- The paper introduces UniVLG, which leverages pre-trained 2D models and a language-conditioned mask decoder to unify 2D and 3D vision-language tasks.
- It employs 2D-to-3D lifting strategies and 3D relative attention layers, achieving state-of-the-art results in 3D referential grounding and segmentation tasks.
- The approach eliminates the need for 3D mesh reconstructions, setting a new standard for robust 3D performance in embodied vision systems.
Unifying 2D and 3D Vision-Language Understanding
Introduction
The paper "Unifying 2D and 3D Vision-Language Understanding" addresses the existing gap between 2D-centric models and the rich 3D sensory data available in embodied systems due to the scarcity of large-scale 3D datasets. It introduces UniVLG, a unified architecture for 2D and 3D vision-language understanding. The model leverages pre-trained 2D models, proposes a language-conditioned mask decoder, and incorporates 2D-to-3D lifting strategies to enhance 3D performance. This paper highlights UniVLG's state-of-the-art performance across multiple 3D vision-language grounding tasks, demonstrating the potential for transferring 2D advances to the data-constrained 3D domain. The model also eliminates reliance on 3D mesh reconstruction and ground-truth object proposals, setting a realistic evaluation standard.
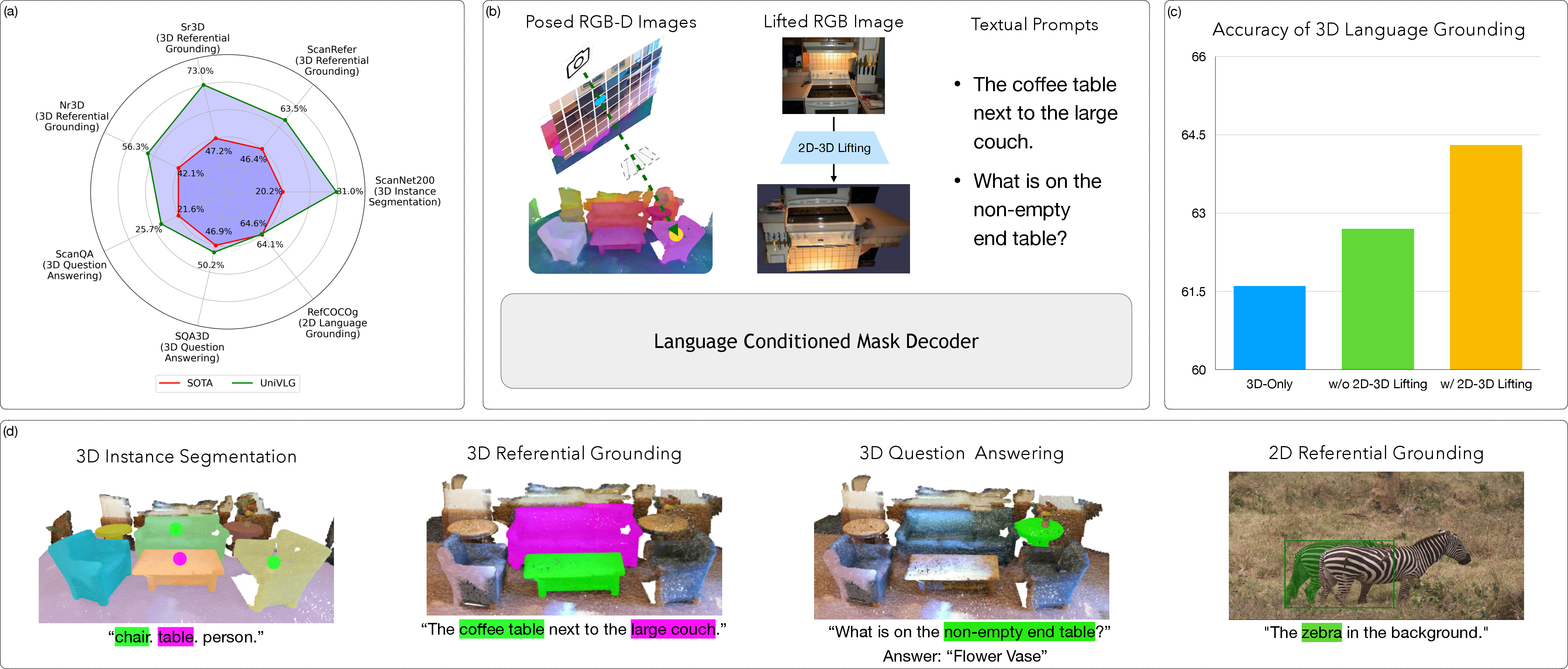
Figure 1: (A) UniVLG achieves state-of-the-art performance across various benchmarks. (B) Accepts posed RGB-D sequences or 2D images lifted to 3D pointmaps. (C) Benefits from joint 2D-3D training. (D) Example task inputs/outputs for UniVLG.
Methodology
Architecture
The UniVLG architecture is a vision-language transformer that processes language utterances along with RGB-D or lifted RGB images. It uses a ViT backbone followed by 3D relative attention layers that produce 3D feature tokens. The model includes a proposed decoder that iteratively refines learnable queries using token-language-query attentions, enabling it to decode object segments and match them to corresponding noun phrases in the input referential utterance.
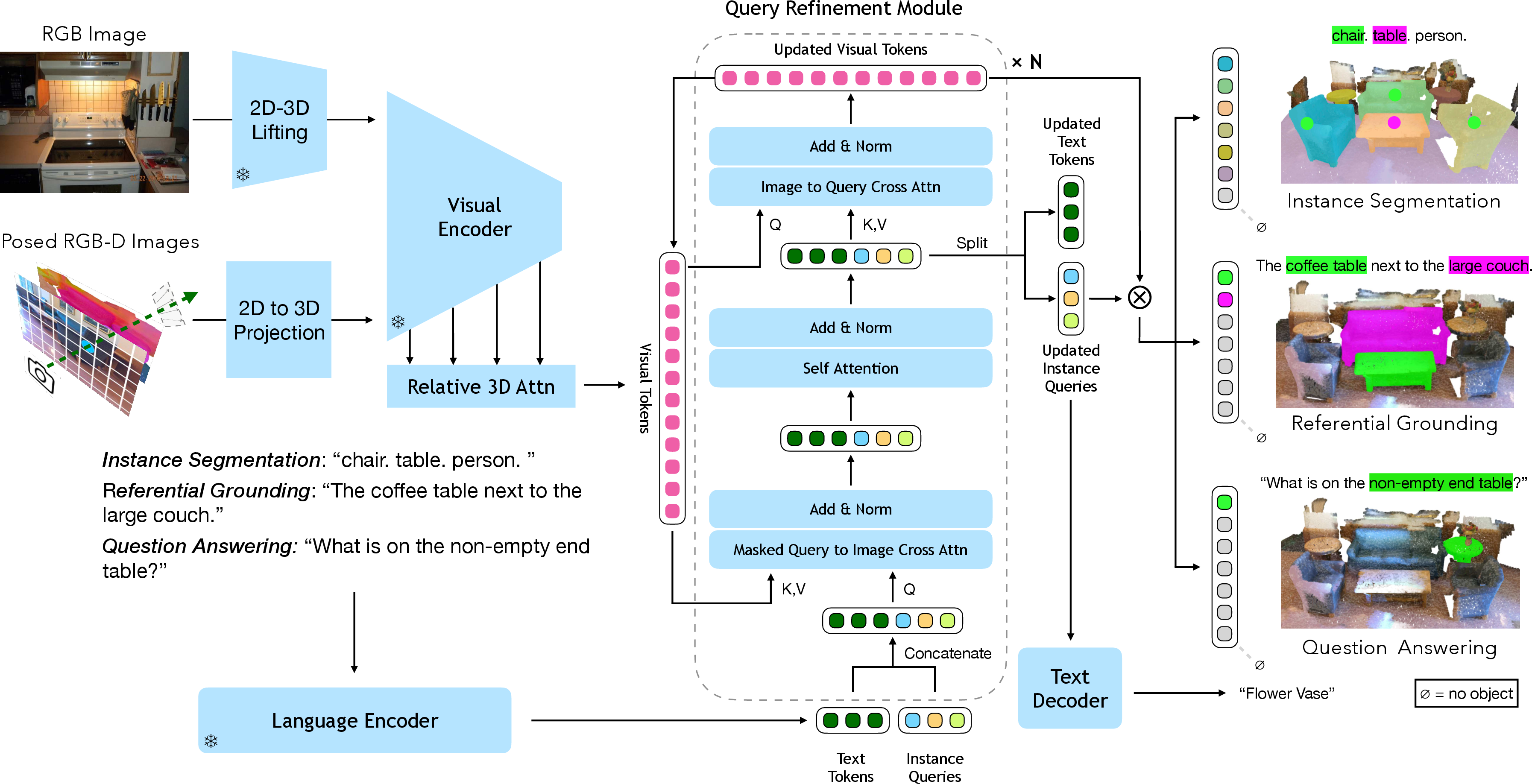
Figure 2: UniVLG Architecture: Fuses information across vision and language to predict 3D segments or generate answers using a ViT backbone and 3D attentions.
Language-Conditioned Mask Decoder
UniVLG introduces a language-conditioned mask decoder shared between 2D and 3D modalities. The decoder predicts segmentation masks by conditioning visual features and language instructions. This innovation is critical for effective grounding in RGB and RGB-D images, providing a unified output space involving per-patch predictions, which translates to precise segment decoding—shown to outperform traditional box-based decoders.
Training Strategy
UniVLG is trained on 2D and 3D datasets, co-training both modalities while leveraging 2D-to-3D lifting strategies which narrow the domain gap between 2D and 3D inputs. The architecture benefits from the representation strength of pre-trained 2D backbones and incorporates supervised mask, text span, box losses, and text generation objectives for end-to-end learning.
Experiments and Results
UniVLG is evaluated on several benchmarks, including 3D referential grounding, visual question answering, and 3D instance segmentation tasks, significantly outperforming existing methods. In the referential grounding task, UniVLG achieves state-of-the-art results in both in-domain (e.g., ScanRefer, NR3D) and out-of-domain settings (e.g., LX3D datasets), demonstrating superior generalization capabilities.

Figure 3: Visualization of UniVLG on 3D Referential Grounding Datasets. Shows predictions and ground-truth in complex scenes.
In 3D referential grounding, UniVLG exhibits resilience to input noise and maintains robust performance across unseen scenes and tasks. The model's lifting strategy enhances its applicability to various domains, closing the performance gap with traditional mesh-based methods while operating directly on sensor-generated point clouds.
Discussion
The paper argues the superiority of mask-based decoding over box-based approaches due to its robust performance in scenarios involving complex object instances. However, decoding segment masks is susceptible to failure modes, such as including distant points or multiple instances within a single mask, necessitating further exploration.
Conclusion
UniVLG effectively bridges the gap between 2D and 3D vision-language tasks, leveraging comprehensive training strategies and architecture designs that integrate pre-trained 2D features and innovative decoding mechanisms. Looking ahead, scaling the model with additional 2D datasets and refining mask decodings remain promising avenues for enhancing 3D vision-language systems' robustness and applicability across different complex real-world tasks.