- Controlled manipulations: systematically vary number of agents, autonomy levels, trigger policies, and permission models to identify causal effects.
- Mixed-methods rigor: complement qualitative insights with inferential statistics on behavior logs and pre-registered hypotheses.
- Release artifacts: code, prompts, and datasets were not indicated as shared; lack of artifacts limits replication and extension.
Collections
Sign up for free to add this paper to one or more collections.

