Learning to Parallel: Accelerating Diffusion Large Language Models via Adaptive Parallel Decoding
Abstract: Autoregressive decoding in LLMs requires $\mathcal{O}(n)$ sequential steps for $n$ tokens, fundamentally limiting inference throughput. Recent diffusion-based LLMs (dLLMs) enable parallel token generation through iterative denoising. However, current parallel decoding strategies rely on fixed, input-agnostic heuristics (e.g., confidence thresholds), which fail to adapt to input-specific characteristics, resulting in suboptimal speed-quality trade-offs across diverse NLP tasks. In this work, we explore a more flexible and dynamic approach to parallel decoding. We propose Learning to Parallel Decode (Learn2PD), a framework that trains a lightweight and adaptive filter model to predict, for each token position, whether the current prediction matches the final output. This learned filter approximates an oracle parallel decoding strategy that unmasks tokens only when correctly predicted. Importantly, the filter model is learned in a post-training manner, requiring only a small amount of computation to optimize it (minute-level GPU time). Additionally, we introduce End-of-Text Prediction (EoTP) to detect decoding completion at the end of sequence, avoiding redundant decoding of padding tokens. Experiments on the LLaDA benchmark demonstrate that our method achieves up to 22.58$\times$ speedup without any performance drop, and up to 57.51$\times$ when combined with KV-Cache.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making a new kind of LLM (called a diffusion LLM) much faster at writing answers without hurting quality. Instead of writing one word at a time, these models polish the whole sentence over several “rounds.” The problem is: they often waste time redoing words that are already correct. The authors build a small “helper” that learns when a word is already right, so the model can lock it in and stop reworking it. They also add a simple trick to stop early when the answer has ended.
What questions did the paper ask?
- Can we speed up diffusion-based LLMs by avoiding unnecessary re-decoding of tokens (words or word-pieces) that are already correct?
- Can we do this in a smart, adaptive way (based on the input and model’s behavior), instead of using one fixed rule for everything?
- Can we detect the end of the answer early so we don’t waste time “writing” padding or [End-of-Text] tokens?
How did they do it?
Think of writing an essay with erasable ink in multiple passes. Each pass, you fix some mistakes. If a sentence is already perfect, you shouldn’t keep rewriting it.
- Diffusion LLMs, in simple terms:
- Traditional models often write one token at a time, left to right (like typing word-by-word). That’s slow because it’s fully sequential.
- Diffusion LLMs “refine” the whole output in rounds (like taking a blurry sentence and making it sharper step-by-step). Many token updates can happen in parallel each round.
- To improve quality, these models sometimes “mask” (blank out) low-confidence tokens and redo them.
- The waste they found:
- Many tokens are re-masked and re-decoded even after they already match the final answer. That’s like repainting a square on a coloring page even though it’s already the right color.
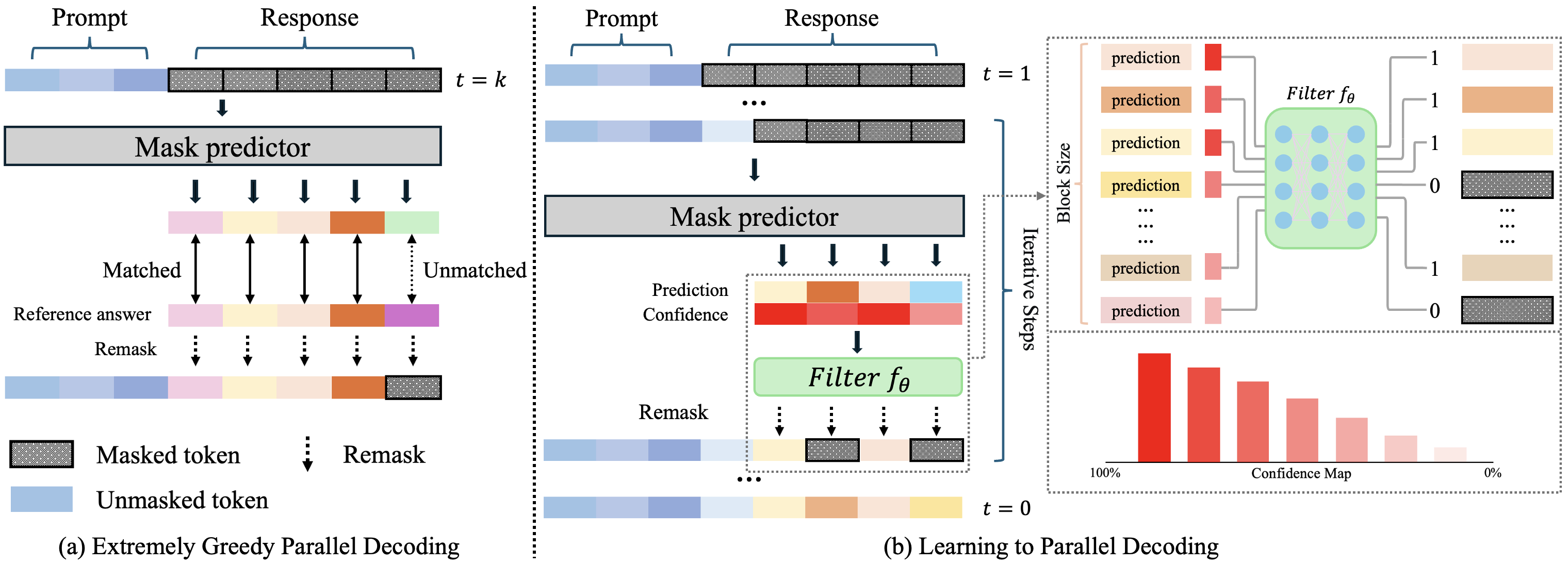
- The “oracle” idea (Extremely Greedy Parallel, EGP):
- Imagine having the answer key during decoding. You would lock in a token as soon as it matches the final answer and never redo it. This would be super fast—but in real life, you don’t have the answer key at inference time.
- Their solution: Learn2PD (Learning to Parallel Decode)
- They train a tiny helper model (a simple two-layer MLP) that looks at the model’s confidence signals and decides, for each token, “Is this likely correct? Can we lock it in?”
- This helper is trained after the main model is done (“post-training”) and takes only minutes on a single GPU. The main LLM stays frozen.
- During decoding, the helper says which tokens to keep and which to keep working on. This approximates the oracle without needing the real answer.
- End-of-Text Prediction (EoTP):
- If the model has already produced the [End-of-Text] token, why keep generating more padding? EoTP detects this reliably and stops decoding immediately to avoid extra steps.
- Compatibility with other speedups:
- They also test their method with KV cache (a common speed trick that reuses attention results). Their approach stacks with it for even greater speed.
What did they find?
- Big speedups, same quality:
- Up to about 22.58× faster than the standard diffusion LLM decoding, with no drop in accuracy on benchmarks like GSM8K (math word problems), MATH, HumanEval, and MBPP (coding tasks).
- With KV cache added, speedups reached about 57.51×, with only a small accuracy decrease.
- Works especially well for longer outputs:
- The longer the allowed generation length (like 1024 tokens), the more time is saved—because there’s more opportunity to avoid unnecessary re-decoding and to stop early with EoTP.
- Lightweight and practical:
- The helper model is tiny (just a two-layer MLP) and trains quickly.
- A two-layer version gave the best balance of speed and accuracy compared to smaller or deeper versions.
- Tunable trade-offs:
- By adjusting the helper’s decision threshold (how “sure” it must be before locking in a token), you can trade a bit of speed for a bit of accuracy or vice versa. They found a sweet spot that keeps accuracy near the baseline while giving strong speedups.
Why does this matter?
- Faster and cheaper AI: Cutting decoding time by 10–50× makes models more affordable and responsive, especially for long answers like math and code.
- Greener computing: Less computation means less energy use.
- Plug-and-play improvement: Because the main model isn’t retrained and the helper is tiny, this approach is easy to add on top of existing diffusion LLMs.
- Builds confidence in diffusion LLMs: It shows diffusion-based decoding can be both fast and high-quality, making it a more practical alternative to traditional, slower, word-by-word generation.
Short takeaway
The paper teaches diffusion LLMs to stop redoing work they’ve already done right. A small learned helper “locks in” correct tokens early, and an end-of-text detector stops decoding as soon as the answer finishes. This simple idea leads to massive speedups—often over 20×—without hurting quality, and it stacks with other speed tricks to go even faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces Learn2PD and EoTP for accelerating diffusion LLM decoding, but it leaves several issues unresolved. Below is a single, concrete list of gaps that future work could address:
- Model coverage and transferability
- Validated only on LLaDA-8B-Instruct; no results for other dLLM families (e.g., DiffuLLaMA, Dream), larger/smaller scales, or different masking/denoising parameterizations.
- No study of cross-model transfer: does a filter trained on one dLLM (or checkpoint) work on another, or after fine-tuning/continued training?
- Generalization to multilingual, multimodal, or domain-specific dLLMs (e.g., code-specialized, math-specialized) remains untested.
- Training signal and oracle definition
- Ambiguity in “reference answer”: the text alternates between using ground-truth vs. the model’s own vanilla output as the oracle target. The consequences of training with self-generated references (label bias, frozen errors) are not analyzed.
- No comparison between training the filter with dataset ground truth vs. model-reference targets to quantify accuracy vs. speed trade-offs and error propagation.
- Feature design for the filter
- The filter uses only current-step per-token confidence; it ignores richer signals such as:
- Temporal dynamics (confidence history across steps), top-k entropy/logit gaps, token identity/type, position index, time step t, block context, or attention/hidden features.
- No calibration analysis of dLLM confidences (are they well-calibrated across steps/blocks?), nor exploration of confidence calibration techniques to improve filter decisions.
- The threshold τ is globally fixed; no adaptive or learned per-token/per-step thresholds, nor uncertainty-aware decision policies (e.g., Bayesian calibration, conformal risk controls).
- Policy optimality and learning objective
- The filter is trained to imitate an oracle (EGP) via BCE, not to directly optimize a speed–quality objective; no exploration of cost-sensitive or reinforcement learning formulations that trade off error risk vs. speed.
- No theoretical guarantees or bounds on speedup vs. quality degradation under the learned policy; the oracle’s empirical upper bound (15–20×) lacks a principled analysis.
- Interaction with diffusion schedules and decoding regimes
- The impact of the number of denoising steps, masking schedules, and noise levels on the filter’s effectiveness is not studied.
- Results are limited to semi-autoregressive block decoding with a fixed block size (32); no study of dynamic block sizing, block-size sensitivity, or extension to fully parallel/non-block variants.
- Early stopping via EoTP
- No quantitative analysis of EoT detection reliability (false positives/negatives), nor safeguards (e.g., patience, majority voting across steps) to prevent premature truncation.
- Applicability to tasks without explicit [EoT] semantics or with structured outputs (e.g., code blocks that should not be cut mid-structure) is untested.
- The policy of “assign [EoT] to all subsequent tokens once detected” is not stress-tested for recovery from erroneous EoT predictions.
- Benchmarking breadth and baselines
- Head-to-head comparisons with contemporary acceleration methods (e.g., Guided Diffusion/FreeCache, SlowFast-Sampling, Prophet, Fast-dLLM’s confidence rules) are missing, so relative gains over strong static/dynamic heuristics remain unclear.
- Evaluation covers only four tasks; no coverage of long-form generation, instruction following, summarization, or multilingual tasks, where stability/early-commit behavior may differ.
- Quality and error analysis
- Limited analysis of failure modes: when does the filter finalize incorrect tokens, and how often would later steps have corrected them without early commitment?
- No semantic equivalence checks (e.g., functionally equivalent code with different tokens) to assess whether token-level matching is the right criterion for “correctness.”
- No human or qualitative analyses of outputs (e.g., hallucination tendencies, reasoning consistency) under early finalization.
- Robustness and OOD behavior
- Generalization to out-of-distribution prompts (adversarial, long chain-of-thought, highly ambiguous queries) is not evaluated.
- Stability under decoding hyperparameters (temperature, nucleus sampling) and stochastic sampling (non-greedy) is unknown.
- Systems and hardware considerations
- Overhead claims for the filter are qualitative; no breakdown of latency, memory footprint, and kernel-level scheduling costs, nor sensitivity to different GPUs/CPUs or batch sizes.
- Scalability to very long contexts (e.g., 4k–32k tokens), streaming scenarios, and multi-query batching is not reported.
- Compatibility with other accelerations
- While KV-cache compatibility is demonstrated, the accuracy drop with Dual Cache is not analyzed; no mitigation (e.g., re-tuning τ, cache-aware features) is proposed.
- Interactions with other caching/approximation methods (e.g., layer/token caches, temporal attention decomposition) are untested.
- Data and training protocol
- The filter is trained on 2,640 FLAN samples; sensitivity to dataset size, composition, and domain diversity is not studied.
- No ablations on training curricula (e.g., curriculum over noise levels, blocks), or on cross-task/domain fine-tuning vs. one-shot training.
- Stopping criteria beyond EoT
- The paper does not explore alternative early-stopping signals (e.g., stability of all tokens over k steps, confidence plateaus) that could complement or replace EoT detection.
- Reproducibility and variance
- No reporting of variance, confidence intervals, or run-to-run stability for TPS and task scores; robustness to random seeds and prompt order is unknown.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the Learn2PD filter model and End-of-Text Prediction (EoTP) into diffusion-based LLM (dLLM) inference pipelines. They leverage the reported 3–22.58× speedups (up to 57.51× with KV-cache) with negligible accuracy loss.
- Sector: Software/Cloud Inference
- Use case: Drop-in acceleration for dLLM serving
- What: Package Learn2PD as a middleware module for popular inference servers (vLLM-style or custom dLLM runners) to increase tokens/sec, reduce compute cost per request, and improve tail latency.
- Tools/workflows:
- Filter training pipeline (minutes on a single GPU) using reference outputs to label token stability
- Runtime integration of the 2-layer MLP filter on confidence streams
- EoTP “sentinel” to halt once the [EoT] token is committed
- Optional: KV-cache stacking to compound speedups
- Assumptions/dependencies: Requires a diffusion LLM exposing token-level confidence; presence of [EoT] in tokenizer; minor engineering to add the filter to the decoding loop.
- Sector: Customer Support and ChatOps
- Use case: Faster, lower-cost agent responses in production
- What: Apply Learn2PD+EoTP to speed up long-form responses (explanations, step-by-step summaries) while preserving accuracy.
- Tools/workflows: Fine-tune filter threshold per domain to balance speed/quality; real-time monitoring of acceptance rates; rollback to baseline on anomaly.
- Assumptions/dependencies: dLLM suitability for customer support tasks; domain-calibrated confidence thresholds to avoid premature token finalization.
- Sector: Software Development (IDE/CI)
- Use case: Latency reduction in code generation and review assistants
- What: Integrate Learn2PD into code assistants using dLLMs for function stubs, test generation, and refactoring, reducing the waiting time in interactive sessions and CI bots.
- Tools/workflows: IDE plugin backed by an accelerated dLLM service; EoTP to stop early for short completions; KV-cache for repeated context (project files).
- Assumptions/dependencies: Availability of dLLM code models; correct calibration of filter threshold for code tasks where minor errors are costly.
- Sector: Education/EdTech
- Use case: Real-time math tutoring and worked-solution generation
- What: Speed up long, step-by-step explanations on GSM8K/MATH-like tasks without degrading accuracy.
- Tools/workflows: Deploy accelerated dLLM endpoints; auto-adjust filter thresholds based on question difficulty; EoTP for concise answers.
- Assumptions/dependencies: dLLM competence on math reasoning; threshold tuning for reasoning-heavy outputs.
- Sector: Data/Content Operations
- Use case: High-throughput synthetic data generation and augmentation
- What: Batch pipelines that produce instructions, Q&A, code snippets, or summaries with drastically reduced runtime and energy use.
- Tools/workflows: Offline filter training on representative corpora; throughput-oriented scheduling; EoTP to minimize padding waste on long generation limits.
- Assumptions/dependencies: Stability of filter across content types; monitoring for domain drift.
- Sector: Energy/Sustainability in Data Centers
- Use case: Lower energy per token and improved carbon footprint accounting
- What: Adopt EoTP to eliminate the ~90% redundant decoding after [EoT]; combine Learn2PD with KV-cache to minimize GPU-hours for AI workloads.
- Tools/workflows: Integrate with telemetry to quantify energy savings; policy-friendly reporting of efficiency gains.
- Assumptions/dependencies: Accurate [EoT] detection; dLLM adoption in production workloads.
- Sector: Academia/Research
- Use case: Scaling dLLM experiments and benchmarks
- What: Use Learn2PD to reduce experiment turnaround time (HumanEval, MBPP, GSM8K) enabling larger ablations and hyperparameter sweeps.
- Tools/workflows: Open-source code; confidence logging and filter training in minutes; reproducible settings for block size and generation length.
- Assumptions/dependencies: Access to dLLM checkpoints (e.g., LLaDA); correct integration of filter in semi-autoregressive block decoding.
- Sector: MLOps/Platform Engineering
- Use case: Multi-tenant capacity planning and autoscaling
- What: Increase throughput per GPU, reduce queue time, and smooth tail latency across tenants using Learn2PD; EoTP to cap unnecessary long runs.
- Tools/workflows: Auto-tune filter thresholds by traffic profile; admission control based on predicted speedups; fallback mechanisms.
- Assumptions/dependencies: Confidence calibration compatible with traffic mix; safe defaults when workloads shift domains.
Long-Term Applications
The following applications require further research, broader dLLM adoption, task-specific calibration, or hardware/software co-design.
- Sector: Cross-Model Generalization (LLM Ecosystem)
- Use case: Adaptive parallel decoding for non-diffusion models
- What: Extend the learned acceptance filter concept to autoregressive LLMs via speculative decoding and token-verifier heads.
- Tools/workflows: Train “acceptance heads” on AR models; merge with existing speculative decoding algorithms.
- Assumptions/dependencies: Access to token-level confidence or proxy signals; robust training labels for “finalization” in AR settings.
- Sector: Healthcare/Legal/Finance (High-Stakes Domains)
- Use case: Domain-specific filters with calibrated reliability
- What: Train specialized filters with conservative thresholds and post-hoc verifiers to ensure quality in regulated outputs (discharge summaries, legal memos, financial reports).
- Tools/workflows: Calibration with domain datasets; confidence–quality mapping; dual-stage verification before committing tokens.
- Assumptions/dependencies: Availability of trustworthy domain data; acceptance of dLLMs in regulated workflows; auditability requirements.
- Sector: Multimodal Generative AI (Vision/Audio)
- Use case: Adaptive early-commit policies for diffusion transformers beyond text
- What: Translate Learn2PD-like filters to time-agnostic masked diffusion for discrete multimodal tokens (e.g., audio units, image tokens).
- Tools/workflows: Confidence tracing in multimodal diffusion; block-wise acceptance for token grids or frames; EoT-like “completion signals.”
- Assumptions/dependencies: Discrete tokenization and confidence exposure in multimodal models; careful evaluation of quality vs speed in perceptual domains.
- Sector: Hardware/Accelerators
- Use case: Decoder-level gating and early commit in silicon
- What: Co-design GPU/ASIC kernels that natively implement token-level acceptance filters and EoTP to cut redundant compute.
- Tools/workflows: Runtime schedulers for masked blocks; hardware primitives for gating; confidence computation fused with kernels.
- Assumptions/dependencies: Vendor support; standard interfaces for model confidence; measurable energy gains at scale.
- Sector: Cloud Products and Pricing
- Use case: “Turbo dLLM tiers” with efficiency SLAs
- What: Offer dedicated service classes for diffusion LLM inference with guaranteed throughput and lower cost per 1K tokens using Learn2PD+EoTP+KV-cache.
- Tools/workflows: Metering and billing coupled to efficiency; automated threshold tuning; customer-facing dashboards.
- Assumptions/dependencies: Sufficient market demand; transparent performance guarantees; operations maturity with adaptive policies.
- Sector: Policy and Standards
- Use case: Efficiency benchmarks and procurement guidelines for AI inference
- What: Create standards that recognize early-termination mechanisms (EoTP) and adaptive decoding policies as best practices for greener AI.
- Tools/workflows: Efficiency certification metrics (tokens/sec per watt, redundancy avoidance rate); reporting templates for public sector procurement.
- Assumptions/dependencies: Policymaker engagement; neutral benchmarks; interoperability across vendors.
- Sector: AutoML for Decoding Policy Learning
- Use case: Task-aware, self-adapting filters
- What: Automated training of filters per dataset/domain with threshold search (e.g., Bayesian optimization) to optimize the speed–quality frontier.
- Tools/workflows: Continuous data collection of confidence traces; adaptive thresholding; online A/B testing.
- Assumptions/dependencies: Stable data distributions; guardrails to avoid quality regressions.
- Sector: Safety/Reliability Engineering
- Use case: Joint acceptance–verification pipelines
- What: Combine Learn2PD with lightweight verifiers (e.g., top-2 logit gap checks, consistency tests) to prevent committing incorrect tokens early.
- Tools/workflows: Two-stage commit: filter decides candidate acceptance; verifier validates; fallback remasking if uncertainty spikes.
- Assumptions/dependencies: Robust verifier signals; tolerance for small latency overhead in exchange for reliability.
These applications become feasible because:
- The filter is lightweight (≈2K params at block size 32), trained in minutes, and adds negligible runtime overhead.
- EoTP is simple to implement and removes substantial padding waste (up to ~90% at long generation lengths).
- Learn2PD is orthogonal to KV caching, so benefits stack (up to 57.51× speedups shown).
Key cross-cutting assumptions and dependencies:
- Requires diffusion LLMs (e.g., LLaDA, Dream) that expose token-level confidence and use block-wise semi-autoregressive decoding.
- Filter generalization depends on training data diversity; domain drift may necessitate periodic recalibration.
- Threshold (τ) tuning is crucial to balance speed and quality; conservative settings recommended for high-stakes domains.
- Accurate [EoT] token detection is necessary to avoid premature termination; safeguards (e.g., double-checking last tokens) may be needed.
Glossary
- Adaptive parallel decoding: A decoding strategy that dynamically decides which tokens to finalize in parallel based on learned signals, rather than fixed heuristics. "we present Learn2PD, a learned approach to accelerate diffusion LLM inference through adaptive parallel decoding."
- Autoregressive (AR) decoding: A generation process that produces tokens strictly one after another, conditioning each new token on previously generated tokens. "most state-of-the-art LLMs rely on autoregressive (AR) decoding \citep{brown2020language, radford2019language,vaswani2017attention}, which generates output tokens sequentially."
- Binary Cross-Entropy Loss (BCELoss): A loss function for binary classification that measures the difference between predicted probabilities and binary targets. "We can reformulate this as an optimization problem by using Binary Cross-Entropy Loss (BCELoss) \citep{de2005tutorial}:"
- Confidence-based sampling: A heuristic that selects tokens to unmask or finalize based on model confidence, favoring those with higher confidence. "confidence-based sampling \citep{chang2022maskgit} prioritizes the most confident tokens for parallel decoding."
- Continuous-Time Markov Chain (CTMC): A stochastic process where transitions occur continuously over time following Markov properties. "This was extended to continuous time by CTMC \citep{campbell2022continuous}."
- D3PM: A discrete diffusion framework using Markov chains to inject and remove noise in categorical data. "leading to D3PM \citep{austin2021structured}, which introduced a Markov chain-based framework for discrete noise injection and denoising trained via ELBO maximization."
- Diffusion LLMs (dLLMs): LLMs that generate sequences via iterative denoising steps, enabling parallel predictions across positions. "Recent diffusion-based LLMs (dLLMs) enable parallel token generation through iterative denoising."
- Diffusion-NAT: A model aligning diffusion denoising with non-autoregressive decoding to speed up generation. "Diffusion-NAT \citep{Zhou2023DiffusionNATSD} aligned the denoising process with non-autoregressive decoding, enabling high-speed generation"
- Dual Cache: A KV caching strategy that caches multiple parts of the computation to improve throughput. "When augmented with the Dual Cache, the system attains substantially higher efficiency, reaching 31.23 TPS and a 57.51× speedup, albeit with a slight decrease in accuracy (74.00)."
- Early-commit decoding: A policy that finalizes all remaining tokens at once when a confidence criterion is met. "Prophet \citep{li2025diffusion} monitors the top-2 logit gap and commits all remaining tokens in one shot via early-commit decoding once it is sufficiently confident."
- ELBO maximization: Training objective that maximizes the Evidence Lower Bound to fit probabilistic generative models. "trained via ELBO maximization."
- End-of-Text Prediction (EoTP): A mechanism that detects the end-of-text token and terminates decoding early to avoid redundant computation. "we introduce End-of-Text Prediction (EoTP) to detect decoding completion at the end of sequence, avoiding redundant decoding of padding tokens."
- Extremely Greedy Parallel (EGP): An oracle decoding strategy that immediately finalizes tokens when their predictions match the reference answer, never remasking correct tokens. "we first establish an oracle baseline: Extremely Greedy Parallel (EGP), which unmasks each token immediately upon correct prediction."
- Guided Diffusion: A rule-based or signal-driven method that guides which tokens to unmask during diffusion decoding without retraining the main model. "They also introduce Guided Diffusion to decide which tokens to unmask each step without retraining."
- Key-Value (KV) Cache: A memory of transformer key and value activations reused across steps to accelerate inference. "Integration with KV Cache achieves a further improvement in throughput to 16.37 tokens/sec (a 57.51× speedup), with only a minimal loss in accuracy."
- Masked Diffusion LLMs (MDLM): A class of diffusion models that operate by masking tokens and learning to denoise them in discrete spaces. "Masked Diffusion Models such as MDLM \citep{shi2024simplified, sahoo2024simple, zheng2024masked} and RADD \citet{ou2025your} provided further theoretical simplifications and formalized connections between parameterizations."
- Non-autoregressive decoding: A generation process that predicts multiple tokens simultaneously instead of sequentially. "Diffusion-NAT \citep{Zhou2023DiffusionNATSD} aligned the denoising process with non-autoregressive decoding, enabling high-speed generation"
- Prefix Cache: A KV caching strategy that reuses key-value activations from the prompt or prefix to accelerate generation. "Similarly, incorporating the Prefix Cache also brings noticeable improvements, yielding 14.79 TPS and a 27.23× acceleration while maintaining a competitive score of 77.71."
- Semi-autoregressive decoding: A hybrid decoding scheme that divides sequences into blocks and decodes block-by-block, enabling parallelism while preserving left-to-right dependencies. "most dLLMs adopt semi-autoregressive decoding \citep{arriola2025block}, which divides the target sequence into contiguous blocks and decodes the blocks from left to right."
- SEDD: A discrete diffusion method that learns the reverse process via a denoising score entropy objective. "SEDD \citep{lou2023discrete} learned the reverse process by modeling the ratio of marginal probabilities using a denoising score entropy objective"
- SlowFast-Sampling: A two-stage sampling strategy alternating between cautious exploration and fast decoding of high-confidence spans. "SlowFast-Sampling \citep{wei2025accelerating} proposes a dynamic two-stage sampler that alternates a cautious exploratory phase with a fast phase that aggressively decodes high-confidence tokens within that span."
- Tokens Per Second (TPS): A throughput metric measuring how many tokens are generated per second during inference. "Performance is measured using three metrics: TPS (tokens/sec), speedup, and accuracy score."
- Top-2 logit gap: The difference between the highest and second-highest logits, used as a confidence signal for early committing. "Prophet \citep{li2025diffusion} monitors the top-2 logit gap and commits all remaining tokens in one shot via early-commit decoding once it is sufficiently confident."
Collections
Sign up for free to add this paper to one or more collections.

