- The paper demonstrates that adaptive block scheduling significantly improves diffusion LLM inference by aligning block boundaries with semantic steps.
- The methodology leverages confidence dynamics analysis to dynamically adjust block sizes, reducing late decoding overhead and premature errors.
- Empirical results reveal up to 5.3% accuracy gains while maintaining competitive throughput across varied dLLM architectures and benchmarks.
AdaBlock-dLLM: Semantic-Aware Diffusion LLM Inference via Adaptive Block Size
Introduction and Motivation
Diffusion-based LLMs (dLLMs) have emerged as a competitive alternative to autoregressive LLMs, offering parallel decoding and improved inference throughput. The semi-autoregressive (semi-AR) decoding paradigm, which partitions the output sequence into fixed-size blocks, is widely adopted in dLLMs due to its compatibility with blockwise KV caching and favorable accuracy–speed trade-offs. However, this paper identifies two critical limitations of fixed block size in semi-AR decoding: late decoding overhead—where high-confidence tokens outside the current block are unnecessarily delayed—and premature decoding error—where low-confidence tokens within the current block are committed too early, leading to suboptimal predictions.
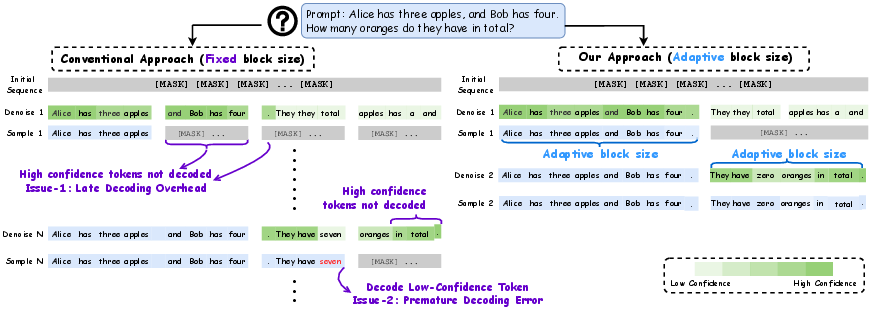
Figure 1: Illustrative examples of late decoding overhead and premature decoding error (left), and how AdaBlock-dLLM overcomes these issues by adaptively aligning block boundaries with semantic steps (right).
Through a statistical analysis of confidence dynamics during the denoising process, the authors identify a volatility band (VB)—a region of fluctuating confidence scores that encodes local semantic structure. This insight motivates AdaBlock-dLLM, a training-free, plug-and-play scheduler that adaptively aligns block boundaries with semantic steps by adjusting block size at runtime. The method is designed to be compatible with existing dLLM architectures and inference pipelines.
Analysis of Confidence Dynamics in dLLM Decoding
The denoise–sample cycle in dLLM decoding iteratively unmasks tokens based on model confidence. The authors analyze the evolution of confidence scores across sequence positions and decoding steps, revealing three regimes: a high-confidence plateau, a volatility band (VB), and a low-confidence floor.
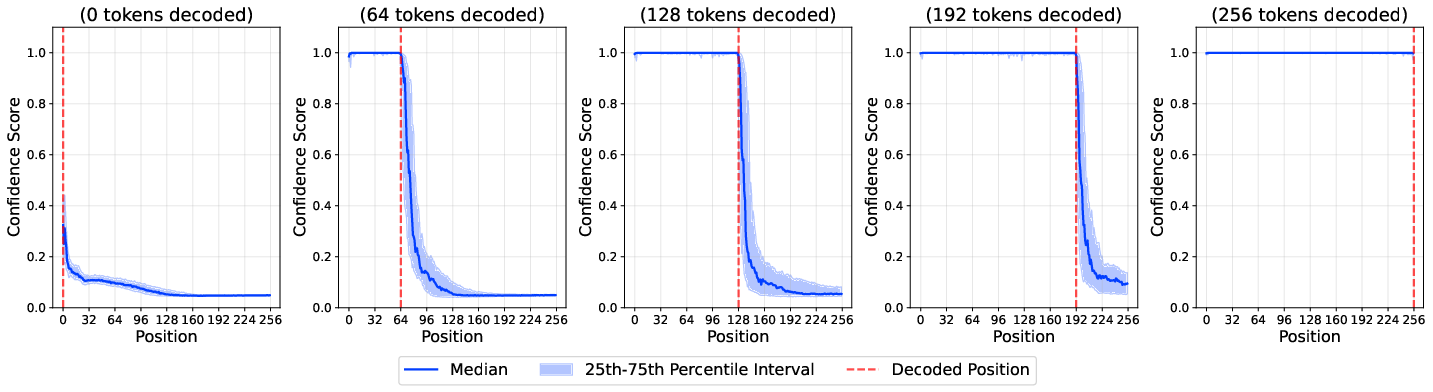
Figure 2: Confidence scores across sequence positions for LLaDA-8B-Base on GSM8K. The high-confidence plateau expands as decoding progresses, while positions beyond the decoded prefix exhibit high variance.
Key observations include:
- Confidence Locality: High-confidence regions emerge near decoded tokens, reflecting local semantic completeness.
- Global Autoregressiveness: Despite the non-autoregressive nature of diffusion models, decoding traces exhibit a chain-like, autoregressive progression.
- Volatility Band: The VB is the region of active decoding, characterized by fluctuating confidence scores and local stochasticity. Its width and position vary across samples and decoding steps.
The misalignment between fixed block boundaries and the dynamic, semantically meaningful boundaries of the VB leads to the two aforementioned issues: late decoding overhead and premature decoding error.
AdaBlock-dLLM: Semantic-Aware Adaptive Block-Size Scheduling
AdaBlock-dLLM introduces a semantic-aware block-size scheduler that dynamically adjusts block size based on the predicted semantic structure of the output. The core idea is to align block boundaries with semantic steps, defined as contiguous spans of tokens exhibiting local semantic coherence, often delimited by special tokens (e.g., newline, period).
The block size determination procedure operates as follows:
- Window Selection: For the current decoding position, select a window of candidate positions.
- Delimiter Identification: Within the window, identify positions where the predicted token is a delimiter from a predefined set (e.g.,
\n, ., ,).
- Confidence Evaluation: Among delimiter positions, select the one with the highest confidence. If its confidence exceeds a threshold τD, set the block size to include all tokens up to and including this delimiter. Otherwise, fall back to the default block size.
This approach ensures that high-confidence, semantically coherent spans are decoded together, while low-confidence or ambiguous regions are deferred for further refinement.
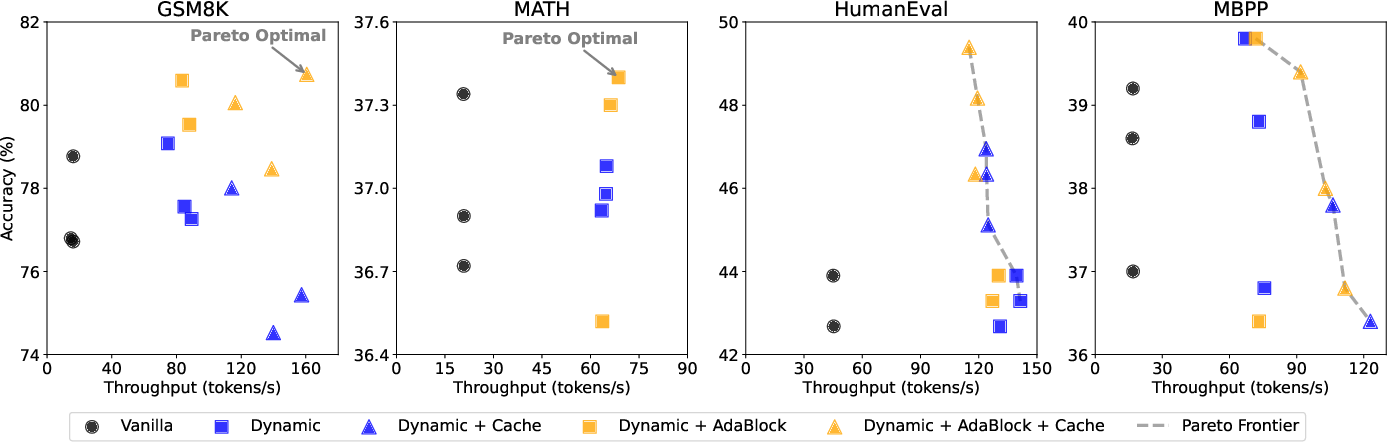
Figure 3: Integrating AdaBlock-dLLM into the SOTA Fast-dLLM pipeline, demonstrating improved accuracy–throughput trade-offs and Pareto optimality across benchmarks.
The full adaptive semi-AR decoding algorithm is formalized in the paper, with modular integration points for the block-size scheduler, denoiser, and dynamic sampler.
Empirical Evaluation
AdaBlock-dLLM is evaluated on multiple dLLMs (LLaDA-8B-Instruct, LLaDA-1.5, Dream-v0-Base-7B) and standard benchmarks (GSM8K, MATH, HumanEval, MBPP). The evaluation considers both generation quality (accuracy) and inference throughput (tokens per second, TPS).
Key empirical findings:
Implementation Considerations
Integration and Overhead
AdaBlock-dLLM is designed as a training-free, plug-and-play enhancement. It requires only minor modifications to the inference pipeline, specifically the insertion of the block-size determination step between denoising and sampling. The method is compatible with existing dLLM architectures and does not require retraining or fine-tuning.
Hyperparameters
- Delimiter Set (D): Should be chosen to reflect task-specific semantic boundaries (e.g.,
\n for reasoning, . for sentences).
- Delimiter Confidence Threshold (τD): Tuned to balance sensitivity and specificity in semantic step detection; lower values suffice for models with strong local stochasticity, while higher values may be needed for AR-adapted dLLMs.
- Default Block Size (B0): Acts as a fallback in ambiguous regions; can be set based on hardware constraints and desired throughput.
Trade-offs
- Accuracy vs. Throughput: Adaptive block sizing may slightly reduce throughput for large default block sizes but yields significant accuracy improvements, especially in tasks requiring semantic consistency.
- Model Dependency: Gains are larger for dLLMs trained from scratch (with higher local stochasticity) than for AR-adapted dLLMs, where global autoregressiveness dominates.
Scaling and Resource Requirements
- Computational Overhead: The additional computation for block-size determination is negligible compared to the overall denoise–sample cycle.
- Memory: No additional memory overhead beyond what is required for standard semi-AR decoding and KV caching.
Implications and Future Directions
AdaBlock-dLLM demonstrates that semantics-aware adaptive scheduling can substantially improve the efficiency and quality of diffusion-based LLM inference. The findings suggest several avenues for future research:
- Training Objectives: Incorporating semantics-aware objectives during training to further enhance local context modeling and blockwise coherence.
- Generalization: Extending adaptive block-size scheduling to other non-autoregressive or hybrid generation paradigms.
- Task-Specific Adaptation: Dynamically adjusting delimiter sets and thresholds based on task or domain, potentially via meta-learning or reinforcement learning.
- Theoretical Analysis: Formalizing the relationship between volatility band dynamics, semantic structure, and decoding efficiency.
Conclusion
AdaBlock-dLLM provides a principled, practical solution to the limitations of fixed block size in semi-AR dLLM decoding. By adaptively aligning block boundaries with semantic steps, it achieves significant improvements in generation quality without sacrificing inference efficiency. The method is readily deployable in existing dLLM systems and opens new directions for semantics-aware inference and training strategies in diffusion-based language modeling.
