- The paper introduces the Next Sequence Prediction (NSP) paradigm, unifying autoregressive and diffusion approaches for dynamic, efficient sequence generation.
- It leverages parallel block training and structured attention masks to retrofit pretrained models for faster inference with controlled speed-accuracy trade-offs.
- Experimental results show that SDLM achieves competitive performance with reduced training costs and strong scalability, validated across diverse benchmarks.
Sequential Diffusion LLMs: Bridging Autoregressive and Diffusion Paradigms
Introduction
The paper introduces Sequential Diffusion LLMs (SDLM), a novel framework that unifies autoregressive and diffusion-based language modeling via the Next Sequence Prediction (NSP) paradigm. SDLM is designed to overcome the limitations of both autoregressive LLMs (ALMs) and diffusion LLMs (DLMs), specifically addressing the inefficiencies of strictly sequential decoding and the rigidity of fixed-length parallel generation. The approach enables dynamic, confidence-driven generation of contiguous token subsequences, retrofits existing ALMs with minimal cost, and preserves compatibility with key-value (KV) caching for efficient inference.
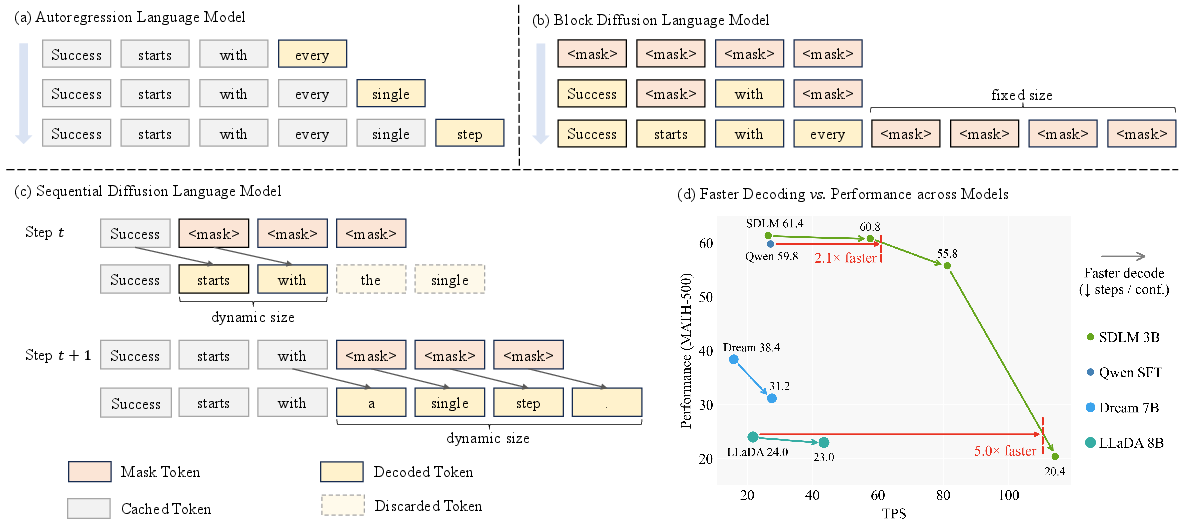
Figure 1: Comparison of decoding paradigms: ALMs (token-by-token), DLMs (fixed block), SDLM (dynamic subsequence), and the speed-accuracy trade-off on MATH-500.
Methodology
Next Sequence Prediction (NSP)
NSP generalizes next-token and next-block prediction by allowing the model to adaptively determine the length of the generated sequence at each decoding step. Formally, NSP defines an autoregressive probability distribution over variable-length sequences, where the model predicts a contiguous subsequence of tokens conditioned on the prefix and a masked block. When the prediction length is set to one, NSP reduces to standard next-token prediction, ensuring seamless integration with pretrained ALMs.
SDLM Architecture and Training
SDLM leverages parallel block training with a structured attention mask. Each block attends bidirectionally within itself and causally to its prefix, enabling efficient parallelization and dynamic sequence generation. The training objective minimizes the cross-entropy over all masked tokens in the block, with shifted prediction to exploit the strong first-token prediction capability of ALMs.
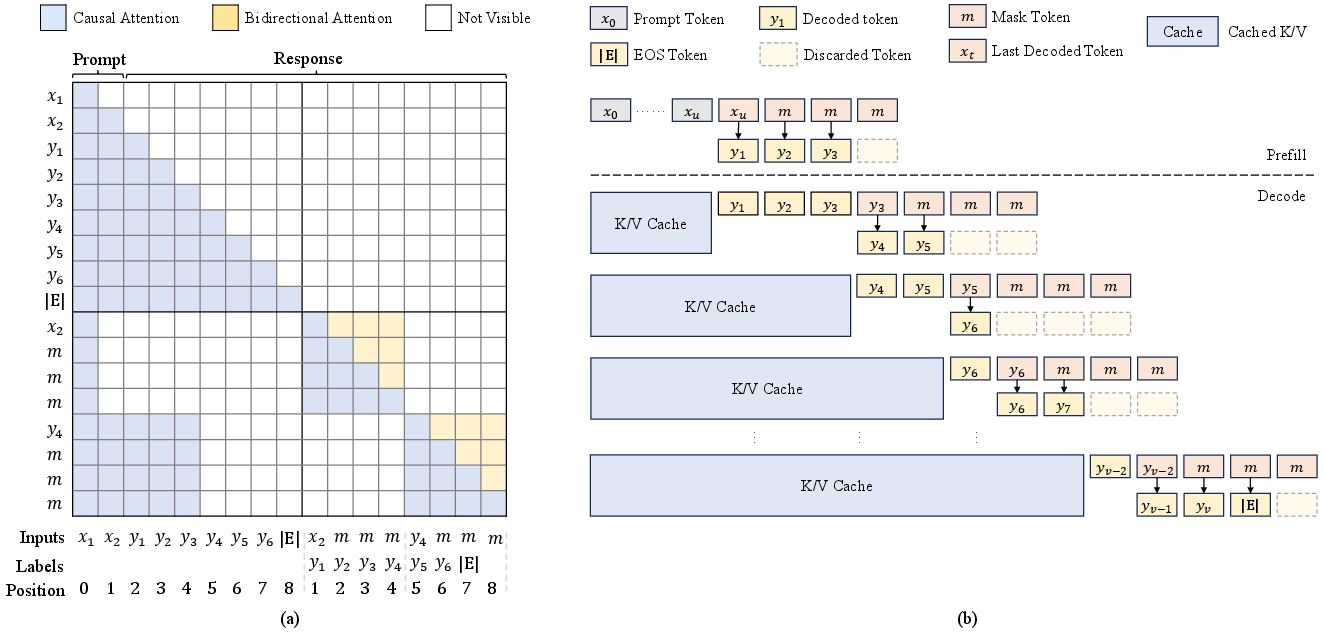
Figure 2: Structured attention mask for parallel block training and sampling, illustrating causal prefix, cross-block visibility, and intra-block bidirectional attention.
Parallel training is achieved by interleaving noise blocks and target blocks, with custom attention masks enforcing causality and local bidirectionality. This design allows SDLM to be fine-tuned from existing ALMs using standard instruction datasets, drastically reducing training cost and compute requirements.
Inference: Longest Prefix Decoding
During inference, SDLM employs Longest Prefix Decoding, dynamically selecting the number of tokens to output per step based on model confidence. Two confidence metrics are explored: logit-based (softmax probability) and entropy-normalized. The decoding length γτ(Zi) is determined by a threshold τ on cumulative confidence, balancing speed and accuracy. Additionally, self-speculative decoding is implemented, verifying the correctness of parallel predictions via consistency checks, further enhancing reliability at the cost of additional forward passes.
Experimental Results
SDLM is evaluated on a comprehensive suite of benchmarks, including general, mathematical, and coding tasks. Models are fine-tuned on Qwen-2.5 (3B and 32B) using 3.5M samples, and compared against ALMs (Qwen-2.5-SFT) and DLMs (Dream-7B, LLaDA-8B).
Key findings include:
Short-answer benchmarks (MMLU, Winogrande, Hellaswag, ARC) confirm that SDLM retains the semantic and reasoning capabilities of the base ALMs, with performance within 1 percentage point of autoregressive baselines.
Ablation Studies
Block Size and Attention Mask
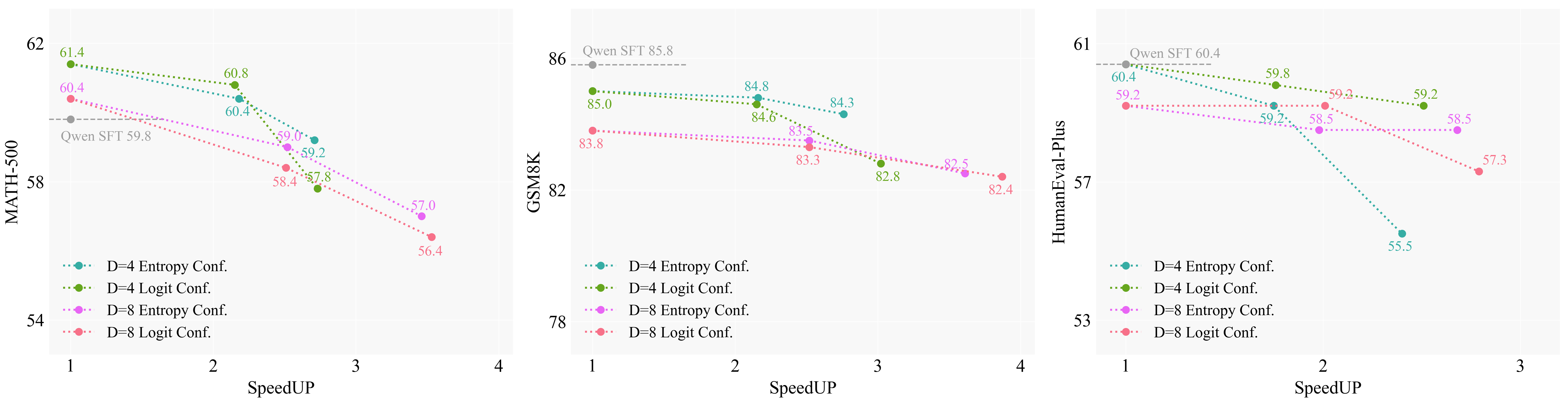
Increasing block size (D) enhances throughput with only marginal performance loss. Bidirectional attention within blocks improves parallel generation efficiency compared to causal masking, as evidenced by higher average tokens per step.
Figure 4: Ablation on attention mask type and prediction shift strategy, quantifying the impact on model performance and acceleration ratio.
Shifted prediction is critical; omitting it leads to significant performance degradation and increased output repetition, highlighting the importance of leveraging ALM's first-token prediction strength.
Self-Speculative Decoding
Self-speculative decoding further increases accepted tokens per step (up to 5.4 for D=8) with comparable accuracy, at the expense of additional validation overhead. This method is particularly effective in scenarios demanding high responsiveness.
Adaptive Decoding Visualization
SDLM's dynamic decoding adapts sequence length to local context, emitting longer subsequences in fluent regions and shorter ones in uncertain or branching contexts.

Figure 5: Visualization of the sampling process, with each blue block representing a subsequence generated in a single decoding step.
Theoretical and Practical Implications
SDLM demonstrates that diffusion-based generation can be effectively retrofitted onto existing ALMs, preserving KV-cache compatibility and enabling dynamic, parallel decoding. The NSP paradigm unifies autoregressive and blockwise diffusion approaches, offering a flexible framework for efficient sequence generation. The ability to control the speed-accuracy trade-off via confidence thresholds or speculative verification is particularly valuable for deployment in latency-sensitive applications.
The results suggest strong scalability: SDLM-32B matches SFT-tuned ALMs with only 3.5M training samples, indicating that the approach is viable for large-scale models and longer training regimes. The minimal architectural changes required for extending prediction horizon (simply appending mask tokens) further facilitate practical adoption.
Future Directions
Potential avenues for future research include:
- Extending SDLM to multimodal and multilingual settings, leveraging its flexible decoding paradigm.
- Investigating adaptive block sizing strategies conditioned on input semantics or uncertainty.
- Integrating advanced speculative decoding mechanisms to further reduce latency.
- Exploring the impact of NSP-based training on model calibration and uncertainty estimation.
Conclusion
Sequential Diffusion LLMs (SDLM) present a unified framework for efficient, dynamic sequence generation, bridging the gap between autoregressive and diffusion paradigms. By retrofitting pretrained ALMs with parallel block training and adaptive decoding, SDLM achieves competitive performance with substantial inference acceleration. The NSP paradigm offers a principled approach to balancing speed and quality, with strong empirical results and scalability. This work lays the foundation for further exploration of unified sequence generation models in both research and production environments.