- The paper’s main contribution is revealing that token-level probability outputs in LLMs consistently diverge from theoretical expectations in controlled probabilistic scenarios.
- It employs experiments with GPT-4.1 and DeepSeek-Chat, using classical prompts like die rolls and coin flips to assess alignment and entropy values.
- Findings imply that standard uncertainty quantification may mislead applications, urging the development of refined methods for strict statistical alignment.
Differentiating Certainty from Probability in LLM Token Outputs
LLMs have become integral in decision-support and knowledge-intensive applications where uncertainty quantification (UQ) is critical. This study examines the alignment between model certainties—derived from token logits—and theoretical probability distributions in well-defined probabilistic scenarios, employing GPT-4.1 and DeepSeek-Chat to assess their ability to align output probabilities with theoretical expectations.
Uncertainty Quantification in Probabilistic Scenarios
UQ aims to measure confidence in model outputs through derived probabilities and entropy values. However, in probabilistic tasks, such as predicting outcomes of random events, accuracy should also reflect alignment with theoretical probability distributions. This paper evaluates two dimensions of LLM responses: validity concerning scenario constraints and alignment with theoretical outcomes.
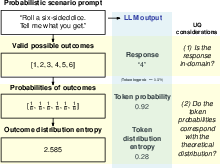
Figure 1: Probabilistic scenario prompting and response evaluation design.
Our hypothesis is that token-level certainty should correspond with theoretically expected distributions, an assertion not typically addressed by conventional UQ methods designed for natural language generation tasks.
Methodology and Experiments
Using 10 prompts based on classical probabilistic scenarios, we assessed LLM responses regarding their probability alignment and entropy in tasks such as "rolling a die" or "flipping a coin". The models were queried in both specified and unspecified contexts to evaluate changes in output certainty.
Prompts were designed to ensure LLMs provided only the outcome, thereby isolating token probability evaluations. Responses were closely examined against expected probabilities and entropies to determine alignment.
Key Findings
Both GPT-4.1 and DeepSeek-Chat correctly understood and adhered to the probabilistic scenario constraints, achieving 100% valid response accuracy. However, their token-level probabilities consistently diverged from theoretical expectations across all scenarios. Explicit prompts specifying probabilistic behavior improved alignment somewhat, but disparities persisted, with entropy values notably higher than theoretical expectations.
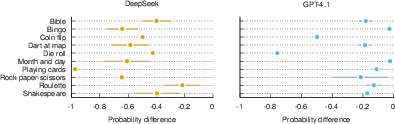

Figure 2: Difference between the selected token's probability and its theoretical value. The error bars show 1 SEM.
These results indicate that reliance on standard UQ measures might be misleading for tasks requiring consistency with statistically derived probabilities.
Discussion: Implications and Future Research
This analysis raises concerns about using current LLMs in probability-driven tasks requiring precise statistical alignment. The research questions the efficacy of LLMs in environments necessitating calibrated probabilistic outputs, casting doubt on their suitability without additional refinement or calibration.
(Figures 3 and 4 provide qualitative insight into how both models articulate their understanding of probability but fail to reflect it quantitatively in their token probabilities.)

Figure 3: DeepSeek-Chat example dialogue for probabilistic reasoning about prompt scenarios.

Figure 4: GPT-4.1 example dialogue for probabilistic reasoning about prompt scenarios.
Future work should focus on developing UQ methods that factor in distributional alignment to ensure that LLM outputs are not only valid within scenario constraints but also reflect the statistical nature of the task. This could enhance model utility in applications where probabilistic reasoning is critical, like automated testing or simulation.
Conclusion
While LLMs exhibit high response certainty and understanding of scenario constraints, their outputs show significant divergence from expected statistical distributions. These discrepancies highlight a critical gap in the probabilistic calibration of LLM outputs that needs addressing for tasks demanding strict adherence to theoretical models. Addressing these gaps with refined UQ methods could improve their robustness and applicability in decision-support systems dependent on statistical accuracy.

