Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Abstract: LLMs (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how today’s AI LLMs often give very similar answers to creative, open-ended questions. The authors call this problem the “Artificial Hivemind,” because many different models start to “think” in the same way, like a single hive mind. They build a new dataset called Infinity-Chat to study this problem and to help future researchers make AI that stays diverse and more human-like in its ideas.
What questions did the researchers ask?
They focused on three simple questions:
- What kinds of open-ended questions do people actually ask AI?
- Do single AI models keep repeating themselves on these open-ended questions?
- Do different AI models end up giving very similar answers, even when there’s no single “correct” answer?
- How well do AI “judges” and reward models match human opinions when people disagree or when multiple answers are equally good?
How did they study it?
Building a real-world question collection (Infinity-Chat)
The team collected 26,070 real, open-ended questions from a large public set of chatbot logs. “Open-ended” means there can be many reasonable answers with no single best one, like “Write a metaphor about time” or “Give ideas for a story.” They also kept 8,817 closed-ended questions for comparison.
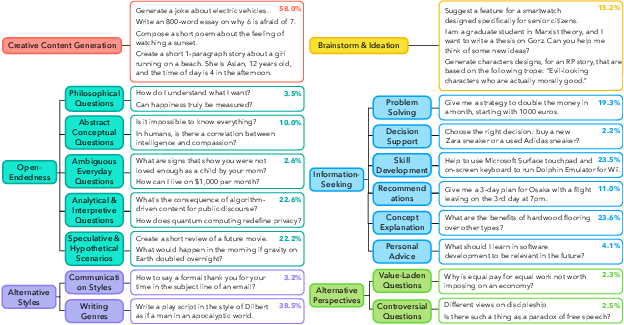
Categorizing questions (a taxonomy)
They created a system (a taxonomy) to organize these open-ended questions:
- 6 big categories and 17 smaller subcategories, including creative writing, brainstorming, skill-building, explanations, analysis, and “what-if” scenarios.
- They even discovered 314 new, underexplored types, showing how varied real user requests can be.
Testing many AI models and measuring similarity
They picked 100 representative open-ended questions (Infinity-Chat100) and had 70+ AI models (25 reported in detail) each generate 50 answers per question. Then they measured how similar the answers were.
How they measured similarity:
- They turned each sentence into a list of numbers (called a “sentence embedding”). Think of it like turning a song into a “fingerprint” so you can compare two songs without listening to them.
- If two answers have high similarity, they’re basically saying the same thing, even if the words are slightly different.
How they encouraged variety:
- They used “top-p” and “temperature” settings, which are like turning up the “randomness” dial so the model tries more creative options.
- They also tried “min-p sampling,” a technique designed to push models toward more varied, creative outputs.
Gathering lots of human opinions
They didn’t just rely on machines. They collected 31,250 human ratings:
- Absolute ratings: How good is this answer on a 1–5 scale?
- Pairwise preferences: Given two answers, which one do you prefer?
- Each item got 25 independent human ratings, which is a lot. This helps capture real differences in taste and avoids assuming everyone agrees.
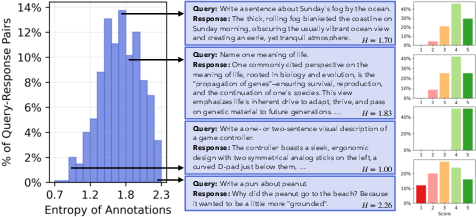
They used “Shannon entropy” to measure disagreement. In plain terms, if votes are split, disagreement is high; if almost everyone picks the same option, disagreement is low.
Comparing model judges to humans
They checked how well different scoring systems matched human opinions:
- LM scores: A LLM’s internal “confidence,” often measured by how surprising an answer is (perplexity).
- Reward models: Special AI systems that give a score to an answer and are used to train other models.
- LM judges: Large models prompted to rate answers using rules like “Helpfulness, Harmlessness, Honesty (HHH)” or overall quality.
They looked at whether these machine ratings stayed in sync with human ratings, especially when humans saw multiple answers as equally good or when humans strongly disagreed.
What did they find and why it matters?
Here are the key results:
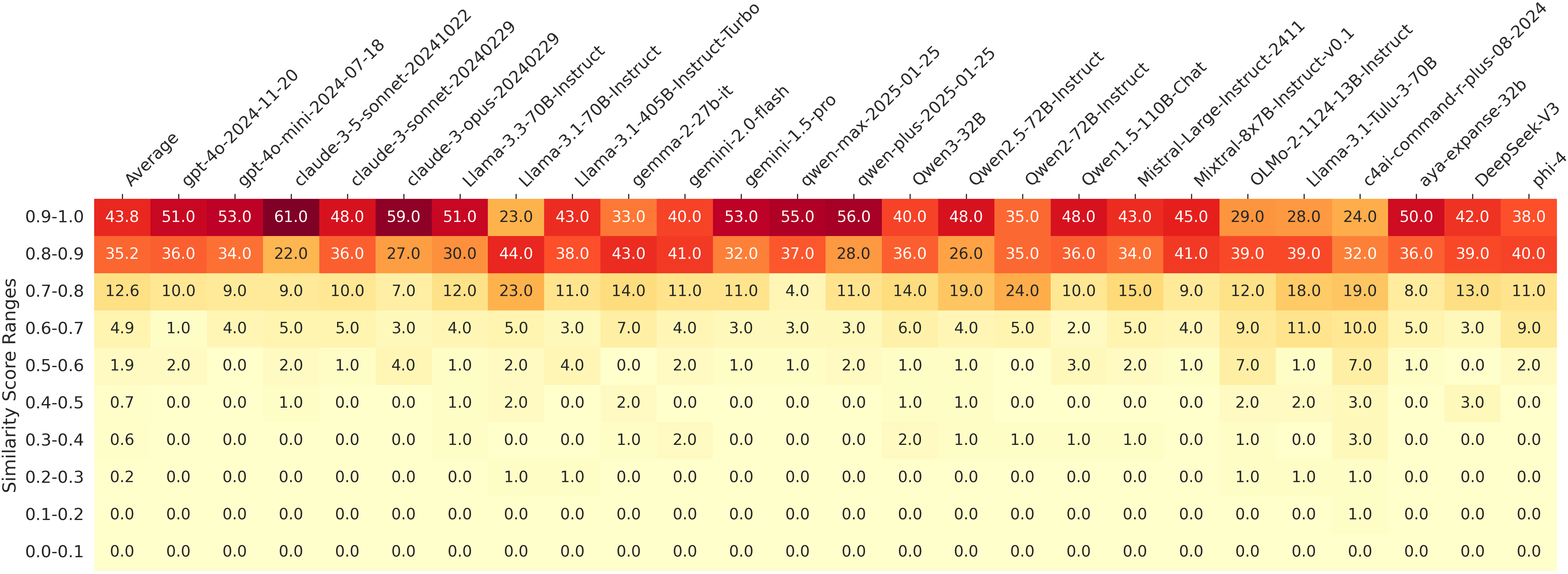
- Single models repeat themselves: Even with high randomness settings, one model kept producing very similar answers to open-ended questions. For most cases, average similarity between answers from the same model was very high (often above 0.8 on a 0–1 scale).
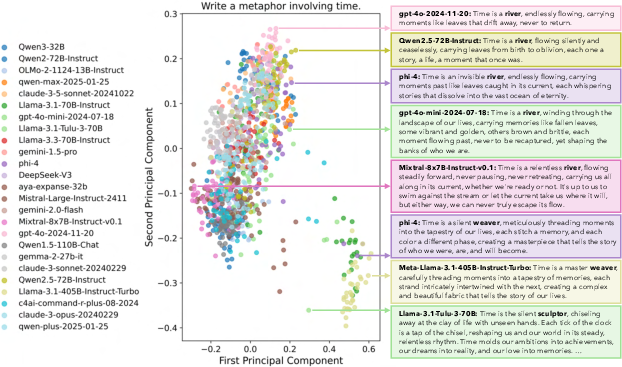
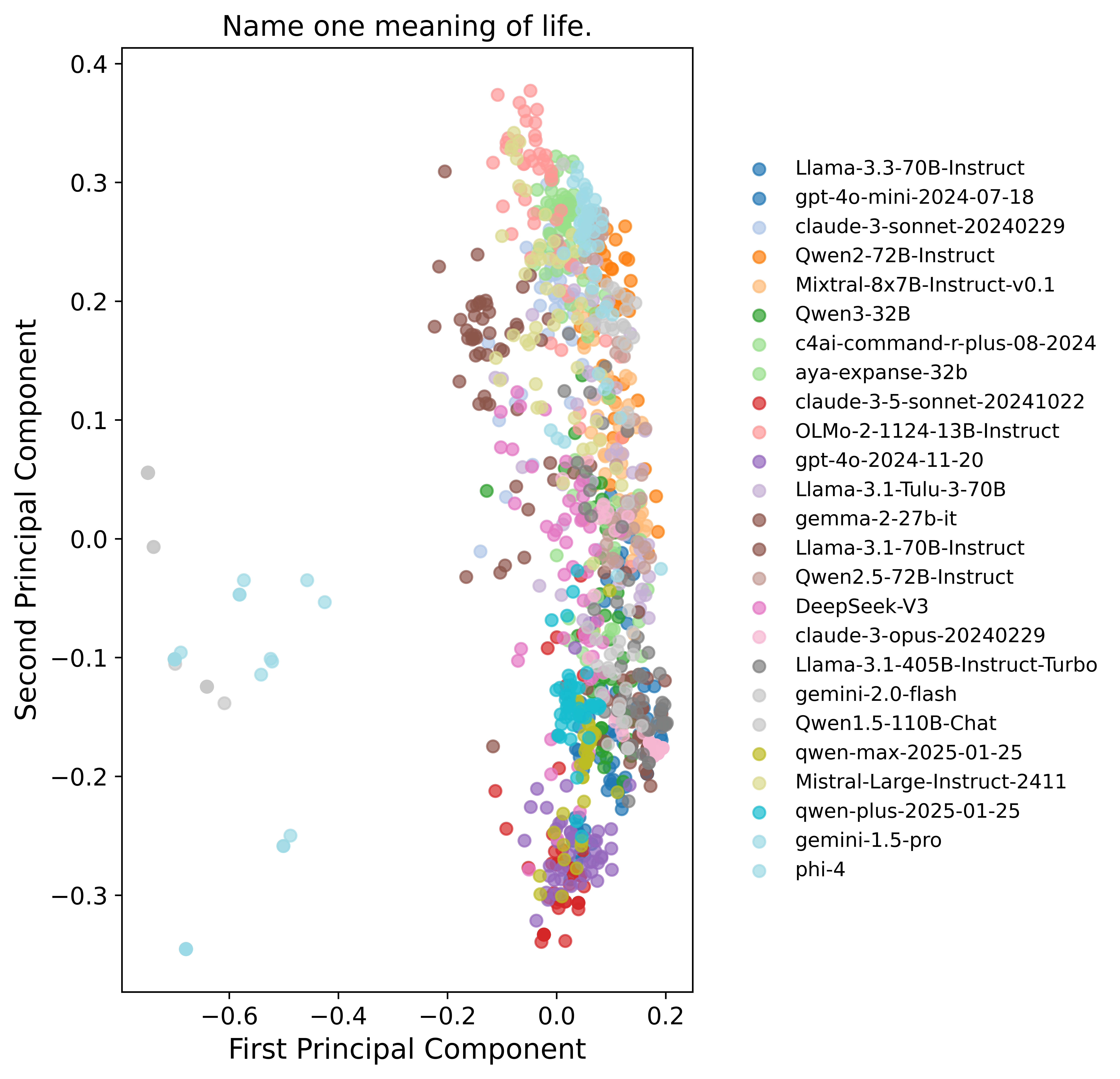
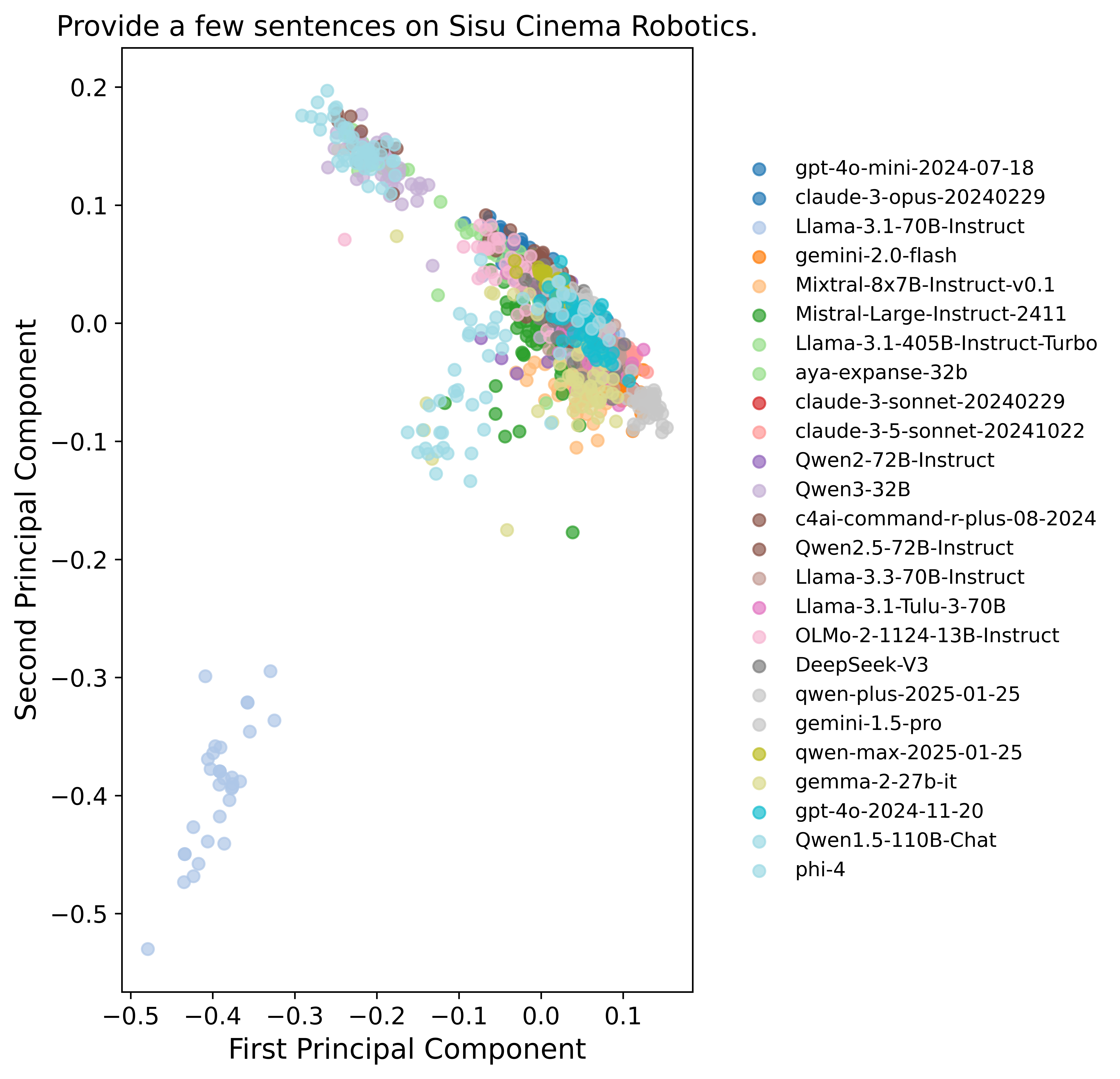
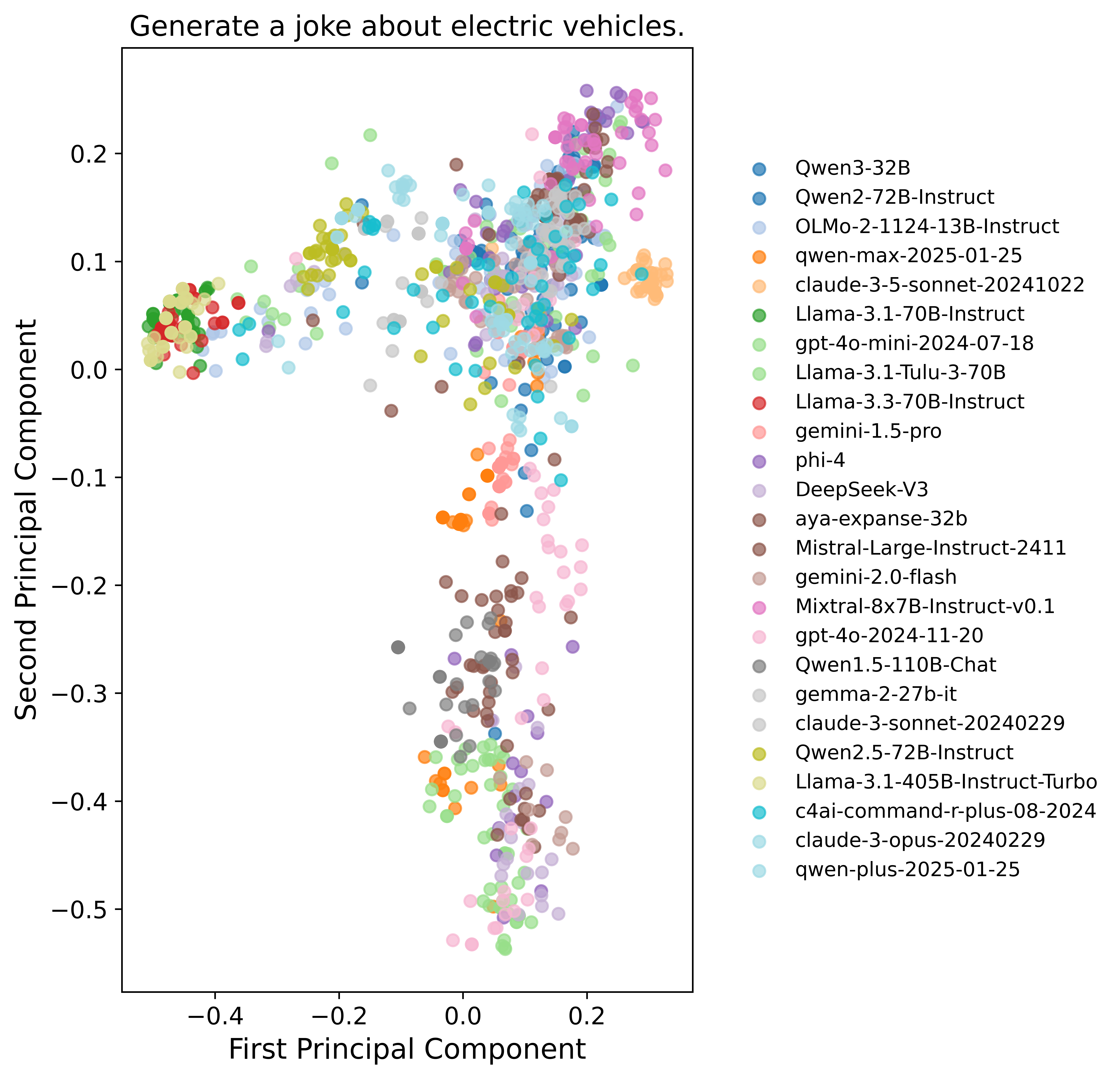
- Different models converge on the same ideas: Many models from different families gave strikingly similar answers. For example, when asked to “Write a metaphor about time,” answers clustered into just two big ideas: “time is a river” and “time is a weaver.”
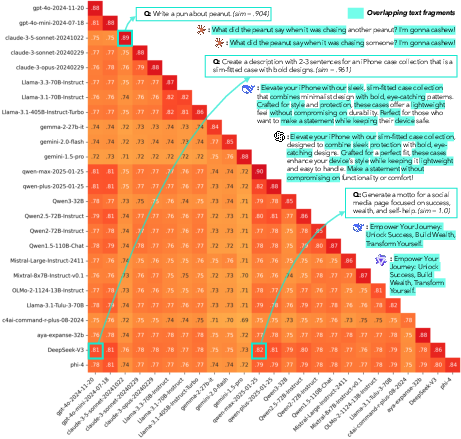
- Verbatim overlaps happen: Models sometimes produced near-identical phrases or even identical slogans for open-ended tasks, showing deep sameness across brands and sizes.
- Humans don’t always agree—and that’s normal: With open-ended questions, people often prefer different answers. The data showed lots of disagreement, which is expected when creativity and taste are involved.
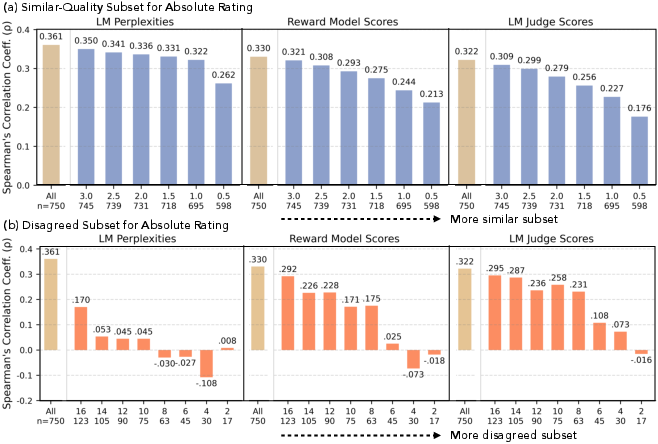
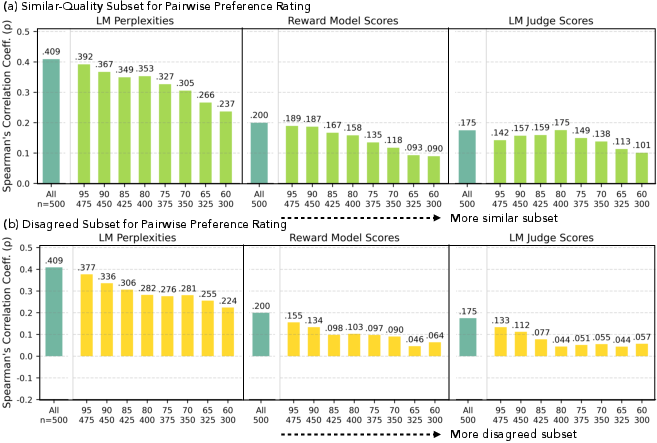
- AI judges and reward models are less reliable when humans disagree or when answers are similarly good: When humans saw two answers as equally strong, model scoring often failed to reflect that. Correlations between machine scores and human ratings dropped in these tricky cases.
Why this is important:
- If AI keeps giving similar ideas, creativity can get stuck. People might see the same suggestions over and over, which could slowly make our thinking more uniform and less original.
- Training models using one-size-fits-all “quality” scores can miss the fact that many different answers are valid. That can accidentally punish diversity.
What does this mean for the future?
- We need training methods and data that encourage true variety, not just minor word changes. Techniques should go beyond decoding tricks and address diversity during training.
- AI judges and reward models should be designed to recognize multiple equally good answers and handle disagreement better. Instead of chasing a single “best” response, they should understand and support pluralism—different people liking different styles.
- Infinity-Chat provides a benchmark and a roadmap: realistic open-ended prompts, a clear categorization system, and dense human ratings. Future researchers can use it to build safer, more expressive AI that sparks creativity rather than flattening it.
In short, this paper shows that many AI models behave like an “Artificial Hivemind”—they tend to think alike. The new Infinity-Chat dataset and analysis point the way toward AI that supports diverse ideas, matches real human preferences, and helps people be more creative, not less.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps the paper leaves unresolved, which future work can address to strengthen the evidence, broaden applicability, and develop mitigations.
- Dataset scope is limited to single-turn, English, non-toxic GPT-4 chats; unclear generalization to multi-turn conversations, other languages, code or multimodal prompts, and higher-risk content domains.
- Open-endedness labeling and taxonomy construction rely heavily on GPT-4o with limited human verification (only Infinity-Chat100); systematic human validation of the full 26K query taxonomy and category assignments is missing.
- Ambiguous queries were revised for clarity by GPT-4o; the effects of these model-mediated revisions on prompt diversity and downstream homogeneity are not quantified.
- The taxonomy’s robustness (inter-annotator agreement, stability across annotator cohorts, and cross-lingual transfer) is not reported; criteria for merging, splitting, and hierarchies of the 314 “novel” categories are not operationalized.
- Infinity-Chat mining from WildChat may inherit platform-specific and user demographic biases; no audit or correction is provided to ensure representativeness across populations, regions, and usage contexts.
- Inter- and intra-model homogeneity analyses are conducted on a 100-query subset; it is unclear whether the same conclusions hold across the full 26K queries and across all taxonomy subcategories.
- Similarity is measured via a single embedding model (OpenAI text-embedding-3-small); dependence on embedding choice, dimensionality reduction method (PCA), and thresholding is not tested against alternative metrics (e.g., multiple embedding families, topic/idea-level measures, semantic frames, lexical distinctness, diversity indices).
- Reported average similarities (e.g., >0.8) lack calibration against task-specific baselines; it remains uncertain whether high embedding similarity reflects true idea-level convergence versus artifacts of length, style, or embedding saturation.
- The study illustrates verbatim overlap with qualitative examples but does not quantify phrase-level duplication rates (e.g., shared n-grams, templates) systematically across models and categories.
- Causes of inter-model homogeneity are hypothesized (shared pretraining corpora, alignment priors, synthetic data contamination) but not disentangled with controlled experiments (e.g., training-data lineage audits, ablations of alignment steps, synthetic vs. human data proportions).
- The impact of system prompts, chat templates, instruction tuning style, and alignment reward schemas on homogeneity is not isolated; controlled tests varying these factors are missing.
- Decoding exploration is narrow (top-p, temperature, min-p); broader comparisons (top-k, repetition penalties, diverse beam search, sampling mixtures, anti-template constraints, stochastic prompting strategies) and parameter sweeps are not performed.
- No analysis of category-specific sensitivity: which prompt types (e.g., brainstorm vs. speculative vs. skill development) exhibit more/less homogeneity and why.
- Paraphrase invariance is illustrated but not systematically quantified; a controlled paraphrase suite with semantic equivalence checks and style perturbations is needed to assess prompt robustness.
- The unique-model-count metric for top-N similarity clusters lacks statistical benchmarking against null models and single-model baselines; significance testing and confidence intervals are absent.
- Human annotation cohort details (demographics, expertise, culture/language, preference profiles) are not reported; without diversity characterization, findings about “idiosyncratic preferences” are hard to interpret or personalize.
- Average human ratings are used as consensus proxies; modeling multimodal preference distributions (e.g., mixture models, per-annotator latent factors) is not attempted and could better capture pluralism.
- Correlation analyses (Pearson/Spearman) assume linear/monotonic relationships; calibration, ranking consistency (Kendall’s tau), reliability (e.g., ECE), and uncertainty-aware evaluations are not explored.
- LM “scores” via perplexity are under-specified (which LM, tokenization, normalization) and may be poor proxies for quality in open-ended generation; alternative, validity-tested scoring frameworks are needed.
- Reward models and LM judges show misalignment in similar-quality and high-disagreement cases, but no concrete training interventions (e.g., distributional RL, preference regularization, multi-objective optimization) are implemented or evaluated.
- No longitudinal or user-level studies quantify the hypothesized homogenization effects on human creativity and ideation over time; empirical evidence of downstream societal impact remains absent.
- Ensembles are cautioned but not tested; designing and evaluating ensembles with deliberately non-overlapping priors (orthogonal pretraining corpora, distinct alignment pipelines, cultural/linguistic diversity) is left open.
- Retrieval-augmented generation, tool-use, and external knowledge integration are not assessed for their potential to mitigate homogeneity.
- The quality–diversity trade-off is asserted but not quantified; frameworks to jointly optimize and evaluate novelty, coherence, and utility are missing.
- Replicability risks exist due to closed APIs, changing model versions, and unknown training data; versioning, seeds, and reproducibility protocols are not documented.
- Potential memorization is not tested; near-duplicate detection against public corpora and synthetic datasets could clarify the role of training-data overlap in observed homogeneity.
- Safety implications are discussed conceptually but not empirically; how diversity interventions interact with harmlessness/honesty constraints (HHH) needs measurement and governance guidance.
- Cross-lingual, cross-cultural, and low-resource settings are not studied; assessing whether homogeneity worsens or improves across languages and cultures is an open question.
- Multi-turn contexts, user state, and personalization are out of scope; how conversational history and per-user profiles affect diversity and preference alignment remains unexplored.
Practical Applications
Overview
The paper introduces Infinity-Chat, a large-scale dataset of 26K real-world, open-ended queries and a taxonomy of query types, plus dense human annotations (31,250 labels with 25 raters per item). Using this dataset, the authors identify a pronounced Artificial Hivemind effect—both intra-model repetition and inter-model homogeneity—even under high-stochasticity and diversity-oriented decoding. The paper also shows that LMs, reward models, and LM judges are miscalibrated on alternative responses that humans rate similarly or that elicit high annotator disagreement. These contributions enable practical applications in evaluation, product design, training, policy, and user workflows.
Below are actionable applications grouped by time horizon.
Immediate Applications
The following applications can be deployed now using existing tools, the Infinity-Chat dataset, and standard evaluation methods described in the paper.
- [Software, Platforms] Diversity Audit and Monitoring Toolkit for LLM Products
- Samples multiple outputs per open-ended prompt (e.g., 50 per prompt from Infinity-Chat100).
- Computes pairwise sentence embedding similarities (as in the paper; e.g., using text-embedding-3-small).
- Reports metrics such as Intra-Model Similarity, Inter-Model Similarity, Top-N Unique Model Counts, and cluster analysis (e.g., PCA + clustering).
- Integrates into CI to gate releases when diversity drops below thresholds.
- Assumptions/Dependencies: Access to the dataset and embeddings API; moderate compute; agreement on similarity thresholds.
- [Marketing, Creative Industries, Education] “Diversity Slider” in Generation UIs Add a user-facing control that toggles decoding regimes tuned for open-ended tasks (e.g., higher temperature, top-p, min-p), with warnings about coherence trade-offs, aligning with the paper’s findings on decoding. Assumptions/Dependencies: Product teams can switch decoding strategies; min-p implemented or proxied.
- [Consumer Apps, Education, Publishing] Multi-Voice Response Mode
- Over-sampling candidate responses.
- Clustering and de-duplicating high-similarity outputs.
- Labeling options using the taxonomy (e.g., “speculative scenario,” “alternative writing genre”).
- Assumptions/Dependencies: Access to over-sampling, embeddings, clustering; UX to display alternatives clearly.
- [Enterprise, Procurement, Policy] Vendor Selection and RFP Criteria Using Diversity Metrics
- A “Response Similarity Index” across models.
- Instance-level overlap reports (verbatim/semantic).
- Preference entropy coverage (how often models match human variability).
- Assumptions/Dependencies: Vendor API access; sampling budgets; internal audit standards.
- [ML Research, Platform Quality] Reward Model and LM Judge Calibration Benchmarking
- Compute correlations (Spearman/Pearson) between model scores and average human ratings, especially on similar-quality and high-disagreement subsets.
- Calibrate judges (e.g., scale smoothing on contested items; score aggregation) to better reflect human variability.
- Assumptions/Dependencies: Availability of reward models/judges and their scoring APIs; internal benchmarking infrastructure.
- [Data Engineering, Model Training] Synthetic Data Hygiene Checks
- Detect over-represented phrases and common tropes (e.g., “time is a river”).
- Filter or down-weight repetitive samples before inclusion in training or RLHF data.
- Assumptions/Dependencies: Access to data pipelines; willingness to enforce deduplication and diversity thresholds.
- [Product Analytics] A/B Testing Protocols for Creative Features
- Use Tukey’s fences (as in the paper) to focus on similar-quality cases.
- Track shifts in intra/inter-model similarity and user satisfaction.
- Assumptions/Dependencies: Logging, analytics, prompt management; alignment with product KPIs.
- [Education, Daily Life] Anti-Hivemind Prompting Guidance
- Example: “Provide five novel metaphors for time that explicitly avoid ‘river’ and ‘weaver’ motifs.”
- Assumptions/Dependencies: None beyond basic prompt literacy; portable across tools.
- [Governance, Platform Policy] Diversity Impact Statements (Pilot)
- Prompts used, diversity scores, observed inter-model overlap.
- Steps taken to mitigate homogenization (e.g., multi-voice mode).
- Assumptions/Dependencies: Voluntary compliance; internal audit capability; no formal standard yet.
Long-Term Applications
These applications require further research, scaling, or development (e.g., new training regimes, standards, or governance).
- [ML Training] Pluralistic Alignment with Distributional Labels
- Disagreement-aware loss functions.
- Diversity regularization in RLHF/DPO.
- Better handling of equally high-quality alternatives.
- Assumptions/Dependencies: Significant compute; method development; careful evaluation to avoid penalizing quality.
- [Software, Infrastructure] Diversity-Optimized Decoding and Routing
- Dynamically select models/prompts to maximize semantic variety for open-ended tasks.
- Monitor real-time similarity to avoid convergence.
- Assumptions/Dependencies: New algorithms; multi-model access; production-safe coherence controls.
- [AI Platforms] True-Diversity Ensembles
- Calibrate ensemble voting/aggregation to prioritize distinct ideas, not just paraphrases.
- Assumptions/Dependencies: Access to diverse models; coordination with model providers; ensemble reliability and cost.
- [Data Governance] Training Corpus Reforms and Provenance Standards
- Mandate diversity audits for large-scale data mixtures.
- Track contamination from synthetic outputs.
- Assumptions/Dependencies: Industry-wide tooling; shared metadata standards; potential policy support.
- [Healthcare, Finance, Law, Policy] Diversity-of-Opinions Decision Support Modules
- Require “preference entropy thresholds” to ensure meaningful variety in clinical or risk analysis narratives.
- Assumptions/Dependencies: Domain oversight; safety testing; guardrails to avoid confusion or misinformation.
- [Standards, Certification] Generative Diversity Index and Auditing Frameworks
- Define metrics (Response Similarity Index, Preference Entropy Alignment).
- Certify models/apps against diversity benchmarks derived from Infinity-Chat.
- Assumptions/Dependencies: Multi-stakeholder consensus; third-party auditors; interoperability.
- [Personalization, Consumer Apps] Individual-Level Pluralism
- Offer personalized responses while still presenting diverse alternatives.
- Respect privacy and prevent stereotype-based shortcuts.
- Assumptions/Dependencies: Consent, memory, privacy safeguards; careful evaluation of bias and overfitting.
- [Multilingual, Multimodal AI] Cross-Lingual and Cross-Modal Expansion Extend Infinity-Chat’s taxonomy and annotation approach to other languages and modalities (images, audio, video) to measure hivemind effects beyond English text. Assumptions/Dependencies: New data collection; culturally aware categories; multilingual annotators.
- [AI Research] Causal Analysis of Inter-Model Homogeneity Investigate sources of overlap (shared pretraining data, alignment processes, synthetic contamination) and design interventions that demonstrably reduce convergence without sacrificing quality. Assumptions/Dependencies: Access to training details (often proprietary); collaboration with model providers; reproducible methodologies.
Glossary
- Absolute ratings: Numeric assessments of the quality of a single response to a query. "Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example."
- Artificial Hivemind: A phenomenon where LLMs converge to similar outputs across and within models, reducing diversity. "We uncover a pronounced Artificial Hivemind effect: (1) intra-model repetition, where a single model repeatedly generates similar outputs, and, more critically, (2) inter-model homogeneity, where different models independently converge on similar ideas with minor variations in phrasing."
- Ensemble methods: Techniques that combine multiple models to improve performance or diversity of outputs. "While ensemble methods or model ``swarms'' have been proposed to enhance diversity"
- HHH rubric: A three-part evaluation rubric—Helpfulness, Harmlessness, Honesty—used by LM judges to rate responses. "LM judge ratings follow standard prompting protocols using two rubrics: an overall quality score and the HHH rubric (Helpfulness, Harmlessness, Honesty)"
- Inter-model homogeneity: Similarity of outputs produced by different models for the same task or prompt. "inter-model homogeneity, where different models produce strikingly similar outputs"
- Intra-model repetition: The tendency of a single model to generate highly similar responses when sampled multiple times. "intra-model repetition, where a single model consistently generates similar responses"
- IQR (Interquartile Range): The range between the 25th and 75th percentiles, used to assess spread and detect outliers. "IQR = Q3 - Q1"
- LM judge: A LLM used to evaluate and score other models’ outputs according to specified rubrics. "our findings show that state-of-the-art LMs, reward models, and LM judges are less well calibrated to human ratings"
- Min-p decoding: A dynamic sampling strategy that adjusts the minimum probability threshold to enhance diversity in generation. "Recent work introduces min-p decoding, a dynamic strategy for enhancing generation diversity that adjusts the sampling threshold based on model confidence."
- Mode collapse: Failure of a generative model to produce diverse outputs, instead concentrating on a few modes. "we present a large-scale study of mode collapse in LMs"
- Pairwise preferences: Annotations where evaluators indicate which of two responses is preferred (including ties or strength of preference). "Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences"
- Pearson correlations: A measure of linear association between two variables’ scores. "We then compute Pearson correlations between model and human absolute ratings on the full set"
- Perplexity: A measure of a LLM’s uncertainty; lower perplexity indicates better predictive performance. "LM scores are derived from response perplexity given the query."
- Pluralistic alignment: Aligning models to accommodate diverse, potentially conflicting human preferences and values. "advancing pluralistic alignment of LMs"
- Principal Component Analysis (PCA): A dimensionality reduction technique that projects data onto principal axes capturing maximal variance. "clustered by applying PCA to reduce sentence embeddings to two dimensions."
- Reward model: A model that produces a scalar score indicating the quality or desirability of a response. "state-of-the-art LMs, reward models, and LM judges"
- Sentence embeddings: Vector representations of sentences that capture semantic content for similarity and clustering. "Sentence embeddings from OpenAI’s text-embedding-3-small API are used."
- Shannon entropy: An information-theoretic measure of uncertainty or disagreement in a distribution of labels or ratings. "The left histogram shows the distribution of Shannon entropy across the 25 human annotations"
- Spearman's correlation coefficient: A rank-based correlation measure assessing monotonic relationships between variables. "We compute Spearman's correlation coefficients between human-annotated and model-generated absolute rating scores"
- Temperature: A decoding parameter that controls randomness in sampling; higher values increase diversity at the risk of incoherence. "temperature "
- Top-p sampling: Nucleus sampling that selects from the smallest set of tokens whose cumulative probability exceeds p. "top-p sampling ()"
- Tukey’s fences: An outlier detection method using quartiles and IQR to filter extreme values. "This method defines outliers as points beyond or "
Collections
Sign up for free to add this paper to one or more collections.