- The paper presents LogTokU, a novel method that estimates token-level uncertainty by using logits as evidence instead of traditional probability measures.
- It employs a Dirichlet distribution to decouple aleatoric and epistemic uncertainties, categorizing performance into four distinct quadrants.
- It enhances reliability in LLM outputs by enabling dynamic decoding strategies for improved accuracy in real-world applications.
Estimating LLM Uncertainty with Evidence
Introduction
The paper "Estimating LLM Uncertainty with Evidence" (2502.00290) addresses a critical challenge in the deployment and reliability of LLMs: their tendency to produce hallucinations, especially when these models encounter queries that exceed their training knowledge scope. The authors propose an innovative method called Logits-induced Token Uncertainty (LogTokU) to estimate token-level uncertainty more accurately, thereby enhancing the reliability of LLM outputs in real-time applications.
Why Probability-based Methods Fail
Traditional uncertainty estimation methods that rely on probability measures often misinterpret the nuances of LLM reliability. These methods fall short because they do not account for the reason behind low probability estimates—whether they are due to multiple correct answers or actual model uncertainty.
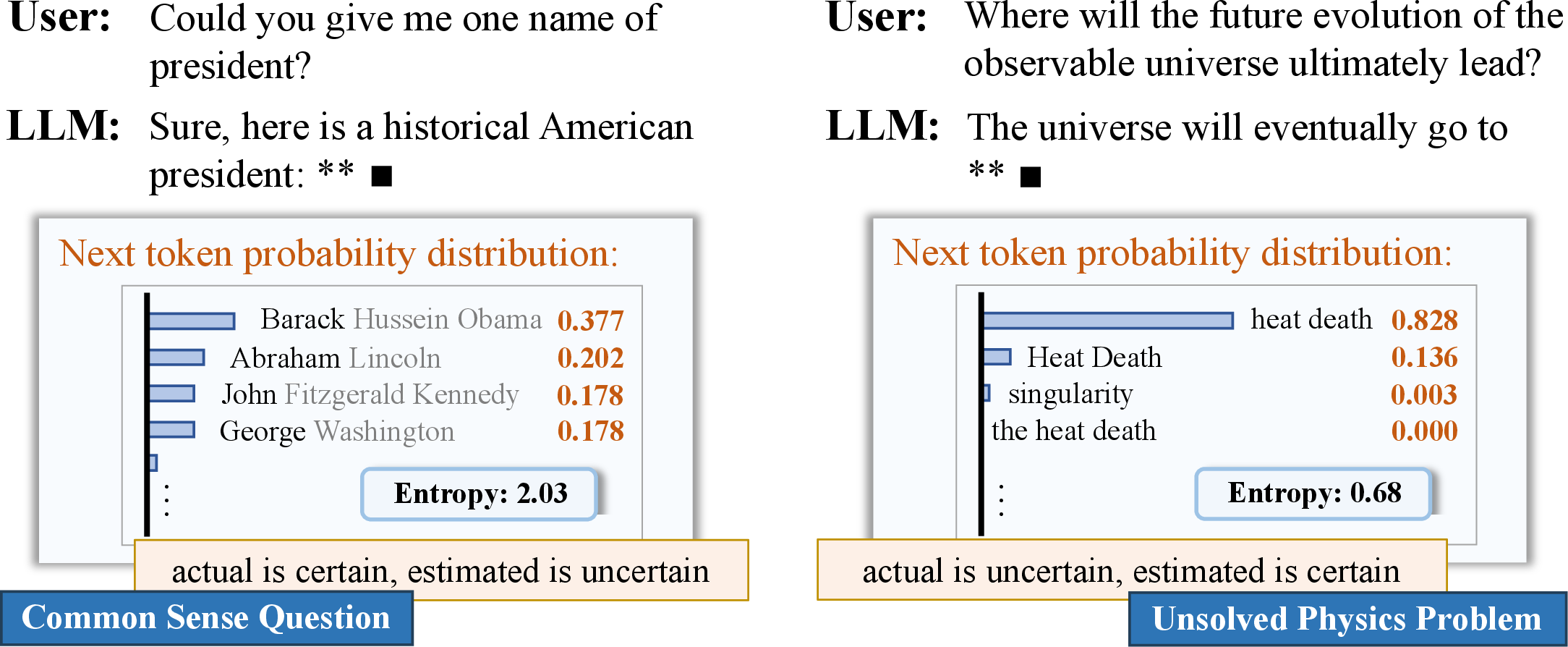
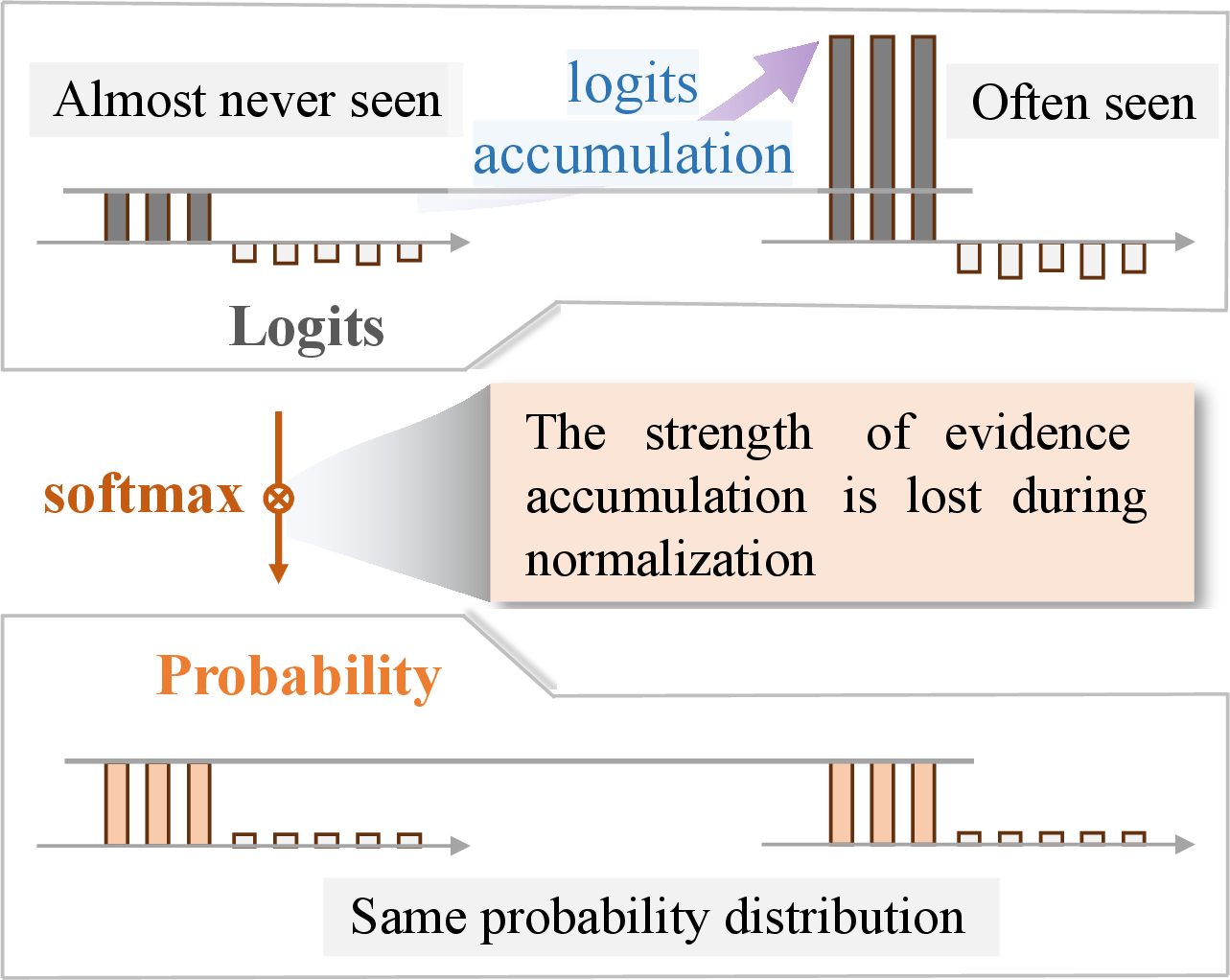
Figure 1: Probability fails in estimating reliability in typical LLM scenarios.
As depicted, LLMs like LLaMA-2 assign low probabilities to common knowledge questions and higher to more specific yet less understood queries, which is counterintuitive and reflects that probability-based measures cannot comprehensively gauge reliability due to the loss of evidence strength information during normalization.
Logits-Induced Token Uncertainty (LogTokU)
LogTokU provides a novel solution by employing the logits themselves rather than solely relying on probabilities post-normalization. The method decouples uncertainty into relative aleatoric and epistemic uncertainties, enabling a clearer indication of LLM confidence on a token level.
The Four Quadrants of LogTokU
The framework categorizes uncertainty into four scenarios:
- High AU, High EU: Reflective of a lack of knowledge and predictive guesswork.
- Low AU, High EU: Indicates a single plausible answer derived from limited knowledge, potentially a repetition.
- Low AU, Low EU: Demonstrates high certainty about a single best-fit answer.
- High AU, Low EU: Implies multiple plausible answers with high confidence, such as synonyms or interchangeable terms.
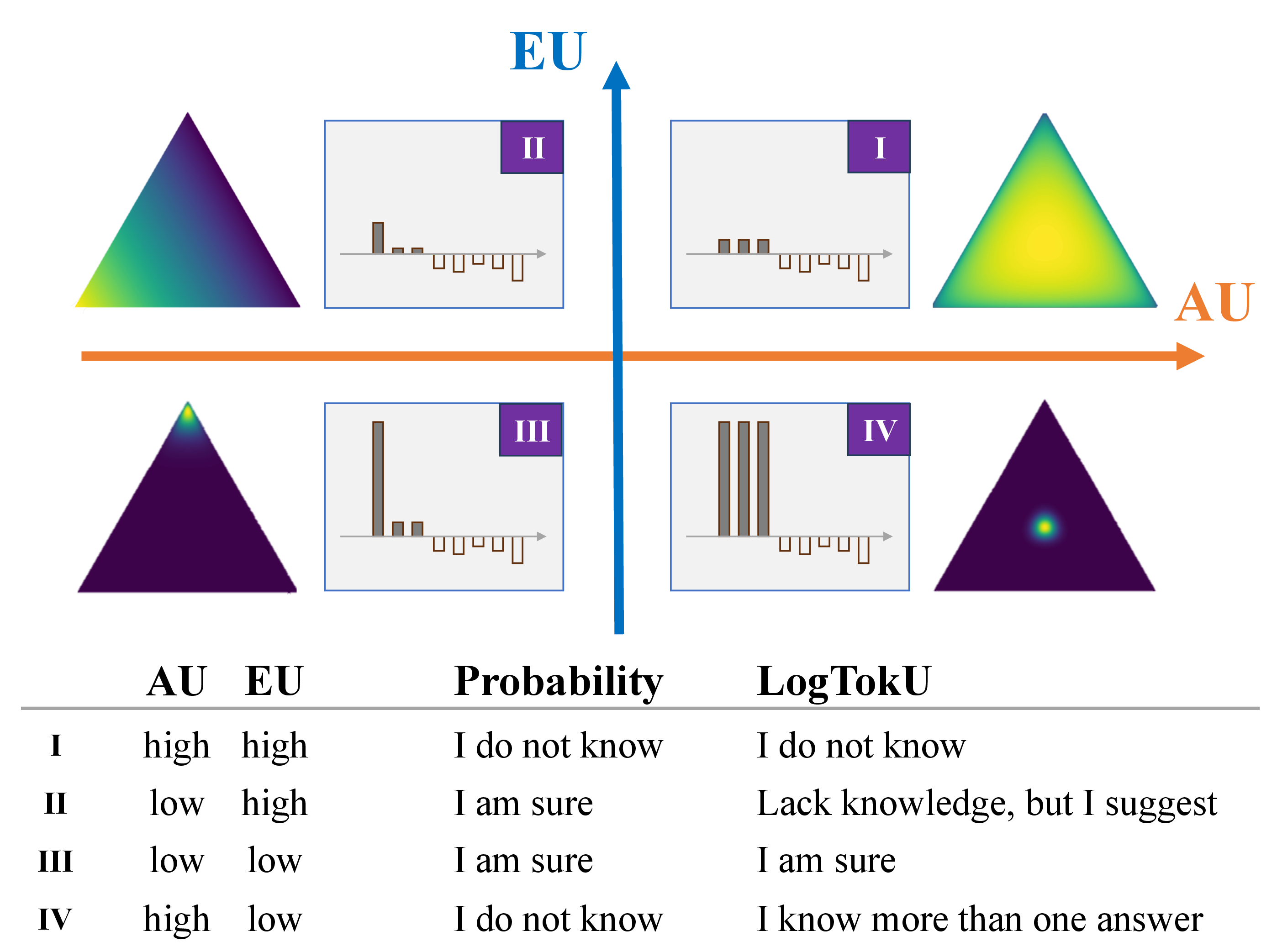
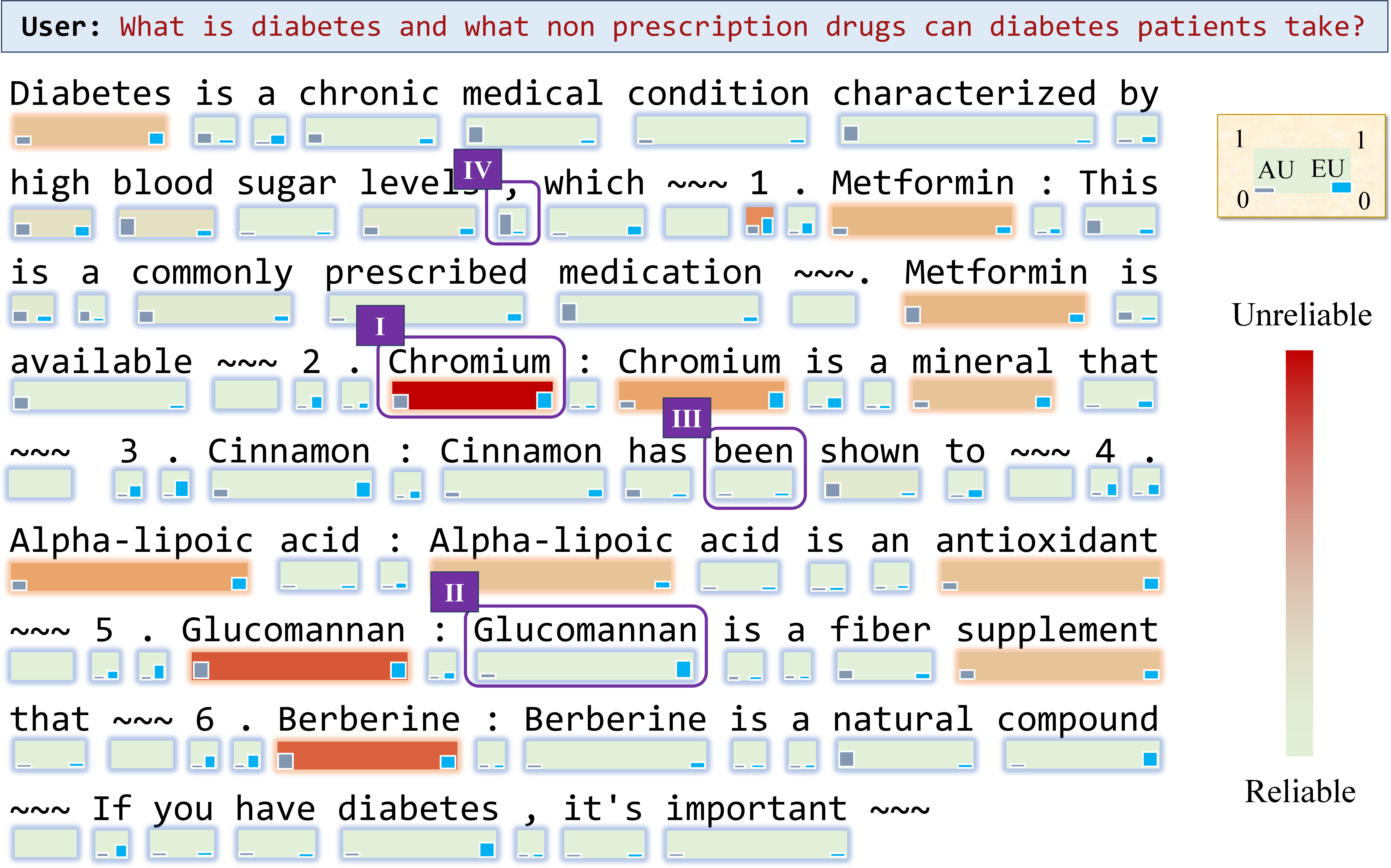
Figure 2: LogTokU scenarios illustrating the diverse reliability contexts captured by Aleatoric and Epistemic uncertainties.
Methodology and Implementation
By treating logits as evidence accumulated through training, LogTokU implements a Dirichlet distribution model using the most significant logits. This approach allows for precise real-time estimation that avoids the computational overhead and inefficiencies of sampling-based methods while accurately modeling the inherent and anticipated uncertainties of token predictions.
Coding Implementation
A sample code illustrating the integration of LogTokU with a typical LLM workflow helps demonstrate its real-world applicability.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import torch
from transformers import Llama2Model
logits = llama2_model(input_ids)
top_k_logits = torch.topk(logits, k=5)
alpha = torch.nn.functional.relu(top_k_logits)
evidence_strength = torch.sum(alpha)
aleatoric_uncertainty = some_function_to_calculate_au(alpha)
epistemic_uncertainty = len(alpha) / (torch.sum(alpha) + 1)
interpret_uncertainty(aleatoric_uncertainty, epistemic_uncertainty) |
Applications
Dynamic Decoding Strategy
The uncertainty framework improves output reliability and diversity management during token sampling and generation. Dynamic adjustments in decoding strategies informed by LogTokU can enhance generation diversity without compromising accuracy critically needed in applications like creative content production or academic responses.
Reliability Estimation
The enhanced, real-time reliability estimation allows user interfaces to more effectively signal model trustworthiness, significantly impacting fields such as healthcare and legal analysis where accuracy is paramount.
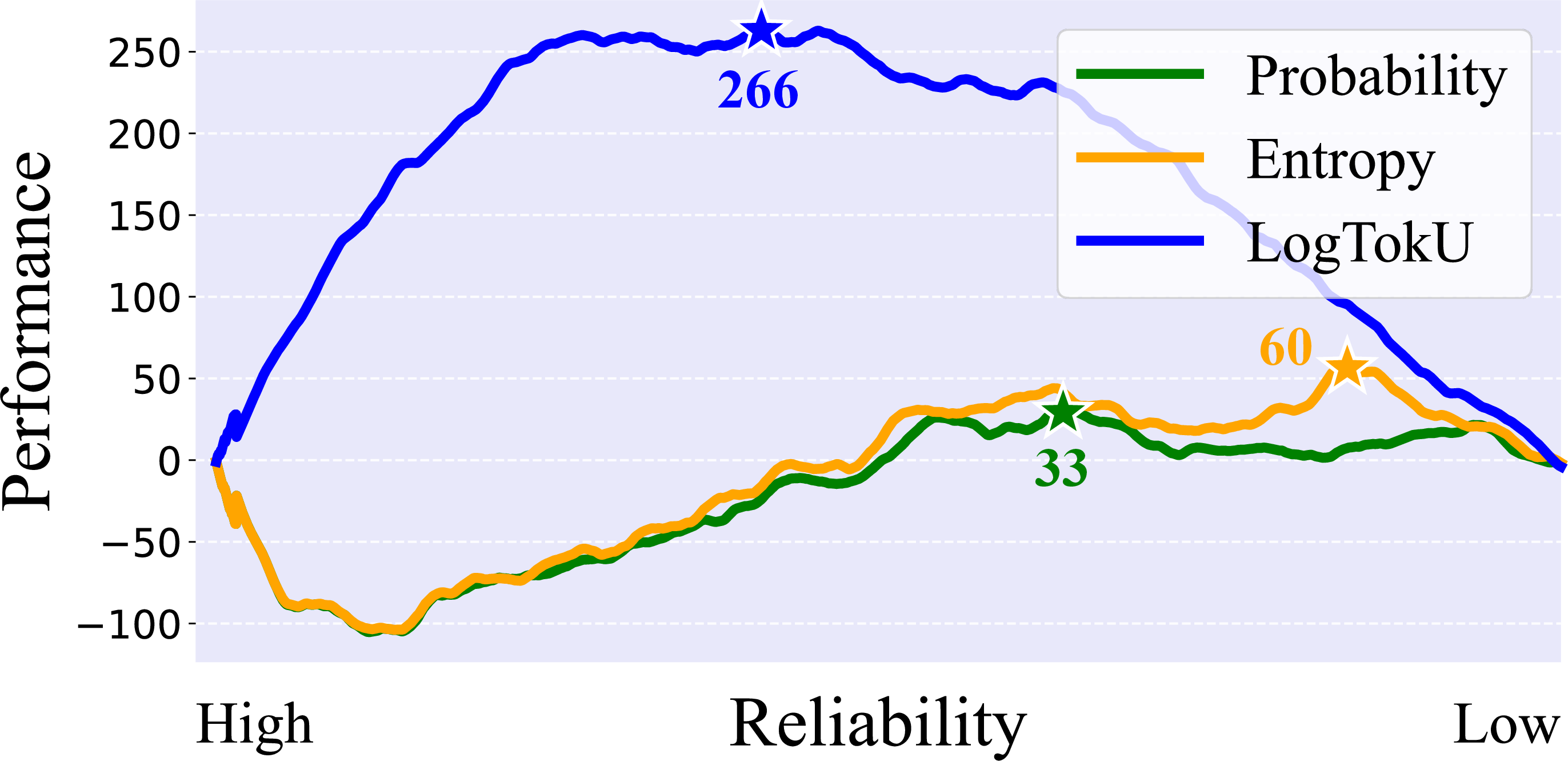
Figure 3: LogTokU-driven cumulative performance improvement through better-informed diversity and accuracy balance.
Conclusion
LogTokU exemplifies a meaningful advance in machine learning, providing elevated clarity in uncertainty quantification and robustness in application-critical scenarios. Future research directions might refine these methodologies further, enhancing both LLM interpretability and scalability in diverse domain applications.