- The paper introduces a taxonomy of uncertainty quantification methods for LLMs, including token-level, self-verbalized, semantic-similarity, and mechanistic interpretability techniques.
- The paper demonstrates how approaches like length-normalization and entailment scoring refine confidence estimation in generated responses.
- The paper highlights calibration challenges and dataset shortcomings, suggesting future research to enhance LLM reliability and safety.
Uncertainty Quantification Techniques for LLMs
Overview
LLMs such as GPT-4 and Llama 3 have garnered significant attention due to their impressive capabilities across language generation, reasoning, and other tasks. However, a critical challenge remains in quantifying the uncertainty associated with their outputs, especially since these models exhibit tendencies to generate hallucinations—confidence-discrepent, incorrect responses. This essay outlines various methodologies and recent advances in uncertainty quantification (UQ) for LLMs, spanning four broad categories: Token-Level UQ, Self-Verbalized UQ, Semantic-Similarity UQ, and Mechanistic Interpretability.
Token-Level Uncertainty Quantification
Token-Level UQ methods leverage the inherent probabilistic outputs of LLMs to deduce uncertainty. These white-box techniques utilize outputs like token probabilities and entropies to estimate confidence levels in a generated response. For example, token-level analyses examine the entropy of predicted tokens to discern how uncertain the LLM might be in its generated content. Techniques such as length-normalization and Meaning-Aware Response Scoring (MARS) further refine these estimates to account for variability in response lengths and compositional intricacies.

Figure 1: Many state-of-the-art LLMs are decoder-only transformers, with N multi-head attention sub-blocks, for auto-regressive output generation.
Self-Verbalized Uncertainty Quantification
Self-verbalized UQ techniques enhance human interpretability by allowing LLMs to express their confidence through natural-language outputs directly. By training models to acknowledge ambiguity via epistemic markers, or to provide probability estimates for their answers, these methods aim for an alignment between model belief and linguistic expression. The challenge, however, lies in ensuring these verbalizations remain calibrated with actual execution, as models tend to overestimate their factuality confidence.

Figure 2: The LLM provides an incorrect response, but communicates its uncertainty using epistemic markers, e.g., "I think."
Semantic-Similarity Uncertainty Quantification
Semantic-Similarity UQ harnesses the degree of coherence among multiple iterations of LLM-generated responses to gauge uncertainty. This category, typically employing black-box strategies, evaluates entailment probabilities or semantic densities over response clusters to produce confidence metrics robust to language variances. Recent works leverage this entailment to track coherence for improved factuality estimations and mitigate latency in decision-making processes under uncertainty.
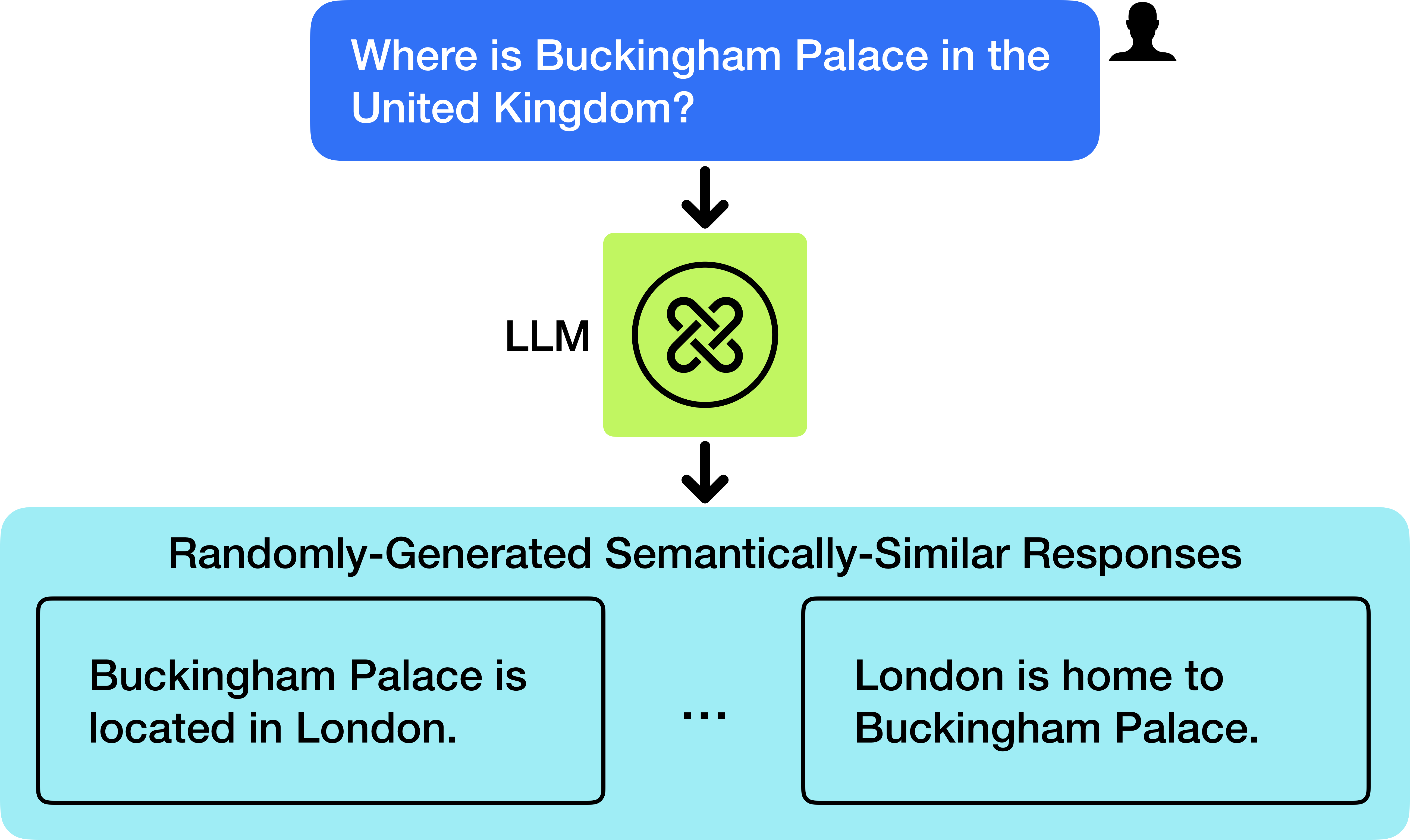
Figure 3: When prompted to answer a question, e.g., "Where is Buckingham Palace in the United Kingdom?", an LLM might generate many variations of the same sentence. Although the form of each response may differ at the token-level, the semantic meaning of the sentences remains consistent.
Mechanistic Interpretability
Mechanistic Interpretability explores the internal network dynamics of LLMs to correlate specific structural or functional features with uncertainty manifestations. Techniques in this field aim to dissect neural network activations, identify latent feature encodings and circuits, and enhance the comprehensibility of LLM operations. While this area has yet to witness extensive deployment for UQ specifically, it holds promise for intrinsic confidence assessments and error attributions.
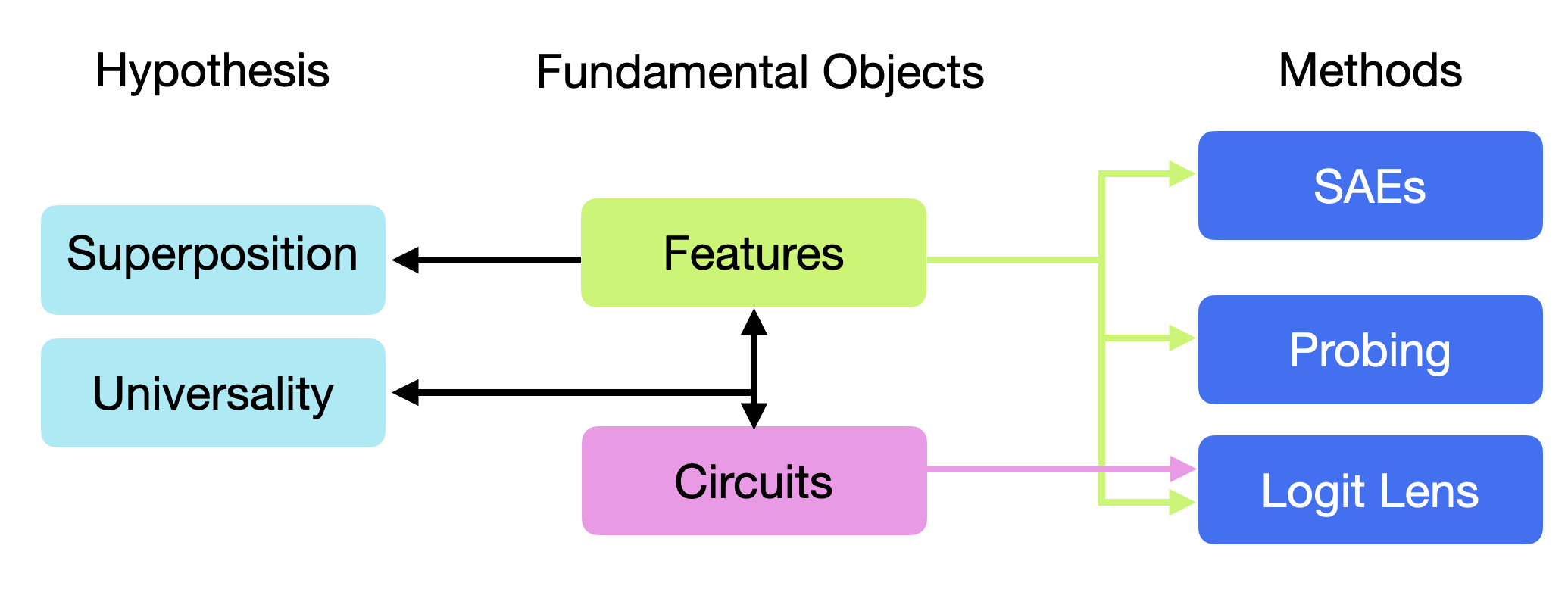
Figure 4: Taxonomy of Mechanistic Interpretability.
Calibration and Dataset Challenges
The misalignment between estimated confidence and observed accuracy constitutes a significant barrier in LLM deployment, prompting the development of calibration techniques. Methods for calibration range from conformal prediction to entropy-based corrective measures. Addressing the shortcomings in existing datasets, there's a need for tailored benchmarks assessing UQ capabilities, particularly those that account for dynamic, multi-episode interactions.
Conclusion
This survey delineates the need for comprehensive UQ methods in LLM operations, proposing a structured taxonomy, reviewing current applications, and identifying directions for future research. Addressing open challenges such as consistency versus factuality, integrating insights from mechanistic interpretability, and formulating robust benchmarks will drive future advances, promoting safer and more reliable AI deployments in complex real-world applications.

Figure 5: Uncertainty quantification methods for LLMs have been employed in hallucination detection. LLMs tend to be less confident when hallucinating, enabling detection.

