- The paper demonstrates that VLMs, despite retaining high-quality visual representations, suffer significant performance drops on vision-centric tasks due to poor LLM integration.
- It evaluates performance using benchmarks like CV-Bench, BLINK, and MOCHI, showing that prompt tuning offers minimal improvements.
- Fine-tuning the LLM component markedly improves performance, underscoring the integration bottleneck between visual and language representations.
Analysis of "Hidden in plain sight: VLMs overlook their visual representations"
Introduction
The paper "Hidden in plain sight: VLMs overlook their visual representations" addresses a critical issue in Vision-LLMs (VLMs), which are supposed to integrate visual and linguistic information effectively. Despite their impressive performance on tasks requiring language knowledge, they fail on vision-centric tasks by a significant margin compared to standalone vision encoders. This paper explores the reasons behind these discrepancies, analyzing the quality of vision representations, prompt sensitivity, and the LLM's efficacy in leveraging visual information.
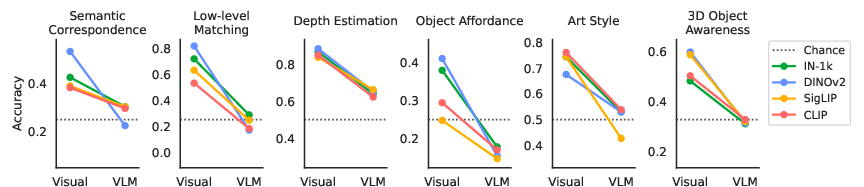
Figure 1: Comparing standard visual evaluation to VLMs across vision-centric tasks, indicating a performance drop to chance-level accuracies in VLM evaluation.
Evaluation and Analysis
The core issue identified is the "visual to VLM performance drop" where tasks solvable by vision encoders become challenging for VLMs, often resulting in performance near random chance levels. This significant decrease indicates that VLMs are failing to utilize the visual representations effectively within their architectures, which points to an integration issue rather than a lack of representational power in vision encoders.
Vision-Centric Tasks
The study focuses on evaluating VLMs across several vision-centric tasks sourced from benchmarks CV-Bench, BLINK, and MOCHI. The tasks are carefully chosen to isolate the vision capability from language knowledge, thus focusing on aspects like depth estimation, visual correspondence, and object affordance.

Figure 2: Finetuning the LLM offers the most significant performance increase across various tasks, highlighting the LLM's role as a bottleneck in VLM performance.
Analysis of Limitations
Three primary areas of limitations in VLMs were identified:
- Quality of Vision Representations: Despite transformations within the VLM architecture, vision representations do not degrade and retain useful information.
- Prompt Sensitivity: The performance gained from prompt tuning is minimal, suggesting that prompt formulation is not the primary issue.
- LLM Integration: The paper highlights the LLM's inability to effectively leverage vision representations as the most significant bottleneck. Fine-tuning the LLM shows notable improvements, indicating its role as a limiting factor.
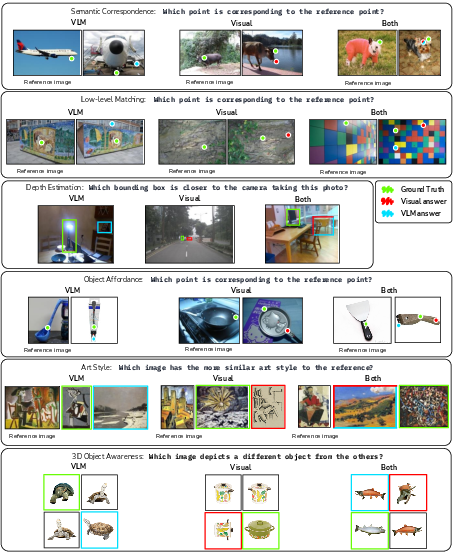
Figure 3: Common failure modes for both evaluation strategies; for instance, small objects are challenging to encode in high fidelity.
Conclusion
The paper sheds light on a critical oversight in the design of VLMs, specifically their failure to leverage vision encoders adequately. It underscores a misalignment between vision and language components, suggesting future work should focus on improving this integration to achieve better performance on vision-centric tasks.
Ultimately, while VLMs show promise in using language as an interface for visual tasks, this research urges caution in interpreting their abilities through language-focused evaluations alone. Addressing these integration challenges could lead to more robust VLM systems capable of effectively handling vision-centric tasks alongside their linguistic competencies.

