- The paper presents GS-Reasoner, demonstrating that integrating explicit 3D visual grounding as an intermediate chain-of-thought step significantly enhances spatial reasoning accuracy.
- It introduces a semantic-geometric hybrid 3D scene representation that fuses vision foundation models with point cloud encoders, ensuring precise alignment of semantic and geometric features.
- It constructs a novel Grounded Chain-of-Thought (GCoT) dataset that bridges step-by-step reasoning with 3D bounding box annotations, outperforming state-of-the-art methods on multiple benchmarks.
GS-Reasoner: Integrating Visual Grounding as Chain-of-Thought for 3D Spatial Reasoning
Introduction
The paper introduces GS-Reasoner, a 3D LLM framework that tightly integrates 3D visual grounding as an explicit, autoregressive intermediate step within spatial reasoning. The central claim is that 3D visual grounding—accurately linking textual references to objects in 3D space—is a prerequisite for robust spatial reasoning. Existing 3D LLMs either underperform in grounding or depend on external modules, which impedes seamless integration and interpretability. GS-Reasoner addresses these limitations by proposing a unified semantic-geometric 3D scene representation and a novel Grounded Chain-of-Thought (GCoT) dataset, enabling end-to-end autoregressive grounding and reasoning.
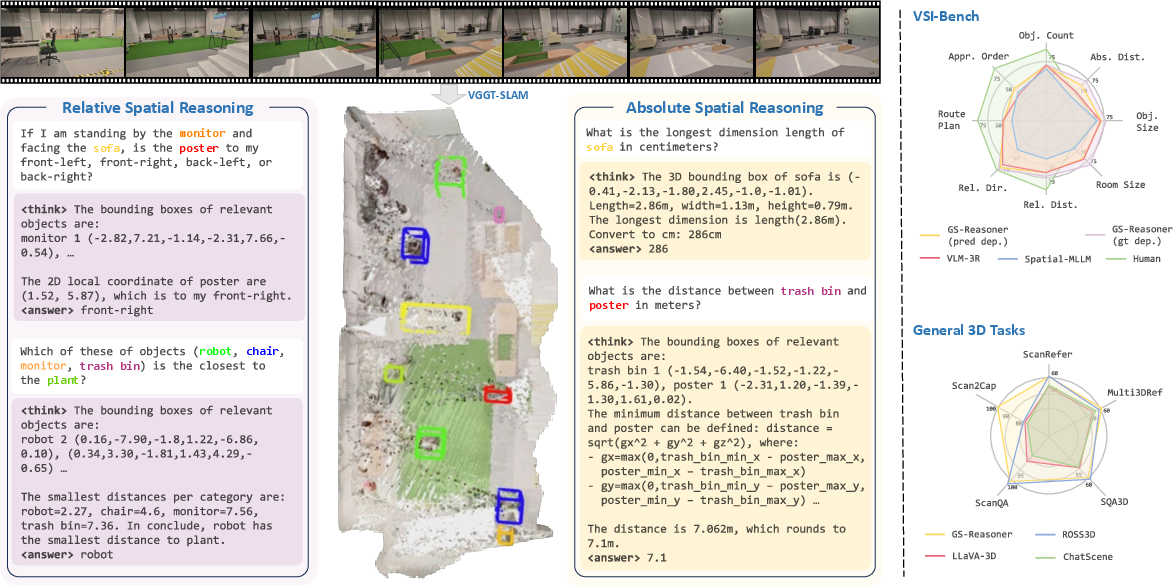
Figure 1: GS-Reasoner integrates visual grounding as an intermediate chain-of-thought for spatial reasoning, with bounding boxes derived autoregressively in the wild, without sensory 3D inputs.
Semantic-Geometric Hybrid 3D Scene Representation
GS-Reasoner constructs a unified 3D scene representation by fusing semantic features from vision foundation models, geometric features from point cloud encoders, and explicit 3D positional encodings. The representation is patch-based, aligning with the input structure of modern vision transformers.
The geometric encoder, based on Point Transformer v3 (PTv3), processes the aggregated point cloud from multi-view depth maps. To address semantic-geometric and position-geometric misalignment, the authors introduce a dual-path pooling mechanism:
- Semantic-aligned geometric features: Cross-attention between patch semantic features (as queries) and geometric features (as keys/values) within each patch.
- Position-aligned geometric features: Sampling the 3D point at the patch center and interpolating geometric features to ensure spatial consistency.
These features are concatenated and projected to form the final patch-level hybrid representation, which is then input to the video LLM for autoregressive grounding and reasoning.
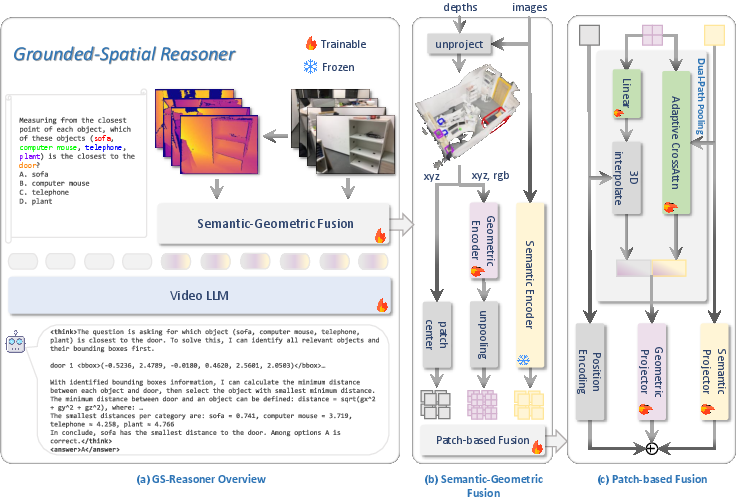
Figure 2: GS-Reasoner framework overview, showing the construction of a semantic-geometric hybrid 3D scene representation and its use in autoregressive 3D visual grounding and spatial reasoning.
Grounded Chain-of-Thought (GCoT) Dataset
The GCoT dataset is designed to bridge grounding and spatial reasoning by providing both 3D bounding box annotations and step-by-step reasoning paths that explicitly incorporate grounding. The dataset construction pipeline involves:
- Generating spatial QA pairs from large-scale 3D datasets (ScanNet, ScanNet++, ARKitScenes).
- Using GPT-4o to generate chain-of-thought (CoT) reasoning paths, leveraging bird's-eye views and object metadata.
- Structuring answers to first ground relevant objects (with explicit 3D bounding boxes) and then perform stepwise spatial reasoning.
The dataset contains 156k QA pairs, with 79% including CoT annotations, and covers a diverse set of spatial and temporal reasoning tasks.
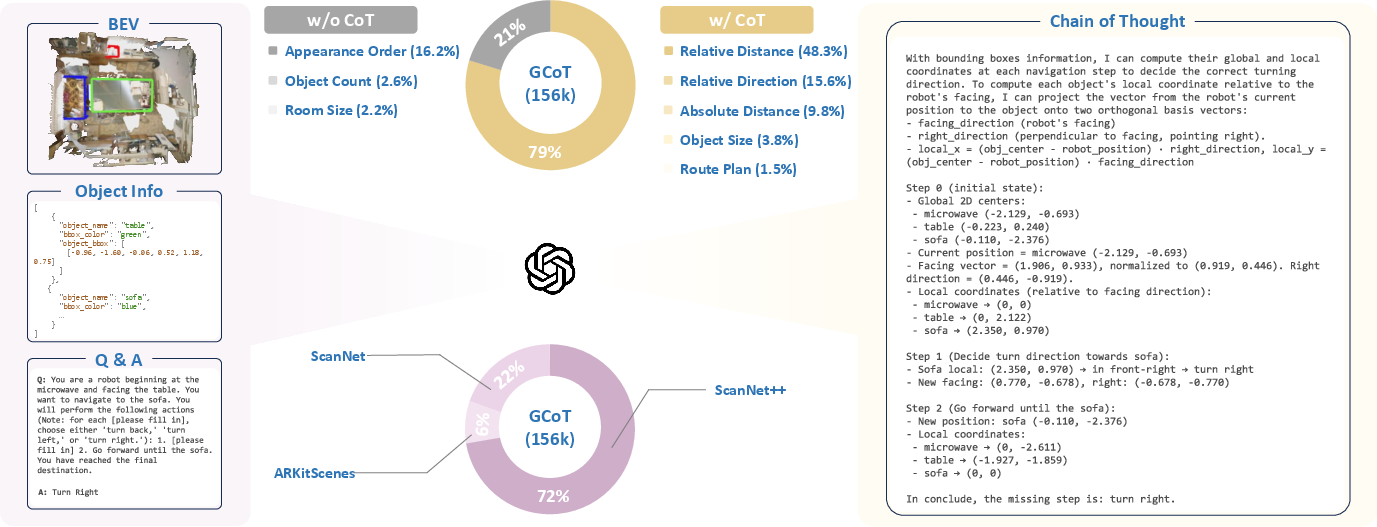
Figure 3: Overview of the GCoT dataset construction, illustrating the generation of spatial QA pairs and CoT paths using GPT-4o.
Experimental Results
3D Visual Grounding
GS-Reasoner is evaluated on standard 3D visual grounding benchmarks (ScanRefer, Multi3DRef, SR3D, NR3D). It achieves state-of-the-art or highly competitive results among 3D LLMs, especially in multi-object grounding (F1@25 on Multi3DRef), and matches or surpasses models that rely on external proposals or grounding modules. Notably, GS-Reasoner operates without any external modules, using only noisy, incomplete sensor point clouds.
Spatial Reasoning
On VSI-Bench, a comprehensive spatial reasoning benchmark, GS-Reasoner outperforms all open-source and proprietary VLMs and specialized spatial reasoning models on most tasks, particularly those requiring precise 3D localization and complex spatial relationships (e.g., Relative Direction, Absolute Distance). Performance further improves with access to ground-truth depth, indicating the importance of accurate geometric input.
General 3D Vision-Language Tasks
GS-Reasoner sets a new state of the art on Scan2Cap (3D dense captioning) and achieves competitive results on ScanQA and SQA3D. The explicit grounding step is shown to improve dense captioning by forcing the model to better capture geometric and positional cues.
Ablation and Analysis
- Zero-shot generalization: GS-Reasoner demonstrates strong transfer to unseen scenes (ScanNet++, ARKitScenes) without finetuning, matching expert models.
- Representation ablation: Dual-path pooling and hybrid semantic-geometric features yield substantial gains in grounding accuracy (Acc@25, Acc@50).
- GCoT ablation: Removing the grounding step from CoT reasoning significantly degrades performance on spatial reasoning tasks, confirming the necessity of explicit grounding as an intermediate step.
Qualitative Results
GS-Reasoner produces interpretable, stepwise reasoning outputs, with explicit bounding box predictions and spatial relationship analysis. Qualitative examples on VSI-Bench demonstrate robust generalization to in-the-wild scenes and complex queries.
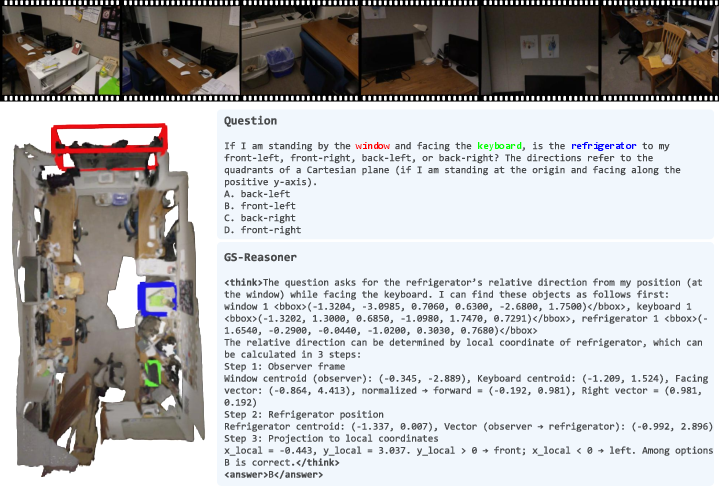
Figure 4: Qualitative results on VSI-Bench, showing GS-Reasoner's stepwise reasoning and grounding outputs.
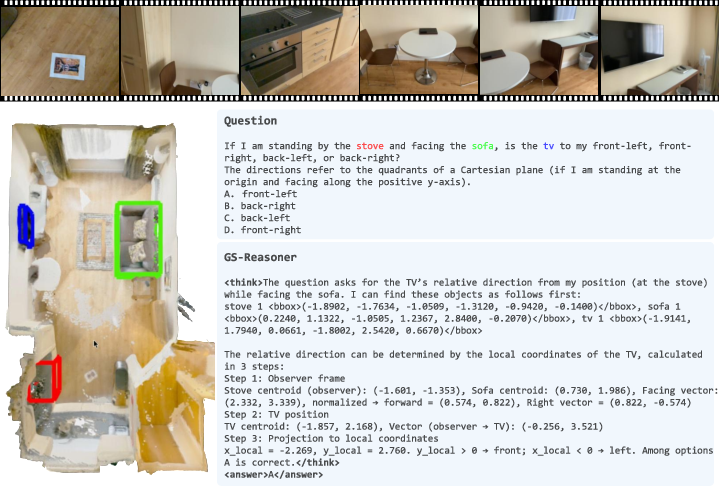
Figure 5: Additional qualitative results on VSI-Bench, highlighting spatial relationship reasoning.
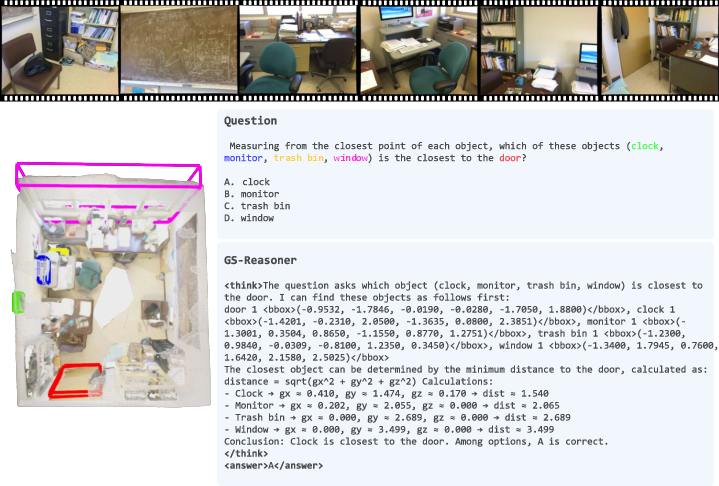
Figure 6: Further qualitative results on VSI-Bench, demonstrating multi-object grounding and reasoning.
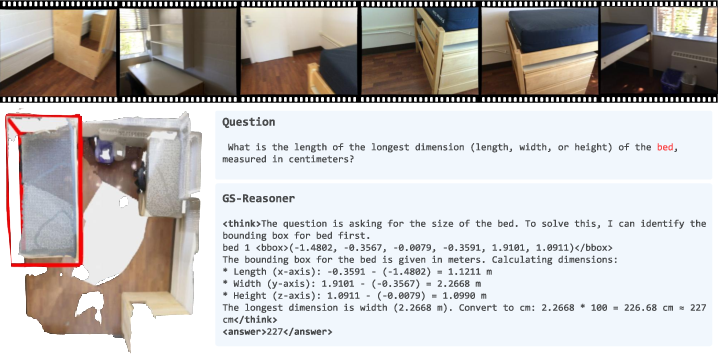
Figure 7: More qualitative results on VSI-Bench, illustrating interpretability and generalization.
Implications and Future Directions
GS-Reasoner demonstrates that integrating 3D visual grounding as an explicit, autoregressive chain-of-thought step is both feasible and beneficial for spatial reasoning in 3D LLMs. The semantic-geometric hybrid representation enables end-to-end training and inference without reliance on external modules, improving interpretability and generalization. The GCoT dataset provides a new paradigm for training models to reason in space by first grounding relevant objects.
Practically, this approach is directly applicable to embodied AI, robotics, and autonomous systems, where spatial reasoning and object localization are critical. The framework is compatible with vision-language-action (VLA) models and can be extended to planning and task decomposition in embodied environments.
Theoretically, the work suggests that explicit intermediate representations (grounding as CoT) can bridge the gap between perception and reasoning in multimodal LLMs. Future research may explore joint training with action data, integration with real-time SLAM, and scaling to outdoor or dynamic environments.
Conclusion
GS-Reasoner establishes a unified, self-contained framework for 3D spatial reasoning by tightly coupling visual grounding and reasoning in an autoregressive, interpretable manner. The semantic-geometric hybrid representation and GCoT dataset are shown to be critical for state-of-the-art performance across grounding, spatial reasoning, and general 3D vision-language tasks. This work provides a foundation for further advances in spatially-aware, multimodal LLMs and their deployment in real-world embodied systems.

