- The paper demonstrates that output homogenization in LLMs is task-dependent by introducing a taxonomy and functional diversity metric.
- It presents a task-anchored sampling technique that improves solution diversity while preserving quality in both objective and creative tasks.
- Empirical evaluations across multiple LLMs reveal a negligible diversity-quality trade-off, underscoring the method’s robustness and practical impact.
Task-Dependent Output Homogenization in LLMs
Introduction
The paper "LLM Output Homogenization is Task Dependent" (2509.21267) presents a comprehensive framework for understanding, evaluating, and mitigating output homogenization in LLMs through a task-dependent lens. The authors argue that the desirability and interpretation of output homogenization are fundamentally contingent on the nature of the task, and that existing diversity-promoting methods often fail to account for this nuance. The work introduces a taxonomy of task categories, formalizes task-anchored functional diversity, and proposes a sampling technique that adaptively promotes or preserves homogenization based on task requirements. Empirical results demonstrate that this approach increases functional diversity where appropriate, without sacrificing response quality, and challenges the prevailing assumption of a diversity-quality trade-off.
Task Taxonomy and Functional Diversity
A central contribution is the taxonomy of eight task categories, each with distinct conceptualizations of output homogenization and functional diversity. These categories span a spectrum from well-specified objective tasks (single verifiable answer) to creative writing and advice/opinion tasks (infinite subjective answers). The taxonomy enables precise anchoring of diversity expectations:
- Well-Specified Singular Objective: Homogenization is desirable; diversity in final answers is not.
- Underspecified Singular Objective / Random Generation: Multiple correct answers; diversity is expected in outputs.
- Problem-Solving Objective: Single correct answer, but diversity in solution strategies is meaningful.
- Creative Writing / Advice or Opinions: Diversity in key creative elements or perspectives is essential.
The paper formalizes task-anchored functional diversity as a metric that evaluates whether two responses are meaningfully different with respect to the task category, operationalized via LLM-judges and human annotation.
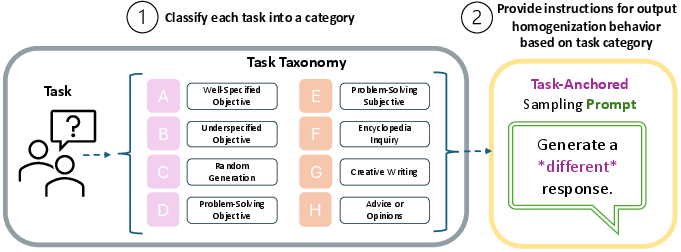
Figure 1: Task-anchored sampling framework: prompts are classified into task categories, and diversity instructions are tailored to the category, enabling adaptive homogenization or diversification.
Task-Anchored Sampling Technique
The authors propose a task-anchored sampling technique that modifies existing prompt-based diversity methods. Instead of generic instructions to "generate diverse responses," the system prompt or in-context regeneration prompt is tailored to the task category, specifying the type of diversity that is meaningful (e.g., solution strategies for math, creative elements for writing). This approach is implemented at inference-time and can be automated by first classifying the prompt into a taxonomy category and then applying the appropriate diversity instruction.
Experimental Evaluation
Functional Diversity Across Tasks
Empirical results on GPT-4o, Claude-4-Sonnet, and Gemini-2.5-Flash across 300 prompts from diverse benchmarks show that task-anchored sampling:
- Preserves homogenization in well-specified objective tasks, avoiding undesired diversity.
- Maximizes functional diversity in creative, advice, and open-ended tasks, outperforming general diversity-promoting methods.
- Improves diversity in solution strategies for problem-solving tasks, where general methods fail to elicit meaningful variation.
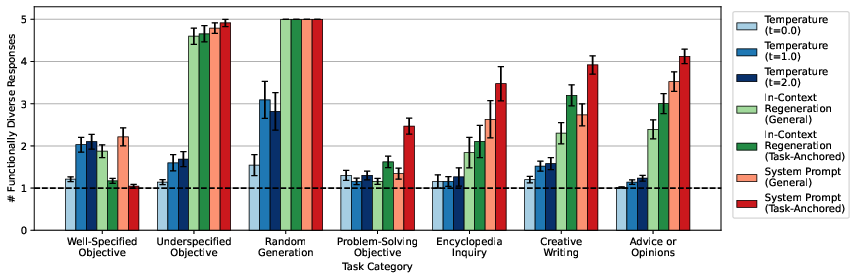
Figure 2: Task-anchored sampling increases functional diversity where desired, while preserving homogenization in tasks requiring consistency (GPT-4o results).
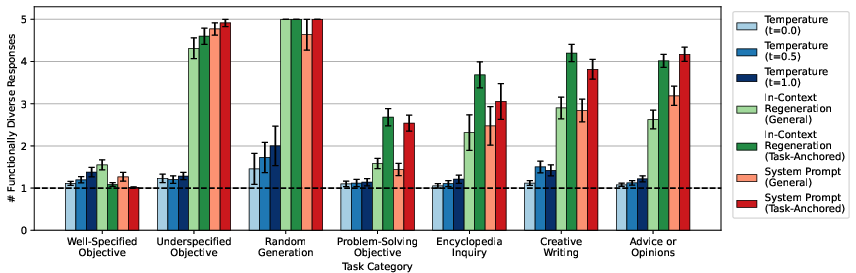
Figure 3: Functional diversity results for Claude-4-Sonnet, showing similar trends to GPT-4o.
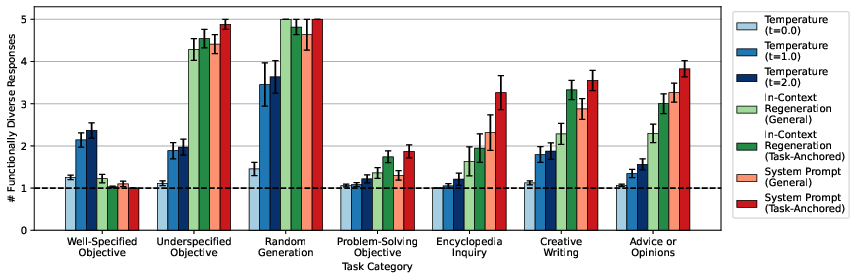
Figure 4: Functional diversity results for Gemini-2.5-Flash, confirming cross-model consistency.
Diversity-Quality Trade-off
The study rigorously evaluates the diversity-quality trade-off using both general metrics (vocabulary, embedding diversity) and task-anchored metrics (functional diversity, checklist-based quality). Results indicate:
- General diversity metrics (e.g., vocabulary diversity) exhibit a strong negative correlation with reward model quality, suggesting a trade-off.
- Task-anchored metrics show negligible trade-off: increased functional diversity does not reduce checklist-based quality scores.
- Task-anchored sampling maintains or improves accuracy in verifiable tasks compared to temperature sampling.
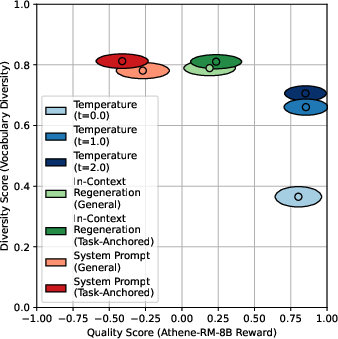
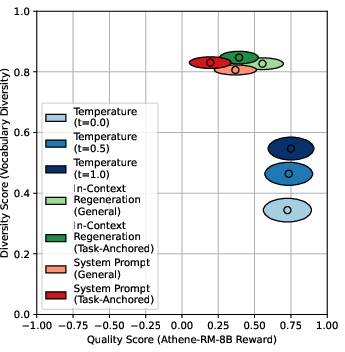
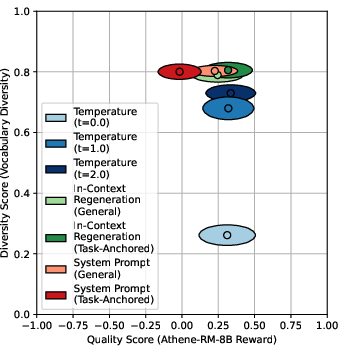
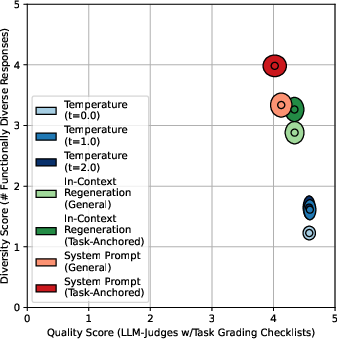
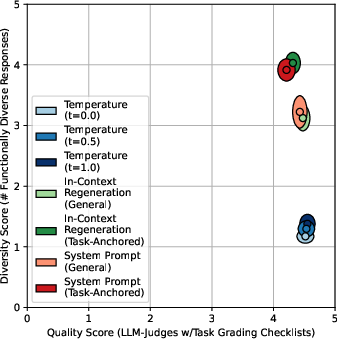
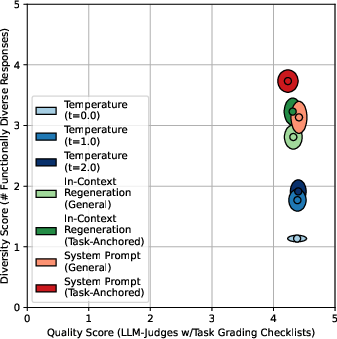
Figure 5: General diversity metrics (vocabulary diversity) vs. reward model quality for GPT-4o, showing a pronounced trade-off.
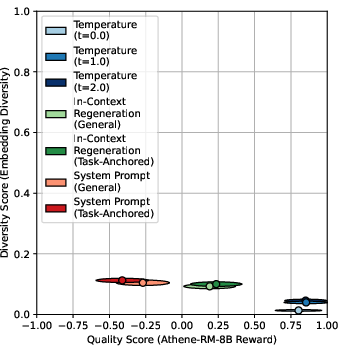
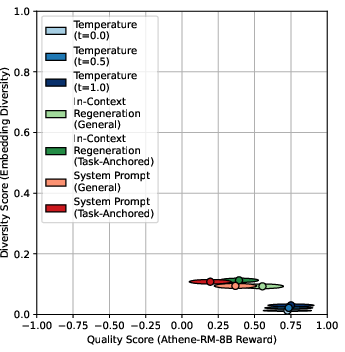
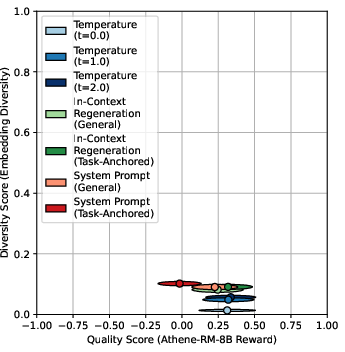
Figure 6: Task-anchored functional diversity vs. checklist-based quality for GPT-4o, showing negligible trade-off.
Implications and Future Directions
Practical Implications
- Robust Evaluation: The taxonomy and task-anchored metrics provide a principled framework for evaluating LLM output diversity, avoiding confabulations and undesired variation in tasks where consistency is critical.
- Safe Deployment: Task-dependent homogenization mitigates risks in downstream applications, such as factual misrepresentation in encyclopedia tasks or lack of pluralism in advice/opinion tasks.
- Alignment and Training: The approach can be extended to alignment methods (e.g., RLHF, DPO) by constructing preference pairs and diversity penalties in a task-informed manner.
Theoretical Implications
- Conceptual Clarity: The work challenges the field's reliance on general diversity metrics and the assumption of a universal diversity-quality trade-off, advocating for task-dependent conceptualization.
- Generalizability: The framework is adaptable to custom taxonomies and can be integrated into chain-of-thought reasoning, enabling models to reason about diversity requirements before generation.
Future Research
- Automated Task Classification: Improving models' ability to autonomously classify prompts into taxonomy categories.
- Integration with Alignment Objectives: Embedding task-anchored diversity directly into training objectives and preference dataset construction.
- Reasoning about Diversity: Training models to explicitly reason about functional diversity requirements as part of their generation process.
Conclusion
This paper establishes that output homogenization in LLMs is inherently task-dependent and that both evaluation and mitigation strategies must be anchored in the specific requirements of the task. The proposed taxonomy, functional diversity metric, and task-anchored sampling technique collectively enable adaptive control over output diversity, improving both the utility and safety of LLM deployments. The empirical results refute the notion of an inevitable diversity-quality trade-off and set a new standard for principled diversity evaluation in generative models. The framework is extensible and provides a foundation for future research in task-aware LLM alignment and generation.

