- The paper introduces a visual representation alignment method that anchors mid-level VLA features to stable teacher embeddings, preserving semantic integrity and boosting OOD generalization.
- It employs a visual alignment loss during fine-tuning to maintain object-centric attention and mitigate representation collapse.
- Evaluated on the VL-Think Task Suite, the method outperforms standard fine-tuning in vision, semantic, and action tasks.
Aligning Visual Representations for OOD Generalization
Introduction
The paper "Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization" (2510.25616) addresses the preservation and enhancement of visual-language understanding within Vision-Language-Action (VLA) models when adapted for action tasks. These models initially leverage Vision-LLMs (VLMs) that integrate visual and linguistic data to enable cross-modal understanding. The transition from VLMs to VLAs, primarily aimed at action tasks, often results in the deterioration of these integrated capabilities, specifically visual representation integrity. The authors propose methods to maintain and improve these representations, thereby enhancing out-of-distribution (OOD) generalization.
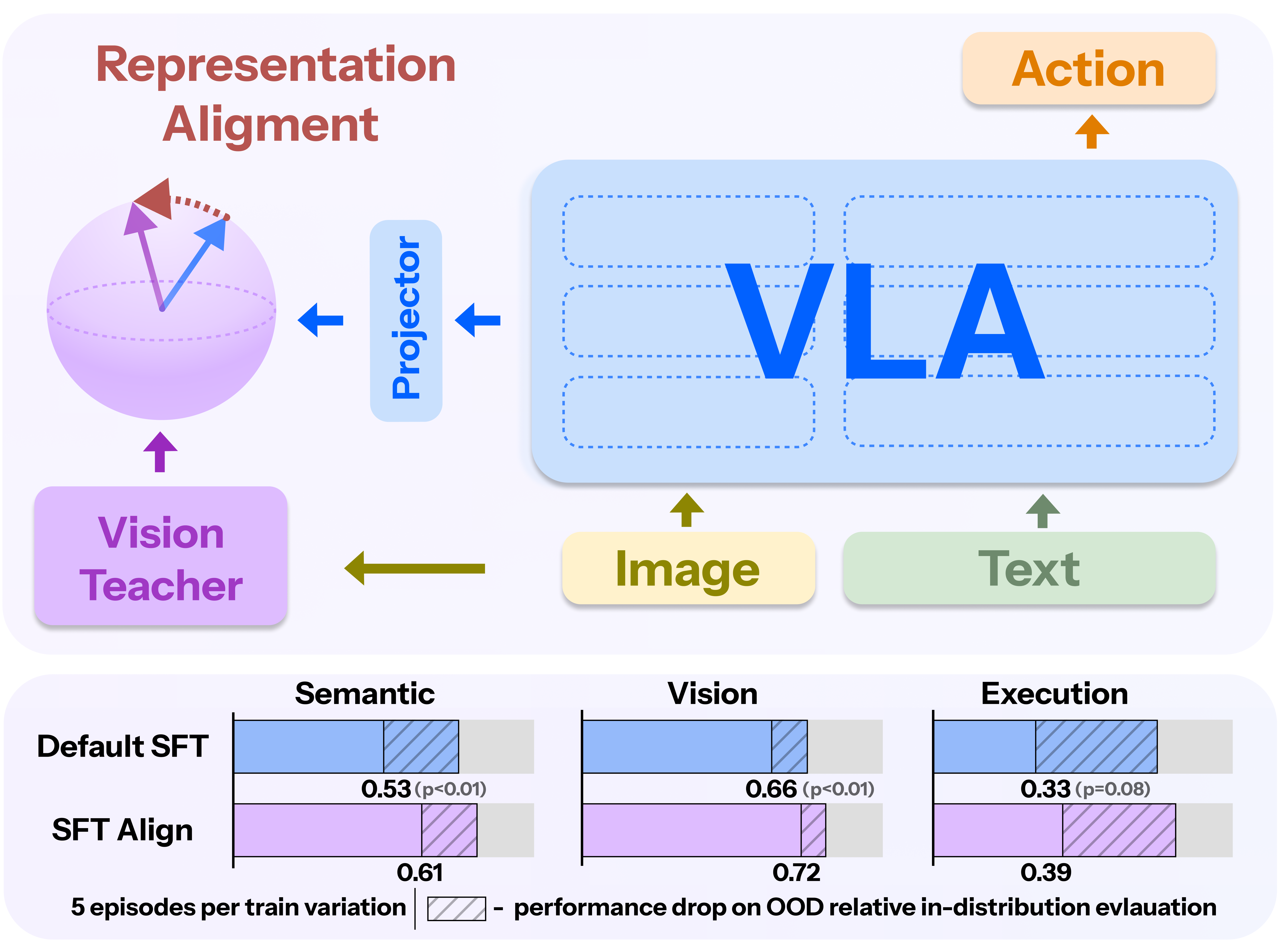
Figure 1: Visual alignment method overview. Mid-level VLA features are projected onto a normalized sphere and aligned with teacher embeddings, preserving visual semantics and improving OOD generalization.
Methodology
The core technique proposed involves a Visual Representation Alignment strategy. This approach seeks to anchor the VLA model's visual representations to a pretrained vision model’s stable, generalized visual features. The motivation stems from the Platonic Representation Hypothesis, which posits convergence of high-performing models to shared latent representations. This is operationalized by aligning mid-level VLA features with teacher model embeddings, thereby maintaining semantic integrity and reducing representational drift during fine-tuning.
Figure 2: Overview of the proposed method. The training pipeline incorporates visual alignment loss with precomputed teacher features, preserving vision-language understanding.
VL-Think Task Suite
To evaluate the effectiveness of VL representation retention, the paper introduces the VL-Think Task Suite. This set of tasks gauges the transfer of VL skills to VLA models post-finetuning, focusing on semantic comprehension beyond pure action execution. Tasks are designed to assess understanding of shapes, colors, symbols, and categories, reflecting the core semantic grounding typical of large-scale VLM pretraining but often eroded in task-specific VLA fine-tuning.

Figure 3: VL-Think Task Suite examples highlight tasks testing object matching based on instructed concepts.
Results
Experiments demonstrate that the proposed alignment method outperforms standard fine-tuning on several axes of generalization, notably in Vision, Semantic, and Execution tasks. Noteworthy is the alignment's success in preserving attention integrity, as shown in attention map analyses where object-centric focus is recovered, demonstrating marked improvement over naive fine-tuning.
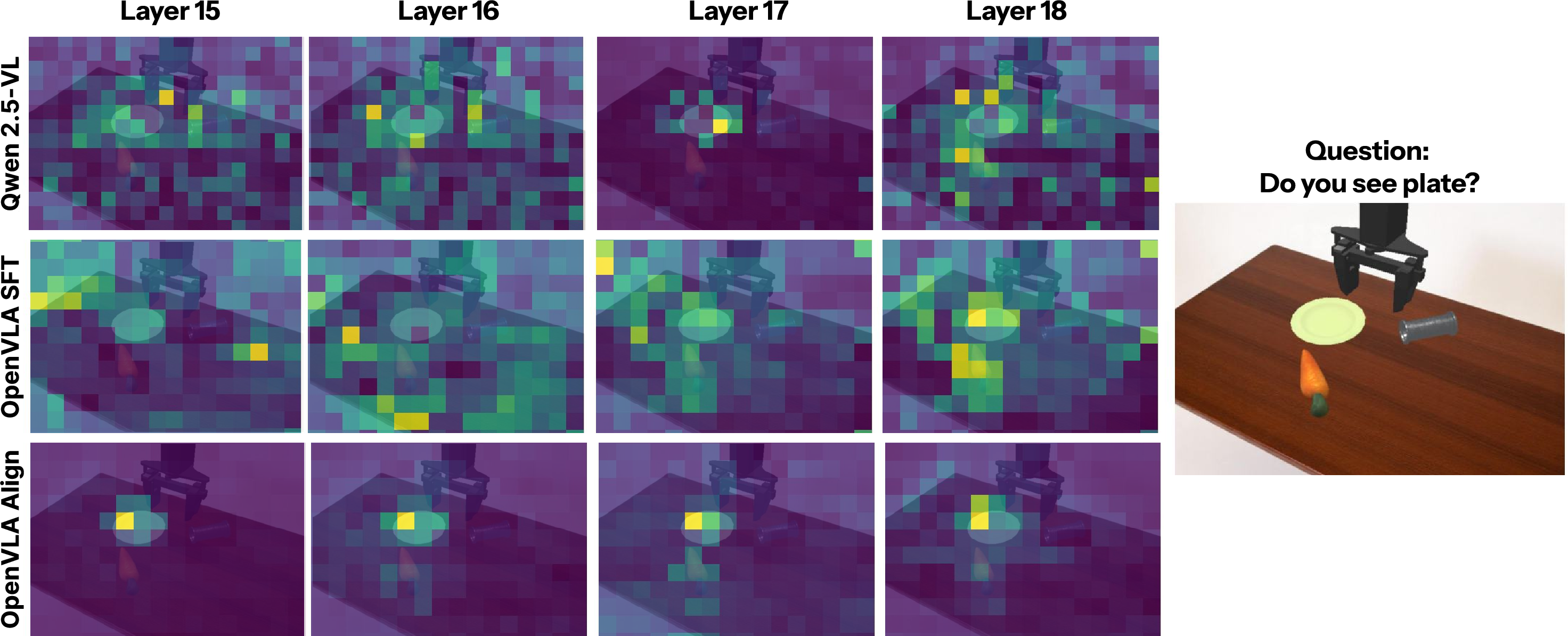
Figure 4: Attention map comparison shows the superiority of aligned models in maintaining object-centric focus within attention maps compared to default fine-tuning.
Additionally, t-SNE visualizations of token embeddings indicate that the alignment strategy effectively mitigates representation collapse, a common issue in unaligned models.
Figure 5: t-SNE visualization of token embeddings showcases clear class separability post-alignment, unlike the overlap seen in naive fine-tuning.
Discussion
The findings underscore the importance of visual-language alignment during the VLA adaptation process. The successful alignment method effectively balances action fine-tuning with preservation of embedded semantic knowledge. This balance not only preserves VL understanding but enhances the model's robustness to domain shifts unknown during initial training. Future directions could involve broader dataset diversity and parameter-efficiency relaxing, which could refine alignment strategies further and extend their applicability across varied VLA tasks.
Conclusion
This work provides a significant step towards addressing representational degradation in VLA systems. Through the Visual Representation Alignment method, the paper offers a lightweight yet effective tool for reinforcing the visual-language grounding necessary for OOD generalization. These insights are essential for developing VLA models that maintain semantic fidelity and functional robustness in dynamic, real-world environments.