Humains-Junior: A 3.8B Language Model Achieving GPT-4o-Level Factual Accuracy by Directed Exoskeleton Reasoning
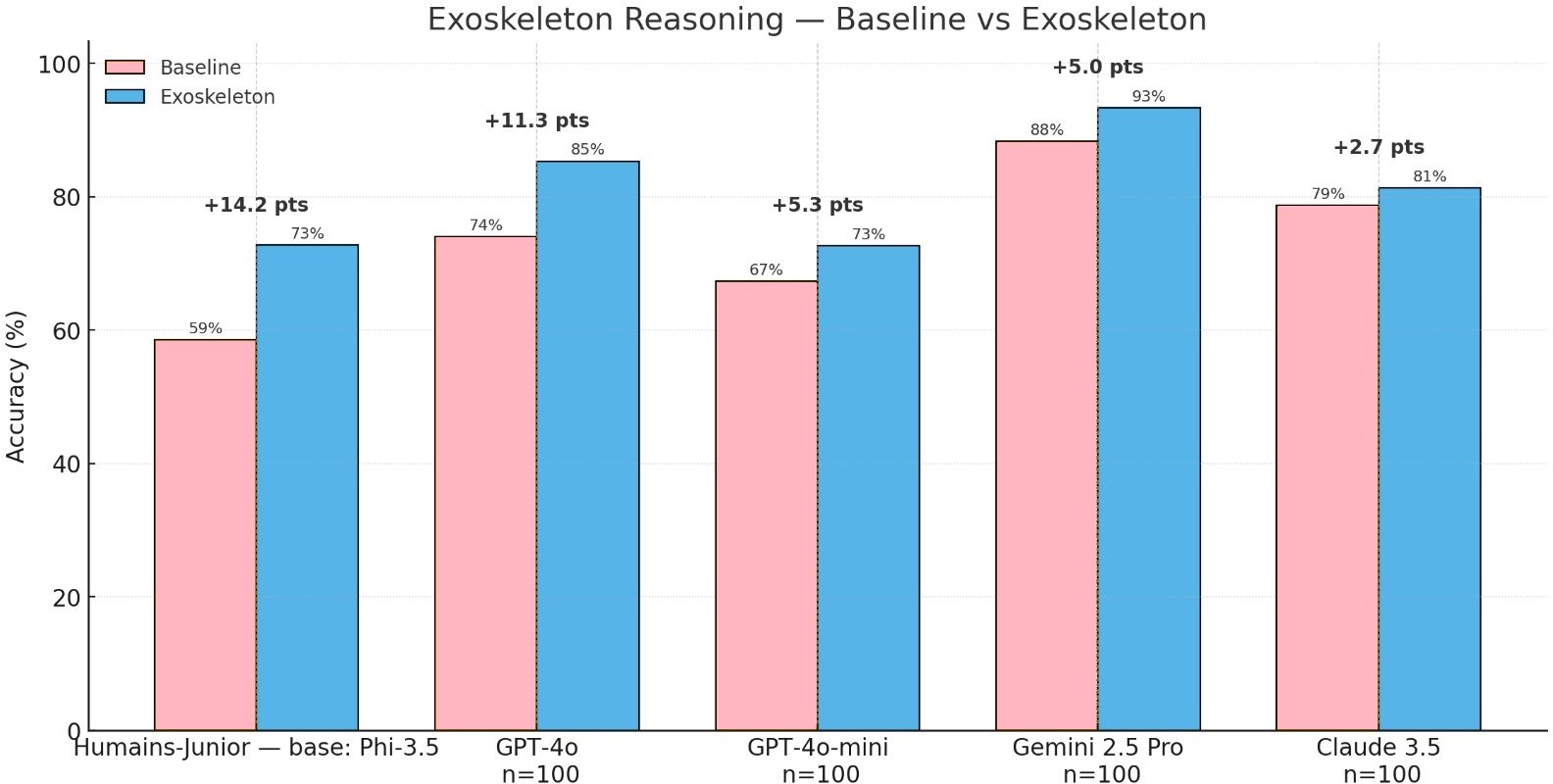
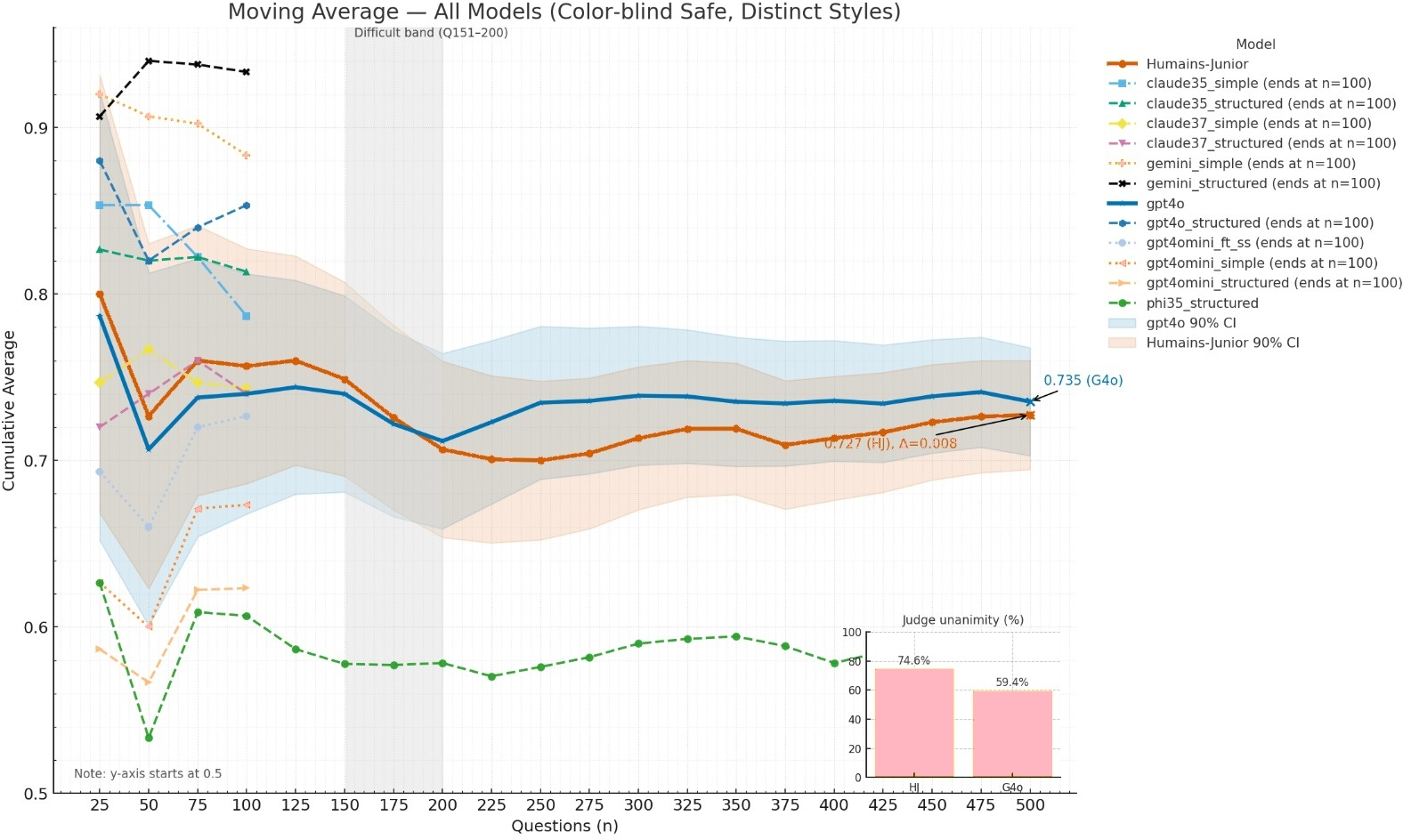
Abstract: We introduce Humans-Junior, a 3.8B model that matches GPT-4o on the FACTS Grounding public subset within a $\pm 5$ pp equivalence margin. Results. On Q1--Q500 under identical judges, GPT-4o scores 73.5% (95% CI 69.5--77.2) and Humans-Junior 72.7% (95% CI 68.7--76.5); the paired difference is 0.8 pp (bootstrap 95% CI $-3.1$ to $+4.7$; permutation $p = 0.72$; Cohen's $d = 0.023$). TOST establishes equivalence at $\pm 5$ pp (not at $\pm 3$ pp). When purchased as managed APIs, Humans-Junior's base model (Phi-3.5-mini-instruct) is $\approx 19\times$ less expensive than GPT-4o on Microsoft AI Foundry pricing; self-hosted or edge deployments can drive incremental inference cost toward zero. Measured vs estimated pricing sources are tabulated in Appendix E. Method. Our approach combines minimal directed "Exoskeleton Reasoning" scaffolds with behavioral fine-tuning that teaches protocol compliance (epistemic discipline) rather than domain answers. Fine-tuning alone adds little; combined, they synergize (+17.7 pp, $p < 0.001$) and reduce variance ($\approx 25\%$). In prompt-only settings on frontier models (Q1--Q100; non-comparable), directed reasoning improved GPT-4o by +11.8 pp to 85.3% and Gemini-2.5-Pro by +5.0 pp to 93.3% (baseline 88.3%, $n = 100$); see Section~5. TL;DR. A 3.8B model achieves GPT-4o-level FACTS accuracy (equivalent within $\pm 5$ pp on Q1--Q500). Cloud pricing shows $\approx 19\times$ lower cost versus GPT-4o, and self-hosted/edge deployments can approach zero marginal cost. Pricing sources are listed in Appendix E. Frontier prompt-only gains (Q1--Q100; non-comparable) and optimized-prompt exploratory results under earlier judges are summarized in Appendix F. Keywords: Small LLMs, Factual Grounding, Directed Reasoning, Fine-Tuning, Model Alignment, Cost-Efficient AI
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Humains‑Junior, a small AI LLM with about 3.8 billion parameters. Its main purpose is to show that a small, affordable model can be just as factually accurate as a much larger, more expensive model (like GPT‑4o) on a tough test called the FACTS Grounding benchmark. The key idea that makes this work is something the authors call “Exoskeleton Reasoning,” which is a simple, step‑by‑step checklist the model follows to make sure its answers are based only on the information it’s given.
Key Questions the Paper Tries to Answer
- Can a small, low‑cost AI match a top‑tier AI in sticking to facts when answering questions, especially when long documents are involved?
- Does adding a simple “check‑before‑you‑answer” reasoning routine improve accuracy across different models?
- Will teaching a model to follow a reasoning protocol (how to think) matter more than teaching it specific facts (what to think)?
- Can these improvements reduce costs enough to make AI more practical to deploy widely?
How They Did It (Methods, Explained Simply)
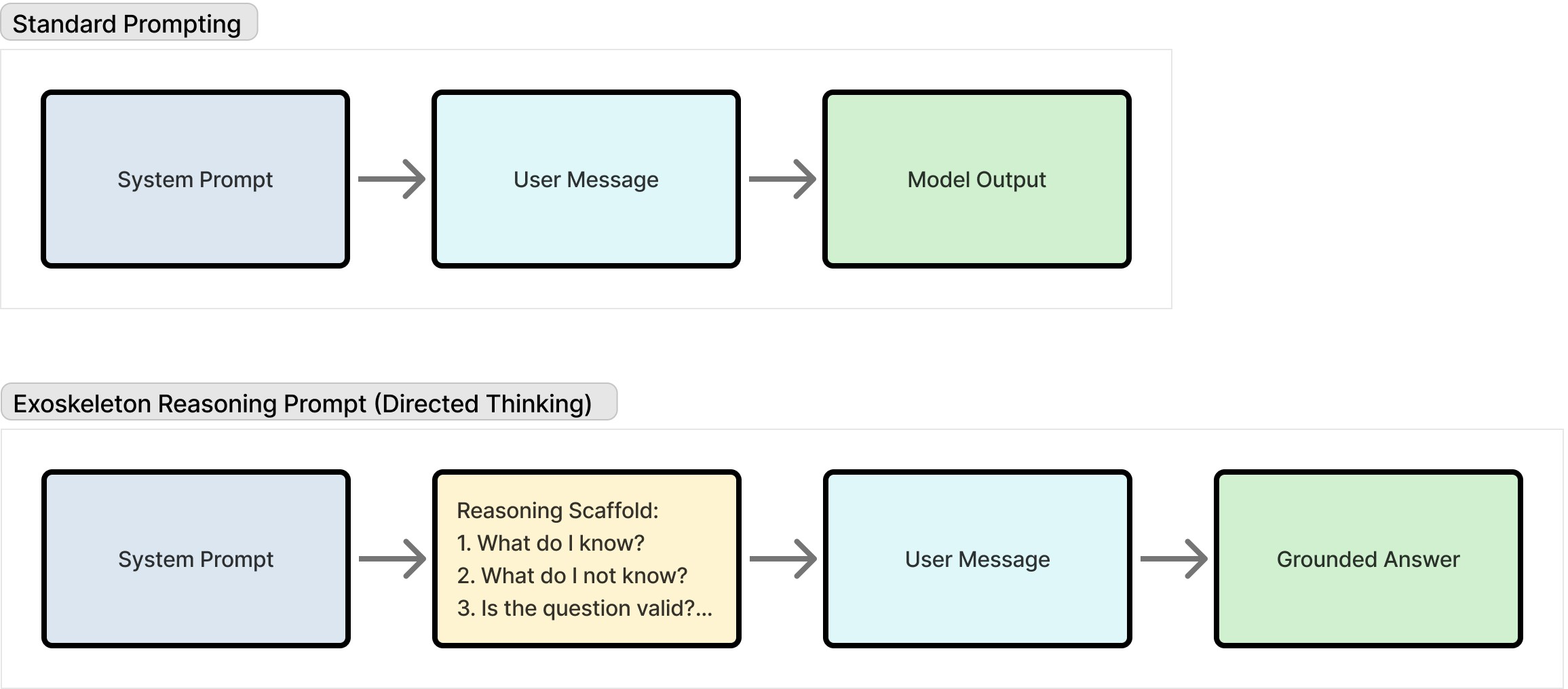
Think of Exoskeleton Reasoning like a pilot’s pre‑flight checklist or a YouTuber’s “script outline” before recording. Before the model writes an answer, it briefly checks the context and its own assumptions so it doesn’t make stuff up.
Here’s the simple routine the model follows:
- Identify key points in the provided document (the “anchors”).
- Test each claim against the given context to see if it’s actually supported.
- Only write the final answer from the parts that passed the checks.
The researchers:
- Started with an existing small model (Phi‑3.5‑mini‑instruct) and fine‑tuned it on conversations from real products where careful reasoning was important (like customer support and in‑car assistants). The training focused on behavior—being careful, admitting uncertainty, and following protocols—not on memorizing specific domain facts.
- Evaluated models on the FACTS Grounding benchmark, which asks questions that must be answered only using the provided documents (no guessing). The benchmark uses three separate AI systems as judges to score factual accuracy.
- Used the same sets of questions for fair comparisons: the first 100 questions for large “frontier” models (like GPT‑4o) and the first 500 for the small, fine‑tuned models (including Humains‑Junior).
- Applied standard statistics to check whether small differences were meaningful. A key test (called TOST) checks whether two models’ results are close enough to be considered “equivalent” within a chosen margin. In this case, the margin was ±5 percentage points.
Main Findings and Why They Matter
- Humains‑Junior scored 72.7% on the first 500 FACTS questions, while GPT‑4o scored 73.5% on the same set. The difference (0.8 percentage points) is tiny, and the formal test showed the two models are equivalent within ±5 percentage points.
- Cost is the standout: on managed cloud pricing, Humains‑Junior is about 19 times cheaper than GPT‑4o for the same kind of task. If you run it yourself on local or edge devices, the added cost per use can be near zero.
- The simple reasoning routine helps big models too. Without any training, just prompting GPT‑4o with the Exoskeleton steps improved its accuracy by about 11.8 percentage points on a smaller test set (Q1–Q100). Gemini‑2.5‑Pro also improved.
- Combining the checklist with behavior training (teaching the model how to follow the protocol) gave a big boost: roughly +17.7 percentage points over the small model’s baseline and about 25% less variability. This means more consistent performance across different kinds of questions.
- The model avoided “hallucinations” (confidently making things up) by being self‑aware of gaps. For example, when a review didn’t declare a single “best” baby co‑sleeper, the scaffolded model explained that the best choice depends on needs, instead of inventing a winner.
What This Means (Implications and Impact)
Big Picture
This work shows that careful thinking beats sheer size for many fact‑based tasks. Instead of relying on expensive “think harder at runtime” modes, teaching the model a simple check‑first routine and aligning its behavior can deliver similar factual accuracy at a fraction of the cost.
Practical Impact
- Organizations can deploy small, cheaper models that still meet high factual standards, making AI more accessible and scalable.
- This is great for systems that must stick to trusted sources, like internal knowledge bases or legal/medical documents, and for Retrieval‑Augmented Generation (RAG) setups where the model must follow supplied context precisely.
- Running on edge devices reduces latency and cost, which helps in real‑time applications (cars, phones, embedded systems).
Safety and Limits
- The checklist tells the model to trust the provided context over its own knowledge. That’s perfect when the context is verified—but risky if the context is wrong. The paper suggests safety modes with overrides for critical domains (medicine, law, finance) and keeping humans in the loop.
- The models are equivalent within ±5 percentage points, not within a tighter ±3. For very high‑stakes jobs where small differences matter, further testing or using larger models may still be preferred.
In short, the paper’s key message is: with a simple, directed reasoning checklist and behavior training, small models can be reliably factual—and much cheaper—making high‑quality AI more practical to use in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, missing analyses, and open questions that future researchers could address to strengthen, validate, or generalize the paper’s claims.
- Full-benchmark coverage and sampling bias: Results rely on sequential subsets (Q1–Q100 for frontier models, Q1–Q500 for fine-tuned models) from the public split; the full 1,719-example benchmark (public+private) was not used. Assess performance on the complete dataset and under randomized sampling to rule out ordering or subset effects.
- Judge panel independence and robustness: GPT-4o serves both as a system under test and as a judge, creating potential conflicts of interest. Re-score identical items with a fully non-overlapping judge panel and include human adjudication baselines; quantify inter-judge agreement, reliability, and bias reduction beyond McNemar tests.
- Statistical inference for judge-averaged outcomes: Wilson CIs are applied to judge-averaged scores (non-binomial). Provide cluster-robust CIs at the question level (or mixed-effects/GLMM approaches) and report bootstrap CIs for per-model accuracies, not only paired differences.
- Equivalence margin selection and sensitivity: Justification for ±5 pp “practical equivalence” is qualitative. Perform sensitivity analyses for ±2, ±3, ±4, ±5 pp and tie margins to concrete deployment risk models (e.g., cost-per-error, domain-critical thresholds).
- Decoding parameter sensitivity and fairness: Models were evaluated under different temperatures (small models at 0.3; frontier at 1.0). Systematically sweep temperature, top_p, and sampling settings to quantify sensitivity and ensure fair, comparable decoding regimes across models.
- Domain-level performance breakdown: Provide per-domain (finance, medicine, law, retail, technology) accuracy, variance, and error taxonomy. Investigate the observed heterogeneity (e.g., Q151–200 difficulty drop) to identify where small models lag or excel.
- Response-level metrics and trade-offs: Analyze response length, coverage, citation density, and abstention/ineligibility rates in detail. Quantify whether Exoskeleton Reasoning changes verbosity, coverage, or abstention behaviors and how these relate to accuracy.
- Confidence calibration and uncertainty expression: Measure calibration (e.g., ECE, Brier score) and the quality of uncertainty statements under Exoskeleton Reasoning; determine whether epistemic restraint leads to better-calibrated outputs.
- Long-context and context window constraints: FACTS includes documents up to ~32k tokens; the small model’s effective context window and performance with very long contexts are not characterized. Measure accuracy and latency as context length scales and report practical limits (window size, truncation effects).
- Token and latency overhead characterization: Exoskeleton overhead is estimated at ~3–5% tokens without detailed latency or throughput measurements. Quantify runtime cost, end-to-end latency, and throughput impacts across hardware configurations and workloads.
- Cost analysis completeness: Inference cost comparisons use cloud list prices and do not include training costs (300M-token fine-tuning), TCO (hardware, energy), or cost-per-correct metrics. Provide comprehensive TCO and cost-per-accurate-answer analyses, including edge-device performance, quantization, and energy measurements.
- Safety validation for context dominance: The scaffold encourages following provided context even when it contradicts established facts. Empirically test the safety modes (context-dominant, override, balanced authority) with red-teaming, seeded-context errors, and measure harmful compliance rates and false-safety overrides.
- External factuality vs. context-grounded correctness: FACTS judges reward context adherence, not objective truth. Evaluate on datasets where context contains intentional errors, or include an external truth evaluation to quantify real-world factual reliability when context is untrusted.
- Generalization beyond FACTS: Validate Exoskeleton Reasoning on other grounding and hallucination benchmarks (e.g., TruthfulQA, HotpotQA, FEVER, HaluEval), on multi-turn dialogues, and across languages to assess broader applicability.
- Reproducibility of Phase 1 fine-tuning: Phase 1 training lacks full hyperparameter disclosure (optimizer, batch size, schedule, epochs, regularization, LR, dataset composition). Share training recipes, code, and synthetic or representative data to allow replication or controlled ablations.
- Ablation of scaffold components: Isolate which Exoskeleton steps (anchor identification, claim testing, synthesis gating, “what might be missing/wrong” cue) are necessary and sufficient. Report quantitative ablations of prompt elements and few-shot exemplars across model families.
- Unified vs. optimized prompts fairness: The paper uses different few-shot counts per model family (e.g., 3-shot for GPT-4o/Claude, 1-shot for others). Quantify the effect of few-shot count and content on performance; ensure a fair comparison under identical prompt budgets.
- Judge preference analysis depth: McNemar tests show opposing per-judge preferences; investigate causes (e.g., stylistic features, length, calibration) and whether preference shifts persist under alternate judge configurations or human oversight.
- Comparative baselines among small models: Evaluate against other SLMs (e.g., Llama 3.x 8B, Mistral 7B, Qwen variants) to determine whether Exoskeleton+behavioral fine-tuning generalizes across architectures and sizes and to contextualize the 3.8B model’s competitiveness.
- Edge deployment realism: Claims of near-zero marginal cost on edge are not accompanied by measured memory footprints, quantization strategies (e.g., int8/int4), device classes, throughput, or energy consumption. Provide detailed edge benchmarks and constraints.
- Data privacy and compliance verification: Training on production logs is described as anonymized, but external audits and compliance artifacts (PII scrubbing validation, DPIA, SOC2/GDPR implications) are not provided. Publish a data handling audit or synthetic dataset that mirrors privacy constraints.
- Mechanistic evidence for “attention allocation” hypothesis: The claim that hallucination is primarily an attention allocation problem is supported by anecdotes. Provide mechanistic analyses (attention/head patterns, attribution, intervention experiments) showing how Exoskeleton shifts attention and reduces specific error modes.
- Compute-scaling comparisons to other reasoning methods: Assertions that RL “thinking modes” cost 3–10× compute are not empirically benchmarked in this work. Run controlled comparisons of Exoskeleton vs. CoT, Self-Refine, ToT, and RL-trained modes under matched token and latency budgets.
- Time drift and judge updates: Scores are known to vary with judge revisions and temporal drift. Quantify temporal robustness (re-evaluations over time) and version sensitivity of judge models; provide locked judge versions and cross-time variance estimates.
- Ineligibility/abstention characterization: While >99% eligibility is noted, a systematic analysis of abstention triggers, partial coverage cases, and judge treatment of restrained answers is missing. Examine abstention as a function of context quality and task type.
- Pricing source validation: The cost table mixes measured vs. estimated sources; include reproducible scripts to measure real billing under typical loads, rate-limit constraints, and context-length distributions.
- Internal GPT-4o-mini experiment transparency: The fine-tuned GPT-4o-mini achieving ~73% is not released; provide weights, training logs, or a distillation of lessons to validate transferability claims.
- Input modality coverage: FACTS tasks vary in structure; assess performance on tables, numeric reasoning, code, and math-specific contexts to understand where Exoskeleton Reasoning helps or fails.
- Production failure modes and monitoring: Define and test monitoring policies (discrepancy logging, confidence thresholds, harm detectors) in real deployments; quantify false positives/negatives and operational impact of the proposed safeguards.
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging the paper’s findings on Exoskeleton Reasoning, epistemic discipline, and small-model equivalence on FACTS with substantial cost savings.
- Cost-optimized, document-grounded customer support copilots (software, retail, telecom)
- What: Replace GPT-4o with Humains-Junior in RAG-based help centers and FAQs where answers must strictly come from a verified knowledge base.
- Tools/Workflows: RAG pipeline with Exoskeleton scaffold; Mode 1 (Context-Dominant) safety mode; judge-unanimity KPI for monitoring.
- Assumptions/Dependencies: Curated, trustworthy KB; retrieval quality; CC BY-NC 4.0 licensing constraints for commercial use; modest 3–5% token overhead.
- On-prem/edge-grounded assistants for privacy-sensitive data (healthcare, finance, legal, government)
- What: Deploy the 3.8B model on servers or edge devices to answer questions strictly from internal documents without sending data to cloud.
- Tools/Workflows: Quantized model on CPU/GPU; dockerized microservice; Mode 2 (Context-Dominant with Safety Override) for safety-critical contexts.
- Assumptions/Dependencies: Sufficient local compute and MLOps; verified corpora; domain safety rules; internal compliance review.
- Prompt-only factuality boosts for frontier models (software, content ops)
- What: Apply the Exoskeleton scaffold to GPT-4o/Gemini today to raise document-grounded accuracy without retraining.
- Tools/Workflows: Unified Exoskeleton prompt template; few-shot examples; minimal integration effort.
- Assumptions/Dependencies: Strong instruction following; willingness to accept small token overhead; evaluation variance across judge panels.
- Sales engineering and product-spec advisors grounded to official materials (SaaS, manufacturing, consumer electronics)
- What: Ensure recommendations strictly reflect current spec sheets, price books, and compatibility matrices.
- Tools/Workflows: RAG with spec changefeeds; Mode 3 (Balanced Authority) with context-confidence gating; discrepancy logging between internal priors and context.
- Assumptions/Dependencies: Up-to-date catalogs; robust retrieval; process for escalating conflicts.
- Compliance-sensitive debt collection and account servicing bots (finance, fintech)
- What: AI agents that adhere to regulatory scripts and only cite verified account records.
- Tools/Workflows: Mode 2 safety override; harm and compliance classifiers; human-in-the-loop for edge cases.
- Assumptions/Dependencies: Accurate, fresh account data; legal review; audit logging of analysis and sources.
- In-vehicle assistants constrained to manuals and telematics (automotive)
- What: On-device copilots for diagnostics and “how-to” guidance grounded to OEM manuals and sensor data.
- Tools/Workflows: Edge deployment; context fusion from CAN/OBD-II and manuals; explicit safety overrides for procedures.
- Assumptions/Dependencies: Reliable signal-to-text adapters; verified procedures; safety certification pathways.
- Legal document Q&A with strict source adherence (legal services, enterprise legal)
- What: Summarize and answer only from provided contracts, filings, or statutes; surface conflicts explicitly.
- Tools/Workflows: Exoskeleton Analysis/Response with per-claim citations; discrepancy logs; Mode 3.
- Assumptions/Dependencies: Verified document sets; attorney oversight; calibrated abstention for gaps.
- Course-material–grounded study assistants (education, edtech)
- What: Tutors that answer strictly from assigned readings/lecture notes and admit gaps otherwise.
- Tools/Workflows: LMS plugin; Mode 1 for vetted materials; source-linked answers; confidence display.
- Assumptions/Dependencies: Curated content; retrieval coverage; instructor governance.
- HR/IT internal policy copilots (enterprise operations)
- What: Slack/Teams bots that answer only from current policy docs, avoiding outdated or speculative guidance.
- Tools/Workflows: Policy KB ingestion with versioning; Mode 1; change-alert workflow when conflicts arise.
- Assumptions/Dependencies: Policy freshness; ownership for updates; access control.
- Procurement and model selection using equivalence testing (MLOps, governance)
- What: Adopt TOST-based equivalence thresholds (±5 pp) to replace expensive models when small models are practically equivalent on org-specific benchmarks.
- Tools/Workflows: Evaluation harness mirroring FACTS judge-averaging; paired comparisons; cost-per-quality dashboards.
- Assumptions/Dependencies: Representative internal test sets; judge configuration stability; organizational tolerance for ±5 pp margin.
- Factuality monitoring with judge-unanimity and restraint metrics (MLOps)
- What: Track “unanimity rate,” abstention rate, and source coverage as reliability KPIs in production.
- Tools/Workflows: Logging of Analysis/Response segments; synthetic judge/rubric checks; drift alarms.
- Assumptions/Dependencies: Observability stack; rubric alignment with business goals; labeling budget for spot audits.
- Developer middleware for protocol compliance (software tooling)
- What: Wrap any LLM call with Exoskeleton scaffolding and safety-mode selection to standardize grounded outputs.
- Tools/Workflows: “Validate→Synthesize” middleware; prompt libraries; per-domain policy packs.
- Assumptions/Dependencies: Integration into app gateways; cross-model compatibility; version pinning of prompts.
Long-Term Applications
These opportunities are promising but require further research, scaling, integration, or validation (e.g., regulatory approval, multimodal capability, or broader benchmarks).
- Safety-certified deployments in regulated domains (healthcare, aviation, finance)
- What: Obtain formal approval to use protocol-compliant SLMs for clinical/operational decision support where context is authoritative.
- Tools/Workflows: Prospective trials; calibrated abstention; full audit trails of analysis steps.
- Assumptions/Dependencies: Regulatory frameworks; liability models; robust fail-safes.
- Adaptive, context-aware scaffolding with tool use (software agents)
- What: Dynamic Exoskeletons that adjust rigor by context confidence and automatically trigger tools (retrieval, calculators, code execution).
- Tools/Workflows: Policy engines; retrieval confidence models; tool routers.
- Assumptions/Dependencies: Reliable confidence estimation; tool reliability; latency budgets.
- Multimodal Exoskeleton Reasoning (vision, audio, sensor fusion)
- What: Ground answers in images, PDFs, voice notes, and telemetry with explicit validation checkpoints.
- Tools/Workflows: Multimodal SLMs; OCR/PDF structure parsers; sensor fusion adapters.
- Assumptions/Dependencies: High-quality multimodal pretraining; domain-specific validation rules.
- Cross-lingual grounded assistants and low-resource support
- What: Exoskeleton-trained multilingual SLMs that maintain epistemic discipline across languages and scripts.
- Tools/Workflows: Multilingual fine-tuning datasets; cross-lingual retrieval.
- Assumptions/Dependencies: Data availability; evaluation suites beyond English; UI localization.
- Government information services with “Balanced Authority” standards (public policy)
- What: Citizen-facing copilots that weigh official sources against detected misinformation and provide transparent conflict reports.
- Tools/Workflows: Source-trust scoring; policy playbooks; transparent analysis presentation.
- Assumptions/Dependencies: Content provenance infrastructure; accessibility requirements; public auditability.
- Edge robotics and industrial assistants with grounded procedures (robotics, manufacturing, energy)
- What: On-device assistants that enforce SOPs and safety manuals during maintenance or operations.
- Tools/Workflows: Procedure-aware Exoskeletons; real-time context ingestion; exception escalation channels.
- Assumptions/Dependencies: Real-time constraints; ruggedized hardware; human factors validation.
- Confidence calibration and user-facing uncertainty UX (product design, HCI)
- What: Standardized interfaces for showing confidence, missing info, and conflicts to end-users.
- Tools/Workflows: Calibrated probability estimates; abstention policies; learnable thresholds.
- Assumptions/Dependencies: Reliable calibration methods; user studies; domain-tuned thresholds.
- Ultra-low-power and mobile deployments (semiconductors, mobile)
- What: Distill and quantize Exoskeleton-compliant SLMs to NPUs for offline phones, wearables, or kiosks.
- Tools/Workflows: 4–2 bit quantization; sparsity; hardware-aware training.
- Assumptions/Dependencies: NPU capabilities; latency/throughput targets; acceptable accuracy loss.
- Domain marketplaces of protocol-compliant SLMs (legal, tax, pharma)
- What: Curated small models fine-tuned for Exoskeleton execution in specific verticals with vetted corpora and safety policies.
- Tools/Workflows: Domain data pipelines; licensing and updates; benchmark suites per vertical.
- Assumptions/Dependencies: High-quality domain corpora; maintenance and versioning; IP compliance.
- Legal-grade audit logging and chain-of-custody for AI outputs (compliance, e-discovery)
- What: Standardize storage of analysis steps, prompts, contexts, and model versions for defensible auditing.
- Tools/Workflows: Cryptographic logging; tamper-evident stores; reproducible evaluation harnesses.
- Assumptions/Dependencies: Storage and privacy policies; auditor acceptance; standard schemas.
- Expanded, consensus-based factuality benchmarks and judge panels (research, standards)
- What: Community-maintained suites beyond FACTS (multilingual, multimodal, safety) with standardized multi-judge protocols and equivalence margins.
- Tools/Workflows: Open scoring infrastructure; panel-variance analysis; organizational equivalence thresholds (e.g., ±3 pp vs ±5 pp).
- Assumptions/Dependencies: Funding, community participation, and governance for updates.
Key cross-cutting assumptions and dependencies (affecting both immediate and long-term uses):
- Ground truth quality: Many applications assume context is verified; in “Context-Dominant” modes, epistemic responsibility shifts to the context provider.
- Safety configuration: Choosing among Mode 1/2/3 and enforcing overrides is critical in safety-critical domains.
- Generalization limits: Equivalence was established at ±5 pp on specific subsets and judge panels; scores may vary with different judges/datasets.
- Licensing and IP: The released model is CC BY-NC 4.0; commercial deployments may require alternative licensing or re-training.
- Retrieval quality: RAG recall/precision and context-confidence scoring materially impact outcomes.
- Operational maturity: Monitoring (unanimity, abstention), human oversight, and upgrade/version controls are necessary for production reliability.
Glossary
- AdamW: An optimization algorithm that adds decoupled weight decay to Adam to improve generalization. "Optimizer: AdamW with paged optimization"
- Adversarial self-critique: A prompting strategy where the model challenges its own outputs to detect errors or biases. "introduced multi-persona reasoning and adversarial self-critique, observing that models 'aim to please' rather than 'aim to be correct.'"
- Bootstrap confidence intervals: Nonparametric intervals derived by resampling data to estimate uncertainty without distributional assumptions. "we also computed bootstrap confidence intervals (10,000 resamples) for the paired difference Δ, which makes no distributional assumptions."
- Chain-of-thought prompting: A technique that elicits step-by-step reasoning traces to improve problem-solving. "Chain-of-thought prompting [2], Self-Refine [4], and Tree of Thoughts [3] reveal that models possess latent reasoning capabilities that prompting can surface."
- Cluster-robust standard errors: Variance estimates that account for intra-cluster correlation to provide reliable inference. "yielding cluster-robust standard errors; however, since our primary inference is the paired comparison using bootstrap methods, this refinement does not materially affect our conclusions."
- Cohen's d: A standardized effect size measuring the magnitude of differences between means. "Cohen's d = 0.023"
- Cognitive scaffolding: Structured guidance that shapes the model’s reasoning process before response synthesis. "Cognitive Scaffolding and Process Supervision."
- Confidence calibration curves: Plots that compare predicted confidence to actual accuracy to assess calibration. "we did not systematically analyze response length, coverage metrics, or confidence calibration curves"
- Epistemic discipline: Training or prompting that instills strict adherence to evidence and context over prior beliefs. "Identify protocol compliance (epistemic discipline) as the key mechanism;"
- Epistemic restraint: The deliberate avoidance of unsupported claims and overconfident assertions. "Even a single cue to assess 'what might be missing or wrong' can activate epistemic restraint."
- Equivalence margin: A predefined bound within which two methods are considered practically equivalent. "The TOST framework tests whether the true difference falls within a pre-specified equivalence margin (±δ)."
- Exoskeleton Reasoning: A minimal, directed validation scaffold inserted before synthesis to enforce grounded analysis. "Exoskeleton Reasoning inserts a minimal directed validation scaffold before synthesis"
- FACTS Grounding: A benchmark assessing factual accuracy based solely on provided context in long-form responses. "The FACTS Grounding benchmark [1] measures factual accuracy in long-form responses by evaluating whether models can answer questions based solely on provided context without hallucination."
- Factual Grounding: Ensuring answers are strictly derived from the given context rather than the model’s prior knowledge. "factual grounding has remained dominated by large models"
- Few-shot examples: Small numbers of illustrative examples included in prompts to demonstrate desired behavior. "Prompt Structure: Shorter prompts (~500 tokens) with 1-2 few-shot examples (150-200 tokens each)"
- Judge-average: The mean accuracy across multiple independent LLM judges for the same item. "Metric. We follow FACTS: the model's factuality score is the average of the three judges' accuracies on the same items (judge-average)."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank layers into specific modules. "Method: Minimal LoRA fine-tuning (rank=1) for identity awareness, merged into the model after training"
- McNemar test: A statistical test for paired nominal data to detect systematic differences between classifiers. "Per-Judge McNemar Tests (Testing for systematic bias):"
- Meta-cognitive reasoning: Self-monitoring steps where the model evaluates what it knows and how it uses context. "requiring models to engage in explicit meta-cognitive reasoning before generating responses."
- Multi-persona reasoning: Prompting the model to adopt multiple roles or viewpoints to critique and refine reasoning. "introduced multi-persona reasoning and adversarial self-critique"
- Paged optimization: An optimizer implementation that pages parameter blocks to manage memory efficiently during training. "Optimizer: AdamW with paged optimization"
- Permutation p-value: A significance measure obtained by randomly shuffling labels to test the null hypothesis. "Permutation p-value: 0.72 (10,000 shuffles; two-tailed)"
- Process supervision: Supervising intermediate reasoning steps rather than only final outputs to improve reliability. "Prior work on process supervision and structured prompting demonstrates that reasoning scaffolds can guide model cognition."
- Protocol compliance: The model’s ability to consistently follow a specified reasoning and validation procedure. "teaches protocol compliance (epistemic discipline) rather than domain answers."
- QKV projections: The query, key, and value linear transformations in attention mechanisms. "Target modules: self_attn.qkv_proj (query, key, value projections only)"
- RAG (Retrieval-Augmented Generation): Architectures that integrate retrieved documents into generation to improve factuality. "This behavior enables benchmark compliance and trusted RAG systems"
- Reinforcement-learned thinking modes: Inference-time reasoning styles trained via reinforcement learning to enhance accuracy. "Reinforcement-learned 'thinking modes' [5,6] achieve stronger results but require 3-10× computational overhead"
- Self-Refine: A prompting method where models iteratively critique and improve their own outputs. "Chain-of-thought prompting [2], Self-Refine [4], and Tree of Thoughts [3] reveal that models possess latent reasoning capabilities that prompting can surface."
- TOST (Two One-Sided Tests) procedure: A formal equivalence testing framework that verifies differences fall within preset bounds. "Equivalence Testing (TOST Procedure): To formally test equivalence rather than merely absence of significant difference, we apply the Two One-Sided Tests (TOST) procedure"
- Tree of Thoughts: A method that explores multiple reasoning paths in a tree structure before finalizing an answer. "Chain-of-thought prompting [2], Self-Refine [4], and Tree of Thoughts [3] reveal that models possess latent reasoning capabilities that prompting can surface."
- Wilson score interval: A confidence interval for binomial proportions with better coverage near boundaries. "All confidence intervals for accuracy measurements use Wilson score intervals for binomial proportions"
Collections
Sign up for free to add this paper to one or more collections.