- The paper introduces DAEDAL, a training-free variable-length denoising strategy that dynamically adapts sequence lengths using model confidence signals.
- It leverages an initial short, fully masked sequence and iterative mask insertion to refine outputs during the diffusion process.
- Experiments on LLaDA-Instruct-8B demonstrate enhanced computational efficiency and improved response quality over fixed-length baselines.
Beyond Fixed: Training-Free Variable-Length Denoising for Diffusion LLMs
Introduction
Diffusion LLMs (DLLMs) have emerged as a significant alternative to Autoregressive LLMs, mainly due to their efficient parallel generation and comprehensive global context modeling. Yet, DLLMs face a critical constraint: the necessity for a statically predefined generation length. This limitation imposes an unsatisfactory trade-off between computational efficiency and task performance. The paper introduces DAEDAL, a novel, training-free denoising strategy aimed at Dynamic Adaptive Length Expansion for DLLMs, eliminating the need for static length predefined at inference time.
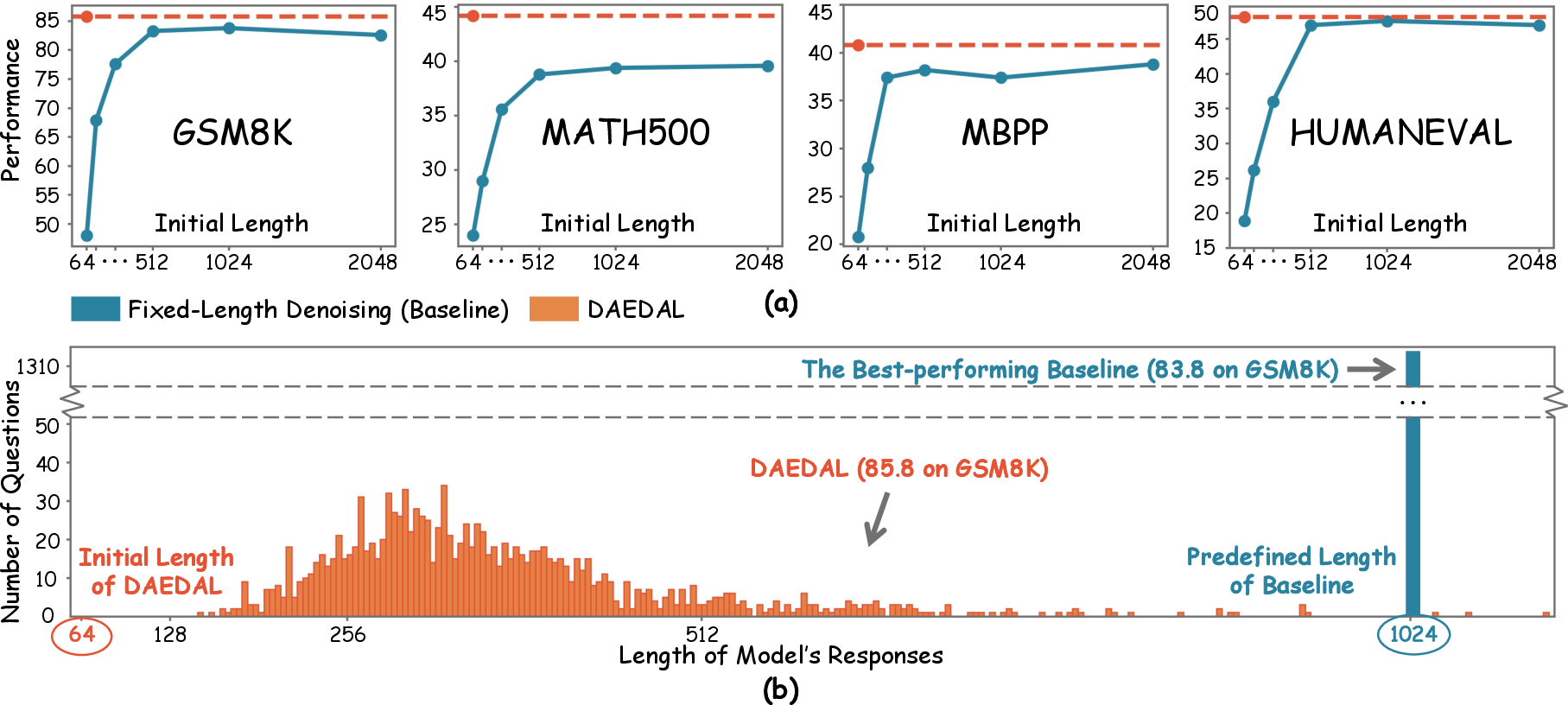
Figure 1: Overview of DAEDAL's effectiveness on LLaDA-Instruct-8B. (a) DAEDAL uses a unified and short initial length, consistently surpassing the baseline, which needs its length meticulously tuned for each benchmark to achieve peak performance. (b) DAEDAL dynamically adjusts length and adaptively expands on a per-problem basis, resulting in a varied distribution of response lengths. In contrast, the baseline is constrained to a fixed length for all problems.
Methodology
Diffusion LLMs Overview
DLLMs leverage a diffusion-based denoising process utilizing bidirectional attention to generate text from a masked initial sequence into coherent outputs. Unlike autoregressive models, DLLMs start from a fixed-length, fully masked sequence, resulting in a rigid inference process without length adaptability. This limitation is problematic, as it prevents dynamic test-time scaling, which autoregressive models excel at.
DAEDAL Mechanism
DAEDAL consists of two primary phases:
- Initial Length Adjustment: It begins with a short initial length, relying on the model's confidence in predicting an End-of-Sequence (EOS) token to guide expansion. Visualization of average EOS token confidence after the first prediction on fully masked sequences forms the basis for task-specific length adequacy assessment.
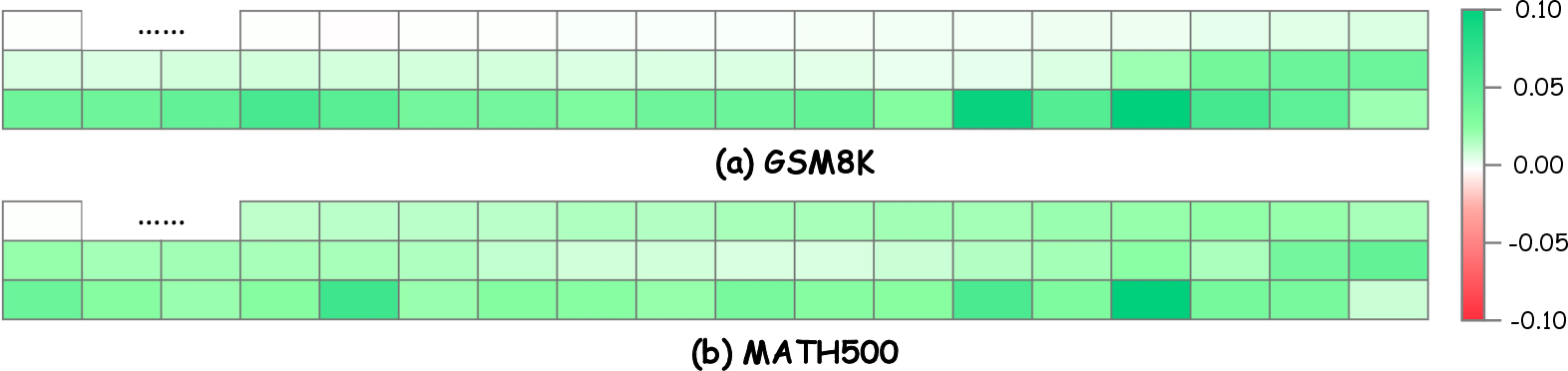
Figure 2: Visualization of the DLLM's awareness of length sufficiency. The heatmaps show the difference in average EOS token confidence at the sequence terminus, measured after the first prediction on a fully masked 128-token input.
- Iterative Mask Insertion: During the denoising process, DAEDAL dynamically expands sequences at positions indicating low prediction confidence. This is an on-demand local refinement, allowing dynamic length adaptation during generation to cater to complex reasoning requirements.
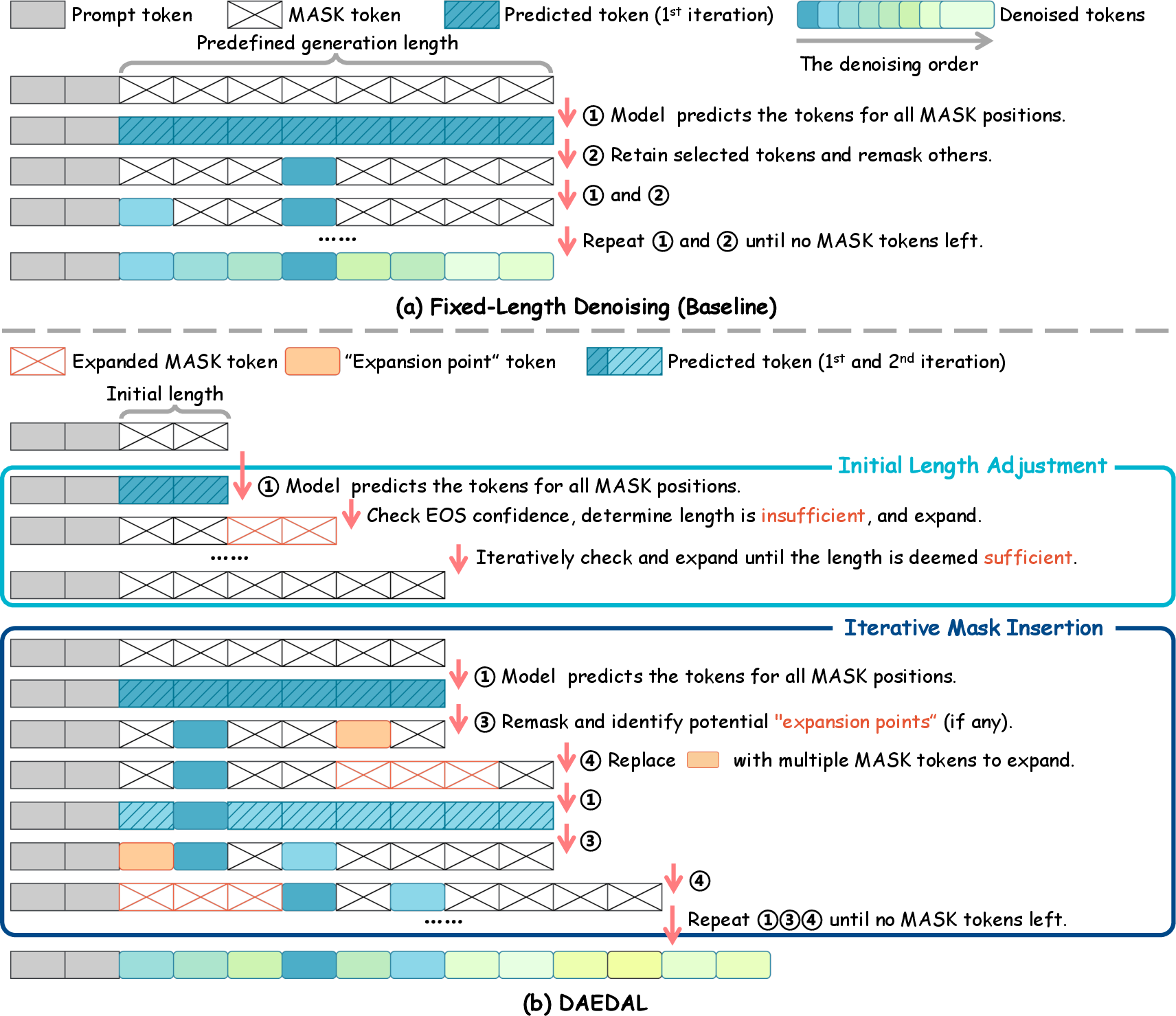
Figure 3: Inference process of Fixed-Length Denoising (Baseline) and DAEDAL. (a) The standard inference process for current DLLMs, which performs iterative denoising on a sequence of a predefined, static length. (b) Our proposed two-stage inference process.
Experiments and Results
The experiments were conducted using LLaDA-Instruct-8B, with DAEDAL displaying a superior capability to adapt lengths dynamically compared to baseline methodologies. The performance analysis included multiple benchmarks, showing DAEDAL's capability to surpass statically fixed baselines while improving computational efficiency and effective token utilization.
The experiments conclusively demonstrated the advantage of DAEDAL in allocating task-appropriate length, as represented by a diverse length distribution, which is more aligned with task complexities than fixed-length baselines.
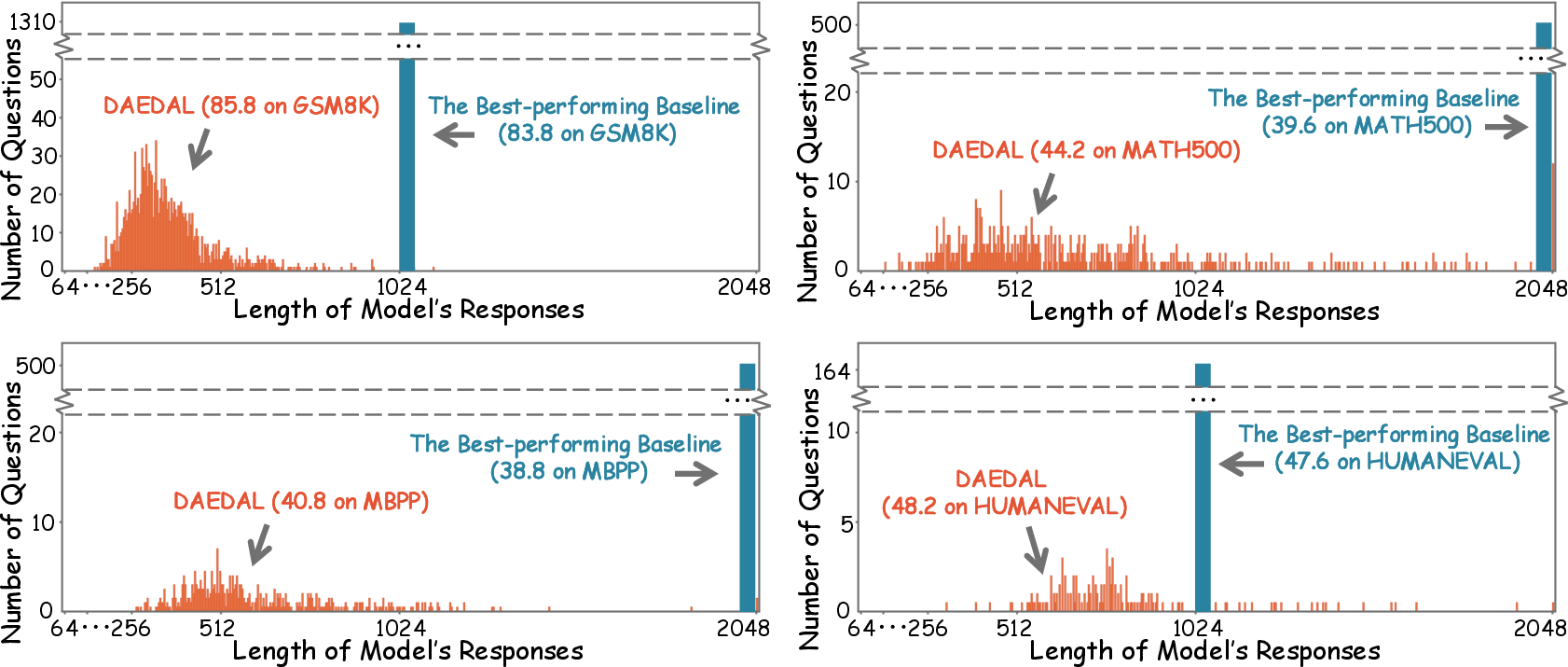
Figure 4: Distribution of individual Response Lengths ($\boldsymbol{N_{token}$) on LLaDA-Instruct-8B. DAEDAL’s dynamic adaptation results in varied length distribution compared to the fixed-length baseline.
Analysis
Threshold Sensitivity
DAEDAL’s robustness was showcased through varied threshold configurations, which governs the token-level filling and sequence-level length adjustment. Even with diverse threshold settings, DAEDAL maintained high accuracy, underscoring its adaptable nature without extensive hyperparameter tuning.
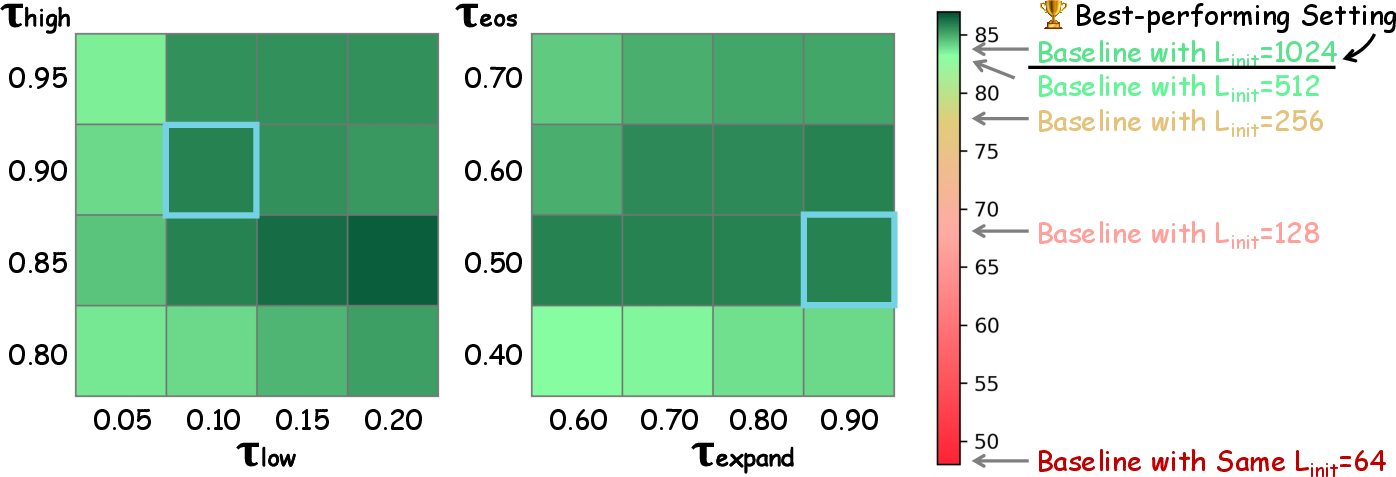
Figure 5: Ablation Results on DAEDAL's Thresholds. The heatmaps present grid search results over interdependent threshold pairs, highlighting stability across configurations.
Conclusion
DAEDAL effectively addresses the static length limitation of DLLMs, introducing a dynamic, training-free approach that leverages intrinsic model signals for length adaptability. This strategic flexibility not only enhances computational efficiency but also aligns DLLMs more closely with autoregressive capabilities for diverse generation tasks. Future avenues may explore integrating DAEDAL's framework with other generation mechanisms, fostering further advancements in language modeling.