- The paper introduces MALLM, a novel framework using multi-agent LLMs and distinct discussion paradigms to improve complex reasoning tasks over traditional Chain-of-Thought approaches.
- It evaluates various discussion paradigms, showing that strategies like the report paradigm quickly achieve consensus while expert personas boost performance in complex tasks.
- The experiments indicate that multi-agent systems excel in strategic and ethical QA tasks, although challenges such as problem drift in basic tasks require further refinement.
Multi-Agent LLMs for Conversational Task-Solving
This paper presents an exploration into the emerging domain of Multi-Agent Systems (MAS) using LLMs for conversational problem-solving tasks. The research systematically evaluates the capabilities and limitations of multi-agent discussions across a variety of tasks and introduces a novel framework, MALLM, for deploying Multi-Agent LLMs.
Overview
Multi-Agent Systems have emerged as compelling frameworks in artificial intelligence, especially with LLMs contributing to tasks involving complex reasoning and creativity. This research builds upon that premise by extending prior work to cover conversational task-solving. It aims to fill the existing research gap by systematically evaluating multi-agent systems across different tasks, discussion paradigms, and formats.
Methodology
The study introduces MALLM, a flexible framework designed for MAS in conversational contexts. MALLM facilitates the study of different agent roles, discussion paradigms, and decision-making protocols. It allows for intricate studies on various characteristics of multi-agent conversations, such as convergence to consensus, length of discussions, and impact of individual agent personas.
Key Components:
- Agents: LLMs forming multiple instances, each embodying distinct personas with potentially varying expertise.
- Discussion Paradigms: Structural communication schemes that define how agents interact (e.g., memory, relay, report, debate paradigms).
- Decision-Making: Consensus-driven decision protocols developed to guide discussions to final solutions.
Experimental Setup
The experiments evaluate the performance of four paradigms—memory, report, relay, and debate—against a single LLM baseline with Chain-of-Thought (CoT) prompting. The tasks range from basic generative and QA tasks (e.g., summarization, translation) to more complex reasoning tasks (e.g., strategic and ethical QA). Each paradigm's impact on the task performance is meticulously analyzed, leveraging various prompts and experimental parameters to ensure robustness.
Results and Analysis
- Task Performance: Multi-agent systems showed significant performance improvements in complex tasks (e.g., strategic QA), leveraging sophisticated reasoning paradigms over a single LLM's CoT prompting. However, they underperformed in basic tasks like translation due to problem drift—a concept introduced to describe performance loss over extended discussion times.
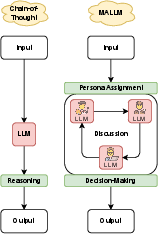
Figure 1: A superficial view on MALLM: Multi-Agent LLMs, compared with Chain-of-Thought for a single model.
- Discussion Patterns: Most discussions converged within a few turns, indicating high agreement among agents, but revealed that some paradigms (like report) might achieve quicker consensus due to centralized information structures.
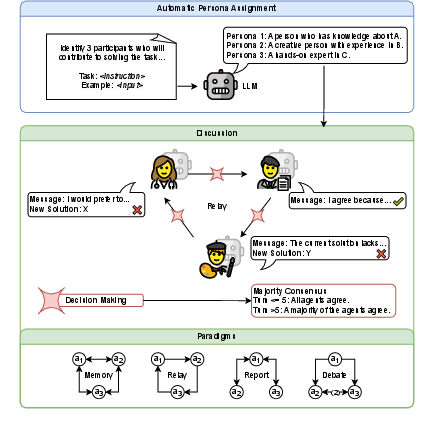
Figure 2: Functionality of MALLM applied to my experiments. First, MALLM automatically determines three personas. Each persona then contributes to multi-agent discussion under one of four paradigms.
- Individual Agent Influence: Agents embodying expert personas had a substantial impact on complex tasks, demonstrating increased task performance and lexical diversity in outputs. Conversely, these personas could complicate simpler tasks, indicating a need for task-specific persona deployment.
Implications and Future Work
The research uncovers critical insights into the strengths and limitations of multi-agent LLMs, suggesting that while they excel in complex reasoning and ethical tasks, they falter in basic, deterministic tasks. This dichotomy indicates further exploration into task-specific paradigms and better role assignments could refine MAS efficacy. Investigations into alignment collapse and response length equality are suggested as potential future research topics given their impact on ethical and balanced AI outputs.
Conclusion
The study positions MALLM as a versatile framework to advance MAS research, shedding light on how multi-agent LLMs can be harnessed to solve conversational tasks effectively. It delineates the boundaries between where multi-agent architectures outperform single models and where further innovation is essential.
This comprehensive exploration sets a foundation for designing more efficient, ethically aligned, and performance-optimized multi-agent LLM systems for diverse application areas in AI.

