- The paper introduces a CPT-SFT-DPO/ORPO pipeline augmented with SLERP-based merging to achieve nonlinear performance gains in domain-specific LLMs.
- It demonstrates that SLERP merging can yield up to 20% improvement on domain benchmarks compared to conventional fine-tuning techniques.
- It highlights the crucial role of data quality and model scale, establishing a threshold for emergent synergistic capabilities in large language models.
Fine-Tuning and Merging LLMs for Domain Adaptation: Scaling, Nonlinearity, and Emergent Capabilities
Introduction
The paper "Fine-tuning LLMs for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities" (2409.03444) systematically interrogates the adaptation of LLMs for specialized technical domains, focusing on biomaterials and materials science as a test case. The authors examine several techniques—continued pre-training (CPT), supervised fine-tuning (SFT), preference optimization strategies (DPO/ORPO), and model merging—and their interactions across model scales. Notably, they identify regimes in which nonlinear model merging (specifically via SLERP) produces merged models with synergistic performance improvements beyond the convex hull defined by the parent models, as well as regimes where this effect vanishes. The work includes comprehensive analysis of data curation, benchmarking protocols, ablations on training dataset quality/size, and multi-modal and agentic capabilities (including image prompt synthesis), with explicit attention to scaling laws and emergent phenomena.
Data Curation and Corpus Structuring
The research implements multi-stage distillation and curation to generate a high-integrity scientific corpus covering raw, distilled, and structured sources (Figure 1). Raw PDFs from targeted scientific domains are processed into formats supporting (a) CPT, (b) SFT over instruction/QA, (c) preference modeling from positive/negative responses, and (d) structured graph/network representations of knowledge. Extraction focuses on concise, lossless transfer of insights and logical structures across scales, enabling downstream training to access not just factual recall but context-linked reasoning and synthesis.
Figure 1: The curatorial pipeline transforms raw text from various sources into QA/instruction-response pairs, and maps scattered data fragments into a consolidated knowledge network.
Training Strategies and Model Merging: Pipeline Structure
The pipeline supports two principal modes (Figure 2): a standard sequential stack (CPT → SFT → preference optimization), and a branched variant augmenting this stack with a merging stage that fuses domain-adapted and general-purpose parent models at different training junctures. The merging protocol is centered on Spherical Linear Interpolation (SLERP), which interpolates in the normalized parameter space of the two models, respecting angular geometry rather than the naive Euclidean linear path (LERP). This approach is mathematically justified to avoid pathological interpolates and experiment traversal through high-loss plateaus, as is common in LERP-based merging.
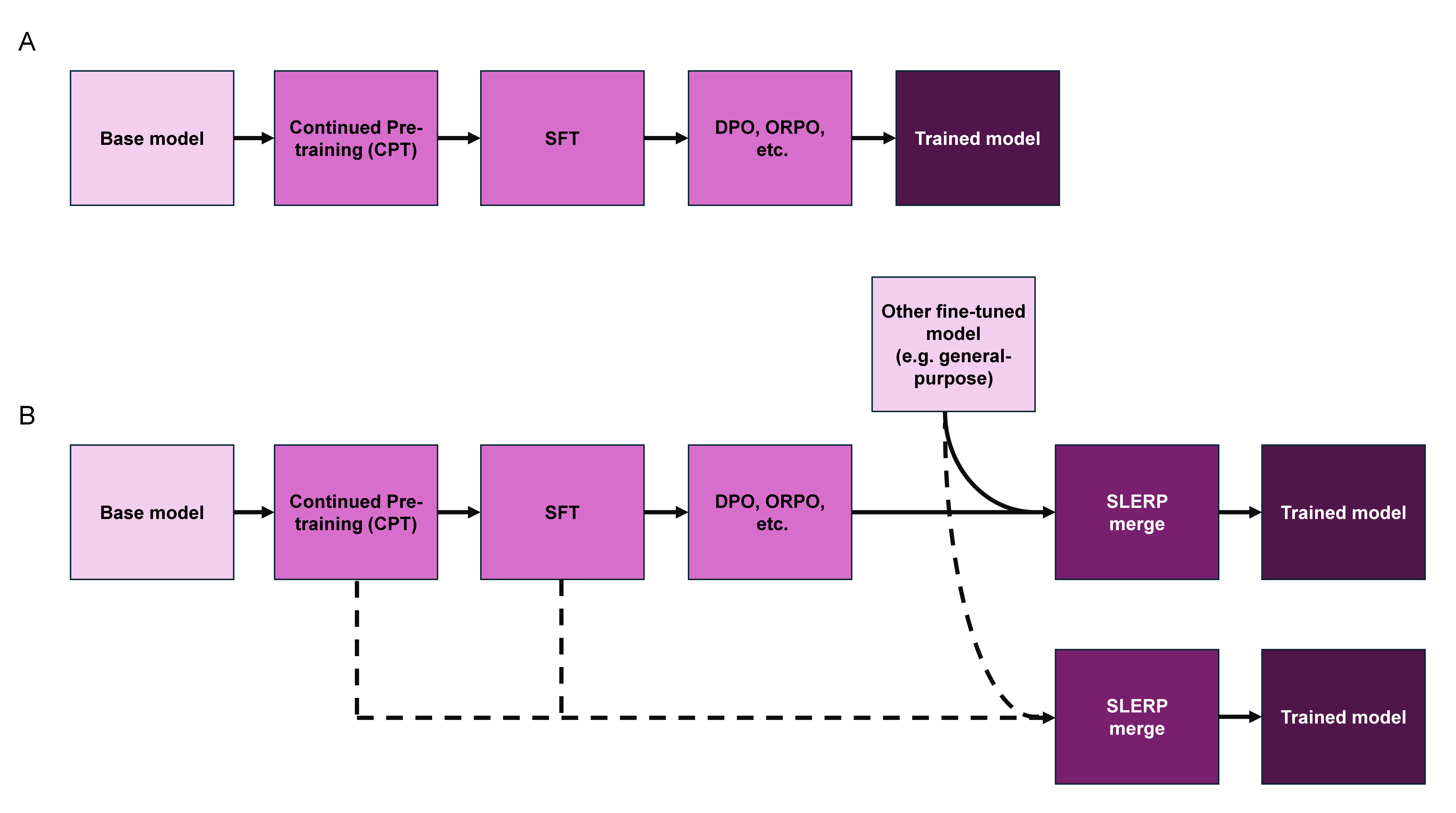
Figure 2: Visual summary of the sequential and merged pipelines, with SLERP-based merging extending classical fine-tuning schemes.
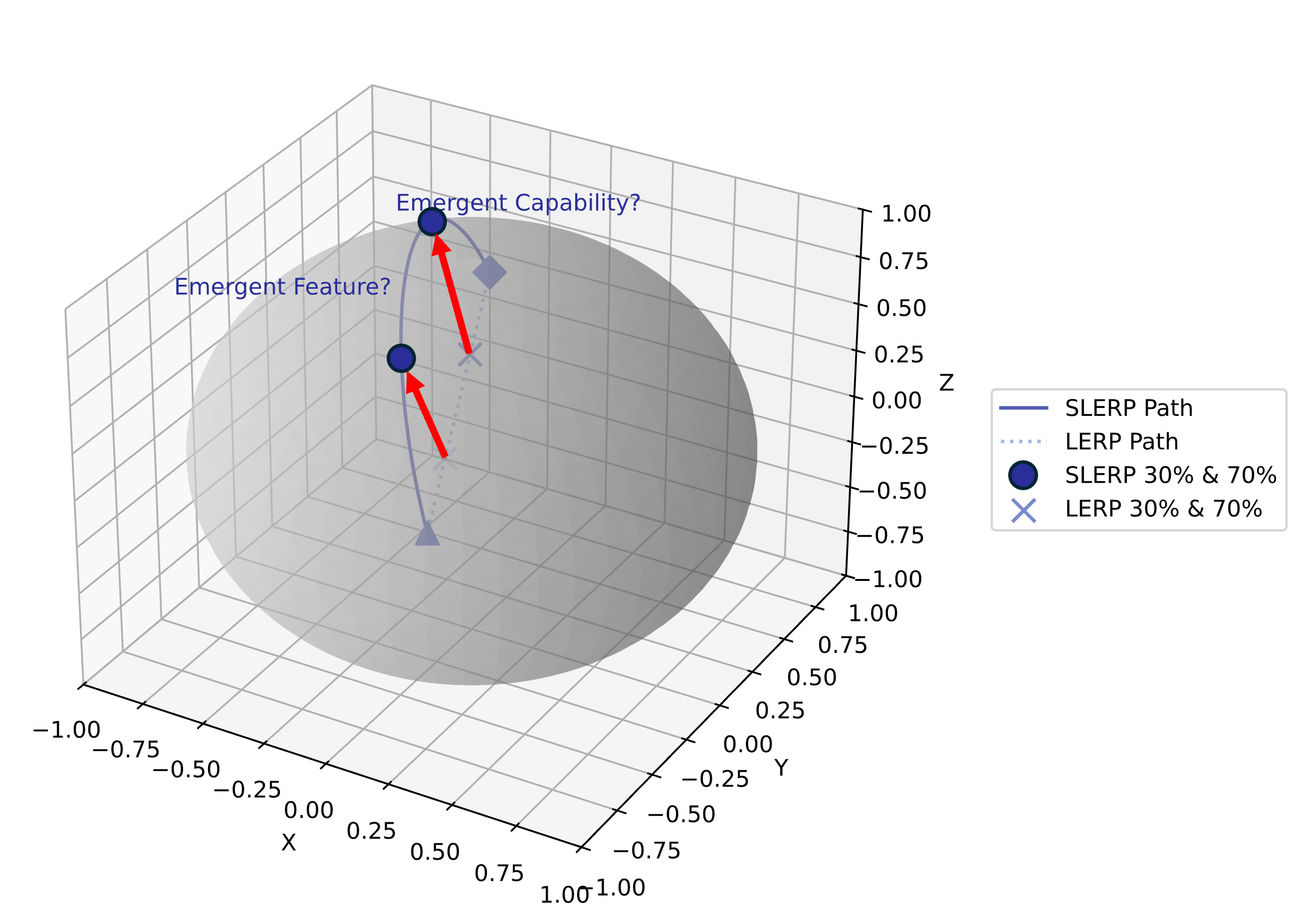
Figure 3: SLERP versus LERP for model parameter interpolation; SLERP traces geodesics on the unit hypersphere, preserving more semantically coherent solutions than direct linear interpolation.
A key outcome is the empirical demonstration of marked nonlinear fitness gains in merged models, specifically in Llama 3.1 (8B) and Mistral 7B variants (Figures 4, 5), when measured on fine-grained, domain-centric benchmarks (e.g., mechanical/biomaterial properties, logic, and scenario-based reasoning). The authors provide explicit evidence that, whereas sequential stacking of CPT→SFT→(DPO/ORPO) often incurs a performance decline relative to strong baseline instruct models (negative relative improvement; see Figure 4B), insertion of a SLERP-based merge with the parent instruct model yields a discontinuous and significant net gain, in some cases exceeding 12% improvement for Llama variants and >20% in Mistral—a non-trivial effect in the competitive 7–8B parameter regime.
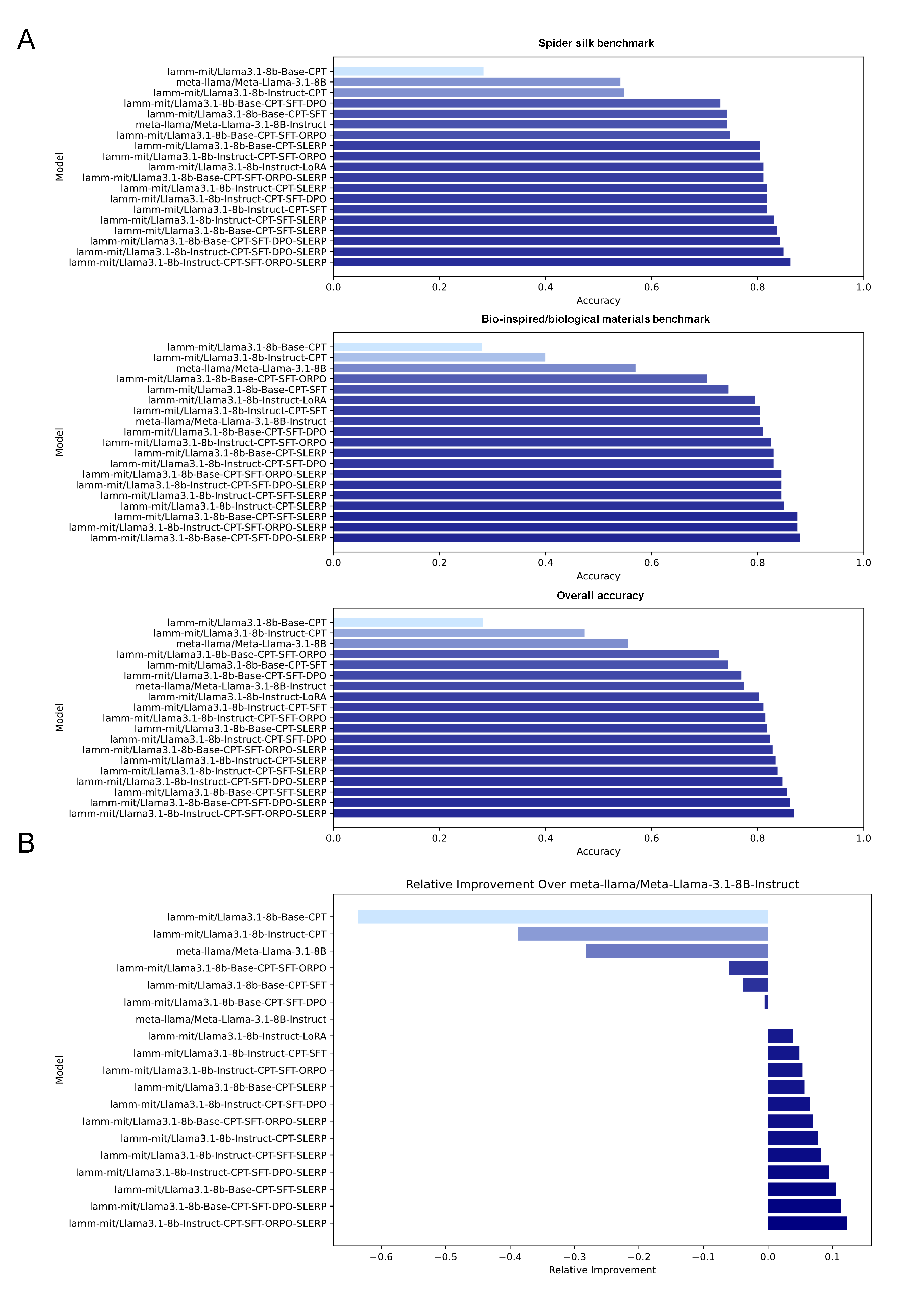
Figure 4: Llama-3.1 performance after each major optimization stage. Note the negative dips for vanilla CPT/SFT/DPO/ORPO, and the subsequent strong positive jump for SLERP-merged models.
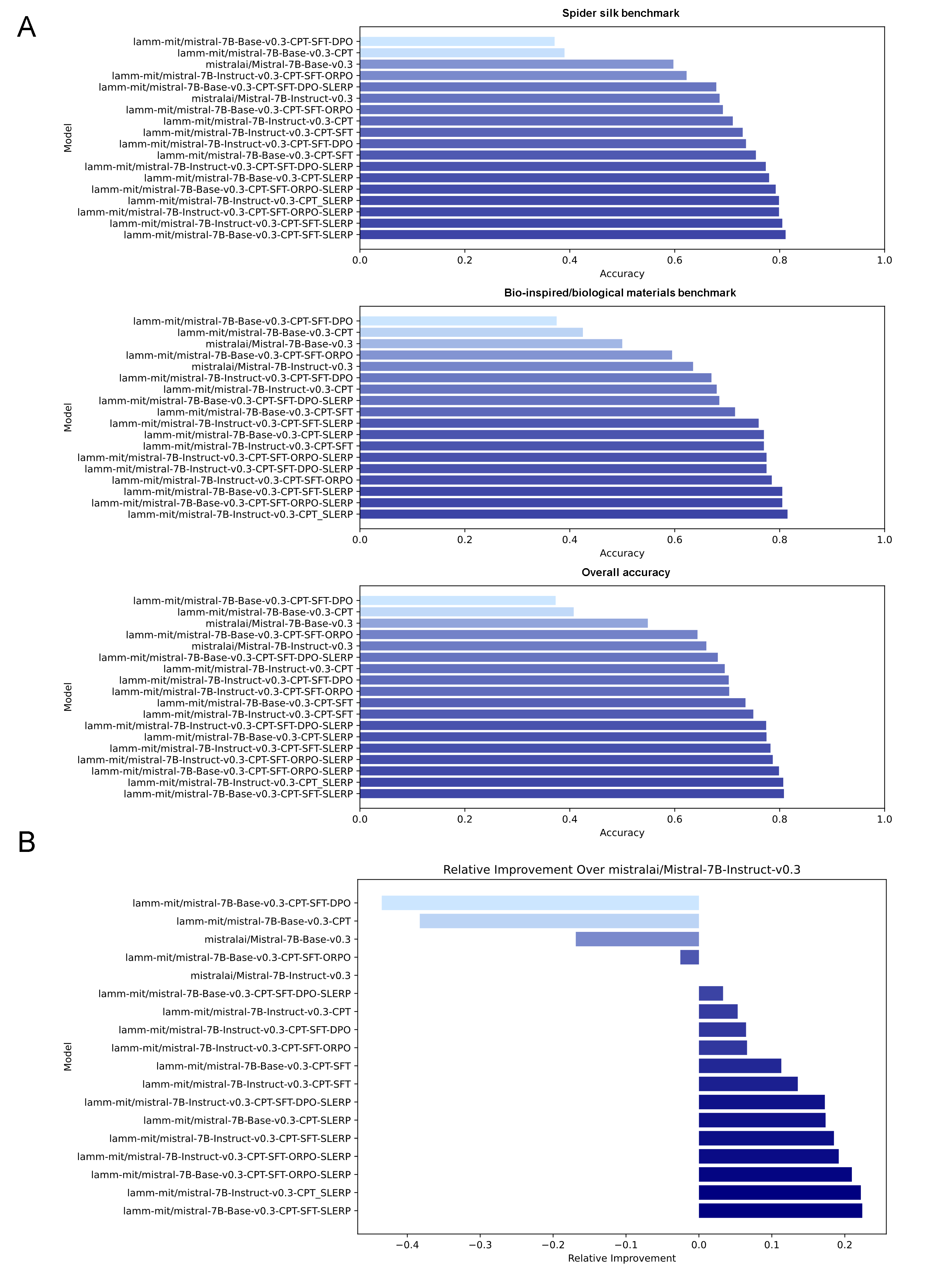
Figure 5: Mistral-7B-v0.3 exhibits even larger performance uplift from model merging, exceeding 20% over the instruct baseline, highlighting architectural responsiveness to merge-based augmentation.
Notably, this improvement is highly nonlinear—merged model fitness often exceeds the linear mean or even the maximum of the parents, especially in scenarios where parent models are instruction-tuned and share moderate alignment in embedding geometry. Regression and clustering analyses (e.g., hierarchical dendrograms, Figure 6) substantiate the distinct grouping of high-performing, merged model lineages versus those using simple transfer, ablation, or LERP interpolation.
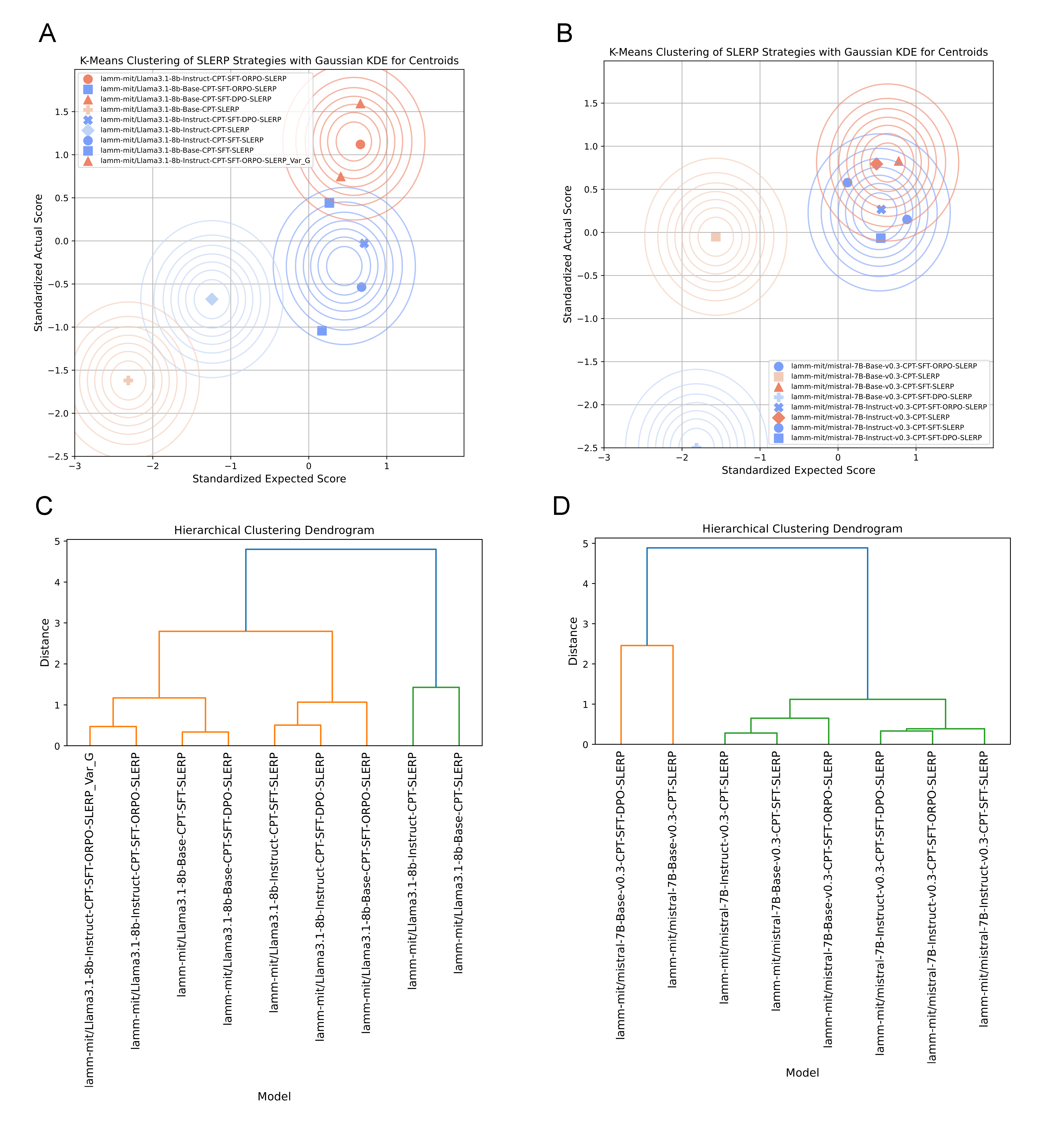
Figure 6: Clustering of model variants reveals that merged, SLERP-optimized models form distinct, high-performing subgroups.
Mechanistic Insights and Scaling Effects
Direct correlation analysis (Figure 7) establishes that SFT and ORPO are the most reliable predictors of performance in the Llama family, while for Mistral, instruction-tuned base models dominate. Merging between parent models with minimal diversity in base architecture or training pathway leads to consistent improvements, whereas excessive divergence correlates with negative merging outcomes—a phenomenon possibly linked to incoherence in parameter-space manifolds.
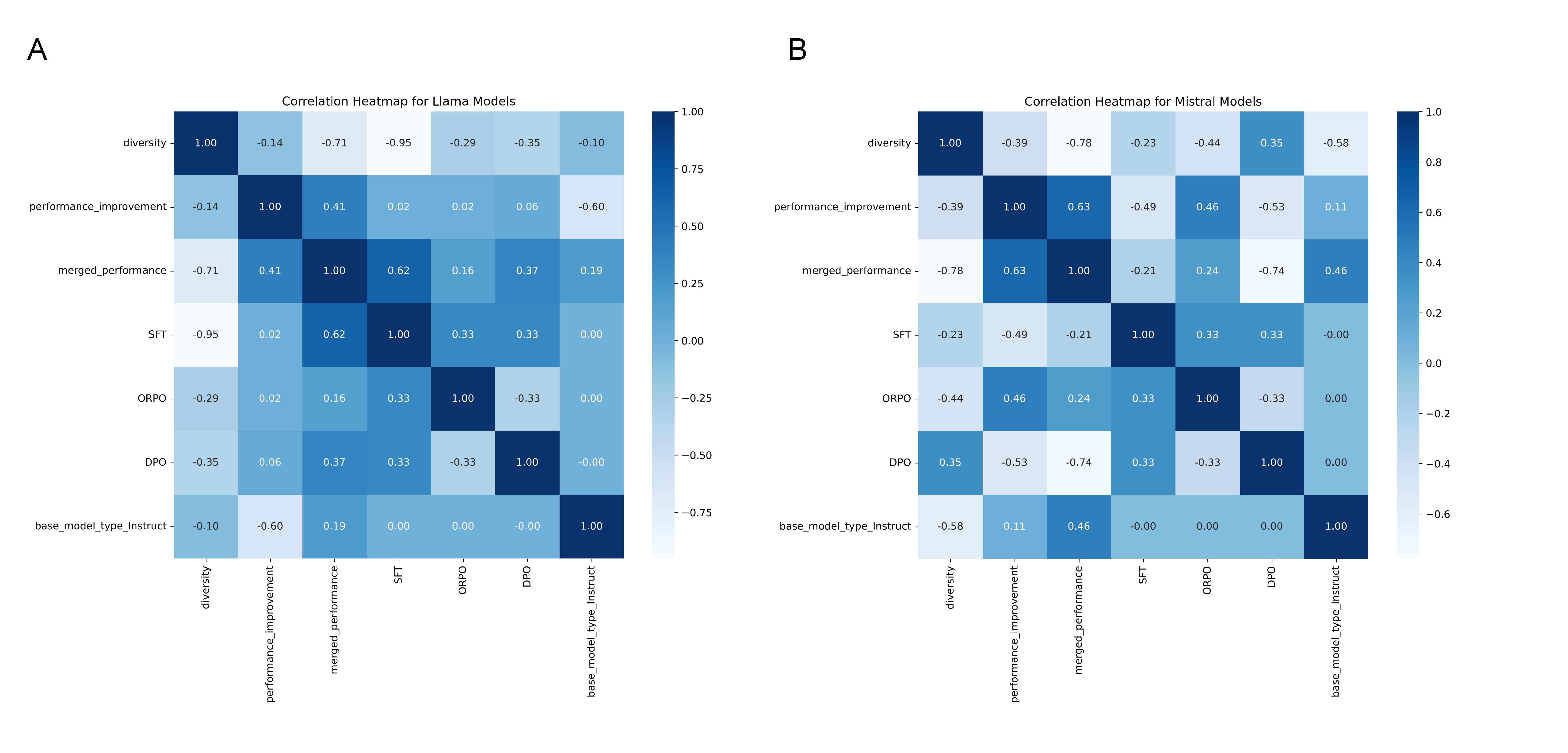
Figure 7: Strong negative correlation of parent model diversity with final merged performance; SFT is most positive in Llama, whereas performance improvements and instruction tuning are more significant in Mistral.
Crucially, the merging-based synergy shows a clear scale threshold: while SLERP merging drives emergent, non-convex gains in 7–8B parameter models, the effect disappears in "small" LLMs (SmolLM-1.7B). Figure 8 documents that for SmolLM, advanced merging yields at best parity with the best parent, and often a degradation. This is a bold, model-scale-dependent claim on the boundaries of model ensembling and synergy, and intuitively supports the view that only sufficiently overparameterized models exhibit the high-dimensional nonlinear structure necessary for SLERP's emergent benefit.
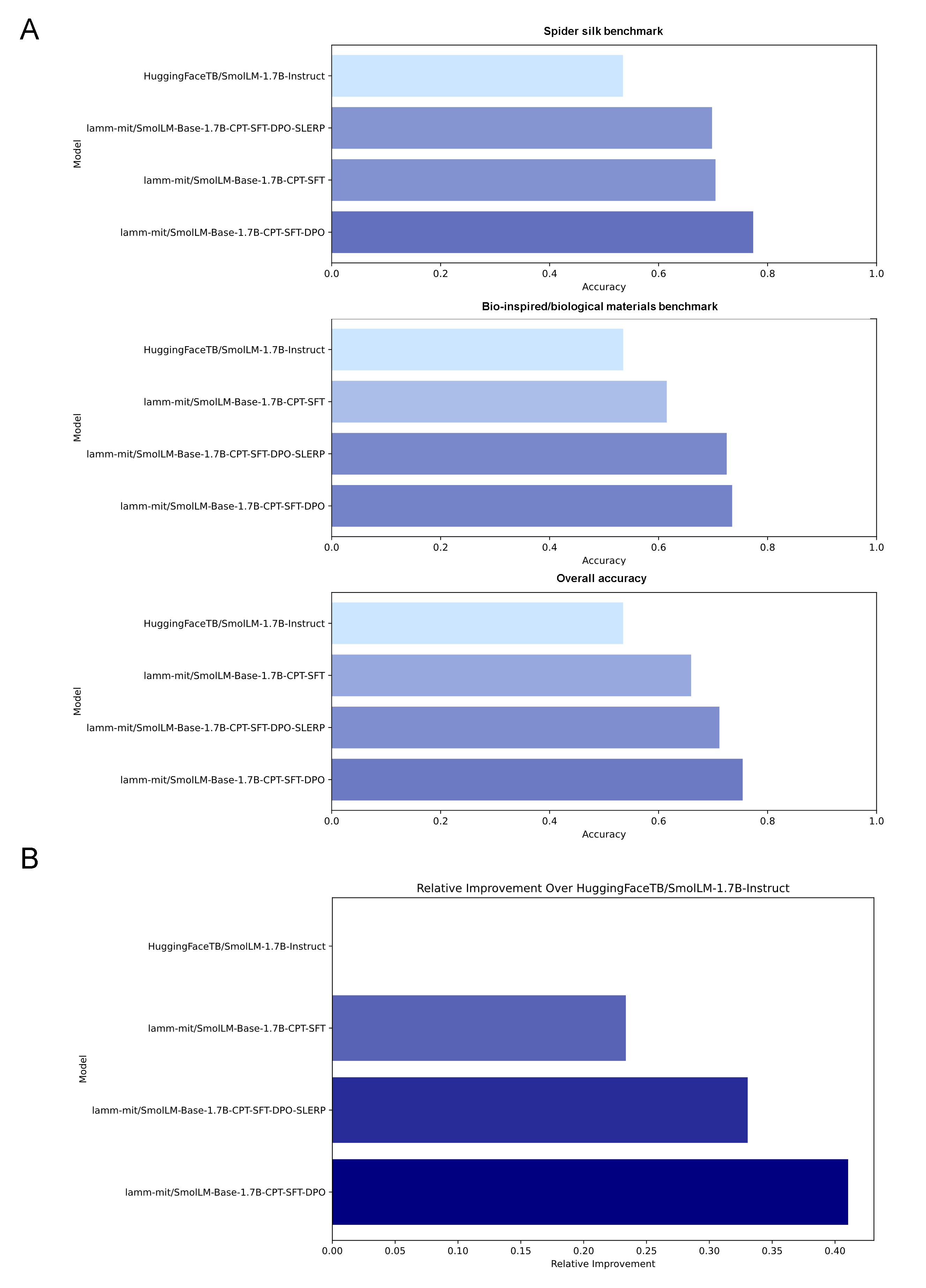
Figure 8: SmolLM (1.7B) fails to yield performance gains through model merging, indicating a threshold effect for emergent synergy in LLM parameter space.
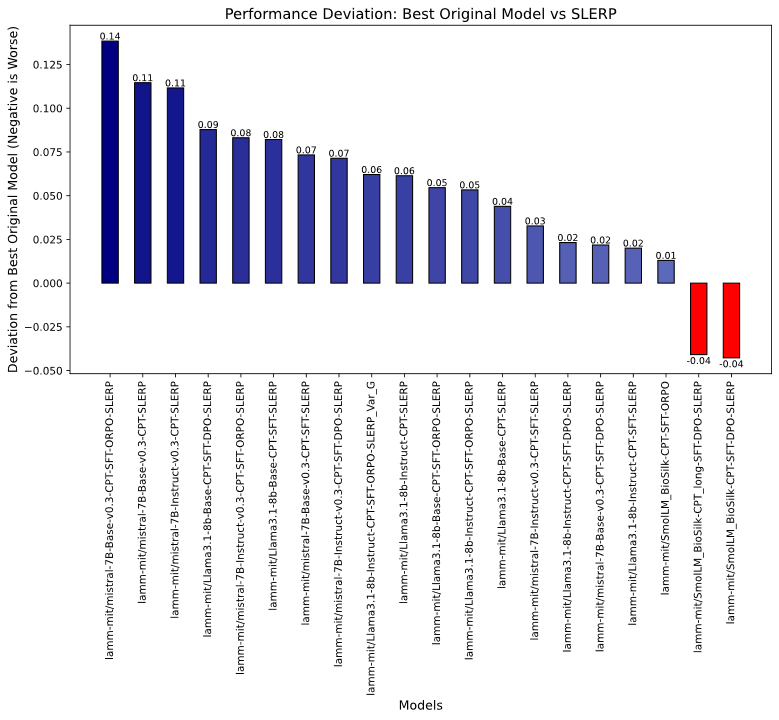
Figure 9: Quantification of synergy/deficit—SLERP merging outperforms best parents in large models (blue), but underperforms in the smallest models (red).
Sensitivity to Data Quality, Composition, and Training Details
Scaling up the raw scientific corpus does not guarantee improved performance. Figure 10 demonstrates that inclusion of additional, lower-quality text in CPT can cause a measurable decline in downstream accuracy. The pipeline thus emphasizes not only data volume but stringent importance of data quality and relevance, especially in low-resolution or OCR-processed corpora common in scientific literature.
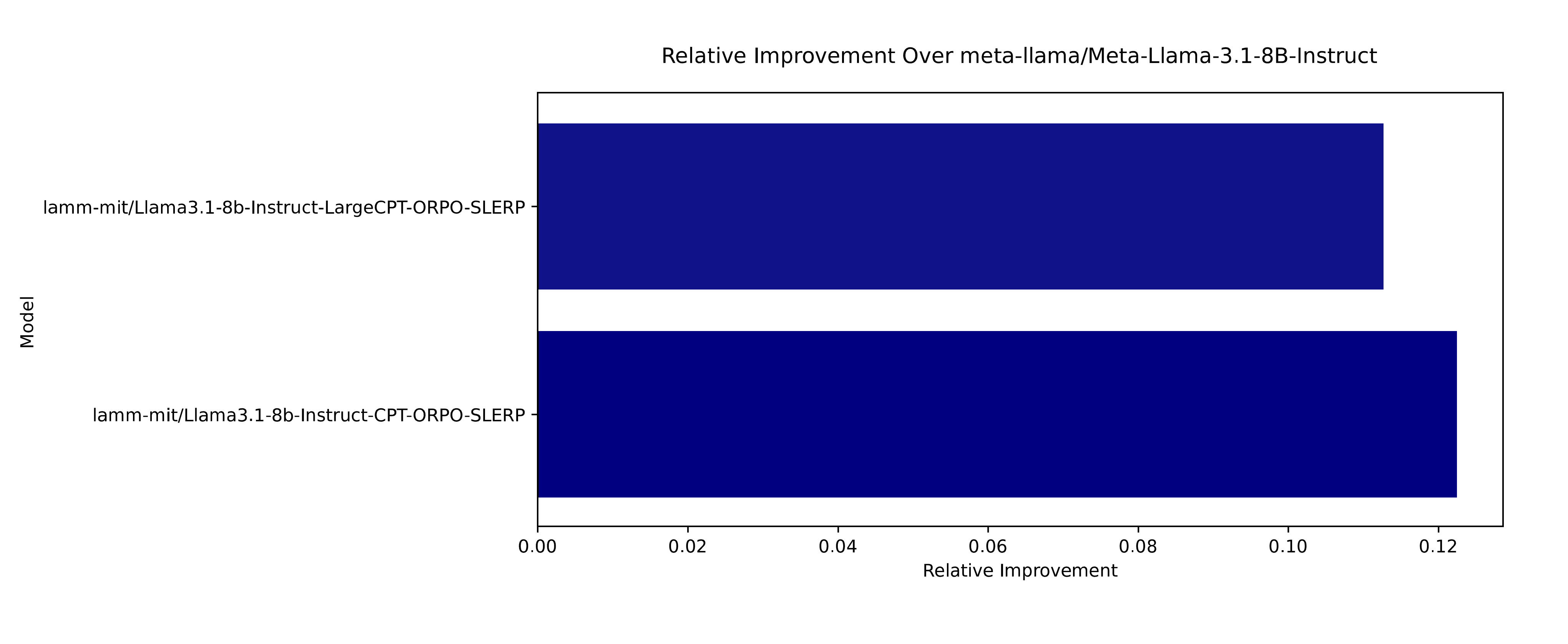
Figure 10: Larger, noisier CPT datasets can reduce performance, underlining the need for high-purity domain-specific data in CPT for optimal downstream gains.
Further, the choice of merge ratios and per-layer parameter blending is nontrivial (Figure 11); simple linear progressions across depth can outperform more complex schemes, and strongly interact with the specific transformer architecture or alignment tuning protocol.
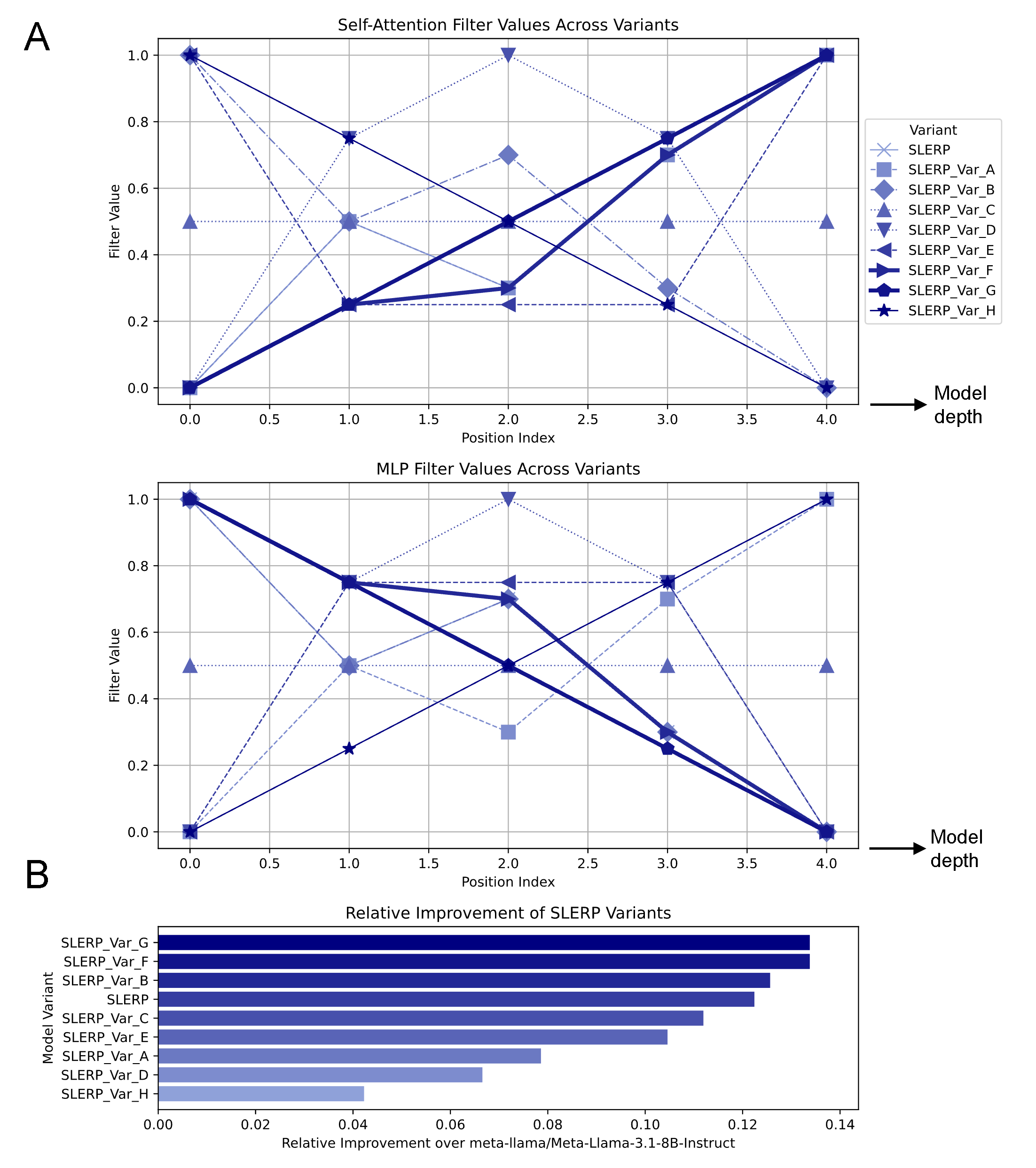
Figure 11: Layerwise blending schemes in model merging impact the realized synergy, with simple monotonic weighting sometimes outperforming more complex variants.
Agentic and Multimodal Applications
The authors also present multi-turn dialog evaluations and autonomous prompt synthesis for multimodal image generation (Figures 14–16). Large, merged LLMs are shown to excel not only at technical reasoning but at integrating disparate biomimetic concepts into actionable coherent prompts for vision models. Smaller models (SmolLM-1.7B), despite limitations in cross-domain emergent capability, can be highly creative and exhibit strong performance in language understanding and structured output within the constraints of their parameterization.

Figure 12: Image prompt generated by SmolLM-Base-1.7B-CPT-SFT-DPO produces biomimetic structures for architectural design.

Figure 13: Mistral-7B-derived model producing intricate, leaf-inspired bio-architectures with multi-domain feature integration.

Figure 14: Urban-scale design synthesis via LLM-guided, cross-domain prompt engineering.
Scaling Laws and Diminishing Returns
Empirical scaling analyses (Figures 18 and 19) reveal that, while absolute task accuracy increases with both model and dataset size, the marginal improvement of additional data or parameter count diminishes. Small models (1.7B) obtain the largest relative percentage upgrades from fine-tuning, but only large models (>7B) can leverage merging-induced synergies.
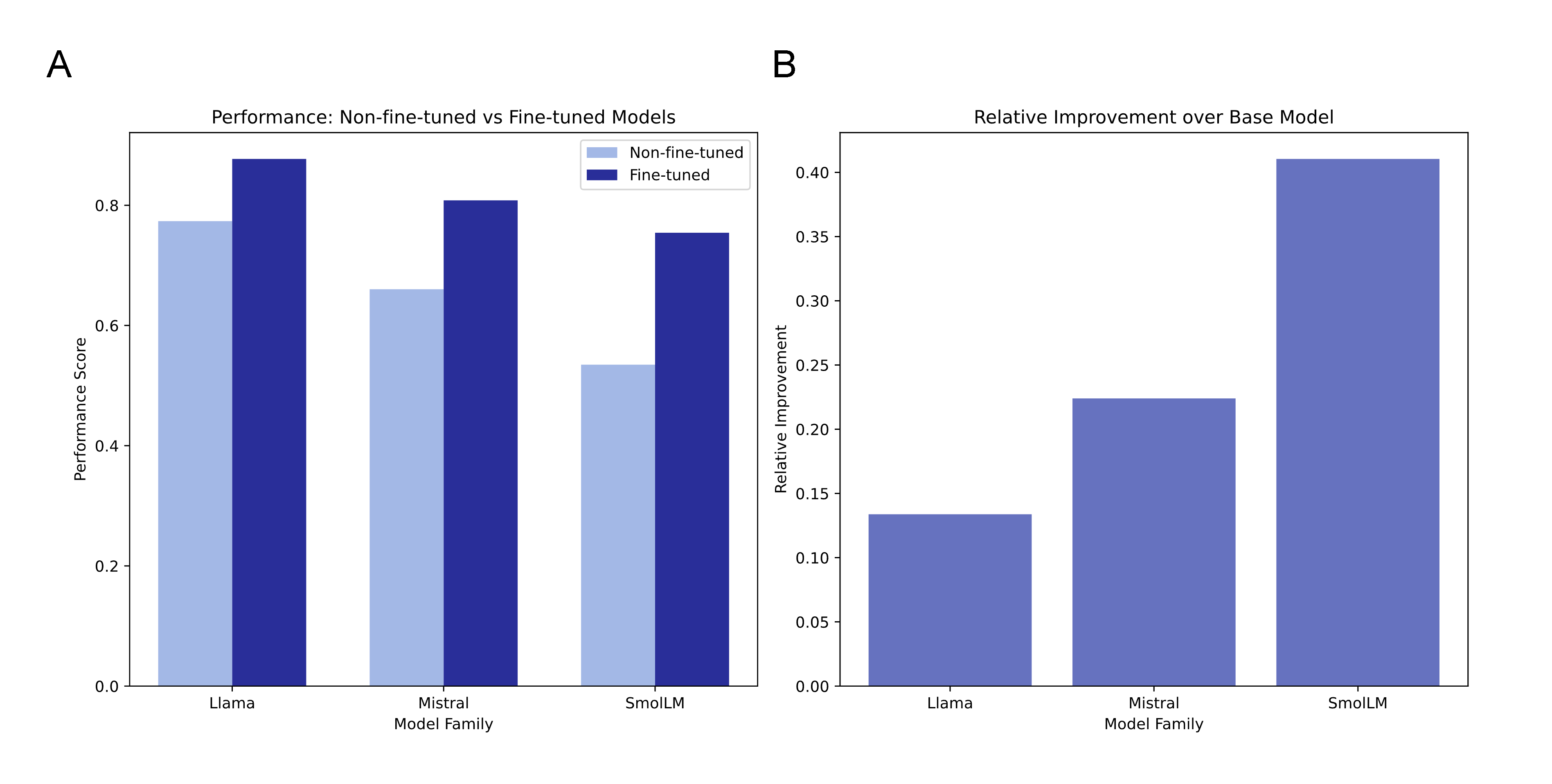
Figure 15: Relative and absolute gains from fine-tuning scale sublinearly with model size; SmolLM achieves the largest percentage uplift due to low baseline.
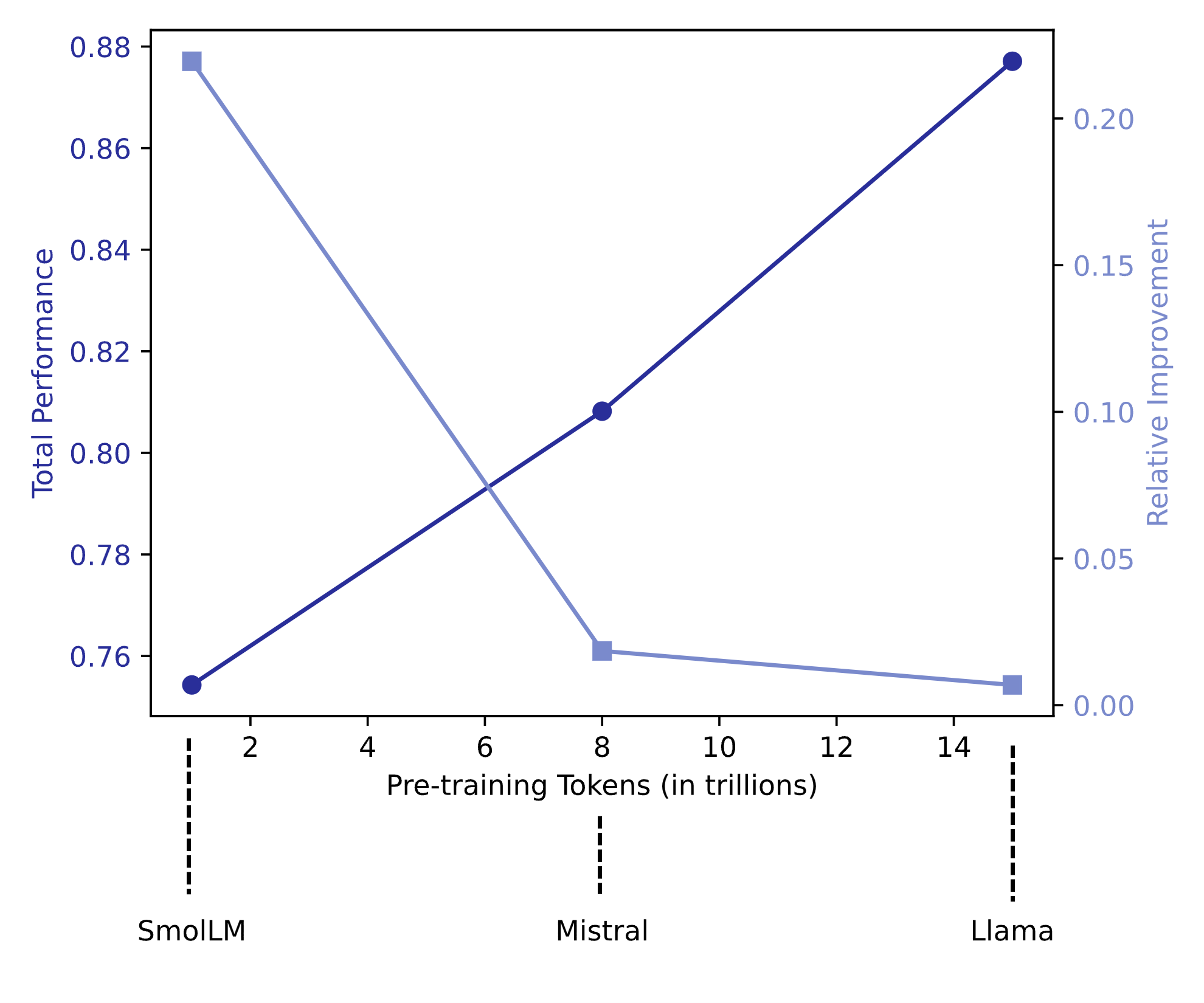
Figure 16: Pretraining corpus size and absolute best performance scale positively, but marginal gain falls off rapidly at the highest resource levels.
Discussion and Implications for Future AI System Design
Nonlinear Model Merging as a Tool for Emergence: The study substantiates that parameter-space geometry in sufficiently large LLMs supports constructive nonlinear superposition of behaviors and skills via spherical merging strategies. This observation has major implications for ensemble learning, parameter-efficient adaptation, and rapid domain shift without full retraining.
Limits of Parameter Interpolation and Diversity: Merging is only beneficial below a certain diversity threshold in the parameter or loss surface manifold. Excessive heterogeneity leads to destructive interference or incoherent interpolation, an observation with practical significance for model portfolio management and federated learning scenarios.
Scale Thresholds for Emergence: Explicitly demonstrated is the absence of synergy for sub-2B parameter LLMs, providing a lower bound on the parameter redundancy or expressivity needed for emergent property realization. This further supports the scaling laws previously conjectured and has direct applications in model selection for resource-constrained environments.
Pipeline Prescriptions: The CPT→SFT→Preference→SLERP pipeline is validated as the most robust paradigm for extracting high-fidelity, domain-specialized models from generic base weights. However, the utility of each stage is model-dependent, with SFT being most critical for Llama and instruction tuning for Mistral, and with ORPO/DPO potentially providing further alignment in human-preference-sensitive applications.
Data Quality over Quantity: Overly aggressive inclusion of low-quality, noisy, or misformatted scientific text can degrade target performance, underscoring the need for refined, multi-stage data processing and distillation even as pretraining scales upward.
Agentic and Multimodal Synergies: LLMs can effectively serve as agents orchestrating complex design tasks, translating technical requirements into actionable prompts for cross-modal pipelines—an essential capacity for future AI systems co-optimizing across language, vision, simulation, and design.
Conclusion
This paper provides an explicit demonstration of nonlinear emergent synergy from model merging in the large-parameter LLM regime and delineates the boundaries—architectural, training, and data-related—where such gains materialize. The findings favor SLERP-based merging as a robust lever for rapid domain adaptation without full retraining, provided the merge partners exhibit sufficient alignment and scale. These results impact strategies for ensemble construction, continual learning, domain transfer, and agentic multi-modal AI systems, and call for further investigation into the topological and geometric aspects of LLM weight space, the limits of scaling, and the interplay between model structure, data curation, and emergent capacity.
Figure 17: Large-scale, high-purity scientific corpus assembly—a foundation for high-fidelity domain adaptation and reasoning in LLMs.